

A Survey on Software-hardware Acceleration for Fully Homomorphic Encryption
-
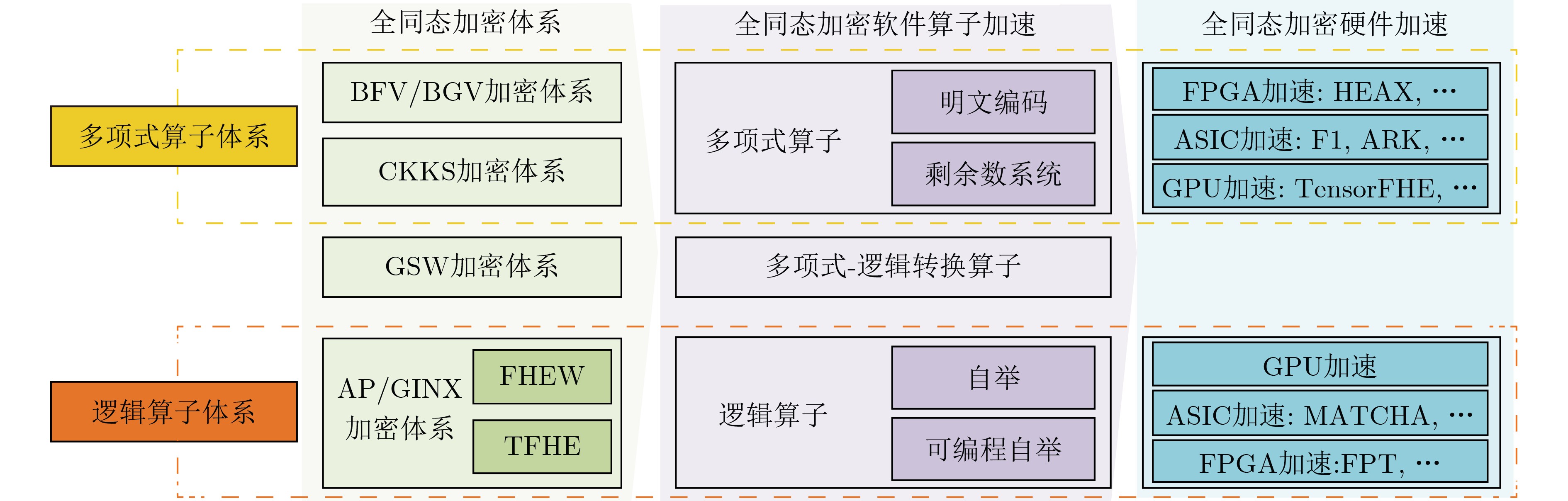
摘要: 全同态加密(FHE)是一种重计算、轻交互的多方安全计算协议。在基于全同态加密的计算协议中,尽管计算参与方之间无需多轮交互与大量通信,加密状态下的密态数据处理时间通常是明文计算的$ {10}^{3}\mathrm{~}{10}^{6} $倍,极大地阻碍了这类计算协议的实际落地;而密态数据上的主要处理负担是大规模的并行密码运算和运算所必须的密文及密钥数据搬运需求。该文聚焦软、硬件两个层面上的全同态加密加速这一研究热点,通过系统性地归类及整理当前领域中的文献,讨论全同态加密计算加速的研究现状与展望。Abstract: Fully Homomorphic Encryption (FHE) is a multi-party secure computation protocol characterized by its high computational complexity and low interaction requirements. Although there is no need for multiple rounds of interactions and extensive communications between computing participants in protocols based on FHE, the processing time of encrypted data is typically $ {10}^{3} $ to $ {10}^{6} $ times of that of plaintext computing, and thus significantly hinders the practical deployment of such protocols. In particular, the large-scale darallel cryptographic operations and the cost of data movement for the ciphertext and key data needed in the operations become the dominating performance bottlenecks. The topic of accelerating FHE in both the software and the hardware layers is discussed in this paper. By systematically categorizing and organizing existing literatures, a survey on the current status and outlook of the research on FHE is presented.
-
表 1 符号定义
符号 描述 符号 描述 $ \lambda $ 安全参数 $ \chi $ 噪声分布 $ p $ 明文模数 $ \mathbb{Z}_q^n $ $ \mathbb{Z}_q^n $上的$ n $维向量 $ q $ LWE密文模数 $ R $ $ \mathbb{Z}[X]/\left( {{X^N} + 1} \right) $上的分圆多项式环 $ Q $ RLWE密文模数 $ {R_Q} $ $ {\mathbb{Z}_Q}[X]/\left( {{X^N} + 1} \right) $上的分圆多项式环 $ Q' $ GSW密文模数 $ {\boldsymbol{a}} $ 向量域上的元素 $ n $ LWE密文维数 $ {a_i} $ $ a $的第$ i $个元素 $ N $ RLWE密文维数 $ \tilde a $ 多项式环上的元素 $ N^{\prime} $ GSW密文维数 $ {\tilde {\boldsymbol{a}}_i} $ 多项式环$ \tilde {\boldsymbol{a}} $的第$ i $元素 $ l $ GSW中包含RLWE个数 $ {{\mathrm{LWE}}}_{\boldsymbol{s}}^{n,q}({\boldsymbol{m}}) $ 参数$ \left( {n,q} \right) $和密钥$ {\boldsymbol{s}} $加密消息$ {\boldsymbol{m}} $的LWE密文 $ \Delta $ 缩放因子 $ {\text{RLWE}}_{{\boldsymbol{\tilde s}}}^{N,Q}({\boldsymbol{\tilde m}}) $ 参数$ \left( {N,Q} \right) $和密钥$ {\boldsymbol{\tilde s}} $加密消息$ {\boldsymbol{\tilde m}} $的RLWE密文 $ \varkappa $ 自举中未被刷新的位数 $ {\text{RGSW}}_{{\boldsymbol{\tilde s}}}^{N',Q'}({\boldsymbol{m}}) $ 参数$ \left( {N',Q'} \right) $和密钥$ {\boldsymbol{\tilde s}} $加密消息$ {\boldsymbol{m}} $的RGSW密文 $ \vartheta $ 自举置零的位数 $ d \leftarrow \mathcal{D} $ 从分布$ \mathcal{D} $中随机选择一个元素$ d $  下载: 导出CSV
下载: 导出CSV
算法1 同态累加 ACC$ \leftarrow b $ For $ i = 1 $ to $ n $ do $ {\text{ACC}} \leftarrow {\text{ACC}} - {\text{B}}{{\text{K}}_i} \cdot {a_i}{\rm{mod}} q $ End ReturnACC
下载: 导出CSV
表 2 全同态加密体系对比
加密体系 线性计算 非线性计算 批处理 特点及应用 BFV/BGV加密体系 √ × √ 整数运算,标量乘法,高效层级同态设计 CKKS加密体系 √ △ √ 实数运算,多项式近似,离散傅里叶变换 AP/GINX加密体系 √ √ × 比特运算,快速自举,布尔电路
下载: 导出CSV
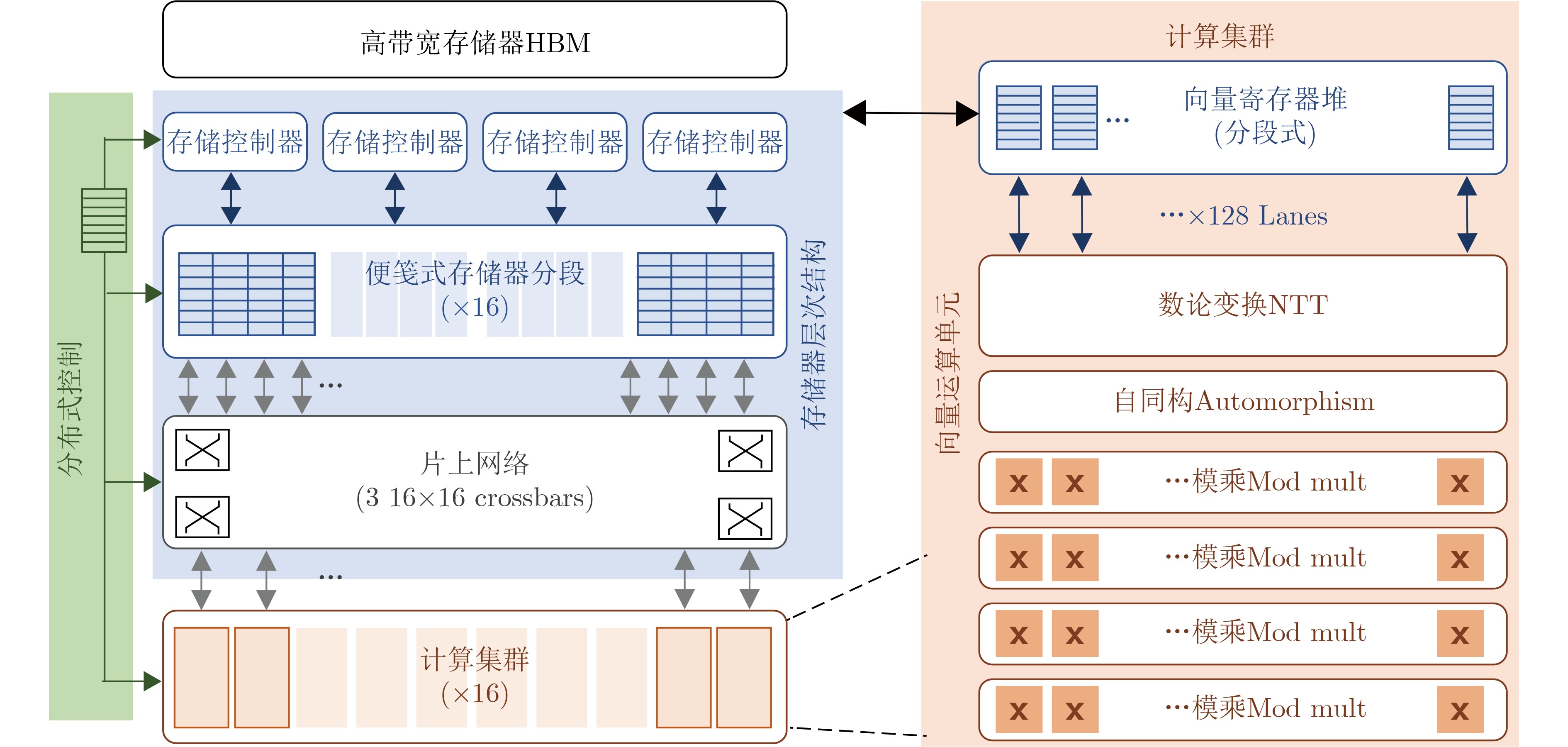
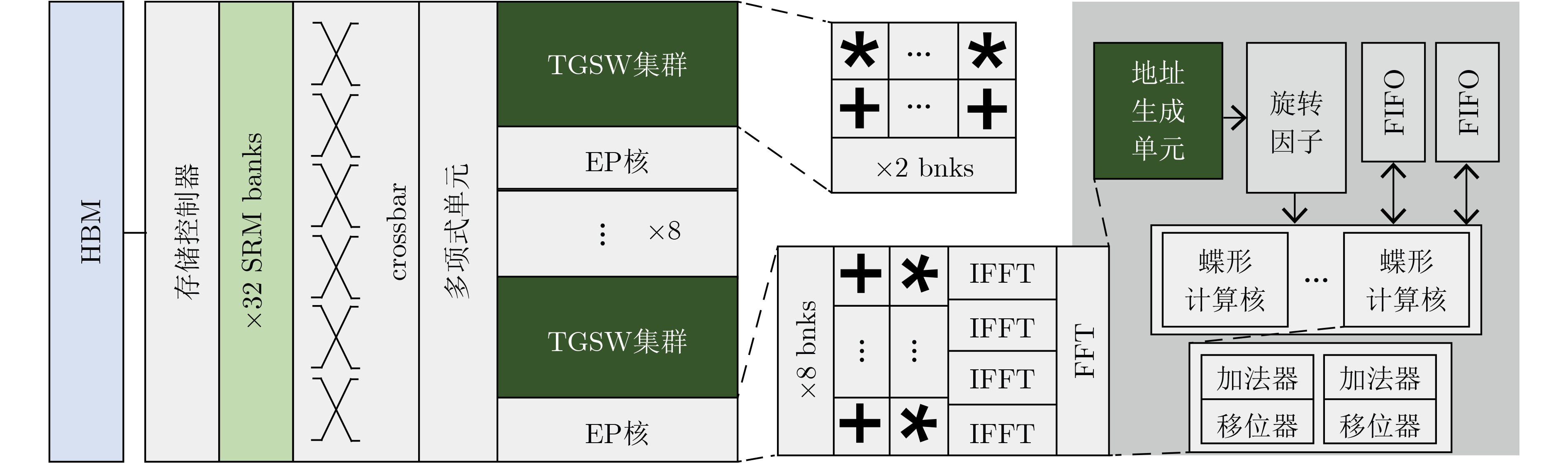
表 3 近期全同态加密算法的硬件加速方案
年份 加速方案 实验平台 面向算法 实验效果 2020 HEAX[60] FPGA CKKS 与单线程Intel Xeon(R) Silver 4108处理器相比较,HEAX可以实现164~268倍的性能提升 2021 Cheetah[61] 40 nm ASIC BFV 相较于当时最好的面向神经网络的同态加密接口解决方案Gazelle[23],综合电路可提供约79倍的加速效果 2021 F1[62] 14 nm/12 nm
ASICBGV, BFV,
GSW, CKKS性能相较于4核心8线程的3.5 GHz Xeon E3-1240v5 CPU软件实现方案速度平均提高了5400倍,其中最高的可达17000倍,并且比当时最快的硬件加速方案HEAX[60]快了172到1866倍不等 2022 CraterLake[63] 14 nm/12 nm
ASICBGV, GSW,
CKKS性能比CPU(32核64线程3.5 GHz AMD Ryzen Threadripper PRO 3975WX)平均高出4600倍,比之前的最佳全同态加密加速器F1[62]高出11.2倍 2022 ARK[64] 7 nm ASIC CKKS 相较于CPU(2.6 GHz Xeon Platinum 8358)单线程软件实现速度提升了最高18 214倍,相较于GPU实现方案100x[65]在一些算子上提升了104~563倍,相较于CraterLake[63]速度提升了1.23~2.58倍 2023 Poseidon[66] FPGA CKKS 对于全同态加密基本运算,Poseidon相较于现有的单线程CPU(3.3 GHz Intel Xeon Gold 6 234)的加速比高达370倍;对于关键算子,Poseidon相较于CPU和FPGA解决方案HEAX[60]的加速比分别高达1300倍和52倍;对于全同态加密基准测试,Poseidon相较于GPU解决方案100x[65]和ASIC解决方案F1[62]的加速比分别高达10.6倍和8.7倍 2023 FxHENN[67] FPGA CKKS 与最先进的基于CPU的HE-CNN推理解决方案LoLa[68]相比,FxHENN实现了高达13.49倍的推理延迟加速效果和1 187.12倍的能量效率 2023 TensorFHE[69] GPU BFV, BGV 比GPGPU上最先进的全同态加密实现100x[4]快 2.61 倍;在特定的工作负载下,TensorFHE可以比 F1+[62]快 2.9 倍 2022 MATCHA[70] 16 nm ASIC TFHE 与实现的GPU同态运行库cuFHE[71]相比,将TFHE门处理吞吐量提高了2.3倍;与FPGA方案TVE[72]改造的ASIC加速器相比,在能效上将每瓦特吞吐量提高了6.3倍 2022 FPT[73] FPGA TFHE FPT的自举吞吐量比现有基于CPU(2.1 GHz Intel Xeon Silver 4208 CPU)的单核实现高近937倍,比FPGA方案[74]高出7.1倍,并且比最近的ASIC方案MATCHA[8]高出2.5倍。
下载: 导出CSV
-
[1] GOLDREICH O, MICALI S, and WIGDERSON A. How to play any mental game[C]. The Nineteenth Annual ACM Symposium on Theory of Computing, New York, USA, 1987: 218–229. doi: 10.1145/28395.28420. [2] YAO A C C. How to generate and exchange secrets[C]. The 27th Annual Symposium on Foundations of Computer Science, Toronto, Canada, 1986: 162–167. doi: 10.1109/SFCS.1986.25. [3] GENTRY C. Fully homomorphic encryption using ideal lattices[C]. The Forty-First Annual ACM Symposium on Theory of Computing, Bethesda, USA, 2009: 169–178. doi: 10.1145/1536414.1536440. [4] HUANG Zhicong, LU Wenjie, HONG Cheng, et al. Cheetah: Lean and fast secure two-party deep neural network inference[C]. The 31st USENIX Security Symposium, Boston, USA, 2022: 809–826. [5] LU Wenjie, HUANG Zhicong, HONG Cheng, et al. PEGASUS: Bridging polynomial and non-polynomial evaluations in homomorphic encryption[C]. 2021 IEEE Symposium on Security and Privacy, San Francisco, USA, 2021: 1057–1073. doi: 10.1109/SP40001.2021.00043. [6] 韦韬, 潘无穷, 李婷婷, 等. 可信隐私计算: 破解数据密态时代“技术困局”[J]. 信息通信技术与政策, 2022, 48(5): 15–24. doi: 10.12267/j.issn.2096-5931.2022.05.003.WEI Tao, PAN Wuqiong, LI Tingting, et al. Trusted-environment-based privacy preserving computing: Breaks the bottleneck of ciphertext-exchange era[J]. Information and Communications Technology and Policy, 2022, 48(5): 15–24. doi: 10.12267/j.issn.2096-5931.2022.05.003. [7] FAN Junfeng and VERCAUTEREN F. Somewhat practical fully homomorphic encryption[R]. Cryptology ePrint Archive 2012/144, 2012. [8] BRAKERSKI Z, GENTRY C, and VAIKUNTANATHAN V. (Leveled) fully homomorphic encryption without bootstrapping[J]. ACM Transactions on Computation Theory, 2014, 6(3): 13. doi: 10.1145/2633600. [9] CHEON J H, KIM A, KIM M, et al. Homomorphic encryption for arithmetic of approximate numbers[C]. The 23rd International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 2017: 409–437. doi: 10.1007/978-3-319-70694-8_15. [10] GENTRY C, SAHAI A, and WATERS B. Homomorphic encryption from learning with errors: Conceptually-simpler, asymptotically-faster, attribute-based[C]. The 33rd Annual Cryptology Conference, Santa Barbara, USA, 2013: 75–92. doi: 10.1007/978-3-642-40041-4_5. [11] CHILLOTTI I, GAMA N, GEORGIEVA M, et al. TFHE: Fast fully homomorphic encryption over the torus[J]. Journal of Cryptology, 2020, 33(1): 34–91. doi: 10.1007/s00145-019-09319-x. [12] BRAKERSKI Z and VAIKUNTANATHAN V. Fully homomorphic encryption from ring-LWE and security for key dependent messages[C]. The 31st Annual Cryptology Conference, Santa Barbara, USA, 2011: 505–524. doi: 10.1007/978-3-642-22792-9_29. [13] COSTACHE A and SMART N P. Which ring based somewhat homomorphic encryption scheme is best?[C]. The Cryptographers' Track at the RSA Conference, San Francisco, USA, 2016: 325–340. doi: 10.1007/978-3-319-29485-8_19. [14] CHEON J H, HAN K, KIM A, et al. Bootstrapping for approximate homomorphic encryption[C]. The 37th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tel Aviv, Israel, 2018: 360–384. doi: 10.1007/978-3-319-78381-9_14. [15] ALPERIN-SHERIFF J and PEIKERT C. Faster bootstrapping with polynomial error[C]. The 34th Annual Cryptology Conference, Santa Barbara, USA, 2014: 297–314. doi: 10.1007/978-3-662-44371-2_17. [16] DUCAS L and MICCIANCIO D. FHEW: Bootstrapping homomorphic encryption in less than a second[C]. The 34th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Sofia, Bulgaria, 2015: 617–640. doi: 10.1007/978-3-662-46800-5_24. [17] GAMA N, IZABACHÈNE M, NGUYEN P Q, et al. Structural lattice reduction: Generalized worst-case to average-case reductions and homomorphic cryptosystems[C]. The 35th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Vienna, Austria, 2016: 528–558. doi: 10.1007/978-3-662-49896-5_19. [18] SMART N P and VERCAUTEREN F. Fully homomorphic SIMD operations[J]. Designs, Codes and Cryptography, 2014, 71(1): 57–81. doi: 10.1007/s10623-012-9720-4. [19] GARNER H L. The residue number system[C]. The Western Joint Computer Conference, San Francisco, USA, 1959: 146–153. doi: 10.1145/1457838.1457864. [20] HALEVI S and SHOUP V. Algorithms in HElib[C]. The 34th Annual Cryptology Conference, Santa Barbara, USA, 2014: 554–571. doi: 10.1007/978-3-662-44371-2_31. [21] HALEVI S and SHOUP V. Bootstrapping for HElib[J]. Journal of Cryptology, 2021, 34(1): 7. doi: 10.1007/s00145-020-09368-7. [22] HALEVI S and SHOUP V. Faster homomorphic linear transformations in HElib[C]. The 38th Annual International Cryptology Conference, Santa Barbara, USA, 2018: 93–120. doi: 10.1007/978-3-319-96884-1_4. [23] JUVEKAR C, VAIKUNTANATHAN V, and CHANDRAKASAN A. GAZELLE: A low latency framework for secure neural network inference[C]. The 27th USENIX Conference on Security Symposium, Baltimore, USA, 2018: 1651–1669. [24] BIAN S, KUNDI D E S, HIROZAWA K, et al. APAS: Application-specific accelerators for RLWE-based homomorphic linear transformations[J]. IEEE Transactions on Information Forensics and Security, 2021, 16: 4663–4678. doi: 10.1109/TIFS.2021.3114032. [25] BOSSUAT J P, MOUCHET C, TRONCOSO-PASTORIZA J, et al. Efficient bootstrapping for approximate homomorphic encryption with non-sparse keys[C]. The 40th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, 2021: 587–617. doi: 10.1007/978-3-030-77870-5_21. [26] LEE Y, LEE J W, KIM Y S, et al. High-precision bootstrapping for approximate homomorphic encryption by error variance minimization[C]. The 41st Annual International Conference on the Theory and Applications of Cryptographic Techniques, Trondheim, Norway, 2022: 551–580. doi: 10.1007/978-3-031-06944-4_19. [27] JUTLA C S and MANOHAR N. Sine series approximation of the mod function for bootstrapping of approximate HE[C]. The 41st Annual International Conference on the Theory and Applications of Cryptographic Techniques, Trondheim, Norway, 2022: 491–520. doi: 10.1007/978-3-031-06944-4_17. [28] CHEN Hao, CHILLOTTI I, and SONG Y. Improved bootstrapping for approximate homomorphic encryption[C]. The 38th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Darmstadt, Germany, 2019: 34–54. doi: 10.1007/978-3-030-17656-3_2. [29] LEE J W, LEE E, LEE Y, et al. High-precision bootstrapping of RNS-CKKS homomorphic encryption using optimal minimax polynomial approximation and inverse sine function[C]. The 40th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, 2021: 618–647. doi: 10.1007/978-3-030-77870-5_22. [30] RATHEE D, RATHEE M, KUMAR N, et al. CrypTFlow2: Practical 2-party secure inference[C]. The 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, USA, 2020: 325–342. doi: 10.1145/3372297.3417274. [31] BAJARD J C, EYNARD J, HASAN M A, et al. A full RNS variant of FV like somewhat homomorphic encryption schemes[C]. The 23rd International Conference on Selected Areas in Cryptography, St. John's, Canada, 2017: 423–442. doi: 10.1007/978-3-319-69453-5_23. [32] CHEON J H, HAN K, KIM A, et al. A full RNS variant of approximate homomorphic encryption[C]. The 25th International Conference on Selected Areas in Cryptography, Calgary, Canada, 2019: 347–368. doi: 10.1007/978-3-030-10970-7_16. [33] HALEVI S, POLYAKOV Y, and SHOUP V. An improved RNS variant of the BFV homomorphic encryption scheme[C]. The Cryptographers’ Track at the RSA Conference, San Francisco, USA, 2019: 83–105. doi: 10.1007/978-3-030-12612-4_5. [34] GENTRY C, HALEVI S, and SMART N P. Homomorphic evaluation of the AES circuit[C]. The 32nd Annual Cryptology Conference, Santa Barbara, USA, 2012: 850–867. doi: 10.1007/978-3-642-32009-5_49. [35] CHEON J H, HAN K, KIM A, et al. A full RNS variant of approximate homomorphic encryption[C]. The 25th International Conference on Selected Areas in Cryptography, Calgary, Canada, 2019: 347–368. doi: 10.1007/978-3-030-10970-7_16. [36] HAN K and KI D. Better bootstrapping for approximate homomorphic encryption[C]. The Cryptographers’ Track at the RSA Conference 2020, San Francisco, USA, 2020: 364–390. doi: 10.1007/978-3-030-40186-3_16. [37] KIM A, PAPADIMITRIOU A, and POLYAKOV Y. Approximate homomorphic encryption with reduced approximation error[R]. Cryptology ePrint Archive 2022/1118, 2022: 120–144. [38] MICCIANCIO D and POLYAKOV Y. Bootstrapping in FHEW-like cryptosystems[C]. The 9th on Workshop on Encrypted Computing & Applied Homomorphic Cryptography, Seoul, South Korea, 2021: 17–28. doi: 10.1145/3474366.3486924. [39] BONNORON G, DUCAS L, and FILLINGER M. Large FHE gates from tensored homomorphic accumulator[C]. The 10th International Conference on Cryptology in Africa, Marrakesh, Morocco, 2018: 217–251. doi: 10.1007/978-3-319-89339-6_13. [40] LEE Y, MICCIANCIO D, KIM A, et al. Efficient FHEW bootstrapping with small evaluation keys, and applications to threshold homomorphic encryption[R]. Cryptology ePrint Archive 2022/198, 2022. [41] MICCIANCIO D and SORRELL J. Ring packing and amortized FHEW bootstrapping[R]. Cryptology ePrint Archive 2018/532, 2018. [42] GUIMARÃES A, PEREIRA H V L, and VAN LEEUWEN B. Amortized bootstrapping revisited: Simpler, asymptotically-faster, implemented[J]. Cryptology ePrint Archive 2023/014, 2023. [43] LIU Fenghao and WANG Han. Batch bootstrapping I: A new framework for SIMD bootstrapping in polynomial modulus[C]. The 42nd Annual International Conference on the Theory and Applications of Cryptographic Techniques, Lyon, France, 2023: 321–352. doi: 10.1007/978-3-031-30620-4_11. [44] BOURA C, GAMA N, GEORGIEVA M, et al. Simulating homomorphic evaluation of deep learning predictions[C]. The 3rd International Symposium on Cyber Security Cryptography and Machine Learning, Beer-Sheva, Israel, 2019: 212–230. doi: 10.1007/978-3-030-20951-3_20. [45] CHILLOTTI I, JOYE M, and PAILLIER P. Programmable bootstrapping enables efficient homomorphic inference of deep neural networks[C]. The 5th International Symposium on Cyber Security Cryptography and Machine Learning, Be’er Sheva, Israel, 2021: 1–19. doi: 10.1007/978-3-030-78086-9_1. [46] CLET P E, ZUBER M, BOUDGUIGA A, et al. Putting up the swiss army knife of homomorphic calculations by means of TFHE functional bootstrapping[R]. Cryptology ePrint Archive 2022/149, 2022. [47] KLUCZNIAK K and SCHILD L. FDFB: Full domain functional bootstrapping towards practical fully homomorphic encryption[J]. IACR Transactions on Cryptographic Hardware and Embedded Systems, 2022, 2023(1): 501–537. doi: 10.46586/tches.v2023.i1.501-537. [48] YANG Zhaomin, XIE Xiang, SHEN Huajie, et al. TOTA: Fully homomorphic encryption with smaller parameters and stronger security[R]. Cryptology ePrint Archive, 2021/1347, 2021. [49] CARPOV S, GAMA N, GEORGIEVA M, et al. Privacy-preserving semi-parallel logistic regression training with fully homomorphic encryption[J]. BMC Medical Genomics, 2020, 13(7): 88. doi: 10.1186/s12920-020-0723-0. [50] GUIMARÃES A, BORIN E, and ARANHA D F. Revisiting the functional bootstrap in TFHE[J]. IACR Transactions on Cryptographic Hardware and Embedded Systems, 2021, 2021(2): 229–253. doi: 10.46586/tches.v2021.i2.229-253. [51] CHILLOTTI I, LIGIER D, ORFILA J B, et al. Improved programmable bootstrapping with larger precision and efficient arithmetic circuits for TFHE[C]. The 27th International Conference on the Theory and Application of Cryptology and Information Security, Singapore, 2021: 670–699. doi: 10.1007/978-3-030-92078-4_23. [52] CHEN Hao, CHILLOTTI I, and SONG Y. Multi-key homomorphic encryption from TFHE[C]. The 25th International Conference on the Theory and Application of Cryptology and Information Security, Kobe, Japan, 2019: 446–472. doi: 10.1007/978-3-030-34621-8_16. [53] BOURA C, GAMA N, GEORGIEVA M, et al. CHIMERA: Combining ring-LWE-based fully homomorphic encryption schemes[J]. Journal of Mathematical Cryptology, 2020, 14(1): 316–338. doi: 10.1515/jmc-2019-0026. [54] CHEN Hao, DAI Wei, KIM M, et al. Efficient homomorphic conversion between (ring) LWE ciphertexts[C]. The 19th International Conference on Applied Cryptography and Network Security, Kamakura, Japan, 2021: 460–479. doi: 10.1007/978-3-030-78372-3_18. [55] REN Xuanle, SU Le, GU Zhen, et al. HEDA: Multi-attribute unbounded aggregation over homomorphically encrypted database[J]. Proceedings of the VLDB Endowment, 2022, 16(4): 601–614. doi: 10.14778/3574245.3574248. [56] GÖTTERT N, FELLER T, SCHNEIDER M, et al. On the design of hardware building blocks for modern lattice-based encryption schemes[C]. The 14th International Workshop on Cryptographic Hardware and Embedded Systems, Leuven, Belgium, 2012: 512–529. doi: 10.1007/978-3-642-33027-8_30. [57] PÖPPELMANN T and GÜNEYSU T. Towards efficient arithmetic for lattice-based cryptography on reconfigurable hardware[C]. The 2nd International Conference on Cryptology and Information Security in Latin America, Santiago, Chile, 2012: 139–158. doi: 10.1007/978-3-642-33481-8_8. [58] PÖPPELMANN T and GÜNEYSU T. Towards practical lattice-based public-key encryption on reconfigurable hardware[C]. The 20th International Conference on Selected Areas in Cryptography, Burnaby, Canada, 2014: 68–85. doi: 10.1007/978-3-662-43414-7_4. [59] 施佺, 韩赛飞, 黄新明, 等. 面向全同态加密的有限域FFT算法FPGA设计[J]. 电子与信息学报, 2018, 40(1): 57–62. doi: 10.11999/JEIT170312.SHI Quan, HAN Saifei, HUANG Xinming, et al. Design of finite field FFT for fully homomorphic encryption based on FPGA[J]. Journal of Electronics & Information Technology, 2018, 40(1): 57–62. doi: 10.11999/JEIT170312. [60] RIAZI M S, LAINE K, PELTON B, et al. HEAX: An architecture for computing on encrypted data[C]. The Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 2020: 1295–1309. doi: 10.1145/3373376.3378523. [61] REAGEN B, CHOI W S, KO Y, et al. Cheetah: Optimizing and accelerating homomorphic encryption for private inference[C]. The 2021 IEEE International Symposium on High-Performance Computer Architecture, Seoul, South Korea, 2021: 26–39. doi: 10.1109/HPCA51647.2021.00013. [62] SAMARDZIC N, FELDMANN A, KRASTEV A, et al. F1: A fast and programmable accelerator for fully homomorphic encryption[C]. The 54th Annual IEEE/ACM International Symposium on Microarchitecture, Greece, 2021: 238–252. doi: 10.1145/3466752.3480070. [63] SAMARDZIC N, FELDMANN A, KRASTEV A, et al. CraterLake: A hardware accelerator for efficient unbounded computation on encrypted data[C]. The 49th Annual International Symposium on Computer Architecture, New York, USA, 2022: 173–187. doi: 10.1145/3470496.3527393. [64] KIM J, LEE G, KIM S, et al. ARK: Fully homomorphic encryption accelerator with runtime data generation and inter-operation key reuse[C]. The 2022 55th IEEE/ACM International Symposium on Microarchitecture, Chicago, USA, 2022: 1237–1254. doi: 10.1109/MICRO56248.2022.00086. [65] JUNG W, KIM S, AHN J H, et al. Over 100x faster bootstrapping in fully homomorphic encryption through memory-centric optimization with GPUs[J]. IACR Transactions on Cryptographic Hardware and Embedded Systems, 2021, 2021(4): 114–148. doi: 10.46586/tches.v2021.i4.114-148. [66] YANG Yinghao, ZHANG Huaizhi, FAN Shengyu, et al. Poseidon: Practical homomorphic encryption accelerator[C]. 2023 IEEE International Symposium on High-Performance Computer Architecture, Montreal, Canada, 2023: 870–881. doi: 10.1109/HPCA56546.2023.10070984. [67] ZHU Yilan, WANG Xinyao, JU Lei, et al. FxHENN: FPGA-based acceleration framework for homomorphic encrypted CNN inference[C]. 2023 IEEE International Symposium on High-Performance Computer Architecture, Montreal, Canada, 2023: 896–907. doi: 10.1109/HPCA56546.2023.10071133. [68] BRUTZKUS A, GILAD-BACHRACH R, and ELISHA O. Low latency privacy preserving inference[C]. The 36th International Conference on Machine Learning, Long Beach, USA, 2019: 812–821. [69] FAN Shengyu, WANG Zhiwei, XU Weizhi, et al. TensorFHE: Achieving practical computation on encrypted data using GPGPU[C]. 2023 IEEE International Symposium on High-Performance Computer Architecture, Montreal, Canada, 2023: 922–934. doi: 10.1109/HPCA56546.2023.10071017. [70] JIANG Lei, LOU Qian, and JOSHI N. MATCHA: A fast and energy-efficient accelerator for fully homomorphic encryption over the torus[C]. The 59th ACM/IEEE Design Automation Conference, San Francisco, USA, 2022: 235–240. doi: 3489517.3530435. [71] DAI Wei. CUDA-accelerated fully homomorphic encryption library[EB/OL]. https://github.com/vernamlab/cuFHE, 2023. [72] GENER Y S, NEWTON P, TAN D, et al. An FPGA-based programmable vector engine for fast fully homomorphic encryption over the torus[EB/OL]. https://people.ece.ubc.ca/lemieux/publications/gener-spsl2021.pdf, 2021. [73] VAN BEIRENDONCK M, D'ANVERS J P, TURAN F, et al. FPT: A fixed-point accelerator for torus fully homomorphic encryption[C]. The 2023 ACM SIGSAC Conference on Computer and Communications Security, Copenhagen, Denmark, 2023: 741–755. doi: 10.1145/3576915.3623159. [74] YE Tian, KANNAN R, and PRASANNA V K. FPGA acceleration of fully homomorphic encryption over the torus[C]. 2022 IEEE High Performance Extreme Computing Conference, Waltham, USA, 2022: 1–7. doi: 10.1109/HPEC55821.2022.9926381. [75] AL BADAWI A, POLYAKOV Y, AUNG K M M, et al. Implementation and performance evaluation of RNS variants of the BFV homomorphic encryption scheme[J]. IEEE Transactions on Emerging Topics in Computing, 2021, 9(2): 941–956. doi: 10.1109/TETC.2019.2902799. [76] AL BADAWI A, JIN Chao, LIN Jie, et al. Towards the AlexNet moment for homomorphic encryption: HCNN, the first homomorphic CNN on encrypted data with GPUs[J]. IEEE Transactions on Emerging Topics in Computing, 2021, 9(3): 1330–1343. doi: 10.1109/TETC.2020.3014636. [77] DAI W and SUNAR B. cuHE: A homomorphic encryption accelerator library[C]. The 2nd International Conference on Cryptography and Information Security in the Balkans, Koper, Slovenia, 2016: 169–186. doi: 10.1007/978-3-319-29172-7_11. [78] AL BADAWI A, VEERAVALLI B, MUN C F, et al. High-performance FV somewhat homomorphic encryption on GPUs: An implementation using CUDA[J]. IACR Transactions on Cryptographic Hardware and Embedded Systems, 2018, 2018(2): 70–95. doi: 10.13154/tches.v2018.i2.70-95. [79] ÖZERK Ö, ELGEZEN C, MERT A C, et al. Efficient number theoretic transform implementation on GPU for homomorphic encryption[J]. The Journal of Supercomputing, 2022, 78(2): 2840–2872. doi: 10.1007/s11227-021-03980-5. [80] MORSHED T, AL AZIZ M, and MOHAMMED N. CPU and GPU accelerated fully homomorphic encryption[C]. 2020 IEEE International Symposium on Hardware Oriented Security and Trust, San Jose, USA, 2020: 142–153. doi: 10.1109/HOST45689.2020.9300288. -

 下载:
下载:


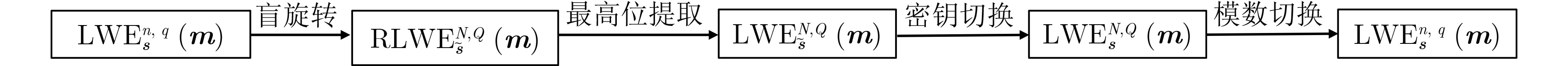




图(8) / 表(4)
计量
- 文章访问数: 3721
- HTML全文浏览量: 2152
- PDF下载量: 605
- 被引次数: 0
