

Self-supervised Multimodal Emotion Recognition Combining Temporal Attention Mechanism and Unimodal Label Automatic Generation Strategy
-
摘要: 大多数多模态情感识别方法旨在寻求一种有效的融合机制,构建异构模态的特征,从而学习到具有语义一致性的特征表示。然而,这些方法通常忽略了模态间情感语义的差异性信息。为解决这一问题,提出了一种多任务学习框架,联合训练1个多模态任务和3个单模态任务,分别学习多模态特征间的情感语义一致性信息和各个模态所含情感语义的差异性信息。首先,为了学习情感语义一致性信息,提出了一种基于多层循环神经网络的时间注意力机制(TAM),通过赋予时间序列特征向量不同的权重来描述情感特征的贡献度。然后,针对多模态融合,在语义空间进行了逐语义维度的细粒度特征融合。其次,为了有效学习各个模态所含情感语义的差异性信息,提出了一种基于模态间特征向量相似度的自监督单模态标签自动生成策略(ULAG)。通过在CMU-MOSI, CMU-MOSEI, CH-SIMS 3个数据集上的大量实验结果证实,提出的TAM-ULAG模型具有很强的竞争力:在分类指标($ Ac{c_2} $, $ {F_1} $)和回归指标(MAE, Corr)上与基准模型的指标相比均有所提升;对于二分类识别准确率,在CMU-MOSI和CMU-MOSEI数据集上分别为87.2%和85.8%,而在CH-SIMS数据集上达到81.47%。这些研究结果表明, 同时学习多模态间的情感语义一致性信息和各模态情感语义的差异性信息,有助于提高自监督多模态情感识别方法的性能。Abstract: Most multimodal emotion recognition methods aim to find an effective fusion mechanism to construct the features from heterogeneous modalities, so as to learn the feature representation with semantic consistency. However, these methods usually ignore the emotionally semantic differences between modalities. To solve this problem, one multi-task learning framework is proposed. By training one multimodal task and three unimodal tasks jointly, the emotionally semantic consistency information among multimodal features and the emotionally semantic difference information contained in each modality are respectively learned. Firstly, in order to learn the emotionally semantic consistency information, one Temporal Attention Mechanism (TAM) based on a multilayer recurrent neural network is proposed. The contribution degree of emotional features is described by assigning different weights to time series feature vectors. Then, for multimodal fusion, the fine-grained feature fusion per semantic dimension is carried out in the semantic space. Secondly, one self-supervised Unimodal Label Automatic Generation (ULAG) strategy based on the inter-modal feature vector similarity is proposed in order to effectively learn the difference information of emotional semantics in each modality. A large number of experimental results on three datasets CMU-MOSI, CMU-MOSEI, CH-SIMS, confirm that the proposed TAM-ULAG model has strong competitiveness, and has improved the classification indices ($ Ac{c_2} $, $ {F_1} $) and regression index (MAE, Corr) compared with the current benchmark models. For binary classification, the recognition rate is 87.2% and 85.8% on the CMU-MOSEI and CMU-MOSEI datasets, and 81.47% on the CH-SIMS dataset. The results show that simultaneously learning the emotionally semantic consistency information and the emotionally semantic difference information for each modality is helpful in improving the performance of self-supervised multimodal emotion recognition method.
-
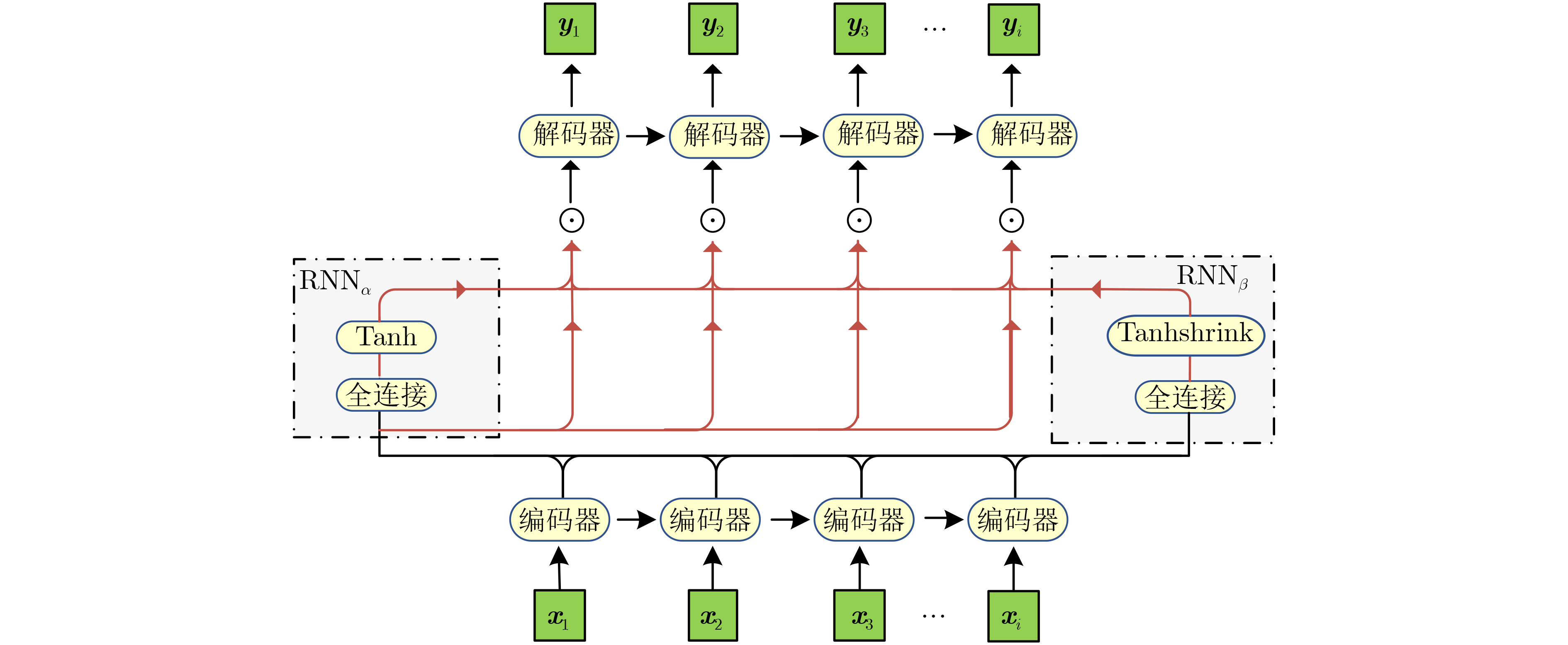
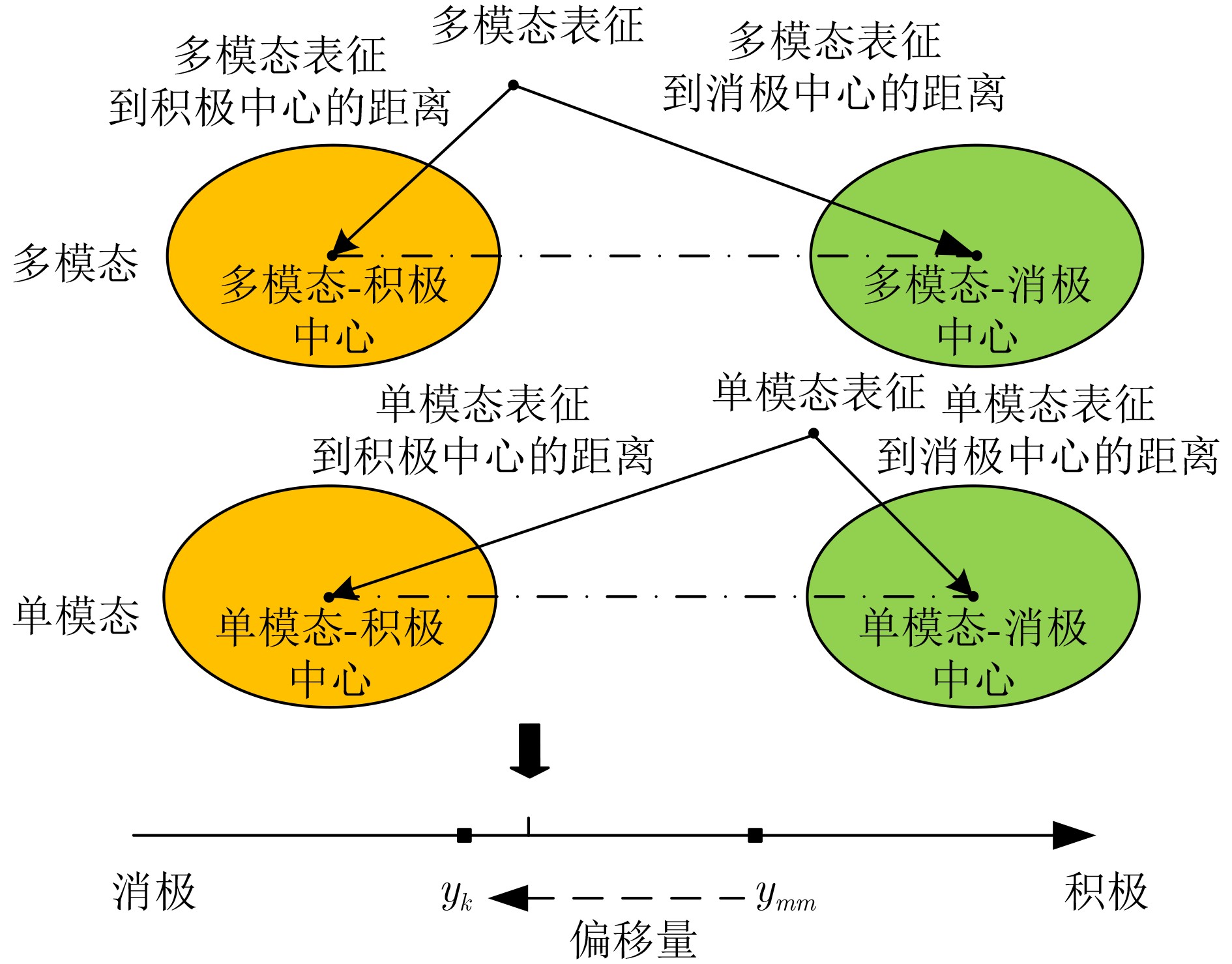
1 自监督单模态标签自动生成
输入:单模态输入$ {I_t} $,$ {I_a} $,$ {I_v} $,多模态标签$ {y_{{mm}}} $ 输出:$ {\mathrm{F}}_k^n $, $ k \in \{ {\text{mm}},{\text{t}},{\text{a}},{\text{v}}\} $, $ n $代表训练次数 1:初始化模型参数$ M\left( {\theta ;x} \right) $ 2:初始化单模态标签$ y_{\text{t}}^1 = {y_{{\text{mm}}}} $, $ y_{\text{a}}^1 = {y_{{\text{mm}}}} $, $ y_{\text{v}}^1 = {y_{{\text{mm}}}} $ 3:初始化全局表征$ {\mathrm{F}}_{\text{t}}^{\text{g}} = 0 $, $ {\mathrm{F}}_{\text{a}}^{\text{g}} = 0 $, $ {\mathrm{F}}_{\text{v}}^{\text{g}} = 0 $, $ {\mathrm{F}}_{{\text{mm}}}^{\text{g}} = 0 $ 4:for 模型训练回合数 do 5: for mini-batch in dataLoader do 6: 通过时间注意力机制计算小批量模态表征$ {{\mathrm{F}}_{\text{t}}} $, $ {{\mathrm{F}}_{\text{a}}} $, $ {{\mathrm{F}}_{\text{v}}} $, $ {{\mathrm{F}}_{{\text{mm}}}} $ 7: 计算多模态表征$ {\mathrm{F}}_{{\text{mm}}}^{\text{*}} $以及预测标签$ \mathop {{y_{{\text{mm}}}}}\limits^ \wedge $ 8: 通过损失函数式(23)来计算损失 9: 计算梯度$ \dfrac{{\partial L}}{{\partial \theta }} $ 10: 更新模型参数$ \theta = \theta - \dfrac{{\partial L}}{{\partial \theta }} $ 11: if $ n \ne 1 $ then 12: 生成相似度分数$ {c_{\text{t}}} $,$ {c_{\text{a}}} $,$ {c_{\text{v}}} $以及通过权重注意力生成单模
态标签$ y_{\text{t}}^n,y_{\text{a}}^n,y_{\text{v}}^n $13: end if 14:利用$ {\mathrm{F}}_s^ * $ $ s \in \left\{ {{\text{mm}},{\text{t}},{\text{a}},{\text{v}}} \right\} $更新全局表征$ {\mathrm{F}}_s^{\text{g}} $ 15: end for 16:end for  下载: 导出CSV
下载: 导出CSV
表 1 数据集的统计信息
下载: 导出CSV
表 2 模型的超参数设置
超参数 CMU-MOSI CMU-MOSEI CMU-SIMS Batch size 32 32 32 Number of Epochs 30 30 30 A-LSTM Dropout Rate 0.0 0.0 0.0 V-LSTM Dropout Rate 0.0 0.0 0.0 BERT Dropout Rate 0.1 0.1 0.1 V-LSTM隐藏层层数 64 32 64 A-LSTM隐藏层层数 32 32 16
下载: 导出CSV
表 3 不同模型对比结果CMU-MOSI数据
模型 Acc2 F1 MAE Corr Acc7 数据设置 TFN [9] 73.90 73.40 0.970 0.633 32.10 非对齐 RAVEN [32] 78.00 76.60 0.915 0.691 33.20 对齐 MCTN [33] 79.36 79.16 0.909 0.676 35.60 对齐 MuIT [34] 81.12 81.08 0.889 0.686 40.00 对齐 MMIM(B)[38] 84.14 84.00 0.700 0.800 46.65 非对齐 MAG-BERT(B)[35] 86.10 86.00 0.712 0.796 / 对齐 MHAI-BER(B)[36] 86.30 86.28 0.727 0.810 / 对齐 ConKI(B)[39] 84.37 84.33 0.681 0.816 48.43 非对齐 MTSA(B)[41] 86.80 86.80 0.696 0.806 46.40 非对齐 MISA(B)[37] 81.80 81.70 0.783 0.761 42.30 对齐 SUGRM(B)$ \otimes $[30] 84.40 84.30 0.703 0.800 / 非对齐 SaPIL(B)$ \otimes $ [42] 83.65 82.51 0.704 0.794 / 非对齐 TETFN(B)$ \otimes $[28] 84.05 83.83 0.717 0.800 / 非对齐 MTL-BAM(B)$ \otimes $[40] 85.36 85.37 0.703 0.798 / 非对齐 TPMSA(B)$ \otimes $[43] 87.00 87.00 0.704 0.799 / 非对齐 HIS-MSA(B)$ \otimes $[29] 86.01 85.99 0.671 0.819 48.40 非对齐 SELF-MM(B)$ \otimes $$ \bullet $[27] 85.02 85.12 0.713 0.798 45.04 非对齐 TAM-ULAG(本文) 87.20 87.12 0.695 0.816 48.94 非对齐
下载: 导出CSV
表 4 不同模型对比结果CMU-MOSEI数据集
模型 Acc2 F1 MAE Corr Acc7 数据设置 TFN [9] 74.30 73.40 0.720 0.497 50.20 非对齐 RAVEN [32] 79.10 79.50 0.614 0.662 / 对齐 MCTN [33] 79.80 80.60 0.609 0.670 / 对齐 MuIT [34] 82.50 82.30 0.580 0.703 48.80 对齐 MMIM(B)[38] 82.50 82.39 0.577 0.716 52.78 非对齐 MAG-BERT(B)[35] 85.10 85.06 0.555 0.758 52.67 对齐 MHAI-BER(B)[36] 85.56 85.52 0.588 0.816 / 对齐 ConKI(B)[39] 82.73 83.08 0.529 0.782 54.25 非对齐 MTSA(B)[41] 82.59 82.67 0.568 0.724 / 非对齐 MISA(B)[37] 83.60 83.80 0.555 0.756 52.20 对齐 SUGRM(B)$ \otimes $[30] 83.70 83.60 0.544 0.748 / 非对齐 SaPIL(B)$ \otimes $ [42] 82.98 83.26 0.523 0.766 / 非对齐 TETFN(B)$ \otimes $[28] 84.25 84.18 0.551 0.748 / 非对齐 MTL-BAM(B)$ \otimes $[40] 84.61 84.71 0.548 0.761 / 非对齐 TPMSA(B)$ \otimes $[43] 85.60 85.60 0.542 0.770 / 非对齐 HIS-MSA(B)$ \otimes $[29] 83.96 83.89 0.510 0.786 54.90 非对齐 SELF-MM(B)$ \otimes $$ \bullet $[27] 82.81 82.53 0.530 0.765 52.80 非对齐 TAM-ULAG(本文) 85.80 86.01 0.518 0.789 54.73 非对齐
下载: 导出CSV
表 6 CMU-MOSI数据集上不同模块的消融实验结果
模型 MAE Corr Acc2 F1 Acc7 w/o BERT 0.713 0.791 84.75 84.81 46.81 w/o 时间注意力 0.704 0.798 85.23 85.25 47.77 w/o 多模态融合 0.701 0.801 84.30 84.21 46.03 w/o ULAG 0.719 0.789 84.72 84.81 47.92 Use ULGM[27] 0.704 0.810 86.98 86.78 48.46 Use SUGRM[30] 0.700 0.811 87.0 86.98 48.53 TAM-ULAG(本文) 0.695 0.816 87.2 87.12 48.94
下载: 导出CSV
表 7 CMU-MOSI数据集上不同模态配置的消融实验结果
模型 MAE Corr Acc2 F1 M 0.732 0.789 83.3 83.3 M, V 0.721 0.791 84.6 84.8 M, A 0.719 0.796 83.8 83.8 M, T 0.704 0.804 85.1 85.3 M, A, V 0.713 0.798 85.5 85.5 M, T, V 0.701 0.800 86.4 86.5 M, T, A 0.708 0.797 86.2 86.1 M, T, A, V 0.695 0.816 87.2 87.12
下载: 导出CSV
表 8 模型在不同数据集上的训练时间、测试时间和参数量的比较
模型 训练时间(ms/单个样本) 测试时间(ms/单个样本) 参数量 SELF-MM[27] CMU-MOSI 4.86 CMU-MOSI 1.57 109 689 220 CMU-MOSEI 5.33 CMU-MOSEI 1.98 CH-SIMS 5.22 CH-SIMS 1.46 MTL-BAM[40] CMU-MOSI 6.33 CMU-MOSI 2.23 112 544 660 CMU-MOSEI 7.18 CMU-MOSEI 2.71 CH-SIMS / CH-SIMS / TAM-ULAG(本文) CMU-MOSI 3.33 CMU-MOSI 1.19 109 694 858 CMU-MOSEI 4.53 CMU-MOSEI 1.43 CH-SIMS 4.21 CH-SIMS 1.23
下载: 导出CSV
表 9 CMU-MOSI数据集上的实例分析
示例 原始标签 文本标签 音频标签 视觉标签
例1
–2.4 –2.47 –2.13 –1.75 例2 
1.8 2.33 –0.55 –0.89 例3 
1.8 2.1 1.2 –1.4
下载: 导出CSV
-
[1] 曾子明, 孙守强, 李青青. 基于融合策略的突发公共卫生事件网络舆情多模态负面情感识别[J]. 情报学报, 2023, 42(5): 611–622. doi: 10.3772/j.issn.1000-0135.2023.05.009.ZENG Ziming, SUN Shouqiang, and LI Qingqing. Multimodal negative sentiment recognition in online public opinion during public health emergencies based on fusion strategy[J]. Journal of the China Society for Scientific and Technical Information, 2023, 42(5): 611–622. doi: 10.3772/j.issn.1000-0135.2023.05.009. [2] 姚鸿勋, 邓伟洪, 刘洪海, 等. 情感计算与理解研究发展概述[J]. 中国图象图形学报, 2022, 27(6): 2008–2035. doi: 10.11834/jig.220085.YAO Hongxun, DENG Weihong, LIU Honghai, et al. An overview of research development of affective computing and understanding[J]. Journal of Image and Graphics, 2022, 27(6): 2008–2035. doi: 10.11834/jig.220085. [3] KUMAR P and RAMAN B. A BERT based dual-channel explainable text emotion recognition system[J]. Neural Networks, 2022, 150: 392–407. doi: 10.1016/j.neunet.2022.03.017. [4] 曾义夫, 蓝天, 吴祖峰, 等. 基于双记忆注意力的方面级别情感分类模型[J]. 计算机学报, 2019, 42(8): 1845–1857. doi: 10.11897/SP.J.1016.2019.01845.ZENG Yifu, LAN Tian, WU Zufeng, et al. Bi-memory based attention model for aspect level sentiment classification[J]. Chinese Journal of Computers, 2019, 42(8): 1845–1857. doi: 10.11897/SP.J.1016.2019.01845. [5] BAKHSHI A, HARIMI A, and CHALUP S. CyTex: Transforming speech to textured images for speech emotion recognition[J]. Speech Communication, 2022, 139: 62–75. doi: 10.1016/j.specom.2022.02.007. [6] 黄程韦, 赵艳, 金赟, 等. 实用语音情感的特征分析与识别的研究[J]. 电子与信息学报, 2011, 33(1): 112–116. doi: 10.3724/SP.J.1146.2009.00886.HUANG Chengwei, ZHAO Yan, JIN Yun, et al. A study on feature analysis and recognition of practical speech emotion[J]. Journal of Electronics & Information Technology, 2011, 33(1): 112–116. doi: 10.3724/SP.J.1146.2009.00886. [7] 杨杨, 詹德川, 姜远, 等. 可靠多模态学习综述[J]. 软件学报, 2021, 32(4): 1067–1081. doi: 10.13328/j.cnki.jos.0061670.YANG Yang, ZHAN Dechuan, JIANG Yuan, et al. Reliable multi-modal learning: A survey[J]. Journal of Software, 2021, 32(4): 1067–1081. doi: 10.13328/j.cnki.jos.0061670. [8] 韩卓群. 基于多模态融合的情感识别技术研究与实现[D]. [硕士论文], 山东大学, 2022. doi: 10.27272/d.cnki.gshdu.2022.004451.HAN Zhuoqun. Research and implementation of emotion recognition technology based on multimodal fusion[D]. [Master dissertation], Shandong University, 2022. doi: 10.27272/d.cnki.gshdu.2022.004451. [9] ZADEH A, CHEN Minghai, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis[C]. Proceedings of 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 2017: 1103–1114. doi: 10.18653/v1/D17-1115. [10] LIU Zhun, SHEN Ying, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2247–2256. doi: 10.18653/v1/P18-1209. [11] MAI Sijie, HU Haifeng, and XING Songlong. Modality to modality translation: An adversarial representation learning and graph fusion network for multimodal fusion[C]. Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 164–172. doi: 10.1609/aaai.v34i01.5347. [12] WU Yang, LIN Zijie, ZHAO Yanyan, et al. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis[C]. Proceedings of the Findings of the Association for Computational Linguistics, Virtual, 2021: 4730–4738. doi: 10.18653/v1/2021.findings-acl.417. [13] YU Wenmeng, XU Hua, MENG Fanyang, et al. CH-SIMS: A Chinese multimodal sentiment analysis dataset with fine-grained annotation of modality[C]. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 2020: 3718–3727. doi: 10.18653/v1/2020.acl-main.343. [14] ZADEH A A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2236–2246. doi: 10.18653/v1/P18-1208. [15] BALTRUŠAITIS T, AHUJA C, and MORENCY L P. Multimodal machine learning: A survey and taxonomy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 423–443. doi: 10.1109/TPAMI.2018.2798607. [16] 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479–1503. doi: 10.3778/j.issn.1673-9418.2112081.ZHAO Xiaoming, YANG Yijiao, and ZHANG Shiqing. Survey of deep learning based multimodal emotion recognition[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1479–1503. doi: 10.3778/j.issn.1673-9418.2112081. [17] KAUR R and KAUTISH S. Multimodal sentiment analysis: A survey and comparison[M]. Information Resources Management Association. Research Anthology on Implementing Sentiment Analysis Across Multiple Disciplines. IGI Global, 2022: 1846–1870. doi: 10.4018/978-1-6684-6303-1.ch098. [18] KAUR R and KAUTISH S. Multimodal sentiment analysis: A survey and comparison[J]. International Journal of Service Science Management Engineering and Technology, 2019, 10(2): 38–58. doi: 10.4018/IJSSMET.2019040103. [19] ZHANG J, XING L, TAN Z, et al. Multi-head attention fusion networks for multi-modal speech emotion recognition[J]. Computers & Industrial Engineering, 2022, 168: 108078. doi: doi: 10.1016/j.cie.2022.108078. [20] GHOSAL D, AKHTAR S, CHAUHAN D, et al. Contextual inter-modal attention for multi-modal sentiment analysis[C]. Proceedings of 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2018: 3454–3466. doi: 10.18653/v1/D18-1382. [21] MAI Sijie, HU Haifeng, and XING Songlong. Divide, conquer and combine: Hierarchical feature fusion network with local and global perspectives for multimodal affective computing[C]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 481–492. doi: 10.18653/v1/P19-1046. [22] MAI Sijie, XING Songlong, and HU Haifeng. Locally confined modality fusion network with a global perspective for multimodal human affective computing[J]. IEEE Transactions on Multimedia, 2020, 22(1): 122–137. doi: 10.1109/TMM.2019.2925966. [23] HE Jiaxuan, MAI Sijie, and HU Haifeng. A unimodal reinforced transformer with time squeeze fusion for multimodal sentiment analysis[J]. IEEE Signal Processing Letters, 2021, 28: 992–996. doi: 10.1109/LSP.2021.3078074. [24] 王汝言, 陶中原, 赵容剑, 等. 多交互图卷积网络用于方面情感分析[J]. 电子与信息学报, 2022, 44(3): 1111–1118. doi: 10.11999/JEIT210459.WANG Ruyan, TAO Zhongyuan, ZHAO Rongjian, et al. Multi-interaction graph convolutional networks for aspect-level sentiment analysis[J]. Journal of Electronics & Information Technology, 2022, 44(3): 1111–1118. doi: 10.11999/JEIT210459. [25] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. Proceedings of 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, 2019: 4171–4186. doi: 10.18653/v1/N19-1423. [26] SIRIWARDHANA S, KALUARACHCHI T, BILLINGHURST M, et al. Multimodal emotion recognition with transformer-based self supervised feature fusion[J]. IEEE Access, 2020, 8: 176274–176285. doi: 10.1109/ACCESS.2020.3026823. [27] YU Wenmeng, XU Hua, YUAN Ziqi, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis[C]. Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2021: 10790–10797. doi: 10.1609/aaai.v35i12.17289. [28] WANG Di, GUO Xutong, TIAN Yumin, et al. TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis[J]. Pattern Recognition, 2023, 136: 109259. doi: 10.1016/j.patcog.2022.109259. [29] ZENG Yufei, LI Zhixin, TANG Zhenjun, et al. Heterogeneous graph convolution based on In-domain Self-supervision for Multimodal Sentiment Analysis[J]. Expert Systems with Applications, 2023, 213: 119240. doi: 10.1016/j.eswa.2022.119240. [30] HWANG Y and KIM J H. Self-supervised unimodal label generation strategy using recalibrated modality representations for multimodal sentiment analysis[C]. Proceedings of the Findings of the Association for Computational Linguistics, Dubrovnik, Croatia, 2023: 35–46. doi: 10.18653/v1/2023.findings-eacl.2. [31] CHOI E, BAHADORI M T, KULAS J A, et al. RETAIN: An interpretable predictive model for healthcare using reverse time attention mechanism[C]. Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 3512–3520. [32] WANG Yansen, SHEN Ying, LIU Zhun, et al. Words can shift: Dynamically adjusting word representations using nonverbal behaviors[C]. Proceedings of 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 7216–7223. doi: 10.1609/aaai.v33i01.33017216. [33] PHAM H, LIANG P P, MANZINI T, et al. Found in translation: Learning robust joint representations by cyclic translations between modalities[C]. Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 6892–6899. doi: 10.1609/aaai.v33i01.33016892. [34] TSAI Y H H, BAI Shaojie, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]. Proceedings of the 57th Association for Computational Linguistics, Florence, Italy, 2019: 6558. doi: 10.18653/v1/P19-1656. [35] RAHMAN W, HASAN K, LEE S, et al. Integrating multimodal information in large pretrained transformers[C]. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 2020: 2359–2369. doi: 10.18653/v1/2020.acl-main.214. [36] ZHAO Xianbing, CHEN Yixin, CHEN Yiting, et al. HMAI-BERT: Hierarchical multimodal alignment and interaction network-enhanced BERT for multimodal sentiment analysis[C]. Proceedings of 2022 IEEE International Conference on Multimedia and Expo, Taipei, China, 2022: 1–6. doi: 10.1109/ICME52920.2022.9859747. [37] HAZARIKA D, ZIMMERMANN R, and PORIA S. MISA: Modality-invariant and-specific representations for multimodal sentiment analysis[C]. Proceedings of the 28th ACM International Conference on Multimedia, Seattle, United States, 2020: 1122–1131. doi: 10.1145/3394171.3413678. [38] HAN Wei, CHEN Hui, and PORIA S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis[C]. Proceedings of Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021: 9180–9192. doi: 10.18653/v1/2021.emnlp-main.723. [39] YU Yakun, ZHAO Mingjun, QI Shiang, et al. ConKI: Contrastive knowledge injection for multimodal sentiment analysis[C]. Proceedings of the Findings of the Association for Computational Linguistics, Toronto, Canada, 2023: 13610–13624. doi: 10.18653/v1/2023.findings-acl.860. [40] XIE Jinbao, WANG Jiyu, WANG Qingyan, et al. A multimodal fusion emotion recognition method based on multitask learning and attention mechanism[J]. Neurocomputing, 2023, 556: 126649. doi: 10.1016/j.neucom.2023.126649. [41] YANG Bo, SHAO Bo, WU Lijun, et al. Multimodal sentiment analysis with unidirectional modality translation[J]. Neurocomputing, 2022, 467: 130–137. doi: 10.1016/j.neucom.2021.09.041. [42] LAI Songning, HU Xifeng, LI Yulong, et al. Shared and private information learning in multimodal sentiment analysis with deep modal alignment and self-supervised multi-task learning[J]. arXiv preprint arXiv: 2305.08473, 2023. [43] YANG Bo, WU Lijun, ZHU Jinhua, et al. Multimodal sentiment analysis with two-phase multi-task learning[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2015–2024. doi: 10.1109/TASLP.2022.3178204. -


 下载:
下载:



图(4) / 表(10)
计量
- 文章访问数: 1610
- HTML全文浏览量: 1468
- PDF下载量: 157
- 被引次数: 0
