

Research on Intelligent Spectrum Allocation Techniques for Incomplete Electromagnetic Information
-
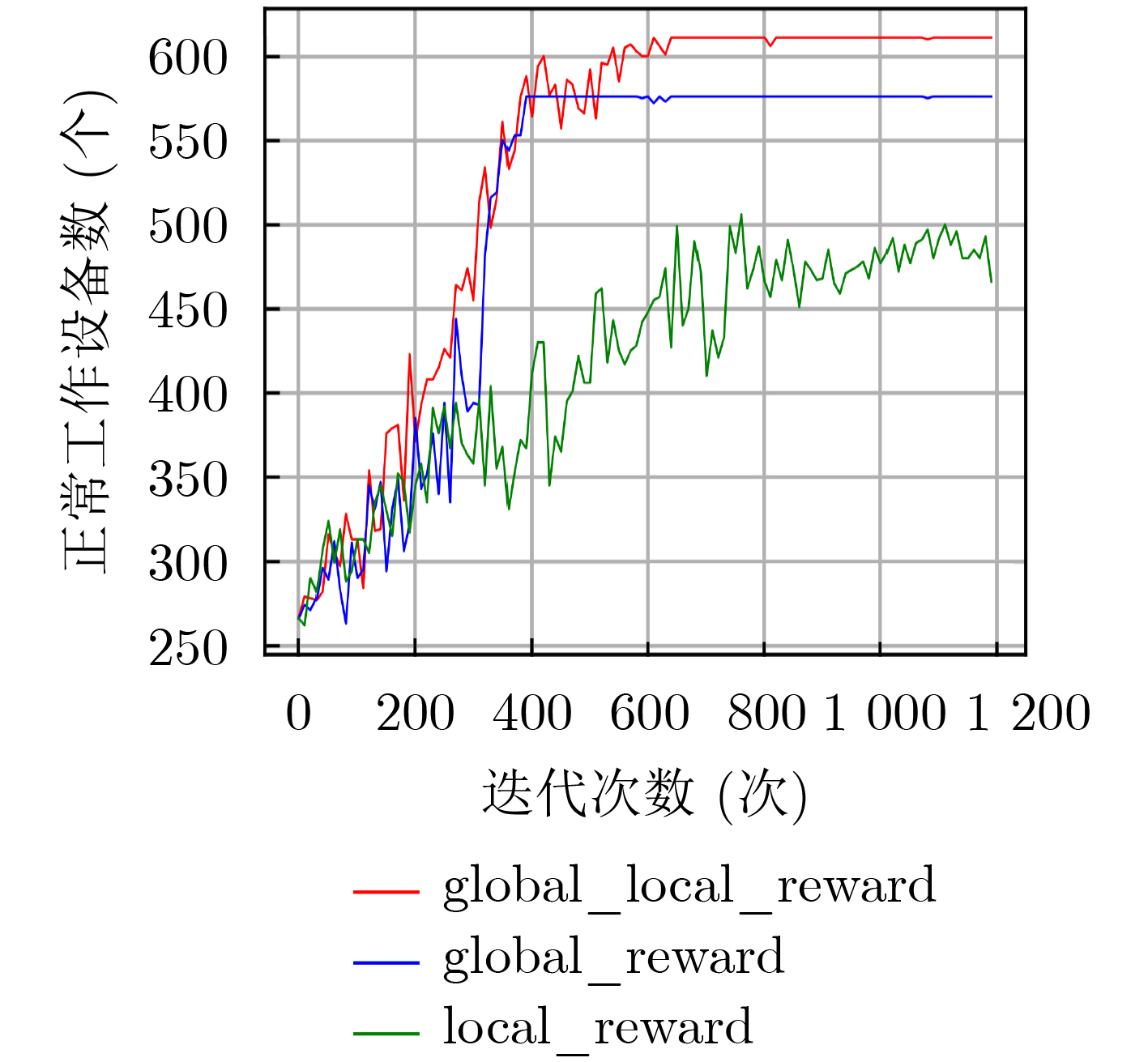
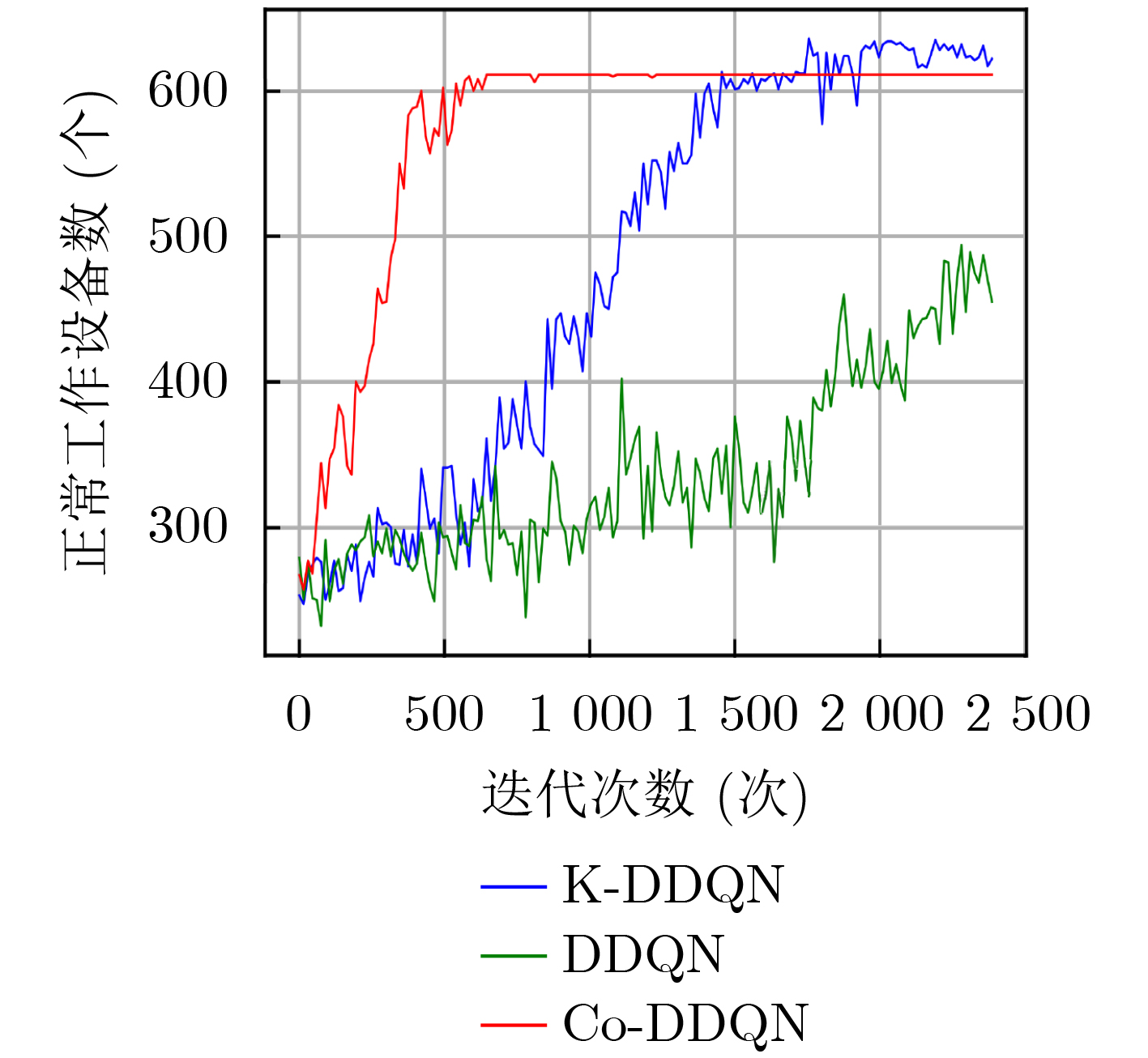
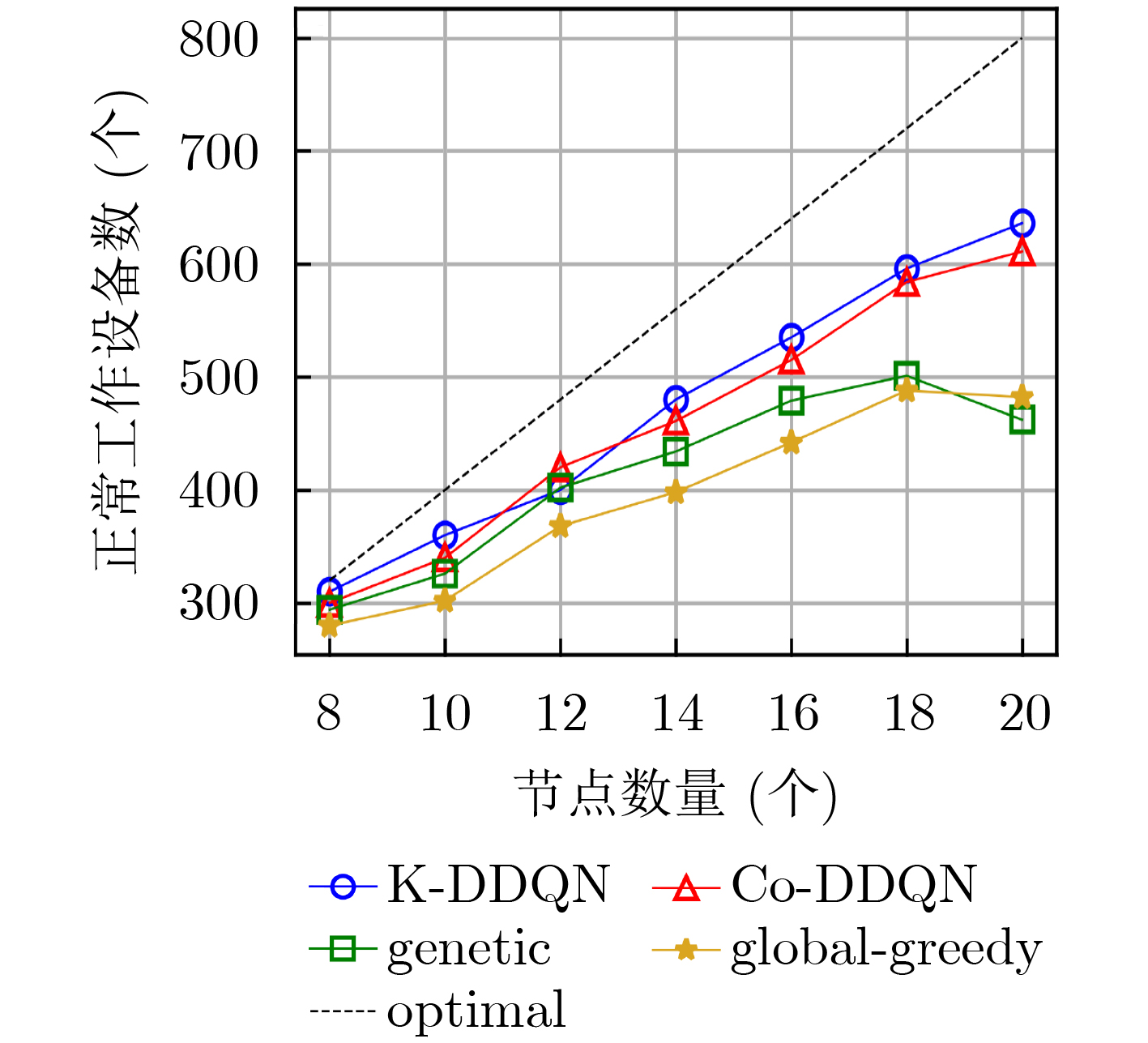
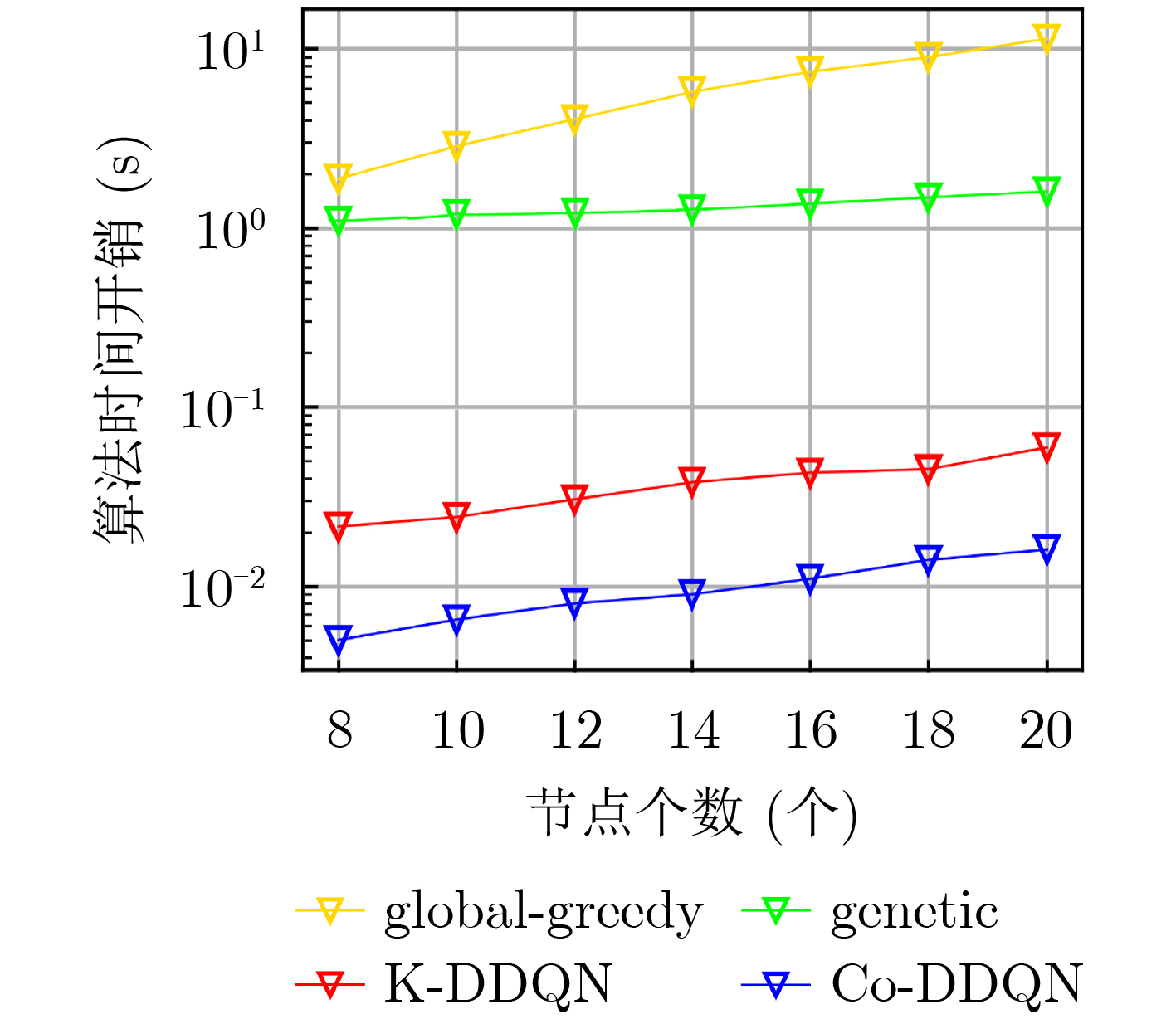
摘要: 针对电磁对抗过程中环境动态变化,多节点自主用频决策频谱利用率低的问题,该文开展面向非完全电磁信息的智能协同频谱分配技术研究,通过多节点智能协同提升频谱利用率。首先将复杂电磁环境频谱分配问题建模为最大化用频设备的优化问题,其次提出一种基于多节点协同分流经验回放机制的资源决策算法(Co-DDQN),算法基于协同分流函数对历史经验数据进行评估,并通过分级经验池进行训练,使各智能体在仅观测自身状态信息条件下形成轻量级协同决策能力,解决低视度条件下多节点决策优化方向与整体优化目标不一致的问题,提升频谱利用率;设计了一种基于置信分配的混合奖励函数,各节点决策兼顾个体的奖励,能够减少惰性节点的出现,探索更优的整体动作策略,进一步提升系统效益。仿真结果表明:当节点数为20时,所提算法的可接入设备数优于全局贪婪算法与遗传算法,并与信息完全共享的集中式频谱分配算法的差距在5%内,更适用于低视度节点的协同频谱分配。Abstract: To solve the problem of low spectrum utilization of multi-node autonomous frequency decision-making in the dynamic electromagnetic countermeasure environment, the research on intelligent cooperative spectrum allocation technology for in complete electromagnetic information is carried out, which improves spectrum utilization through multi-node intelligent collaboration. Firstly, the spectrum allocation problem is modelled as an optimization problem to maximize the frequency-using equipment, and secondly, a resource decision-making algorithm based on the multi-node cooperative diversion experience repetition mechanism (Cooperation- Deep double Q-network, Co-DDQN) is proposed. This algorithm evaluates the historical experience data based on the cooperative diversion function and is trained by a hierarchical experience pool, so that each agent can form a lightweight cooperative decision-making ability under self-observation, and solve the problem of inconsistency between the optimization direction of multi-node decision-making and the overall optimization goal under low-visibility conditions. Besides, a hybrid reward function based on confidence allocation is designed, and each node considers itself when the decision is made, which can reduce the emergence of lazy nodes, explore a better overall action strategy, and further improve the system efficiency. Simulation results show that when the number of nodes is 20, the number of accessible devices of the proposed algorithm outperforms the global greedy algorithm and the genetic algorithm, and the difference with the centralized spectrum allocation algorithm with complete information sharing is within 5%, which is more suitable for cooperative spectrum allocation of low-visibility nodes.
-
表 1 系统参数
参数 含义 M 作战空间范围 T 整个战时时隙数 f 电磁环境中正交子信道 B 信道带宽 $ {P^{{\mathrm{r}}}} $ 雷达设备发射功率 $ {P^{{\mathrm{c}}}} $ 通信设备发射功率 $ {P^{{\mathrm{e}}}} $ 敌方设备发射功率 $ {N_t} $ t时隙环境中的噪声功率 $ g_{n{,{\mathrm{c}}}}^{{{\mathrm{com}}}} $ 节点n中的通信设备至控制中心c的信道增益 $ g_{n,n'}^{{{\mathrm{com}}}} $ 节点n中的通信设备至其余节点$ n' $的信道增益 $ g_{n{,{\mathrm{c}}}}^{{{\mathrm{rad}}}} $ 节点n中的雷达设备至控制中心c的信道增益 $ g_{n,n'}^{{{\mathrm{rad}}}} $ 节点n中的雷达设备至其余节点$ n' $的信道增益 $ {g_{{\mathrm{e}}{,}n}} $ 敌方设备e至节点n的信道增益 $ {g_{{\mathrm{e}}{\text{,}}{\mathrm{c}}}} $ 敌方设备e至控制中心c的信道增益 $ P_{\min }^{\text{e}} $ 雷达最小可检测功率  下载: 导出CSV
下载: 导出CSV
1 Co-DDQN算法
1: 环境初始化;构建DDQN神经网络,设置目标Q网络中参数的
更新频率为$ {T}_{\mathrm{f}\mathrm{r}\mathrm{e}} $2:for each episode do: 3: $ t=0 $ /*初始化时间系数*/ 4: for each mini-episode do: 5: $ {{\boldsymbol{s}}}_{t}^{n} $,$ {{\boldsymbol{a}}}_{t}^{n} $ /*各节点n感知自身状态信息并根据
$ \varepsilon {\text{-}}\mathrm{g}\mathrm{r}\mathrm{e}\mathrm{e}\mathrm{d}\mathrm{y} $策略输出各节点策略*/6: ${\boldsymbol{A}}_t^n \leftarrow \{ {\boldsymbol{a}}_t^1,{\boldsymbol{a}}_t^2,\cdots,{\boldsymbol{a}}_t^n| n\in N\} $ /*联合所有节点策略进行
资源分配,与环境交互获取奖励*/7: $ {{\boldsymbol{S}}}_{t+1} $; $ {\mathrm{R}\mathrm{W}}_{t} $ /*更新环境状态;获取系统总收益*/ 8: $ {{\boldsymbol{s}}}_{t+1}^{n} $; $ {\mathrm{r}\mathrm{w}}_{t}^{n} $ /*各节点感知自身状态信息;获取自身奖励*/ 9: 将经验样本存入各节点的经验池 10: $ {D}^{1\mathrm{s}\mathrm{t}},{D}^{2\mathrm{n}\mathrm{d}},{D}^{3\mathrm{r}\mathrm{d}} $ /*各节点建立3种经验池*/ 11: 根据3.2.1节协同分流函数对经验进行评估分流 12: $ {\mathrm{loss}} $ /*基于 $ {D}^{1\mathrm{s}\mathrm{t}},{D}^{2\mathrm{n}\mathrm{d}},{D}^{3\mathrm{r}\mathrm{d}} $计算损失函数*/ 13: $ \stackrel{~}{\theta }\leftarrow \theta $ /*使用不同学习率$ {{\mathrm{lr}}}_{L}={\alpha {\mathrm{lr}}}_{M}={\alpha }^{2}{{\mathrm{lr}}}_{S} $更新网
络参数*/14: $ t\leftarrow t+1 $ /*进入下一时隙*/ 15: end 16: if $ \mathrm{e}\mathrm{p}\mathrm{i}\mathrm{s}\mathrm{o}\mathrm{d}\mathrm{e}\%{T}_{\mathrm{f}\mathrm{r}\mathrm{e}}==0 $: 17: 复制当前网络参数至目标Q网络 18:end
下载: 导出CSV
-
[1] 王沙飞, 鲍雁飞, 李岩. 认知电子战体系结构与技术[J]. 中国科学: 信息科学, 2018, 48(12): 1603–1613. doi: 10.1360/N112018- 00153.WANG Shafei, BAO Yanfei, and LI Yan. The architecture and technology of cognitive electronic warfare[J]. SCIENTIA SINICA Informationis, 2018, 48(12): 1603–1613. doi: 10.1360/N112018-00153. [2] 唐建强, 李昊. 美军电磁战斗管理发展分析[J]. 电子信息对抗技术, 2020, 35(2): 39–43. doi: 10.3969/j.issn.1674-2230.2020.02.010.TANG Jianqiang and LI Hao. The analysis of electromagnetic battle management in US[J]. Electronic Information Warfare Technology, 2020, 35(2): 39–43. doi: 10.3969/j.issn.1674-2230.2020.02.010. [3] 刘辉, 颜飙, 陈永丽. 基于超图的D2D多对多资源分配方案[J]. 计算机工程与设计, 2018, 39(12): 3605–3609,3621. doi: 10.16208/j.issn1000-7024.2018.12.002.LIU Hui, YAN Biao, and CHEN Yongli. Many-to-many resource allocation scheme for D2D based on hypergraph[J]. Computer Engineering and Design, 2018, 39(12): 3605–3609,3621. doi: 10.16208/j.issn1000-7024.2018.12.002. [4] 蔡畅, 王亚芳, 苗兵梅, 等. 基于改进遗传算法的认知无线传感网动态频谱分配方案[J]. 电信科学, 2017, 33(8): 85–93. doi: 10.11959/j.issn.1000-0801.2017217.CAI Chang, WANG Yafang, MIAO Bingmei, et al. Dynamic spectrum allocation for cognitive radio sensor networks based on improved genetic algorithm[J]. Telecommunications Science, 2017, 33(8): 85–93. doi: 10.11959/j.issn.1000-0801.2017217. [5] HUANG Jun, XING Congcong, QIAN Yi, et al. Resource allocation for multicell device-to-device communications underlaying 5G networks: A game-theoretic mechanism with incomplete information[J]. IEEE Transactions on Vehicular Technology, 2018, 67(3): 2557–2570. doi: 10.1109/TVT.2017.2765208. [6] YANG Helin, ZHAO Jun, LAM K Y, et al. Distributed deep reinforcement learning-based spectrum and power allocation for heterogeneous networks[J]. IEEE Transactions on Wireless Communications, 2022, 21(9): 6935–6948. doi: 10.1109/TWC.2022.3153175. [7] SI Jiangbo, HUANG Rui, LI Zan, et al. When spectrum sharing in cognitive networks meets deep reinforcement learning: Architecture, fundamentals, and challenges[J]. IEEE Network, 2024, 38(1): 187–195. doi: 10.1109/MNET.130.2200390. [8] MENG Fan, CHEN Peng, WU Lenan, et al. Power allocation in multi-user cellular networks: Deep reinforcement learning approaches[J]. IEEE Transactions on Wireless Communications, 2020, 19(10): 6255–6267. doi: 10.1109/TWC.2020.3001736. [9] 赵浩钦, 杨政, 司江勃, 等. 一种聚类辅助的智能频谱分配技术研究[J]. 西安电子科技大学学报, 2023, 50(6): 1–12. doi: 10.19665/j.issn1001-2400.20231006.ZHAO Haoqin, YANG Zheng, SI Jiangbo, et al. Research on a clustering-assisted intelligent spectrum allocation technique[J]. Journal of Xidian University, 2023, 50(6): 1–12. doi: 10.19665/j.issn1001-2400.20231006. [10] 王涵, 俞扬, 姜远. 基于通信的多智能体强化学习进展综述[J]. 中国科学: 信息科学, 2022, 52(5): 742–764. doi: 10.1360/SSI-2020-0180.WANG Han, YU Yang, and JIANG Yuan. Review of the progress of communication-based multi-agent reinforcement learning[J]. SCIENTIA SINICA Informationis, 2022, 52(5): 742–764. doi: 10.1360/SSI-2020-0180. [11] TAN Junjie, LIANG Yingchang, ZHANG Lin, et al. Deep reinforcement learning for joint channel selection and power control in D2D networks[J]. IEEE Transactions on Wireless Communications, 2021, 20(2): 1363–1378. doi: 10.1109/TWC.2020.3032991. [12] YIN Ziyan, LIN Yan, ZHANG Yijin, et al. Collaborative multiagent reinforcement learning aided resource allocation for UAV anti-Jamming communication[J]. IEEE Internet of Things Journal, 2022, 9(23): 23995–24008. doi: 10.1109/JIOT.2022.3188833. [13] 窦慧, 张凌茗, 韩峰, 等. 卷积神经网络的可解释性研究综述[J]. 软件学报, 2024, 35(1): 159–184. doi: 10.13328/j.cnki.jos.006758.DOU Hui, ZHANG Lingming, HAN Feng, et al. Survey on convolutional neural network interpretability[J]. Journal of Software, 2024, 35(1): 159–184. doi: 10.13328/j.cnki.jos.006758. [14] 肖博, 霍凯, 刘永祥. 雷达通信一体化研究现状与发展趋势[J]. 电子与信息学报, 2019, 41(3): 739–750. doi: 10.11999/JEIT180515.XIAO Bo, HUO Kai, and LIU Yongxiang. Development and prospect of radar and communication integration[J]. Journal of Electronics & Information Technology, 2019, 41(3): 739–750. doi: 10.11999/JEIT180515. [15] TANG Qinqin, XIE Renchao, YU F R, et al. Decentralized computation offloading in IoT fog computing system with energy harvesting: A Dec-POMDP approach[J]. IEEE Internet of Things Journal, 2020, 7(6): 4898–4911. doi: 10.1109/JIOT.2020.2971323. [16] VAN HASSELT H, GUEZ A, and SILVER D. Deep reinforcement learning with double Q-learning[C]. The 30th AAAI Conference on Artificial Intelligence, Phoenix, USA, 2016: 2094–2100. doi: 10.5555/3016100.3016191. -

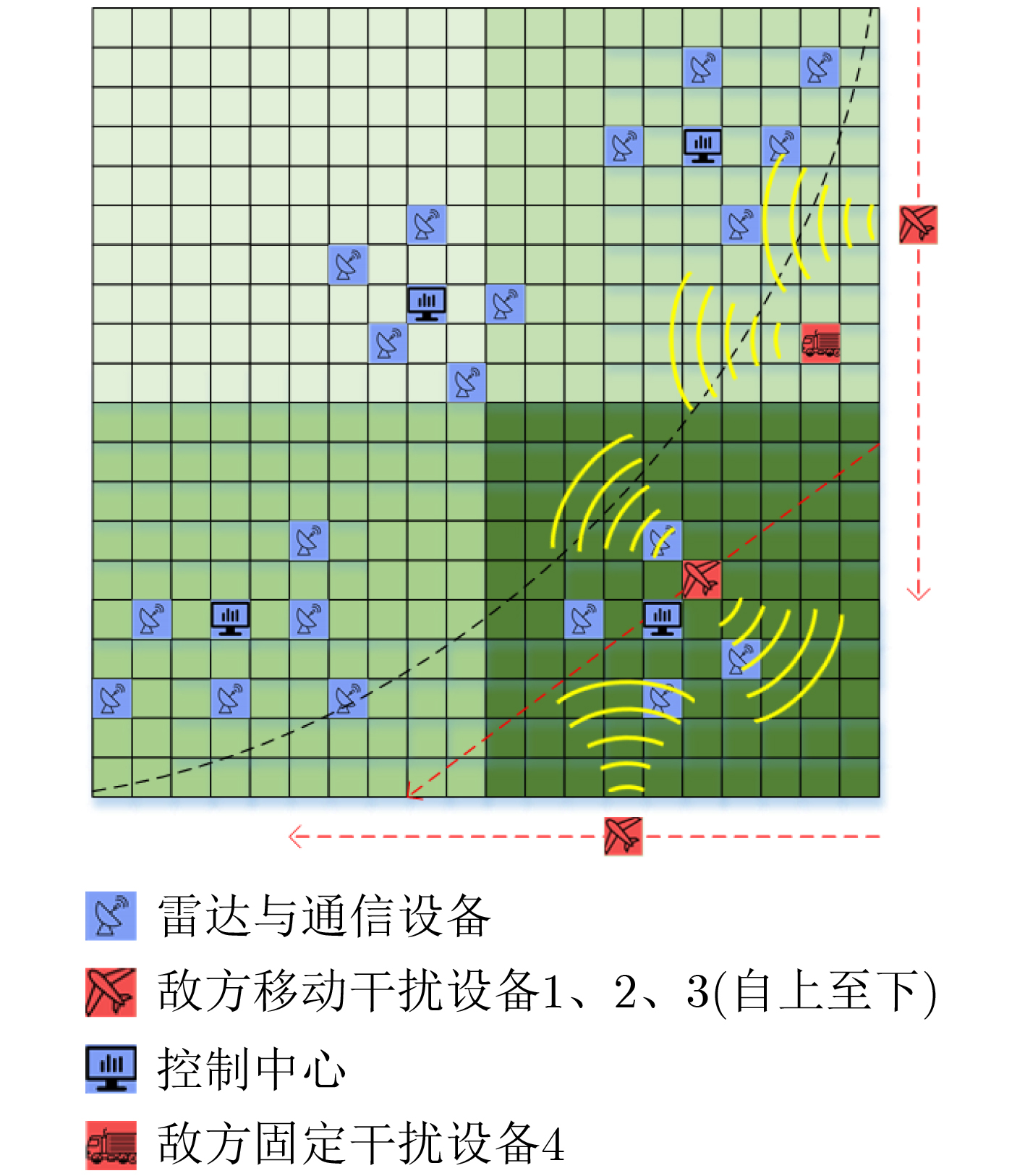
 下载:
下载:
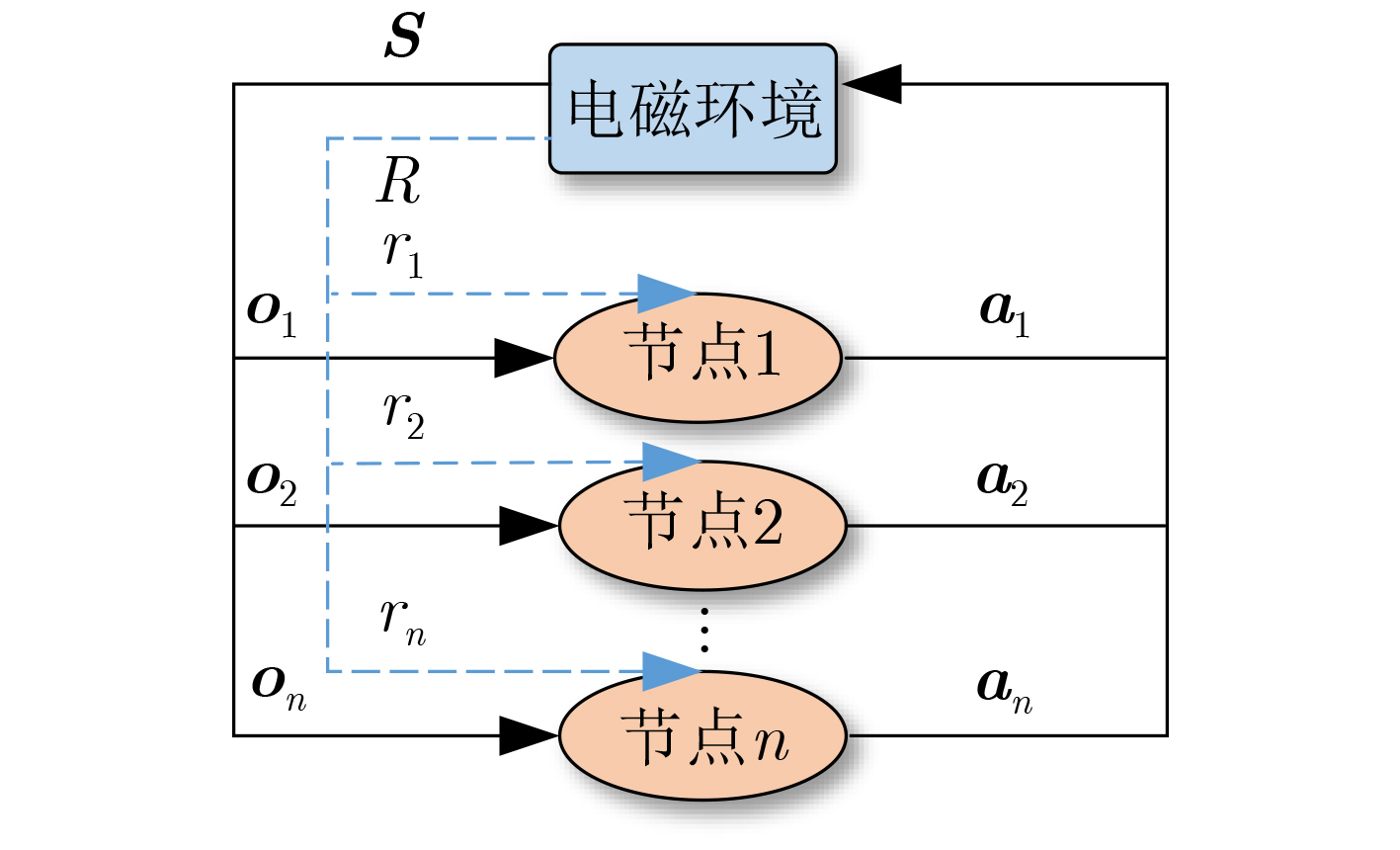
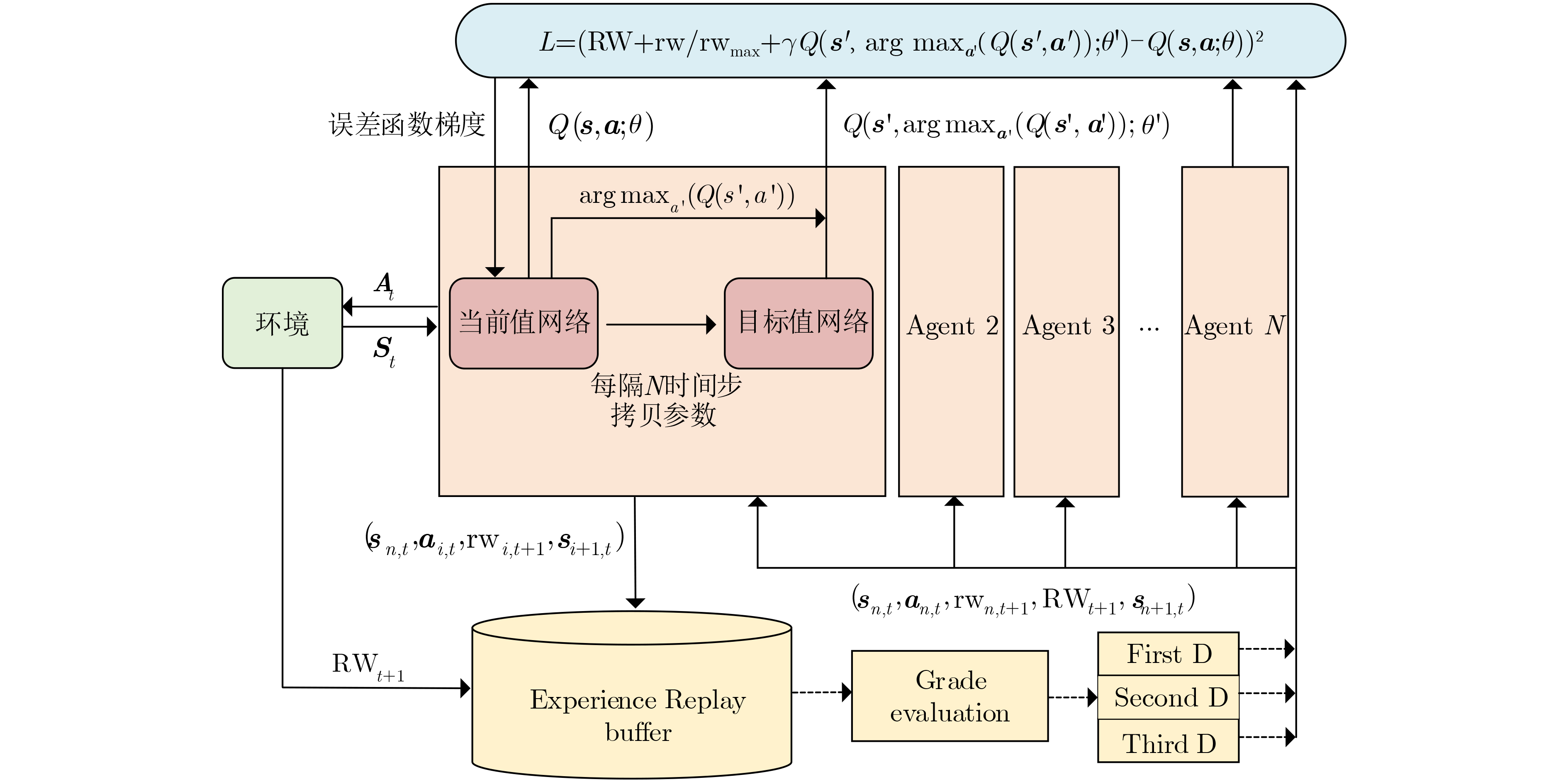
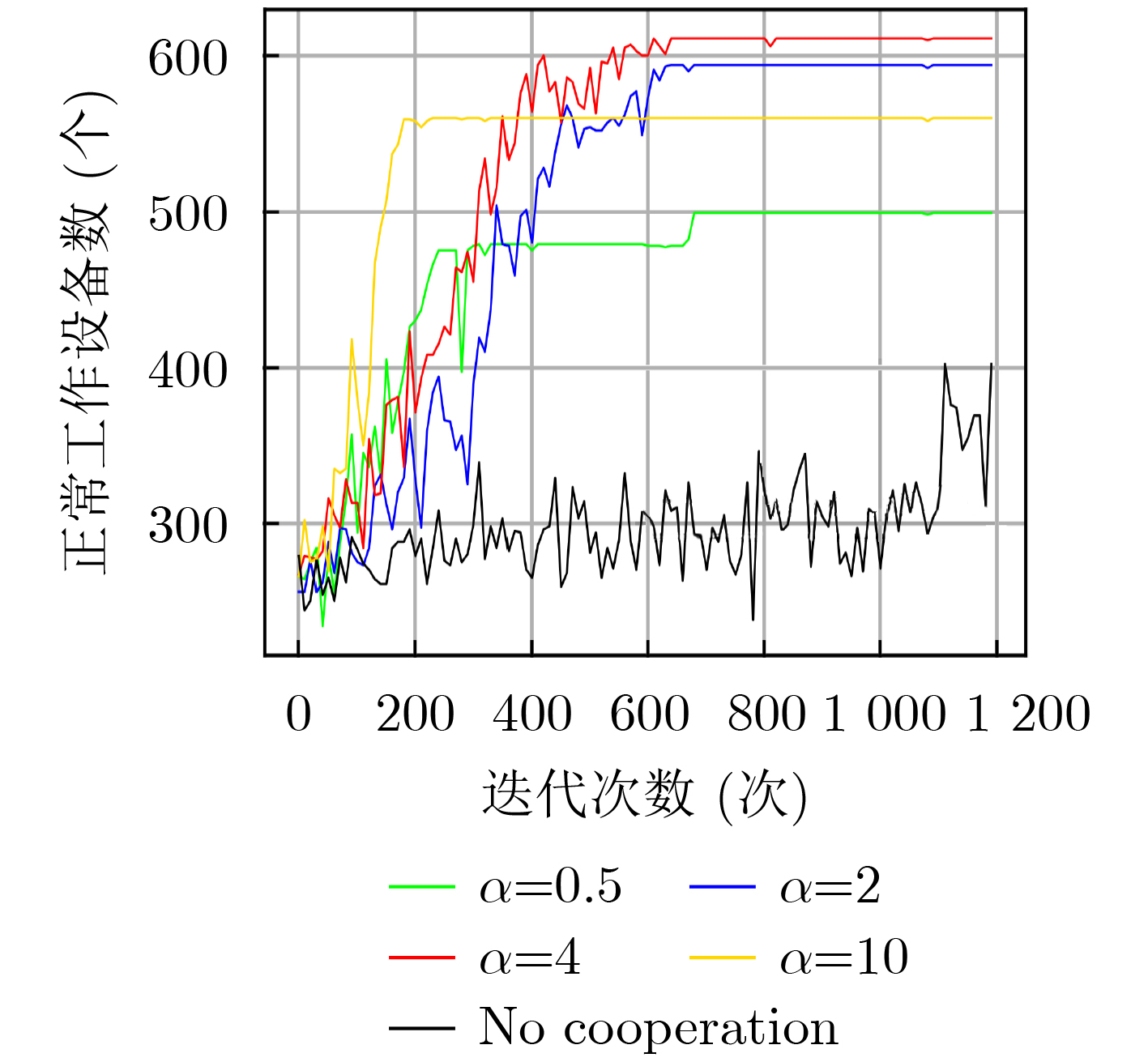



图(9) / 表(2)
计量
- 文章访问数: 972
- HTML全文浏览量: 663
- PDF下载量: 135
- 被引次数: 0
