

Screen-Shooting Resilient Watermarking Scheme Combining Invertible Neural Network and Inverse Gradient Attention
-
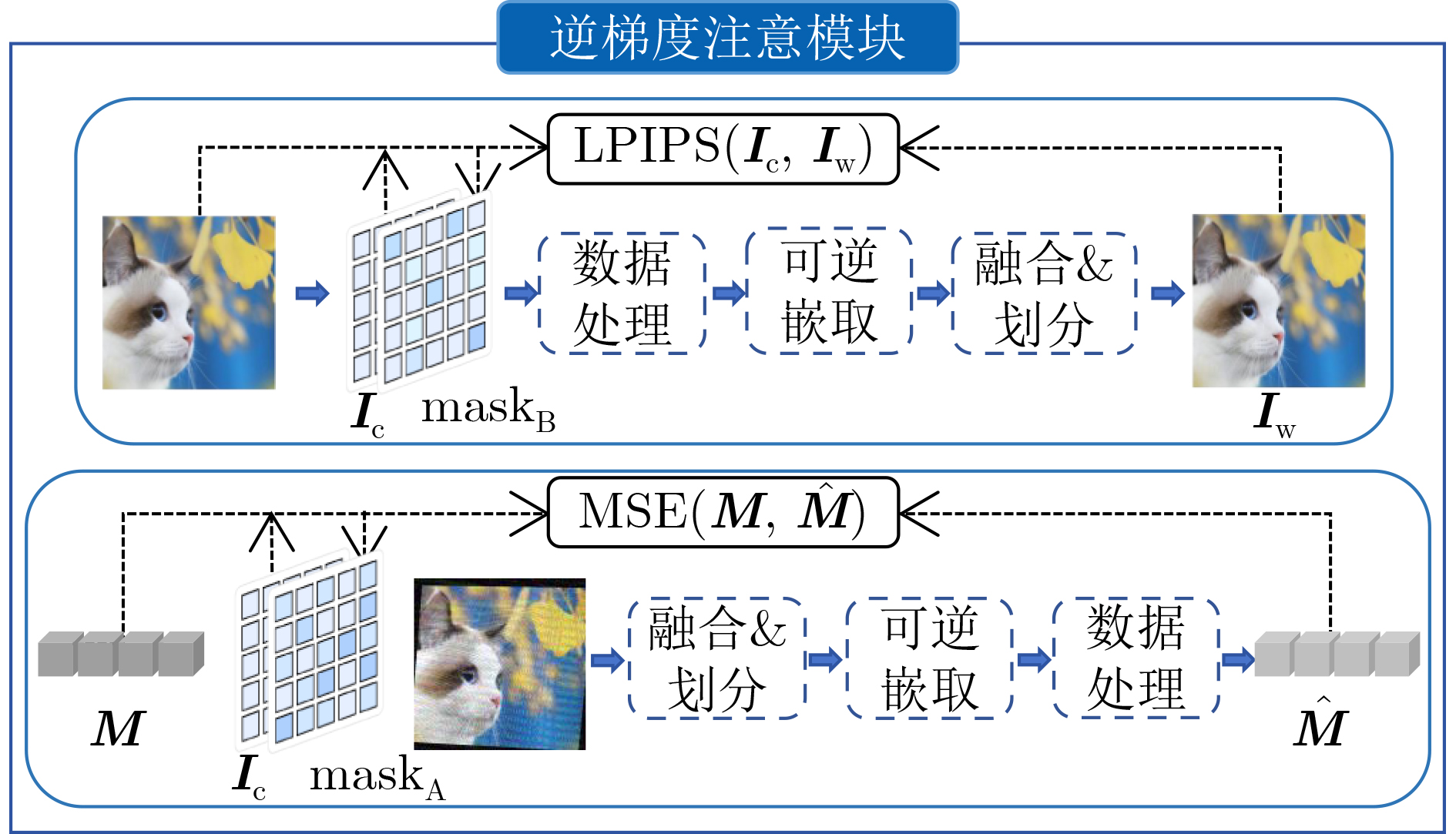
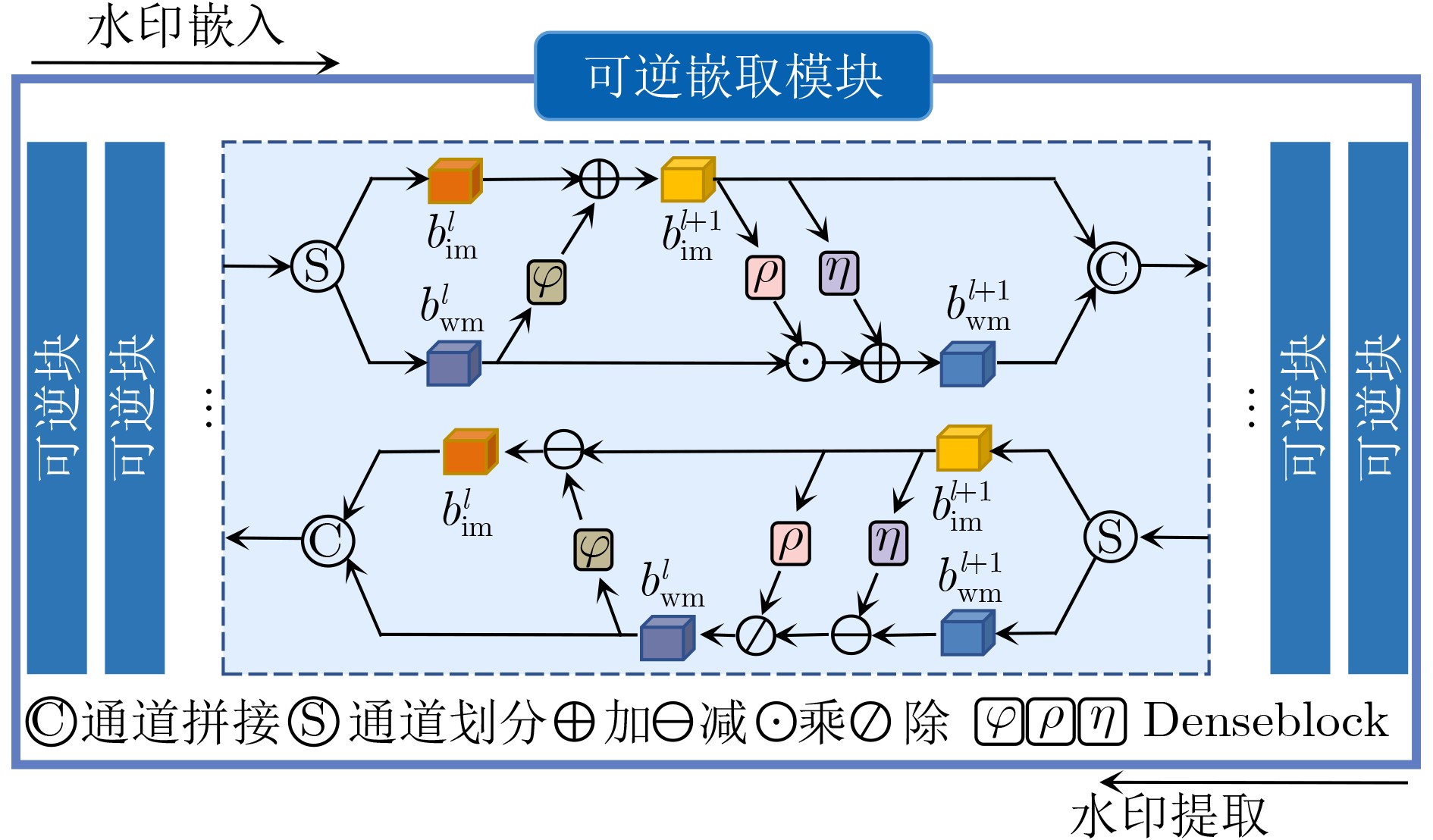
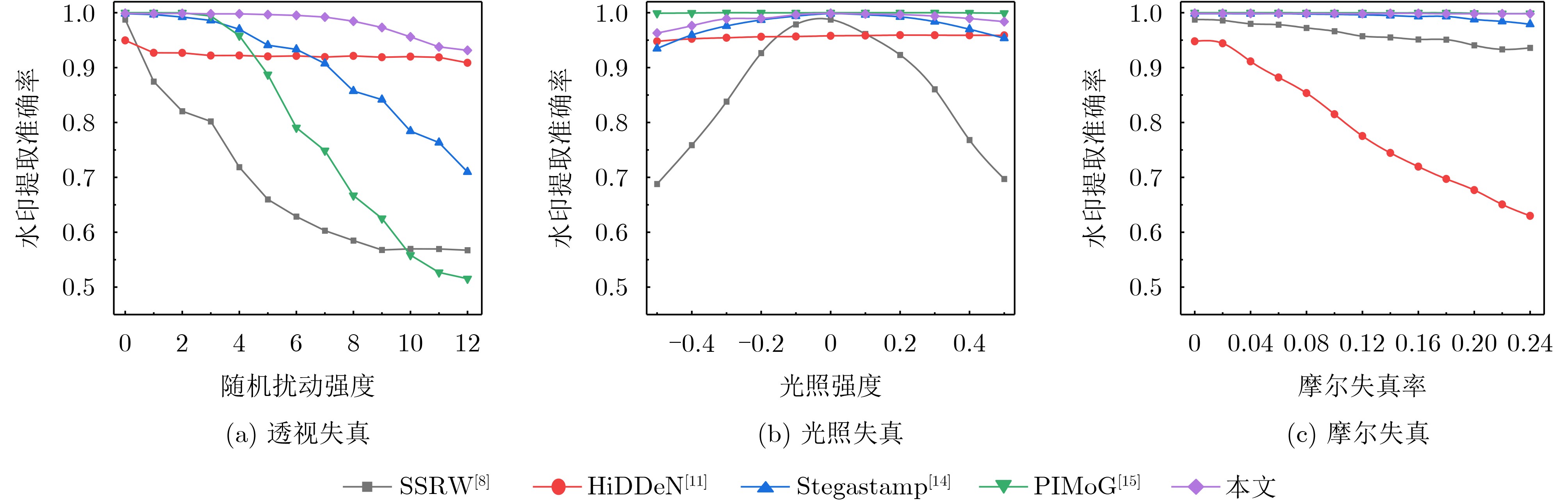
摘要: 随着智能设备的普及,数字媒体内容的传播和分享变得更加便捷,人们可以通过手机拍摄屏幕等简单方式轻松获取未经授权的信息,导致屏幕拍摄传播成为版权侵权的热点问题。为此,该文针对屏幕盗摄版权保护任务提出一种端到端的基于可逆神经网络和逆梯度注意力的抗屏摄攻击图像水印框架,实现屏幕盗摄场景下版权维护的目标。该文将水印的嵌入和提取视为相互关联的逆问题,利用可逆神经网络实现编解码网络的一体化,有助于减少信息传递损失。进一步地,通过引入逆梯度注意模块,捕捉载体图像中鲁棒性强且视觉质量高的像素值,并将水印信息嵌入到载体图像中不易被察觉和破坏的区域,保证水印的不可见性和模型的鲁棒性。最后,通过可学习感知图像块相似度(LPIPS)损失函数优化模型参数,指导模型最小化水印图像感知差异。实验结果表明,所提方法在鲁棒性和水印图像视觉质量上优于目前同类的基于深度学习的抗屏摄攻击水印方法。Abstract: With the growing use of smart devices, the ease of sharing digital media content has been enhanced. Concerns have been raised about unauthorized access, particularly via screen shooting. In this paper, a novel end-to-end watermarking framework is proposed, employing invertible neural networks and inverse gradient attention, to tackle the copyright infringement challenges related to screen content leakage. A single invertible neural network is employed by the proposed method for watermark embedding and extraction, ensuring information integrity during network propagation. Additionally, robustness and visual quality are enhanced by an inverse gradient attention module, which emphasizes pixel values and embeds the watermark in imperceptible areas for better invisibility and model resilience. Model parameters are optimized using the Learnable Perceptual Image Patch Similarity (LPIPS) loss function, minimizing perception differences in watermarked images. The superiority of this approach over existing learning-based screen-shooting resilient watermarking methods in terms of robustness and visual quality is demonstrated by experimental results.
-
表 6 视觉质量指标测试($ {\mathrm{w}}\;\&\; {\mathrm{w}}/{\mathrm{o}}{\text{ IGA}} $)
视觉评价指标 PSNR$ \uparrow $ SSIM$ \uparrow $ LPIPS$ \downarrow $ $ {\mathrm{w}}/{\mathrm{o}}{\text{ IGA}} $ 37.464 0.972 0.006 $ {\mathrm{w}}{\text{ IGA}} $ 39.306 0.984 0.001  下载: 导出CSV
下载: 导出CSV
表 7 不同拍摄距离的水印提取精度($ {\mathrm{w}}\;\&\; {\mathrm{w}}/{\mathrm{o}}{\text{ IGA}} $)
距离(cm) 20 30 40 50 60 $ {\mathrm{w}}/{\mathrm{o}}{\text{ IGA}} $ 99.52 97.63 95.95 90.95 97.62 $ {\mathrm{w}}{\text{ IGA}} $ 100 99.52 99.29 98.91 99.08
下载: 导出CSV
-
[1] VAN SCHYNDEL R G, TIRKEL A Z, and OSBORNE C F. A digital watermark[C]. 1st International Conference on Image Processing, Austin, USA, 1994, 2: 86–90. doi: 10.1109/ICIP.1994.413536. [2] 方涵. 屏摄鲁棒水印方法研究[D]. [博士论文], 中国科学技术大学, 2021. doi: 10.27517/d.cnki.gzkju.2021.000591.FANG Han. Research on screen shooting resilient watermarking[D]. [Ph. D. dissertation], University of Science and Technology of China, 2021. doi: 10.27517/d.cnki.gzkju.2021.000591. [3] WAN Wenbo, WANG Jun, ZHANG Yunming, et al. A comprehensive survey on robust image watermarking[J]. Neurocomputing, 2022, 488: 226–247. doi: 10.1016/j.neucom.2022.02.083. [4] 项世军, 杨乐. 基于同态加密系统的图像鲁棒可逆水印算法[J]. 软件学报, 2018, 29(4): 957–972. doi: 10.13328/j.cnki.jos.005406.XIANG Shijun and YANG Le. Robust and reversible image watermarking algorithm in homomorphic encrypted domain[J]. Journal of Software, 2018, 29(4): 957–972. doi: 10.13328/j.cnki.jos.005406. [5] 张天骐, 周琳, 梁先明, 等. 基于Blob-Harris特征区域和NSCT-Zernike的鲁棒水印算法[J]. 电子与信息学报, 2021, 43(7): 2038–2045. doi: 10.11999/JEIT200164.ZHANG Tianqi, ZHOU Lin, LIANG Xianming, et al. A robust watermarking algorithm based on Blob-Harris and NSCT-Zernike[J]. Journal of Electronics & Information Technology, 2021, 43(7): 2038–2045. doi: 10.11999/JEIT200164. [6] KANG Shuangyong, JIN Biao, LIU Yuxin, et al. Research on screen shooting resilient watermarking based on dot-matric[C]. 2023 2nd International Conference on Big Data, Information and Computer Network (BDICN), Xishuangbanna, China, 2023: 194–199. doi: 10.1109/BDICN58493.2023.00048. [7] SCHABER P, KOPF S, WETZEL S, et al. CamMark: Analyzing, modeling, and simulating artifacts in camcorder copies[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2015, 11(2s): 42. doi: 10.1145/2700295. [8] FANG Han, ZHANG Weiming, ZHOU Hang, et al. Screen-shooting resilient watermarking[J]. IEEE Transactions on Information Forensics and Security, 2019, 14(6): 1403–1418. doi: 10.1109/TIFS.2018.2878541. [9] DONG Li, CHEN Jiale, PENG Chengbin, et al. Watermark-preserving keypoint enhancement for screen-shooting resilient watermarking[C]. 2022 IEEE International Conference on Multimedia and Expo, Taipei, China, 2022: 1–6. doi: 10.1109/ICME52920.2022.9859950. [10] KANDI H, MISHRA D, and GORTHI S R K S. Exploring the learning capabilities of convolutional neural networks for robust image watermarking[J]. Computers & Security, 2017, 65: 247–268. doi: 10.1016/j.cose.2016.11.016. [11] ZHU Jiren, KAPLAN R, JOHNSON J, et al. HiDDeN: Hiding data with deep networks[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 682–697. doi: 10.1007/978-3-030-01267-0_40. [12] ZHANG Honglei, WANG Hu, CAO Yuanzhouhan, et al. Robust data hiding using inverse gradient attention[EB/OL]. https://doi.org/10.48550/arXiv.2011.10850, 2020. [13] WENGROWSKI E and DANA K. Light field messaging with deep photographic steganography[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1515–1524. doi: 10.1109/CVPR.2019.00161. [14] TANCIK M, MILDENHALL B, and NG R. StegaStamp: Invisible hyperlinks in physical photographs[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 2114–2123. doi: 10.1109/CVPR42600.2020.00219. [15] FANG Han, JIA Zhaoyang, MA Zehua, et al. PIMoG: An effective screen-shooting noise-layer simulation for deep-learning-based watermarking network[C]. 30th ACM International Conference on Multimedia, Lisbon, Portugal, 2022: 2267–2275. doi: 10.1145/3503161.3548049. [16] DINH L, KRUEGER D, and BENGIO Y. NICE: Non-linear independent components estimation[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015. [17] KINGMA D P and DHARIWAL P. Glow: Generative flow with invertible 1×1 convolutions[C]. Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 10236–10245. [18] XIE Yueqi, CHENG K L, and CHEN Qifeng. Enhanced invertible encoding for learned image compression[C]. 29th ACM International Conference on Multimedia, Chengdu, China, 2021: 162–170. doi: 10.1145/3474085.3475213. [19] XIAO Mingqing, ZHENG Shuxin, LIU Chang, et al. Invertible image rescaling[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 126–144. doi: 10.1007/978-3-030-58452-8_8. [20] GUO Mengxi, ZHAO Shijie, LI Yue, et al. Invertible single image rescaling via steganography[C]. 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, China, 2022: 1–6. doi: 10.1109/ICME52920.2022.9859915. [21] LU Shaoping, WANG Rong, ZHONG Tao, et al. Large-capacity image steganography based on invertible neural networks[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 10811–10820. doi: 10.1109/CVPR46437.2021.01067. [22] GUAN Zhenyu, JING Junpeng, DENG Xin, et al. DeepMIH: Deep invertible network for multiple image hiding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 372–390. doi: 10.1109/TPAMI.2022.3141725. [23] MA Rui, GUO Mengxi, HOU Yi, et al. Towards blind watermarking: Combining invertible and non-invertible mechanisms[C]. 30th ACM International Conference on Multimedia, Lisbon, Portugal, 2022: 1532–1542. doi: 10.1145/3503161.3547950. [24] ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 586–595. doi: 10.1109/CVPR.2018.00068. -


 下载:
下载:




图(6) / 表(7)
计量
- 文章访问数: 1607
- HTML全文浏览量: 1124
- PDF下载量: 127
- 被引次数: 0
