

Semi-paired Multi-modal Query Hashing Method
-
摘要: 多模态哈希能够将异构的多模态数据转化为联合的二进制编码串。由于其具有低存储成本、快速的汉明距离排序的优点,已经在大规模多媒体检索中受到了广泛的关注。现有的多模态哈希方法假设所有的询问数据都具备完整的多种模态信息以生成它们的联合哈希码。然而,实际应用中很难获得全完整的多模态信息,针对存在模态信息缺失的半配对询问场景,该文提出一种新颖的半配对询问哈希(SPQH),以解决半配对的询问样本的联合编码问题。首先,提出的方法执行投影学习和跨模态重建学习以保持多模态数据间的语义一致性。然后,标签空间的语义相似结构信息和多模态数据间的互补信息被有效地捕捉以学习判别性的哈希函数。在询问编码阶段,通过学习到的跨模态重构矩阵为未配对的样本数据补全缺失的模态特征,然后再经习得的联合哈希函数生成哈希特征。相比最先进的基线方法,在Pascal Sentence, NUS-WIDE和IAPR TC-12数据集上的平均检索精度提高了2.48%。实验结果表明该算法能够有效编码半配对的多模态询问数据,取得了优越的检索性能。Abstract: Multimodal hashing can convert heterogeneous multimodal data into unified binary codes. Due to its advantages of low storage cost and fast Hamming distance sorting, it has attracted widespread attention in large-scale multimedia retrieval. Existing multimodal hashing methods assume that all query data possess complete multimodal information to generate their joint hash codes. However, in practical applications, it is difficult to obtain fully complete multimodal information. To address the problem of missing modal information in semi-paired query scenarios, a novel Semi-paired Query Hashing (SPQH) method is proposed to solve the joint encoding problem of semi-paired query samples. Firstly, the proposed method performs projection learning and cross-modal reconstruction learning to maintain semantic consistency among multimodal data. Then, the semantic similarity structure information of the label space and complementary information among multimodal data are effectively captured to learn a discriminative hash function. During the query encoding stage, the missing modal features of unpaired sample data are completed using the learned cross-modal reconstruction matrix, and then the hash features are generated using the learned joint hash function. Compared to state-of-the-art baseline methods, the average retrieval accuracy on the Pascal Sentence, NUS-WIDE, and IAPR TC-12 datasets has improved by 2.48%. Experimental results demonstrate that the algorithm can effectively encode semi-paired multimodal query data and achieve superior retrieval performance.
-
Key words:
- Multimodal retrieval /
- Hashing /
- Semi-paired data /
- Cross-modal reconstruction /
- Binary codes
-
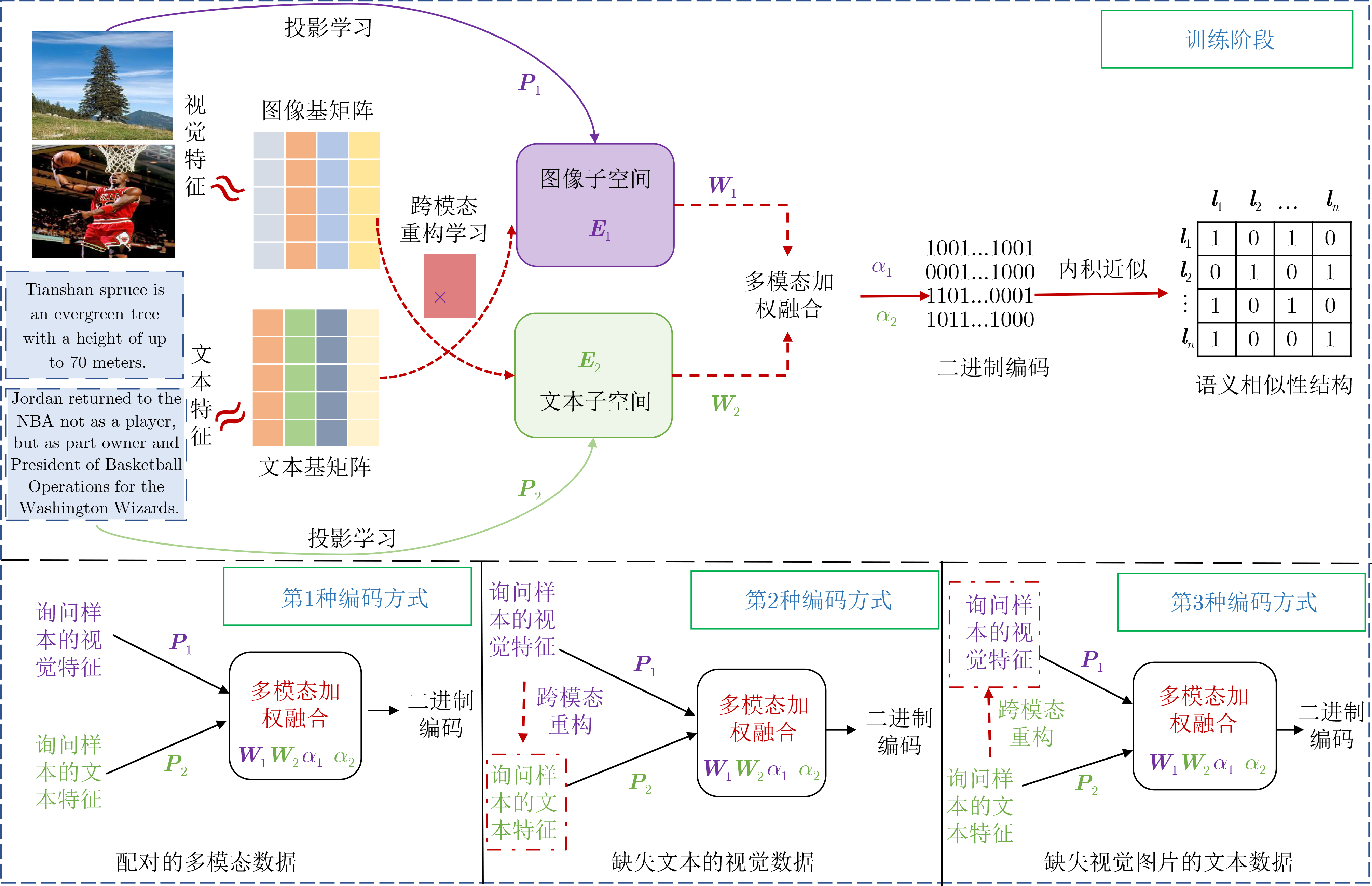
1 半配对的多模态询问哈希模型
输入:训练集${\boldsymbol{O}}= \left({\boldsymbol{y}}_1^{(1)},{\boldsymbol{y}}_1^{(2)},{\boldsymbol{l}}_1\right),\left({\boldsymbol{y}}_2^{(1)},{\boldsymbol{y}}_2^{(2)},{\boldsymbol{l}}_2\right),\cdots, $
$ \left({\boldsymbol{y}}_n^{(1)},{\boldsymbol{y}}_n^{(2)},{\boldsymbol{l}}_n \right) $,核特征表示矩阵:${{\boldsymbol{X}}_1},{{\boldsymbol{X}}_2} $.输出:${{\boldsymbol{P}}_1},{{\boldsymbol{P}}_2},{{\boldsymbol{U}}_1},{{\boldsymbol{U}}_2},{{\boldsymbol{W}}_1},{{\boldsymbol{W}}_2},{\alpha _m} $. ① 初始化${{\boldsymbol{U}}_1},{{\boldsymbol{U}}_2},{{\boldsymbol{E}}_1},{{\boldsymbol{E}}_2},{{\boldsymbol{W}}_1},{{\boldsymbol{W}}_2},{\boldsymbol{B}},{\alpha _1},{\alpha _2} $. ② for iter =1: $\xi $ do ③ 根据等式(5)和式(7)分别更新${{\boldsymbol{P}}_1} $和${{\boldsymbol{P}}_2} $; ④ 根据等式(9)和式(11)分别更新${{\boldsymbol{E}}_1} $和${{\boldsymbol{E}}_2} $; ⑤ 根据等式(13)和式(15)分别更新${{\boldsymbol{U}}_1} $和${{\boldsymbol{U}}_2} $; ⑥ 根据等式(17)和式(18)分别更新${{\boldsymbol{W}}_1} $和${{\boldsymbol{W}}_2} $; ⑦ 根据式(20)更新${\alpha _1} $和${\alpha _2} $; ⑧ 根据式(23)和式(24)更新${\boldsymbol{B}} $; ⑨ end for  下载: 导出CSV
下载: 导出CSV
表 1 3个基准数据集的统计数据
数据集 Pascal Sentence NUS-WIDE IAPR TC-12 数据集的大小 1 000 186 577 20 000 训练集大小 600 5 000 5 000 检索集大小 600 186 577 18 000 测试集大小 400 1 866 2 000 类别数目 20 10 255
下载: 导出CSV
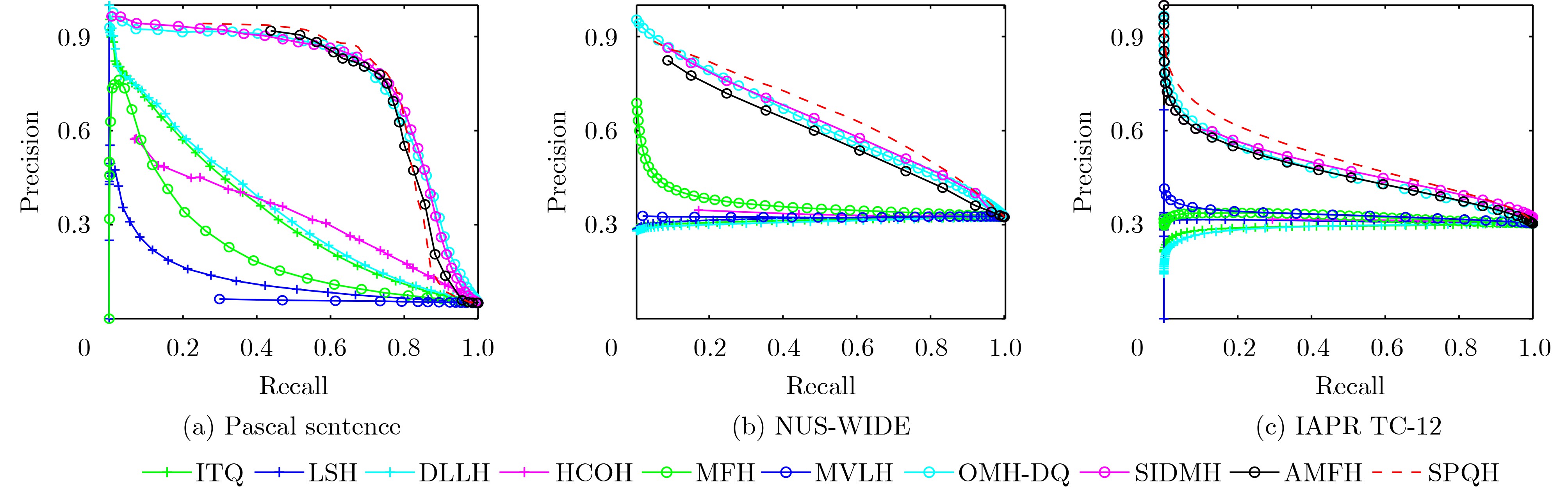
表 2 完全配对的询问场景下不同比特长度的多模态检索任务的mAP比较
任务 方法 Pascal Sentence NUS-WIDE IAPR TC-12 16 32 64 128 16 32 64 128 16 32 64 128
O2OITQ 0.3602 0.3523 0.3675 0.3803 0.3724 0.3751 0.3776 0.3789 0.3730 0.3844 0.3936 0.4020 LSH 0.1011 0.1243 0.1572 0.2129 0.3421 0.3554 0.3544 0.3672 0.3251 0.3363 0.3509 0.3686 DLLH 0.3631 0.3720 0.3971 0.3959 0.3738 0.3782 0.3794 0.3823 0.3644 0.3796 0.3863 0.3868 HCOH 0.2135 0.4812 0.4846 0.4860 0.3232 0.3451 0.3434 0.3645 0.3082 0.3581 0.3717 0.3712 MFH 0.1834 0.2399 0.2729 0.2731 0.3673 0.3752 0.3803 0.3815 0.3263 0.3374 0.3435 0.3451 MVLH 0.1192 0.1347 0.1200 0.1202 0.3363 0.3339 0.3324 0.3284 0.3394 0.3401 0.3409 0.3499 OMH-DQ 0.4177 0.6719 0.7414 0.7622 0.5223 0.5381 0.5823 0.5957 0.3949 0.4200 0.4446 0.4642 SIDMH 0.6681 0.7479 0.7596 0.7660 0.5828 0.5976 0.6055 0.6120 0.4131 0.4277 0.4364 0.4706 AMFH 0.6837 0.7501 0.7511 0.7519 0.6190 0.6240 0.6271 0.6385 0.4198 0.4374 0.4571 0.4887 SPQH_all 0.5176 0.7641 0.7799 0.7689 0.6208 0.6269 0.6353 0.6410 0.4060 0.4601 0.4691 0.4964
下载: 导出CSV
表 4 Pascal Sentence数据集上SPQH与深度方法的mAP比较
方法 哈希编码长度 32 64 128 DMHOR 0.5930 0.6693 0.6860 DMVH 0.5301 0.6010 0.6720 SIDMH 0.7479 0.7596 0.7660 FGCMH 0.7089 0.7433 0.7511 SPQH_all 0.7641 0. 7799 0.7689
下载: 导出CSV
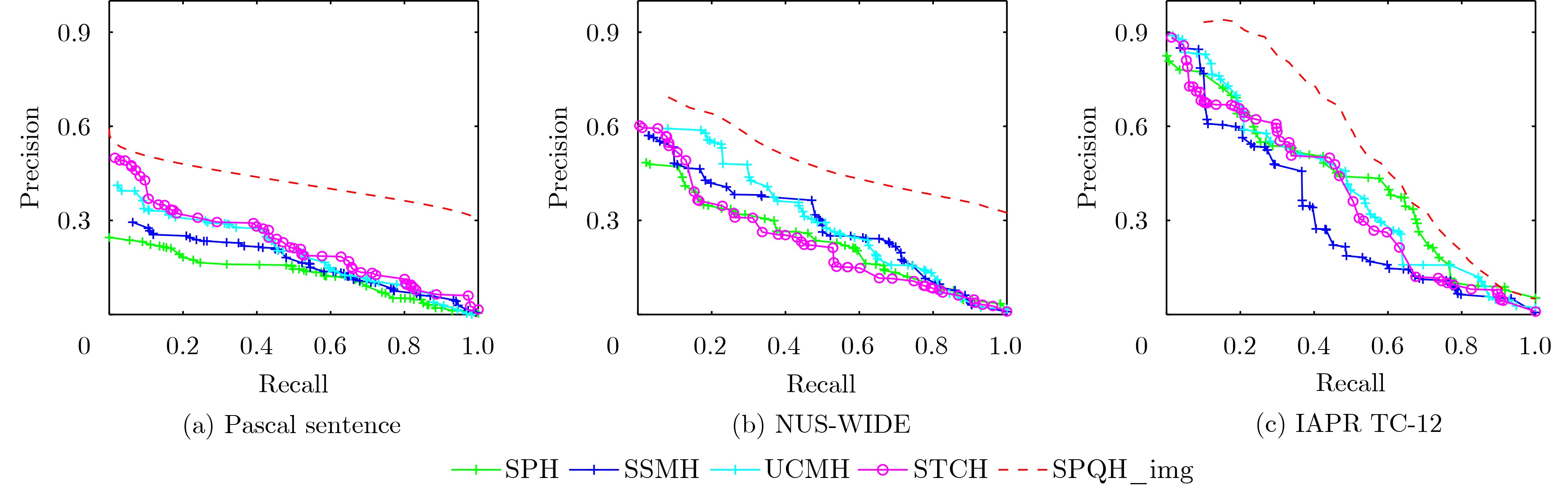
表 3 完全未配对的询问场景下不同比特长度的多模态检索任务的mAP比较
任务 方法 Pascal Sentence NUS-WIDE IAPR TC-12 16 32 64 128 16 32 64 128 16 32 64 128
I2ISPH 0.2425 0.2839 0.2919 0.3034 0.3142 0.3210 0.3465 0.3609 0.3352 0.3500 0.3634 0.3798 SSMH 0.2600 0.3240 0.3499 0.3817 0.3468 0.3591 0.3877 0.4047 0.3258 0.3528 0.3503 0.3699 UCMH 0.2766 0.3908 0.4778 0.5119 0.3500 0.3588 0.4051 0.4166 0.3487 0.3744 0.3795 0.3798 STCH 0.2999 0.4126 0.4953 0.5648 0.3589 0.3603 0.3926 0.4260 0.3561 0.3807 0.3822 0.3912 SPQH_img 0.3168 0.4533 0.5996 0.6111 0.3597 0.3612 0.4286 0.4319 0.3777 0.3823 0.3902 0.4003
T2TSPH 0.3717 0.3958 0.4122 0.4534 0.4017 0.4128 0.4203 0.4399 0.2922 0.3021 0.3448 0.3485 SSMH 0.3916 0.4443 0.4929 0.5341 0.5322 0.5538 0.5727 0.5894 0.3306 0.3529 0.3674 0.3879 UCMH 0.4633 0.5324 0.5911 0.6317 0.5512 0.5677 0.5824 0.5878 0.3527 0.3742 0.3922 0.4157 STCH 0.4718 0.6377 0.6651 0.6818 0.5677 0.6025 0.6148 0.6281 0.3789 0.3879 0.4206 0.4379 SPQH_txt 0.5058 0.7433 0.7578 0.7600 0.5801 0.6199 0.6312 0.6327 0.3801 0.4054 0.4377 0.4416
下载: 导出CSV
表 5 语义结构保持项的消融实验
方法 Pascal Sentence NUS-WIDE IAPR TC-12 SPQH-DSP 0.4614 0.4166 0.3949 SPQH 0.7799 0.6353 0.4691
下载: 导出CSV
表 6 SPQH在询问阶段基于不同模态特征编码的mAP比较
方法(询问数据的特征类型) Pascal Sentence NUS-WIDE IAPR
TC-12SPQH1 (文本特征) 0.6159 0.4702 0.4162 SPQH_txt (文本特征+
伪图片特征)0.7578 0.6312 0.4377 SPQH2 (图片特征) 0.4837 0.4023 0.3680 SPQH_img (图片特征+
伪文本特征)0.5996 0.4286 0.3902 SPQH_all (图片特征+
文本特征)0.7799 0.6353 0.4691
下载: 导出CSV
-
[1] GEETHA V and SUJATHA N. A survey on divergent classification of social media networking[C]. 2022 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 2022: 203–207. doi: 10.1109/ICCCIS56430.2022.10037606. [2] 顾广华, 霍文华, 苏明月, 等. 基于非对称监督深度离散哈希的图像检索[J]. 电子与信息学报, 2021, 43(12): 3530–3537. doi: 10.11999/JEIT200988.GU Guanghua, HUO Wenhua, SU Mingyue, et al. Asymmetric supervised deep discrete hashing based image retrieval[J]. Journal of Electronics & Information Technology, 2021, 43(12): 3530–3537. doi: 10.11999/JEIT200988. [3] GONG Yunchao, LAZEBNIK S, GORDO A, et al. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2916–2929. doi: 10.1109/TPAMI.2012.193. [4] DATAR M, IMMORLICA N, INDYK P, et al. Locality-sensitive hashing scheme based on p-stable distributions[C]. The 20th Annual Symposium on Computational Geometry, Brooklyn, USA, 2004: 253–262. doi: 10.1145/997817.997857. [5] SHEN Fumin, SHEN Chunhua, LIU Wei, et al. Supervised discrete hashing[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 37–45. doi: 10.1109/CVPR.2015.7298598. [6] JI Rongrong, LIU Hong, CAO Liujuan, et al. Toward optimal manifold hashing via discrete locally linear embedding[J]. IEEE Transactions on Image Processing, 2017, 26(11): 5411–5420. doi: 10.1109/TIP.2017.2735184. [7] KOUTAKI G, SHIRAI K, and AMBAI M. Hadamard coding for supervised discrete hashing[J]. IEEE Transactions on Image Processing, 2018, 27(11): 5378–5392. doi: 10.1109/TIP.2018.2855427. [8] LIN Mingbao, JI Rongrong, LIU Hong, et al. Supervised online hashing via hadamard codebook learning[C]. The 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 2018: 1635–1643. doi: 10.1145/3240508.3240519. [9] LIN Mingbao, JI Rongrong, CHEN Shen, et al. Similarity-preserving linkage hashing for online image retrieval[J]. IEEE Transactions on Image Processing, 2020, 29: 5289–5300. doi: 10.1109/TIP.2020.2981879. [10] JIN Lu, LI Zechao, PAN Yonghua, et al. Weakly-supervised image hashing through masked visual-semantic graph-based reasoning[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 916–924. doi: 10.1145/3394171.3414022. [11] LI Zechao, TANG Jinhui, ZHANG Liyan, et al. Weakly-supervised semantic guided hashing for social image retrieval[J]. International Journal of Computer Vision, 2020, 128(8/9): 2265–2278. doi: 10.1007/s11263-020-01331-0. [12] SONG Jingkuan, YANG Yi, HUANG Zi, et al. Effective multiple feature hashing for large-scale near-duplicate video retrieval[J]. IEEE Transactions on Multimedia, 2013, 15(8): 1997–2008. doi: 10.1109/TMM.2013.2271746. [13] SHEN Xiaobo, SHEN Fumin, SUN Quansen, et al. Multi-view latent hashing for efficient multimedia search[C]. The 23rd ACM International Conference on Multimedia, Brisbane, Australia, 2015: 831–834. doi: 10.1145/2733373.2806342. [14] LIU Li, YU Mengyang, and SHAO Ling. Multiview alignment hashing for efficient image search[J]. IEEE Transactions on Image Processing, 2015, 24(3): 956–966. doi: 10.1109/TIP.2015.2390975. [15] LU Xu, LIU Li, NIE Liqiang, et al. Semantic-driven interpretable deep multi-modal hashing for large-scale multimedia retrieval[J]. IEEE Transactions on Multimedia, 2021, 23: 4541–4554. doi: 10.1109/TMM.2020.3044473. [16] YU Jun, HUANG Wei, LI Zuhe, et al. Hadamard matrix-guided multi-modal hashing for multi-modal retrieval[J]. Digital Signal Processing, 2022, 130: 103743. doi: 10.1016/j.dsp.2022.103743. [17] 庾骏, 黄伟, 张晓波, 等. 基于松弛Hadamard矩阵的多模态融合哈希方法[J]. 电子学报, 2022, 50(4): 909–920. doi: 10.12263/DZXB.20210760.YU Jun, HUANG Wei, ZHANG Xiaobo, et al. Multimodal fusion hash learning method based on relaxed Hadamard matrix[J]. Acta Electronica Sinica, 2022, 50(4): 909–920. doi: 10.12263/DZXB.20210760. [18] LU Xu, ZHU Lei, CHENG Zhiyong, et al. Online multi-modal hashing with dynamic query-adaption[C]. The 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 2019: 715–724. doi: 10.1145/3331184.3331217. [19] YU Jun, ZHANG Donglin, SHU Zhenqiu, et al. Adaptive multi-modal fusion hashing via hadamard matrix[J]. Applied Intelligence, 2022, 52(15): 17170–17184. doi: 10.1007/s10489-022-03367-w. [20] SHEN Xiaobo, SUN Quansen, and YUAN Yunhao. Semi-paired hashing for cross-view retrieval[J]. Neurocomputing, 2016, 213: 14–23. doi: 10.1016/j.neucom.2016.01.121. [21] WANG Di, SHANG Bin, WANG Quan, et al. Semi-paired and semi-supervised multimodal hashing via cross-modality label propagation[J]. Multimedia Tools and Applications, 2019, 78(17): 24167–24185. doi: 10.1007/s11042-018-6858-8. [22] GAO Jing, ZHANG Wenjun, ZHONG Fangming, et al. UCMH: Unpaired cross-modal hashing with matrix factorization[J]. Neurocomputing, 2020, 418: 178–190. doi: 10.1016/j.neucom.2020.08.029. [23] JING Rongrong, TIAN Hu, ZHANG Xingwei, et al. Self-Training based semi-Supervised and semi-Paired hashing cross-modal retrieval[C]. 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 2022: 1–8. doi: 10.1109/IJCNN55064.2022.9892301. [24] RASHTCHIAN C, YOUNG P, HODOSH M, et al. Collecting image annotations using amazon’s mechanical Turk[C]. The NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, Los Angeles, America, 2010: 139–147. [25] CHUA T S, TANG Jinhui, HONG Richang, et al. NUS-WIDE: A real-world web image database from national university of Singapore[C]. The ACM International Conference on Image and Video Retrieval, Santorini, Greece, 2009: 48. doi: 10.1145/1646396.1646452. [26] ESCALANTE H J, HERNÁNDEZ C A, GONZALEZ J A, et al. The segmented and annotated IAPR TC-12 benchmark[J]. Computer Vision and Image Understanding, 2010, 114(4): 419–428. doi: 10.1016/j.cviu.2009.03.008. [27] WANG Daixin, CUI Peng, OU Mingdong, et al. Deep multimodal hashing with orthogonal regularization[C]. The 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 2015: 2291–2297. [28] YANG Rui, SHI Yuliang, and XU Xinshun. Discrete multi-view hashing for effective image retrieval[C]. 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 2017: 175–183. doi: 10.1145/3078971.3078981. [29] LU Xu, ZHU Lei, LIU Li, et al. Graph convolutional multi-modal hashing for flexible multimedia retrieval[C/OL]. The 29th ACM International Conference on Multimedia, Chengdu, China, 2021: 1414–1422. doi: 10.1145/3474085.3475598. -

 下载:
下载:

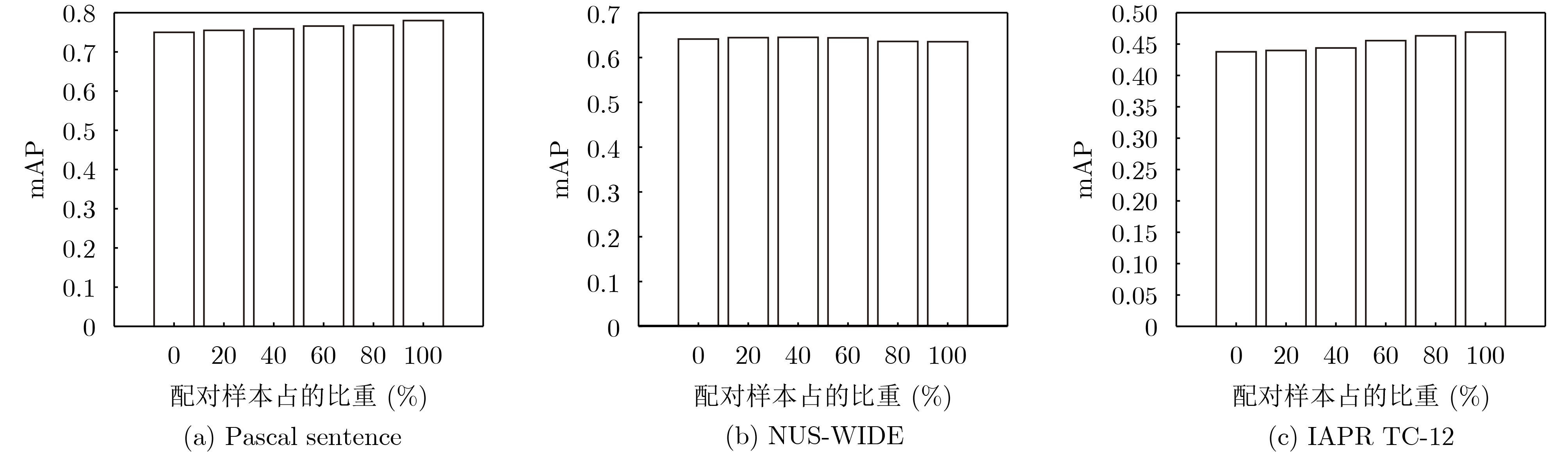



图(7) / 表(7)
计量
- 文章访问数: 736
- HTML全文浏览量: 680
- PDF下载量: 59
- 被引次数: 0
