

Remote Sensing Images Small Object Detection Algorithm With Adaptive Fusion and Hybrid Anchor Detector
-
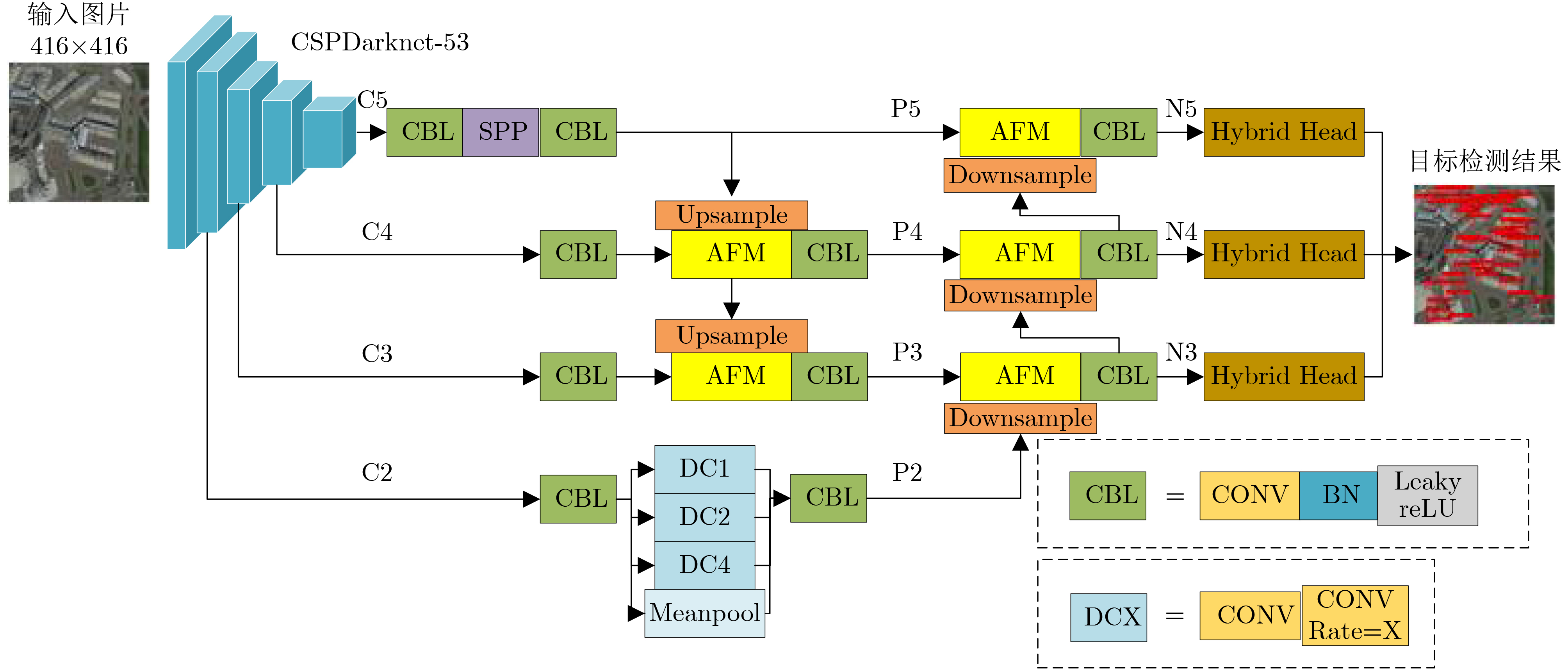
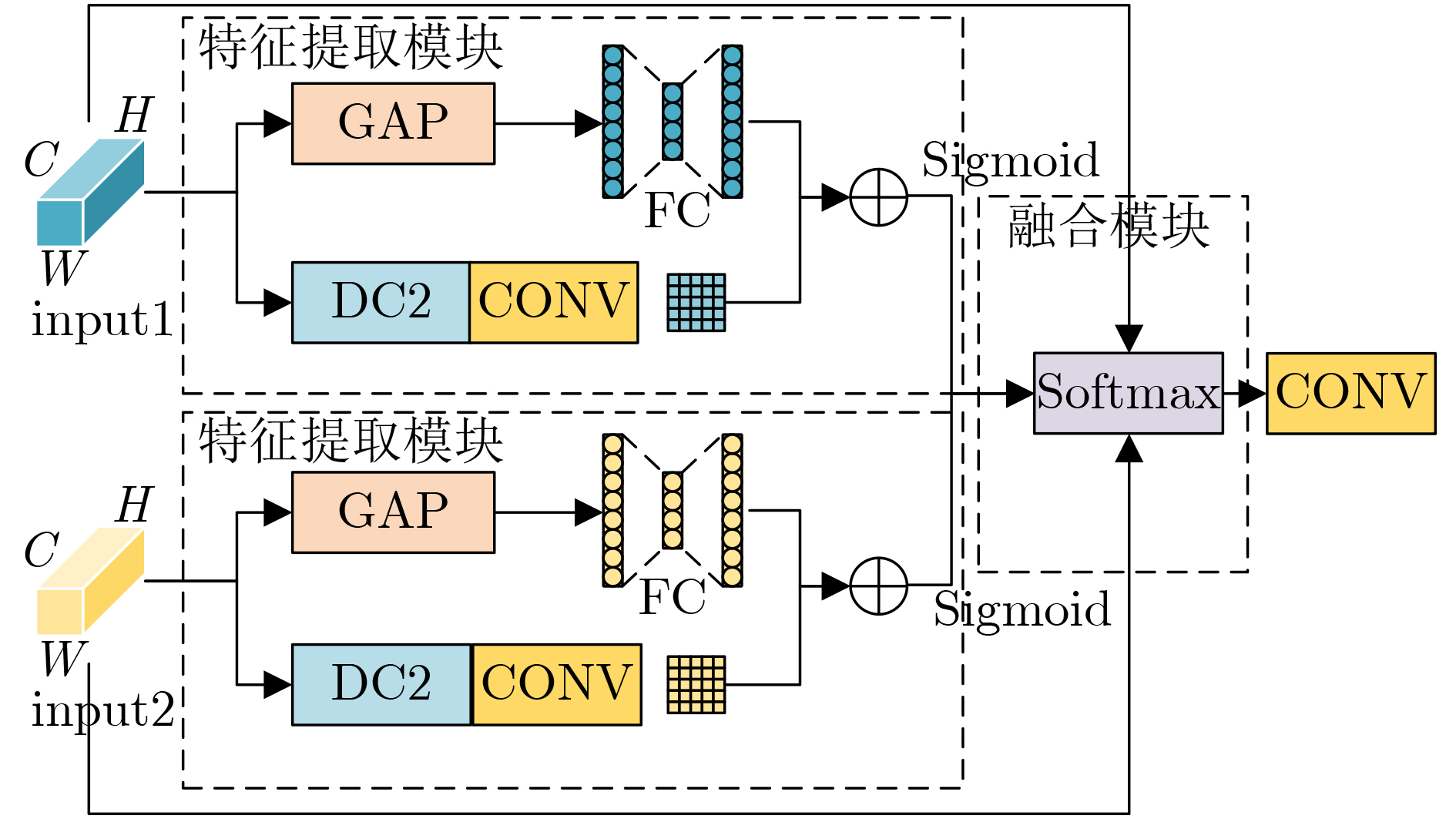
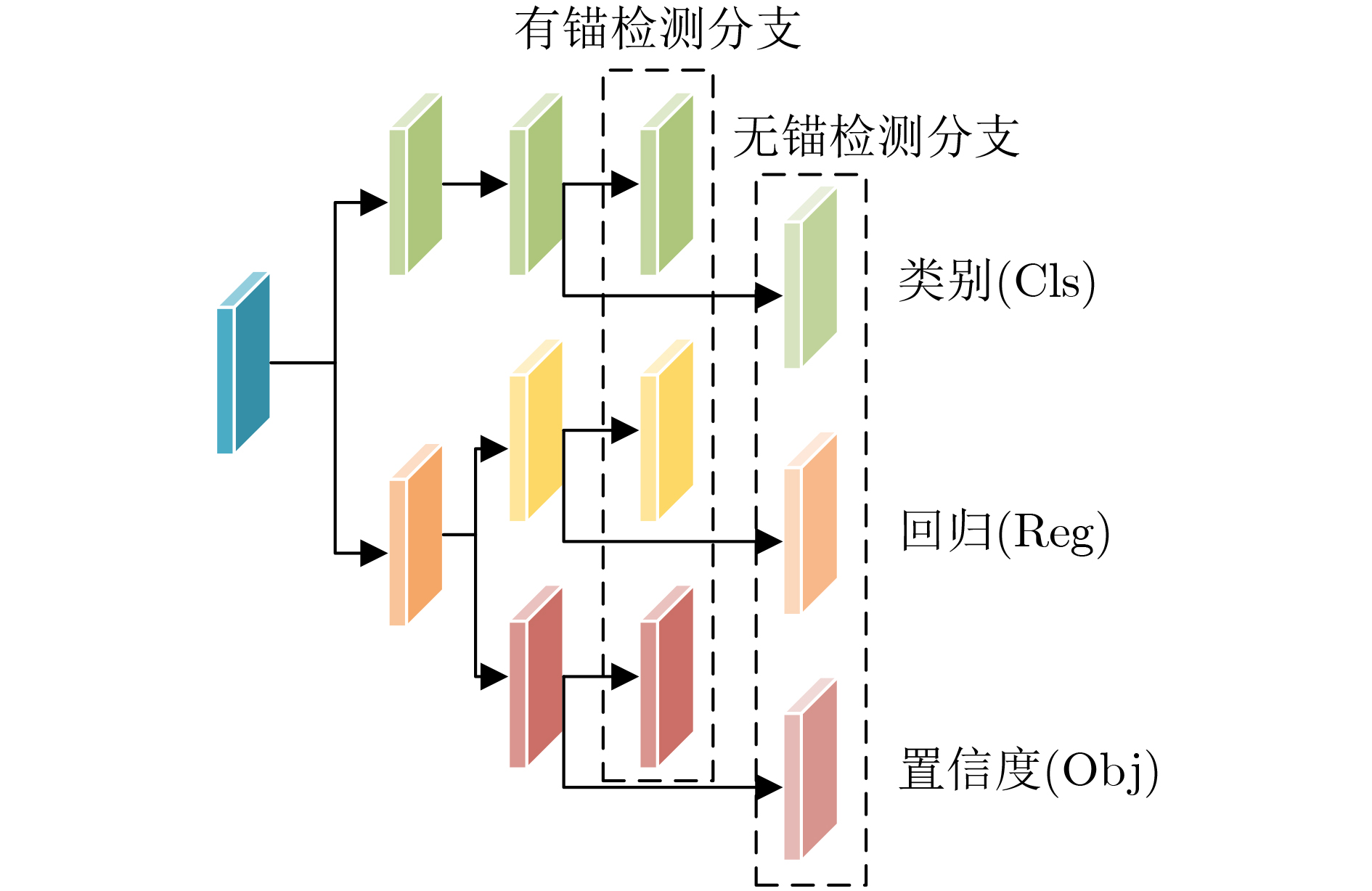
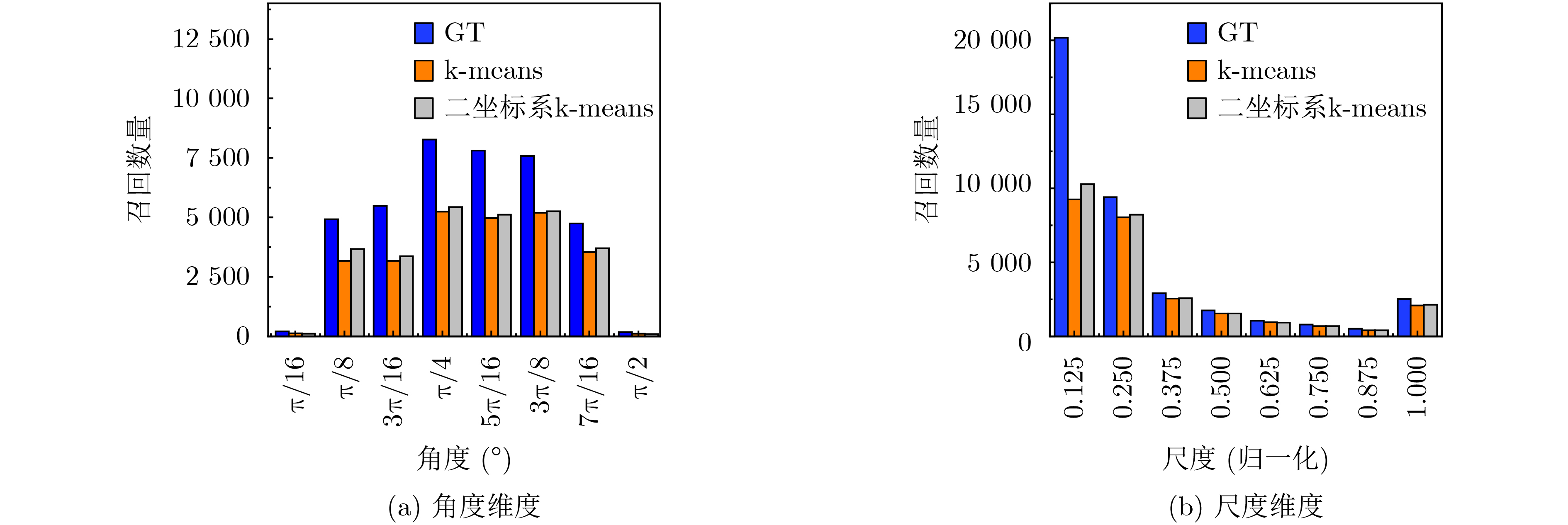
摘要: 针对遥感图像背景噪声多,小目标多且密集排列,以及目标尺度分布广导致的遥感图像小目标难以检测的问题,该文提出一种根据不同尺度的特征信息自适应融合的混合锚检测器AEM-YOLO。首先,提出了一种结合目标宽高信息以及尺度宽高比信息的二坐标系k-means聚类算法,生成与遥感图像数据集匹配度较高的锚框。其次,设计了自适应增强模块,用于解决不同尺度特征之间的直接融合导致的信息冲突,并引入更低特征层沿自底向上的路径传播小目标细节信息。通过混合解耦检测头的多任务学习以及引入尺度引导因子,可以有效提高对宽高比大的目标召回率。最后,在DIOR数据集上进行实验表明,相较于原始模型,AEM-YOLO的AP提高了7.8%,在小中大目标的检测中分别提高了5.4%,7.2%,8.6%。Abstract: A hybrid detector AEM-YOLO based on the adaptive fusion of different scale features is proposed, aiming at the problems of difficult detection of small objects in remote sensing images caused by the high background noise, dense arrangement of small objects, and wide-scale distribution. Firstly, a two-axes k-means clustering algorithm combining width and height information with scale and ratio information is proposed to generate anchor boxes with high matching degrees with remote sensing datasets. Secondly, an adaptive enhance module is designed to address information conflicts caused by direct fusion between different scale features. A lower feature layer is introduced to broadcast small object details along the bottom-up path. By using multi-task learning and scale guidance factor, the recall for objects with a high aspect ratio can be effectively improved. Finally, the experiments on the DIOR dataset show that compared with the original model, the AP of AEM-YOLO is improved by 7.8%, and increased by 5.4%, 7.2%, and 8.6% in small, medium, and large object detection, respectively.
-
Key words:
- Remote sensing images /
- Deep learning /
- Object detection /
- Detection head /
- Adaptive fusion /
- Anchor boxes
-
表 1 不同平衡系数对有锚检测分支精度的影响
$ \beta $ 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 mAP(%) 81.5 81.6 82.0 82.2 82.3 82.1 82.2 82.6 82.4 82.5 82.3  下载: 导出CSV
下载: 导出CSV
表 3 不同聚类算法在DIOR数据集实验结果对比(%)
Method AP AP50 AP75 APS APM APL 预设锚框 44.3 75.5 45.2 8.1 33.5 59.2 k-means 41.9 75.5 40.6 9.4 33.7 55.1 二坐标系k-means 44.7 76.2 45.8 11.0 34.8 58.5
下载: 导出CSV
表 4 不同多尺度融合模块在DIOR数据集实验结果对比(%)
算法 AP AP50 AP75 APS APM APL FPN-PAN 47.4 77.6 49.3 11.4 36.2 62.3 Bi-FPN 46.6 77.6 48.1 10.0 37.2 61.4 ASFF 47.9 78.3 49.8 10.2 36.4 63.0 AEM-F 47.6 78.0 49.8 10.9 36.0 62.9 AEM-A 48.0 78.9 50.2 13.3 37.5 62.5 AEM 49.5 79.0 52.2 12.9 37.3 65.0
下载: 导出CSV
表 5 不同检测头在DIOR数据集实验结果对比(%)
算法 AP AP50 AP75 APS APM APL Coupled Head 44.7 76.2 45.8 11.0 34.8 58.5 Decoupled Head 47.4 77.6 49.3 11.4 36.2 62.3 ASFF Head 48.3 78.3 50.5 11.1 36.9 63.3 Hybrid Head 50.5 79.4 53.2 12.6 39.1 66.2
下载: 导出CSV
表 6 在DIOR数据集上的消融实验结果(%)
Pre-train Neck Head AP AP50 AP75 APS APM APL Para(M) FPS × × × 44.3 75.5 45.2 8.1 33.5 59.2 64.0 61.2 √ × × 44.7 76.2 45.8 11.0 34.8 58.5 64.0 61.4 √ √ × 49.5 79.0 52.2 12.9 37.3 65.0 74.0 52.4 √ √ √ 52.1 80.9 55.3 13.5 40.7 67.8 74.0 53.6
下载: 导出CSV
表 7 不同输入尺寸下在NWPU VHR-10数据集实验结果对比(%)
算法 输入尺寸 AP AP50 AP75 APS APM APL YOLOv4 416×416 40.5 83.6 35.6 18.4 38.8 51.7 AEM-YOLO 416×416 45.1 88.2 40.6 29.9 43.5 57.5 YOLOv4 608×608 44.4 88.8 35.2 22.5 40.0 45.5 AEM-YOLO 608×608 51.9 91.7 49.8 30.7 47.0 54.0
下载: 导出CSV
表 8 不同目标检测方法在DIOR数据集实验结果对比
EfficientDet RetinaNet ASFF YOLOv3 YOLOv4 YOLOv5 YOLOX YOLOv6 YOLOv7 YOLOv8 本文算法 mAP(%) 65.3 69.0 79.9 74.5 76.9 77.8 62.9 79.3 78.9 82.3 82.6 GFLOPs 21.0 152.3 82.4 65.7 64.0 86.6 54.2 60.8 80.0 109.1 95.8 fps 34.4 46.8 45.3 82.3 72.1 53.5 64.8 61.3 59.7 57.7 53.6
下载: 导出CSV
-
[1] WANG Kun and LIU Maozhen. Toward structural learning and enhanced YOLOv4 network for object detection in optical remote sensing images[J]. Advanced Theory and Simulations, 2022, 5(6): 2200002. doi: 10.1002/adts.202200002. [2] 王成龙, 赵倩, 赵琰, 等. 基于深度可分离卷积的实时遥感目标检测算法[J]. 电光与控制, 2022, 29(8): 45–49. doi: 10.3969/j.issn.1671-637X.2022.08.009.WANG Chenglong, ZHAO Qian, ZHAO Yan, et al. A real-time remote sensing target detection algorithm based on depth Separable convolution[J]. Electronics Optics & Control, 2022, 29(8): 45–49. doi: 10.3969/j.issn.1671-637X.2022.08.009. [3] REIS D, KUPEC J, HONG J, et al. Real-time flying object detection with YOLOv8[J]. arXiv: 2305.09972, 2023. doi: 10.48550/arXiv.2305.09972. [4] ZHU Chenchen, HE Yihui, and SAVVIDES M. Feature selective anchor-free module for single-shot object detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 840–849. doi: 10.1109/CVPR.2019.00093. [5] LIU Songtao, HUANG Di, and WANG Yunhong. Learning spatial fusion for single-shot object detection[J]. arXiv: 1911.09516, 2019. doi: 10.48550/arXiv.1911.09516. [6] 马梁, 苟于涛, 雷涛, 等. 基于多尺度特征融合的遥感图像小目标检测[J]. 光电工程, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363.MA Liang, GOU Yutao, LEI Tao, et al. Small object detection based on multi-scale feature fusion using remote sensing images[J]. Opto-Electronic Engineering, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363. [7] 雷大江, 杜加浩, 张莉萍, 等. 联合多流融合和多尺度学习的卷积神经网络遥感图像融合方法[J]. 电子与信息学报, 2022, 44(1): 237–244. doi: 10.11999/JEIT200792.LEI Dajiang, DU Jiahao, ZHANG Liping, et al. Multi-stream architecture and multi-scale convolutional neural network for remote sensing image fusion[J]. Journal of Electronics & Information Technology, 2022, 44(1): 237–244. doi: 10.11999/JEIT200792. [8] QIN Zheng, LI Zeming, ZHANG Zhaoning, et al. ThunderNet: Towards real-time generic object detection on mobile devices[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 6717–6726. doi: 10.1109/ICCV.2019.00682. [9] KIM M, JEONG J, and KIM S. ECAP-YOLO: Efficient channel attention pyramid YOLO for small object detection in aerial image[J]. Remote Sensing, 2021, 13(23): 4851. doi: 10.3390/rs13234851. [10] BOCHKOVSKIY A, WANG C Y, and LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[J]. arXiv: 2004.10934, 2020. doi: 10.48550/arXiv.2004.10934. [11] ZHENG Zhaohui, WANG Ping, LIU Wei, et al. Distance-IoU loss: Faster and better learning for bounding box regression[C]. Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12993–13000. doi: 10.1609/aaai.v34i07.6999. [12] GE Zheng, LIU Songtao, WANG Feng, et al. YOLOX: Exceeding YOLO series in 2021[J]. arXiv: 2107.08430, 2021. doi: 10.48550/arXiv.2107.08430. [13] LI Ke, WAN Gang, CHENG Gong, et al. Object detection in optical remote sensing images: A survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296–307. doi: 10.1016/j.isprsjprs.2019.11.023. [14] CHENG Gong, HAN Junwei, ZHOU Peicheng, et al. Multi-class geospatial object detection and geographic image classification based on collection of part detectors[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2014, 98: 119–132. doi: 10.1016/j.isprsjprs.2014.10.002. [15] TAN Mingxing, PANG Ruoming, and LE Q V. EfficientDet: Scalable and efficient object detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10778–10787. doi: 10.1109/CVPR42600.2020.01079. [16] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2999–3007. doi: 10.1109/ICCV.2017.324. [17] WANG C Y, BOCHKOVSKIY A, and LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 7464–7475. doi: 10.1109/CVPR52729.2023.00721. [18] LI Chuyi, LI Lulu, JIANG Hongliang, et al. YOLOv6: A single-stage object detection framework for industrial applications[J]. arXiv: 2209.02976, 2022. doi: 10.48550/arXiv.2209.02976. -

 下载:
下载:






图(8) / 表(8)
计量
- 文章访问数: 993
- HTML全文浏览量: 899
- PDF下载量: 133
- 被引次数: 0
