

A Study of Two-layer Asynchronous Federated Learning with Two-factor Updating for Vehicular Networking
-
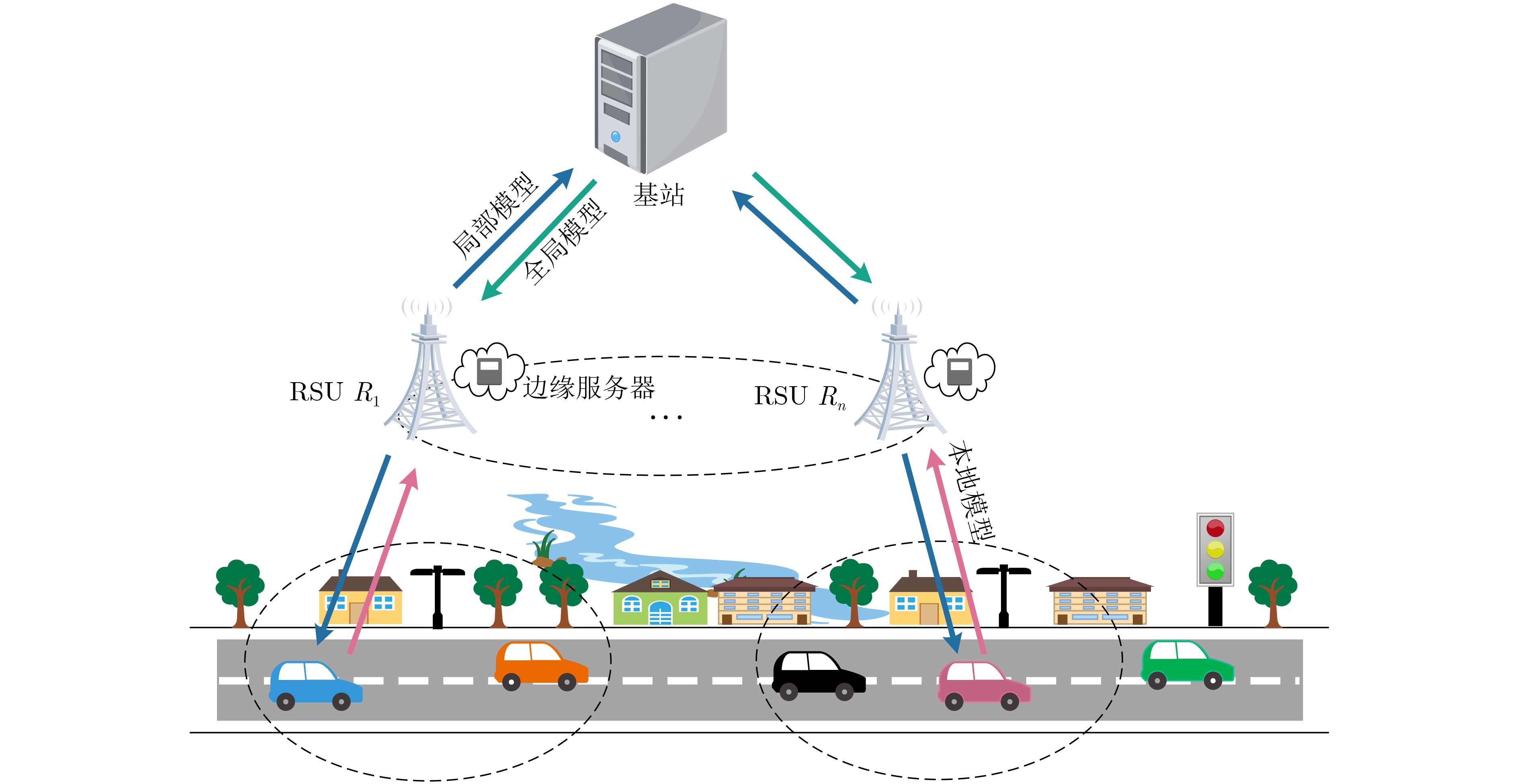
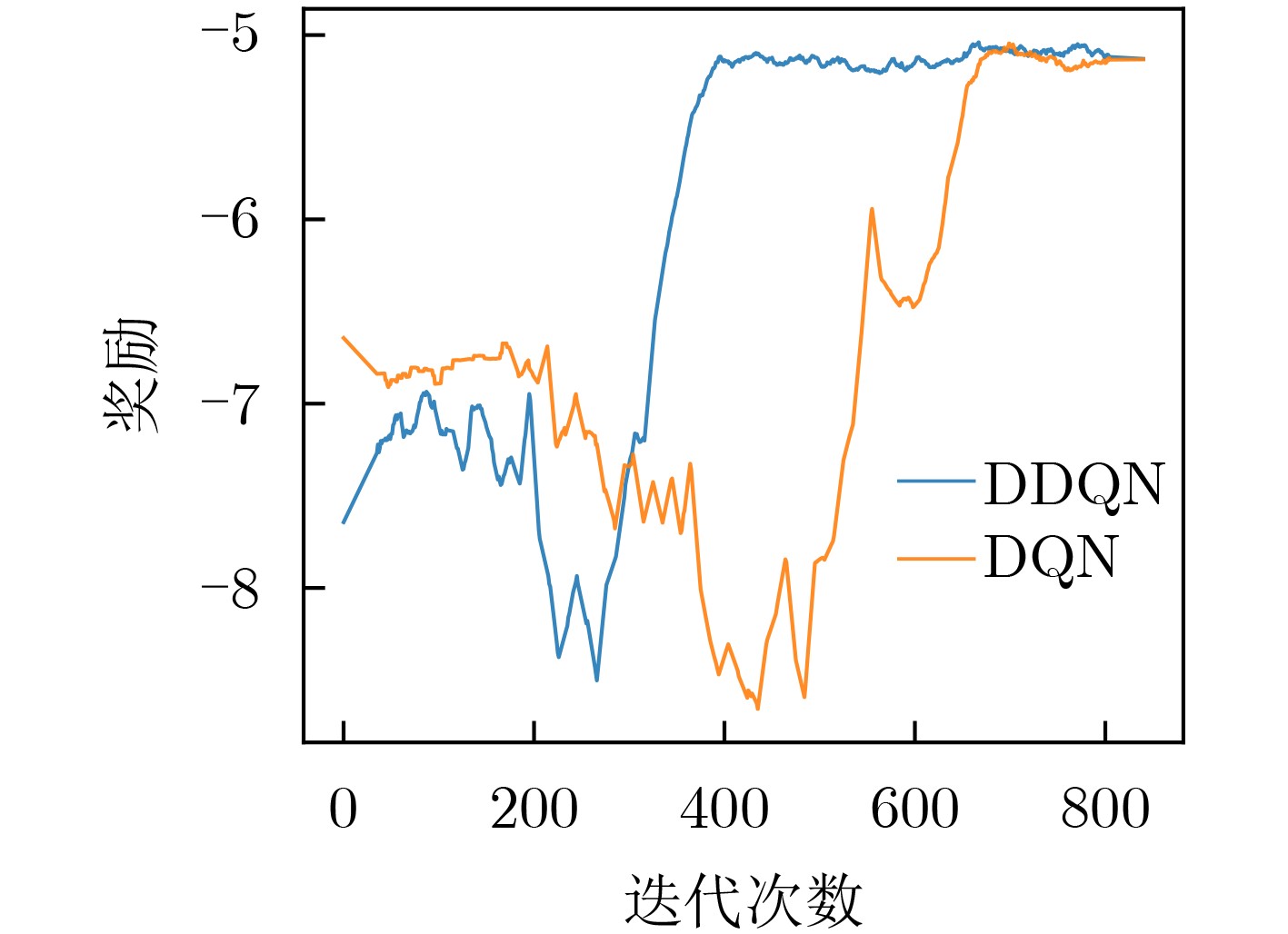
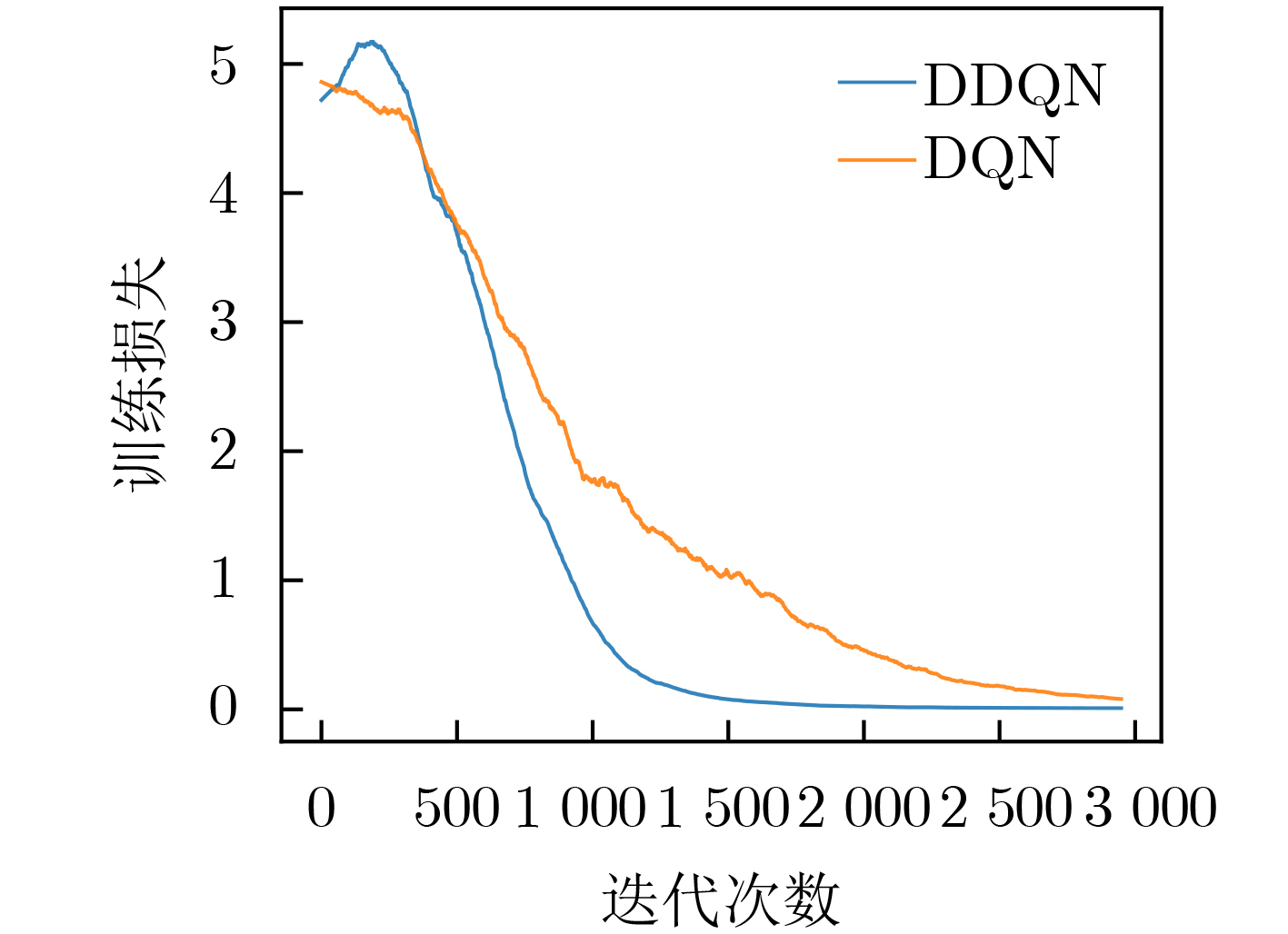
摘要: 针对车联网(IoV)中节点资源异构、拓扑结构动态变化等特点,该文建立了一个双因子更新的双层异步联邦学习(TTAFL)框架。考虑到模型版本差和车辆参与联邦学习(FL)次数对局部模型更新的影响,提出基于陈旧因子和贡献因子的模型更新方案。同时,为了避免训练过程中,车辆移动带来路侧单元切换的问题,给出考虑驻留时间的节点选择方案。最后,为了减少精度损失与系统能耗,利用强化学习方法优化联邦学习的本地迭代次数与路侧单元局部模型更新次数。仿真结果表明,所提算法有效提高了联邦学习的训练效率和训练精度,降低了系统能耗。Abstract: In response to the characteristics of heterogeneous node resources and dynamic changes in the network topology in the Internet of Vehicles (IoV), a Two-layer Asynchronous Federated Learning with Two-factor updating (TTAFL) framework is established in this paper. Considering the impact of model version differences and the number of times that vehicles participate in Federated Learning (FL) on server model updates, a model update scheme based on staleness factor and contribution factor is proposed. Furthermore, to avoid the problem of roadside unit switching caused by vehicle mobility during the training process, a node selection scheme considering the residence time is given. Finally, in order to reduce the accuracy loss and system energy consumption, a reinforcement learning method is used to optimize the number of local iterations of FL and the number of local model updates of roadside units. Simulation results show that the proposed algorithm effectively improves the training efficiency and training accuracy of federated learning and reduces the system energy consumption.
-
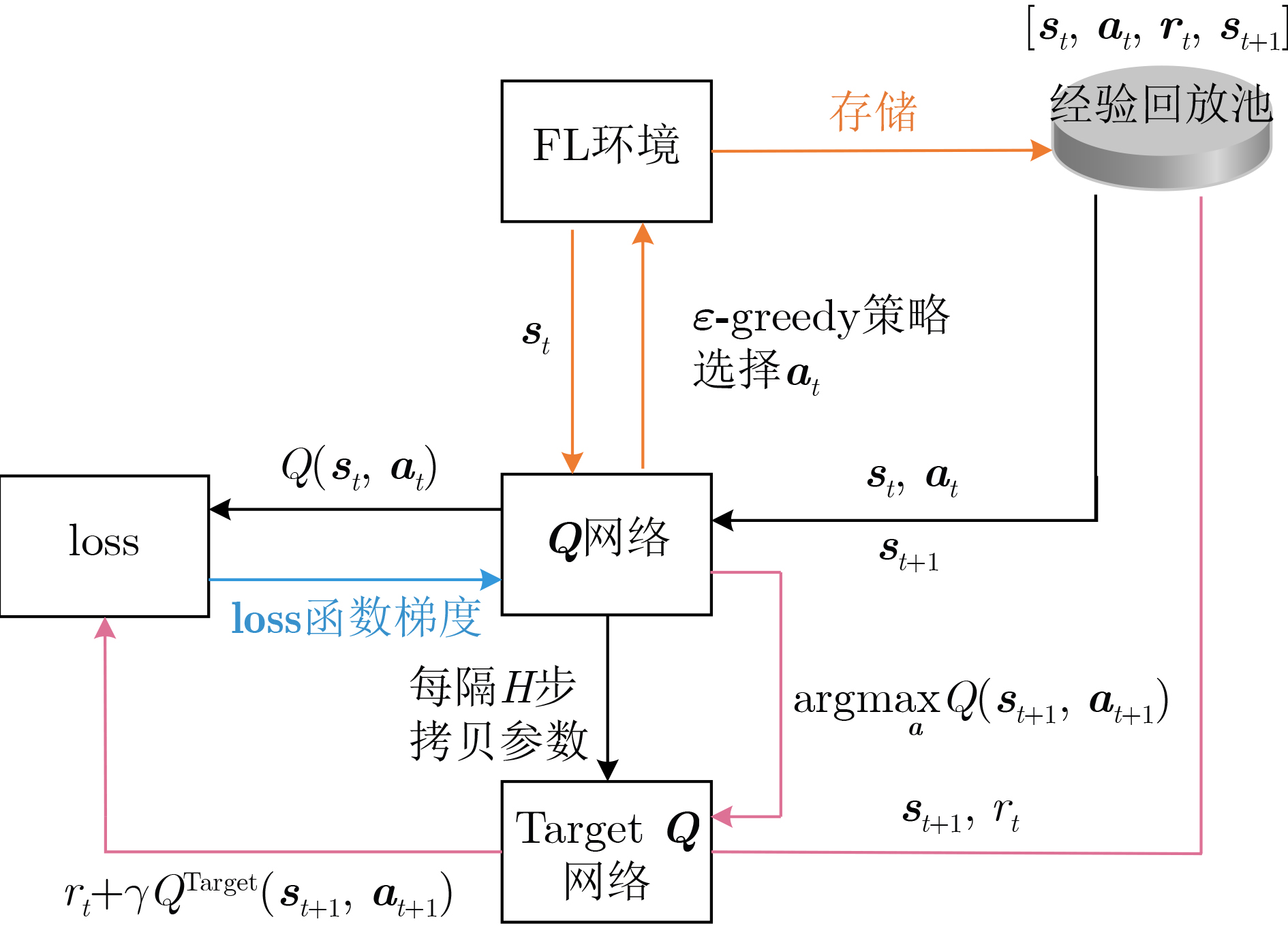
算法1 基于DDQN的联邦学习参数优化算法 输入:迭代轮数$T$,动作集$A$,衰减因子$\gamma $,探索率$\varepsilon $,探索衰
减$ {\text{decay}} $,当前${\boldsymbol{Q}}$网络$Q$,Target ${\boldsymbol{Q}}$网络$Q'$,批量梯度下降的
样本数$h$,Target ${\boldsymbol{Q}}$网络参数更新频率$H$,神经网络开始训练
时系统当前轮次为$ {P_1} $,神经网络训练的频率为$ {P_2} $输出:最优动作$ {\boldsymbol{a}} = (\theta ,\kappa ) $ (1) 初始化当前${\boldsymbol{Q}}$网络与Target ${\boldsymbol{Q}}$网络,将经验回放池
Memory清空。(2) for epoch=1 to $T$ do (3) 初始化双层异步联邦学习的状态s (4) 将${\boldsymbol{s}}$输入${\boldsymbol{Q}}$网络,得到${\boldsymbol{Q}}$网络所有动作对应的$Q$值输出,并
利用$ \varepsilon $-贪婪策略选出动作$ {\boldsymbol{a}} = (\theta ,\kappa ) $(5) 根据动作更新联邦学习参数$ \theta $和$ \kappa $并进行训练,得到新的状态
$ {s_{t + 1}} $和奖励$ {r_t} $(6) 将$ \{ {{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t}.{{\boldsymbol{r}}_t},{{\boldsymbol{s}}_{t + 1}}\} $存入经验回放池 (7) 令$ {{\boldsymbol{s}}_t} = {{\boldsymbol{s}}_{t + 1}} $ (8) if $ {\text{epoch}} \gt {P_1}{\text{ }}\& \& {\text{ epoch }}\% {\text{ }}{P_2} = = 0 $ (9) 从经验回放池中采样$h$个样本,并计算Target $Q$网络的值$ {y_{t + 1}} $
(10) 将误差$ {\text{loss}} = \dfrac{1}{h}\displaystyle\sum\limits_{i = 1}^h {{{({y_{t + 1}} - {Q^{{\text{Target}}}}({{\boldsymbol{s}}_{t + 1}},{{\boldsymbol{a}}_{t + 1}}))}^2}} $反向传
播以更新${\boldsymbol{Q}}$网络参数(11) if $ {\text{epoch }}\% {\text{ }}H = = 0 $ (12) 将${\boldsymbol{Q}}$网络参数复制给Target ${\boldsymbol{Q}}$网络 (13) end if (14) end if (15) $ {\text{epoch = epoch}} + 1 $ (16) $ \varepsilon = \varepsilon \cdot {\text{decay}} $ (17) end for  下载: 导出CSV
下载: 导出CSV
-
[1] ZHOU Xiaokang, LIANG Wei, SHE Jinhua, et al. Two-layer federated learning with heterogeneous model aggregation for 6G supported internet of vehicles[J]. IEEE Transactions on Vehicular Technology, 2021, 70(6): 5308–5317. doi: 10.1109/TVT.2021.3077893. [2] XU Chenhao, QU Youyang, LUAN T H, et al. An efficient and reliable asynchronous federated learning scheme for smart public transportation[J]. IEEE Transactions on Vehicular Technology, 2023, 72(5): 6584–6598. doi: 10.1109/TVT.2022.3232603. [3] MCMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]. The 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, USA, 2017: 1273–1282. [4] ABDULRAHMAN S, TOUT H, OULD-SLIMANE H, et al. A survey on federated learning: The journey from centralized to distributed on-site learning and beyond[J]. IEEE Internet of Things Journal, 2021, 8(7): 5476–5497. doi: 10.1109/JIOT.2020.3030072. [5] ZHU Hangyu, ZHANG Haoyu, and JIN Yaochu. From federated learning to federated neural architecture search: A survey[J]. Complex & Intelligent Systems, 2021, 7(2): 639–657. doi: 10.1007/s40747-020-00247-z. [6] SUN Feng, ZHANG Zhenjiang, ZEADALLY S, et al. Edge computing-enabled internet of vehicles: Towards federated learning empowered scheduling[J]. IEEE Transactions on Vehicular Technology, 2022, 71(9): 10088–10103. doi: 10.1109/TVT.2022.3182782. [7] LIM W Y B, LUONG N C, HOANG D T, et al. Federated learning in mobile edge networks: A comprehensive survey[J]. IEEE Communications Surveys & Tutorials, 2020, 22(3): 2031–2063. doi: 10.1109/COMST.2020.2986024. [8] YANG Zhigang, ZHANG Xuhua, WU Dapeng, et al. Efficient asynchronous federated learning research in the internet of vehicles[J]. IEEE Internet of Things Journal, 2023, 10(9): 7737–7748. doi: 10.1109/JIOT.2022.3230412. [9] CHAI Haoye, LENG Supeng, CHEN Yijin, et al. A hierarchical blockchain-enabled federated learning algorithm for knowledge sharing in internet of vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(7): 3975–3986. doi: 10.1109/TITS.2020.3002712. [10] SAPUTRA Y M, HOANG D T, NGUYEN D N, et al. Dynamic federated learning-based economic framework for internet-of-vehicles[J]. IEEE Transactions on Mobile Computing, 2023, 22(4): 2100–2115. doi: 10.1109/TMC.2021.3122436. [11] WANG Yuwei and KANTARCI B. A novel reputation-aware client selection scheme for federated learning within mobile environments[C]. 2020 IEEE 25th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks, Pisa, Italy, 2020: 1–6. doi: 10.1109/CAMAD50429.2020.9209263. [12] XIAO Huizi, ZHAO Jun, PEI Qingqi, et al. Vehicle selection and resource optimization for federated learning in vehicular edge computing[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(8): 11073–11087. doi: 10.1109/TITS.2021.3099597. [13] 贺文晨, 郭少勇, 邱雪松, 等. 基于DRL的联邦学习节点选择方法[J]. 通信学报, 2021, 42(6): 62–71. doi: 10.11959/j.issn.1000-436x.2021111.HE Wenchen, GUO Shaoyong, QIU Xuesong, et al. Node selection method in federated learning based on deep reinforcement learning[J]. Journal on Communications, 2021, 42(6): 62–71. doi: 10.11959/j.issn.1000-436x.2021111. [14] YANG Peng, YAN Mengjiao, CUI Yaping, et al. FedDD: Federated double distillation in IoV[C]. 2022 IEEE 96th Vehicular Technology Conference, London, United Kingdom, 2022: 1–5,doi: 10.1109/VTC2022-Fall57202.2022.10012798. [15] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791. -

 下载:
下载:



图(8) / 表(1)
计量
- 文章访问数: 991
- HTML全文浏览量: 816
- PDF下载量: 79
- 被引次数: 0
