

A New Paradigm for Intelligent Traffic Perception: A Traffic Sign Detection Architecture for the Metaverse
-
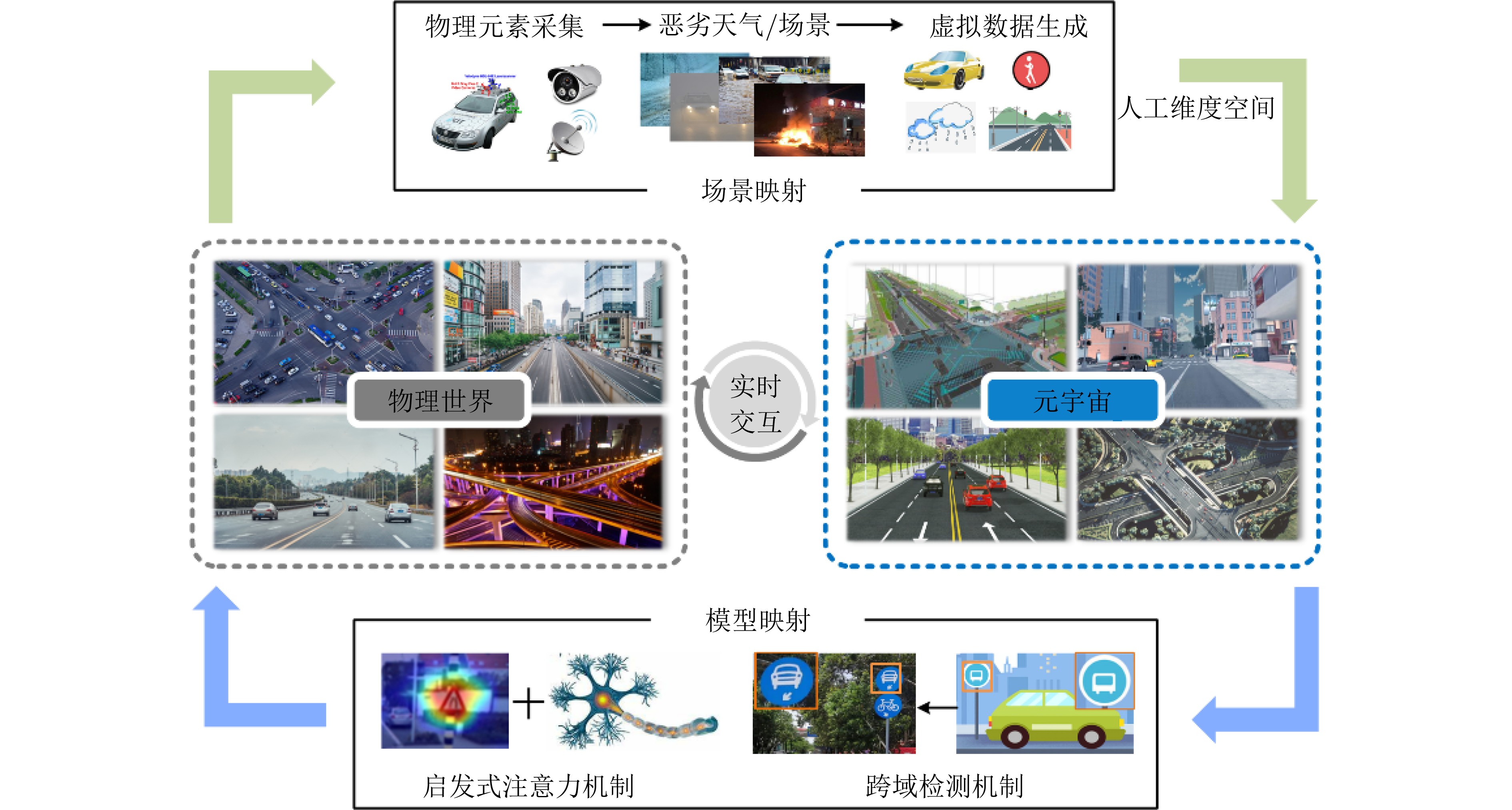
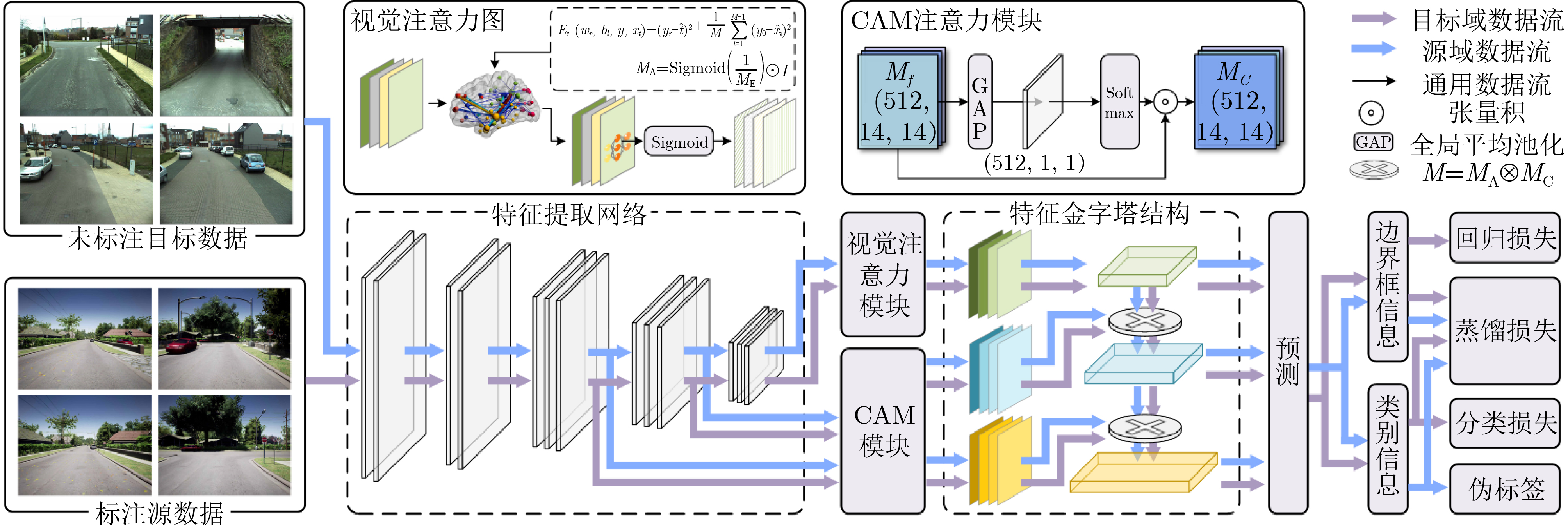
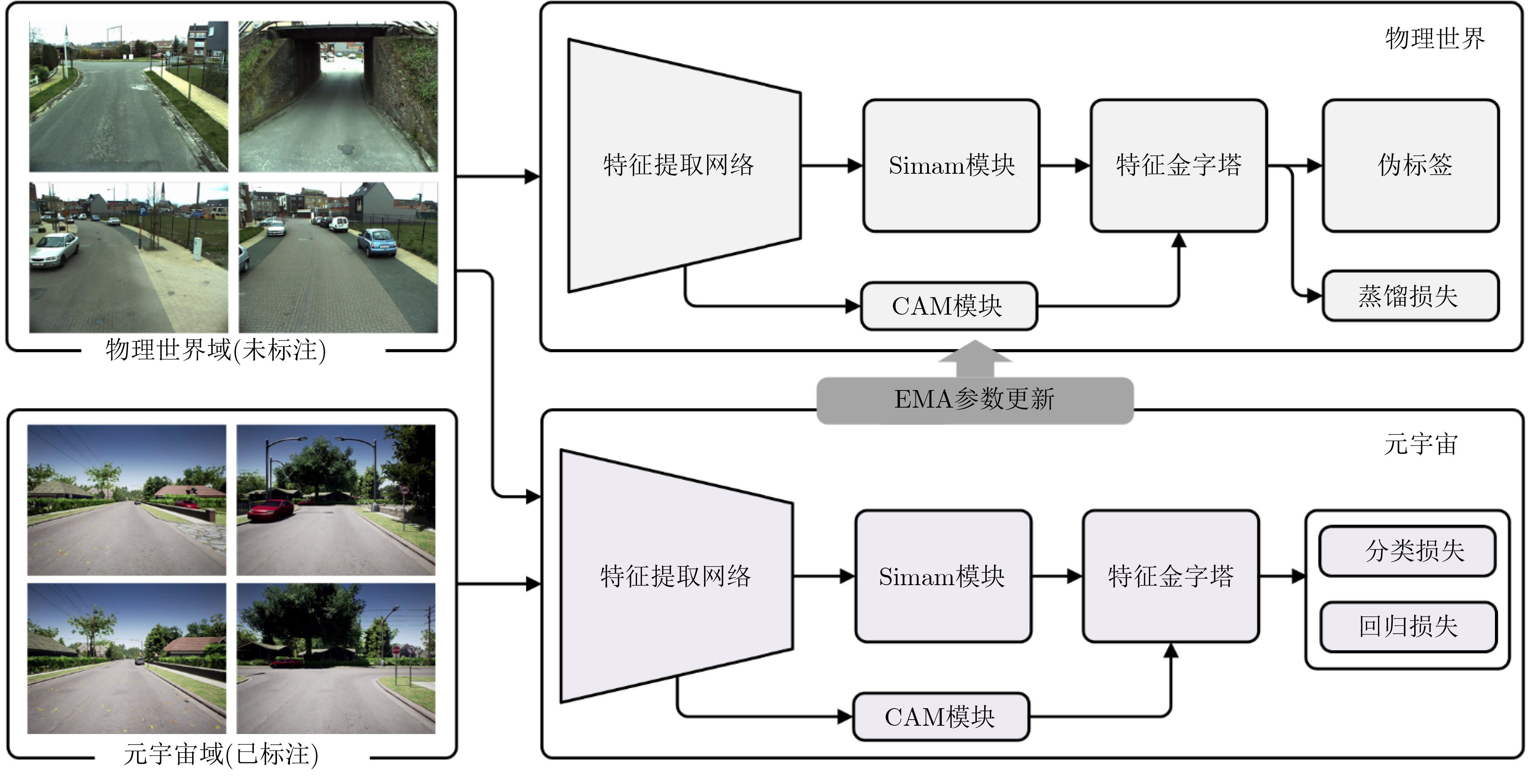
摘要: 交通标志检测对智能交通系统和智能驾驶的安全稳定运行具有重要作用。数据分布不平衡、场景单一会对模型性能造成较大影响,而建立一个完备的真实交通场景数据集需要昂贵的时间成本和人工成本。基于此,该文提出一个面向元宇宙的交通标志检测新范式以缓解现有方法对真实数据的依赖。首先,通过建立元宇宙和物理世界之间的场景映射和模型映射,实现检测算法在虚实世界之间的高效运行。元宇宙作为一个虚拟化的数字世界,能够基于物理世界完成自定义场景构建,为模型提供海量多样的虚拟场景数据。同时,该文结合知识蒸馏和均值教师模型建立模型映射,应对元宇宙和物理世界之间存在的数据差异问题。其次,为进一步提高元宇宙下的训练模型对真实驾驶环境的适应性,该文提出启发式注意力机制,通过对特征的定位和学习来提高检测模型的泛化能力。所提架构在CURE-TSD, KITTI, VKITTI数据集上进行实验验证。实验结果表明,所提面向元宇宙的交通标志检测器在物理世界具有优异的检测效果而不依赖大量真实场景,检测准确率达到89.7%,高于近年来其他检测方法。Abstract: Traffic sign detection plays an important role in the safe and stable operation of intelligent transportation systems and intelligent driving. Unbalanced data distribution and monotonous scene will lead to poor model performance, but building a complete real traffic scene dataset requires expensive time and labor costs. Based on this, a new metaverse-oriented traffic sign detection paradigm is proposed to alleviate the dependence of existing methods on real data. Firstly, by establishing the scene mapping and model mapping between the metaverse and the physical world, the efficient operation of the detection algorithm between the virtual and real worlds is realized. As a virtualized digital world, Metaverse can complete custom scene construction based on the physical world, and provide massive and diverse virtual scene data for the model. At the same time, knowledge distillation and the mean teacher model is combined in this paper to establish a model mapping to deal with the problem of data differences between the metaverse and the physical world. Secondly, in order to further improve the adaptability of the training model under the Metaverse to the real driving environment, a heuristic attention mechanism is designed to improve the generalization ability of the detection model by locating and learning features. The proposed architecture is experimentally verified on the CURE-TSD, KITTI, Virtual KITTI (VKITTI) datasets. Experimental results show that the proposed metaverse-oriented traffic sign detector has excellent detection results in the physical world without relying on a large number of real scenes, and the detection accuracy reaches 89.7%, which is higher than other detection methods of recent years.
-
Key words:
- Metaverse /
- Intelligent transportation systems /
- Traffic sign detection /
- Scene mapping /
- Model mapping
-
表 1 本文主要贡献
参考文献 核心瓶颈 本文贡献 [2–8] 现有基于深度学习的交通标志检测算法依赖于大量的多样数据集进行训练,且实际对算法的测试成本较高,安全性无法得到保证。 本文首次提出了在元宇宙和物理世界实现交通标志检测的新范式。为此,建立了一种场景映射机制,以基于来自物理世界的场景信息构建元宇宙中的交通场景。此外,引入模型映射机制,通过虚拟世界表示增强模型对物理世界中交通标志的识别能力 [9–15] 元宇宙下训练和测试的模型应用于物理世界要求其具备更好的泛化能力,模型性能无差别实现于虚实世界。 本文设计基于启发式注意力的目标检测器。所提出的启发式注意力机制受视神经科学和CAM的启发,结合3维注意力权重的能量函数和目标定位引导,从而提高检测器的特征提取能力和泛化能力。  下载: 导出CSV
下载: 导出CSV
表 2 在CURE-TSD数据集上的对比实验
方法 精度 召回率 mAP AP50 APS APM APL 文献[15] 0.892 0.842 0.489 0.869 0.561 0.806 0.879 文献[3] 0.904 0.834 0.492 0.883 0.557 0.813 0.900 文献[36] 0.896 0.827 0.473 0.878 0.558 0.790 0.876 文献[10] 0.885 0.833 0.481 0.866 0.545 0.784 0.861 本文所提方法(不使用跨域结构) 0.924 0.835 0.514 0.883 0.563 0.801 0.889 本文所提方法+跨域训练 0.897 0.808 0.480 0.848 0.548 0.772 0.863
下载: 导出CSV
表 3 不同训练数据配置下的对比实验
训练数据 方法 精度 召回率 mAP AP50 APS APM APL 20k CURE-TSD中真实场景数据 文献[15] 0.880 0.831 0.468 0.860 0.552 0.793 0.867 文献[3] 0.886 0.819 0.479 0.874 0.544 0.801 0.889 文献[36] 0.876 0.801 0.463 0.863 0.539 0.782 0.864 文献[10] 0.871 0.815 0.468 0.858 0.528 0.772 0.849 本文所提方法+跨域训练 0.904 0.822 0.504 0.870 0.555 0.794 0.876 10k Meta-TSD和CURE-TSD中
虚拟场景数据+5k CURE-TSD中
真实场景数据文献[15] 0.853 0.801 0.429 0.810 0.519 0.736 0.851 文献[3] 0.871 0.802 0.437 0.821 0.525 0.741 0.861 文献[36] 0.863 0.792 0.422 0.827 0.513 0.749 0.848 文献[10] 0.821 0.804 0.445 0.801 0.502 0.729 0.837 本文所提方法+跨域训练 0.892 0.804 0.458 0.826 0.537 0.757 0.862
下载: 导出CSV
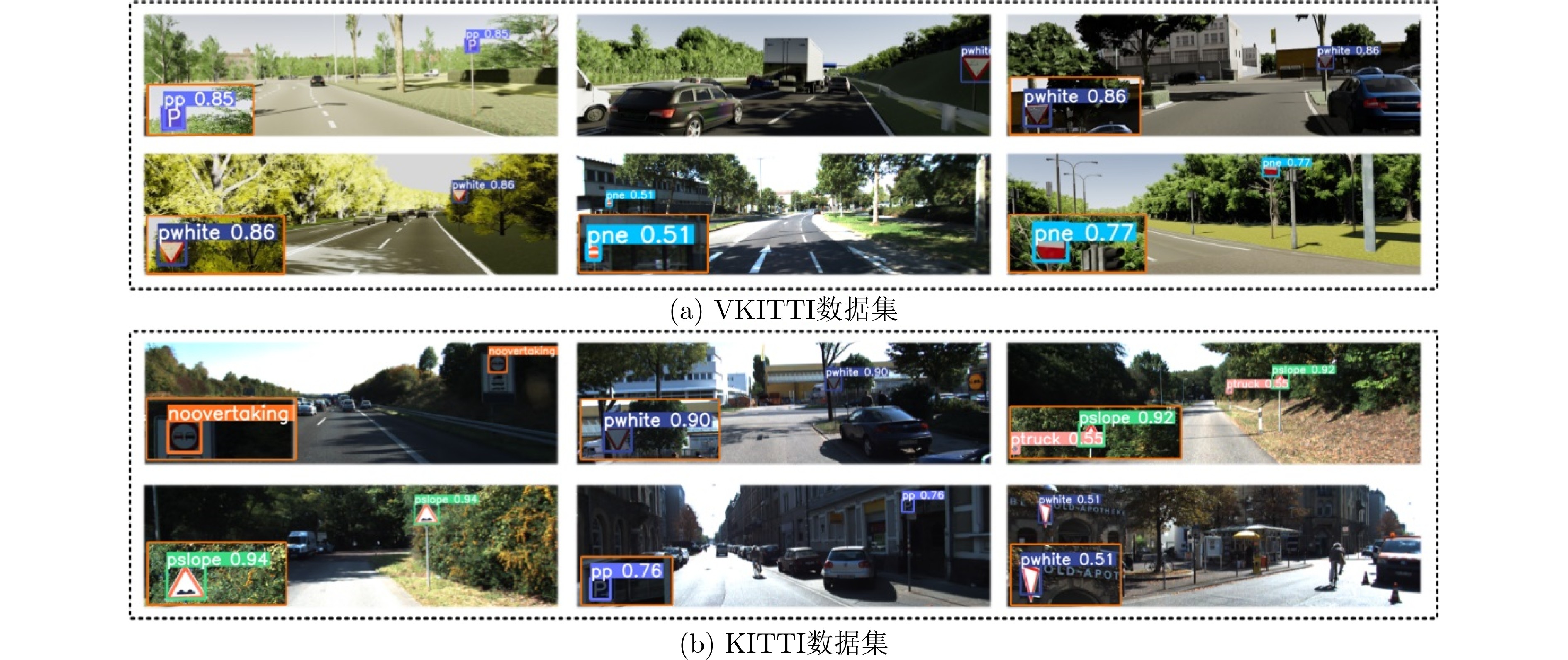
表 4 提出方法在KITTI, VKITTI数据集上测试结果
数据集 精度 平均置信度 




KITTI 0.757 0.747 0.821 0.793 0.781 0.755 0.735 VKITTI 0.781 0.774 0.843 0.825 0.817 0.776 0.768 *备注:  下载: 导出CSV
下载: 导出CSV
表 5 在CURE-TSD数据集上的消融实验
启发式注意力 跨域检测结构 精度 召回率 GFLOPs 0.887 0.796 15.6 √ 0.924 0.835 16.9 √ 0.853 0.764 31.2 √ √ 0.897 0.808 33.8
下载: 导出CSV
-
[1] KUSUMA A T and SUPANGKAT S H. Metaverse fundamental technologies for smart city: A literature review[C]. 2022 International Conference on ICT for Smart Society (ICISS), Bandung, Indonesia, 2022: 1–7. doi: 10.1109/ICISS55894.2022.9915079. [2] TEMEL D, CHEN M H, and ALREGIB G. Traffic sign detection under challenging conditions: A deeper look into performance variations and spectral characteristics[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(9): 3663–3673. doi: 10.1109/TITS.2019.2931429. [3] LIU Yuanyuan, PENG Jiyao, XUE Jinghao, et al. TSingNet: Scale-aware and context-rich feature learning for traffic sign detection and recognition in the wild[J]. Neurocomputing, 2021, 447: 10–22. doi: 10.1016/j.neucom.2021.03.049. [4] LARSSON F and FELSBERG M. Using fourier descriptors and spatial models for traffic sign recognition[C]. The 17th Scandinavian Conference on Image Analysis, Ystad, Sweden, 2011: 238–249. doi: 10.1007/978-3-642-21227-7_23. [5] 董哲康, 钱智凯, 周广东, 等. 基于忆阻的全功能巴甫洛夫联想记忆电路的设计、实现与分析[J]. 电子与信息学报, 2022, 44(6): 2080–2092. doi: 10.11999/JEIT210376.DONG Zhekang, QIAN Zhikai, ZHOU Guangdong, et al. Memory circuit design, implementation and analysis based on memristor full-function pavlov associative[J]. Journal of Electronics & Information Technology, 2022, 44(6): 2080–2092. doi: 10.11999/JEIT210376. [6] HORN D and HOUBEN S. Fully automated traffic sign substitution in real-world images for large-scale data augmentation[C]. 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, USA, 2020: 465–471. doi: 10.1109/IV47402.2020.9304547. [7] 杨宇翔, 曹旗, 高明煜, 等. 基于多阶段多尺度彩色图像引导的道路场景深度图像补全[J]. 电子与信息学报, 2022, 44(11): 3951–3959. doi: 10.11999/JEIT210967.YANG Yuxiang, CAO Qi, GAO Mingyu, et al. Multi-stage multi-scale color guided depth image completion for road scenes[J]. Journal of Electronics & Information Technology, 2022, 44(11): 3951–3959. doi: 10.11999/JEIT210967. [8] MIN Weidong, LIU Ruikang, HE Daojing, et al. Traffic sign recognition based on semantic scene understanding and structural traffic sign location[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(9): 15794–15807. doi: 10.1109/TITS.2022.3145467. [9] 董哲康, 杜晨杰, 林辉品, 等. 基于多通道忆阻脉冲耦合神经网络的多帧图像超分辨率重建算法[J]. 电子与信息学报, 2020, 42(4): 835–843. doi: 10.11999/JEIT190868.DONG Zhekang, DU Chenjie, LIN Huipin, et al. Multi-channel memristive pulse coupled neural network based multi-frame images super-resolution reconstruction algorithm[J]. Journal of Electronics & Information Technology, 2020, 42(4): 835–843. doi: 10.11999/JEIT 190868. [10] LI Zhishan, CHEN Mingmu, HE Yifan, et al. An efficient framework for detection and recognition of numerical traffic signs[C]. 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 2022: 2235–2239. doi: 10.1109/ICASSP43922.2022.9747406. [11] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [12] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 213–229. doi: 10.1007/978-3-030-58452-8_13. [13] HAN Kai, WANG Yunhe, CHEN Hanting, et al. A survey on vision transformer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 87–110. doi: 10.1109/TPAMI.2022.3152247. [14] WEI Hongyang, ZHANG Qianqian, QIAN Yurong, et al. MTSDet: Multi-scale traffic sign detection with attention and path aggregation[J]. Applied Intelligence, 2023, 53(1): 238–250. doi: 10.1007/s10489-022-03459-7. [15] WANG Junfan, CHEN Yi, DONG Zhekang, et al. Improved YOLOv5 network for real-time multi-scale traffic sign detection[J]. Neural Computing and Applications, 2023, 35(10): 7853–7865. doi: 10.1007/s00521-022-08077-5. [16] KIM J Y and OH J M. Opportunities and challenges of metaverse for automotive and mobility industries[C]. The 13th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 2022: 113–117. doi: 10.1109/ICTC55196.2022.9952976. [17] ZHANG Hui, LUO Guiyang, LI Yidong, et al. Parallel vision for intelligent transportation systems in metaverse: Challenges, solutions, and potential applications[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2023, 53(6): 3400–3413. doi: 10.1109/TSMC.2022.3228314. [18] JIANG Pengtao, ZHANG Changbin, HOU Qibin, et al. LayerCAM: Exploring hierarchical class activation maps for localization[J]. IEEE Transactions on Image Processing, 2021, 30: 5875–5888. doi: 10.1109/TIP.2021.3089943. [19] THORPE S, FIZE D, and MARLOT C. Speed of processing in the human visual system[J]. Nature, 1996, 381(6582): 520–522. doi: 10.1038/381520a0. [20] GAIDON A, WANG Qiao, CABON Y, et al. VirtualWorlds as proxy for multi-object tracking analysis[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 4340–4349. doi: 10.1109/CVPR.2016.470. [21] GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: The KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231–1237. doi: 10.1177/0278364913491297. [22] SHREINER D. OpenGL Programming Guide: The Official Guide to Learning OpenGL, Versions 3.0 and 3.1[M]. Addison-Wesley Professional, 2009. [23] TORII A, HAVLENA M, and PAJDLA T. From google street view to 3D city models[C]. The IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 2009: 2188–2195. doi: 10.1109/ICCVW.2009.5457551. [24] NJOKU J N, NWAKANMA C I, AMAIZU G C, et al. Prospects and challenges of Metaverse application in data-driven intelligent transportation systems[J]. IET Intelligent Transport Systems, 2023, 17(1): 1–21. doi: 10.1049/itr2.12252. [25] PAMUCAR D, DEVECI M, GOKASAR I, et al. A metaverse assessment model for sustainable transportation using ordinal priority approach and Aczel-Alsina norms[J]. Technological Forecasting and Social Change, 2022, 182: 121778. doi: 10.1016/j.techfore.2022.121778. [26] SONG Jie, CHEN Ying, YE Jingwen, et al. Spot-adaptive knowledge distillation[J]. IEEE Transactions on Image Processing, 2022, 31: 3359–3370. doi: 10.1109/TIP.2022.3170728. [27] LIU Yuyuan, TIAN Yu, CHEN Yuanhong, et al. Perturbed and strict mean teachers for semi-supervised semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 4248–4257. doi: 10.1109/CVPR52688.2022.00422. [28] 张润丰, 姚伟, 石重托, 等. 融合虚拟对抗训练和均值教师模型的主导失稳模式识别半监督学习框架[J]. 中国电机工程学报, 2022, 42(20): 7497–7508. doi: 10.13334/j.0258-8013.pcsee.211673.ZHANG Runfeng, YAO Wei, SHI Zhongtuo, et al. Semi-supervised learning framework of dominant instability mode identification via fusion of virtual adversarial training and mean teacher model[J]. Proceedings of the CSEE, 2022, 42(20): 7497–7508. doi: 10.13334/j.0258-8013.pcsee.211673. [29] DING Xiaohan, ZHANG Xiangyu, MA Ningning, et al. RepVGG: Making VGG-style ConvNets great again[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 13728–13737. doi: 10.1109/CVPR46437.2021.01352. [30] WANG Jibin and ZHANG Shuo. An improved deep learning approach based on exponential moving average algorithm for atrial fibrillation signals identification[J]. Neurocomputing, 2022, 513: 127–136. doi: 10.1016/j.neucom.2022.09.079. [31] CHAUDHARI S, MITHAL V, POLATKAN G, et al. An attentive survey of attention models[J]. ACM Transactions on Intelligent Systems and Technology, 2021, 12(5): 53. doi: 10.1145/3465055. [32] RUEDA M R, POZUELOS J P, CÓMBITA L M, et al. Cognitive neuroscience of attention from brain mechanisms to individual differences in efficiency[J]. AIMS Neuroscience, 2015, 2(4): 183–202. doi: 10.3934/Neuroscience.2015.4.183. [33] ROSSI L F, HARRIS K D, and CARANDINI M. Spatial connectivity matches direction selectivity in visual cortex[J]. Nature, 2020, 588(7839): 648–652. doi: 10.1038/s41586-020-2894-4. [34] LUO Zhengding, LI Junting, and ZHU Yuesheng. A deep feature fusion network based on multiple attention mechanisms for joint iris-periocular biometric recognition[J]. IEEE Signal Processing Letters, 2021, 28: 1060–1064. doi: 10.1109/LSP.2021.3079850. [35] WANG Junfan, CHEN Yi, JI Xiaoyue, et al. Vehicle-mounted adaptive traffic sign detector for small-sized signs in multiple working conditions[J]. IEEE Transactions on Intelligent Transportation Systems, doi: 10.1109/TITS.2023.3309644. [36] GU Yang and SI Bingfeng. A novel lightweight real-time traffic sign detection integration framework based on YOLOv4[J]. Entropy, 2022, 24(4): 487. doi: 10.3390/e24040487. -

 下载:
下载:







图(9) / 表(5)
计量
- 文章访问数: 1614
- HTML全文浏览量: 684
- PDF下载量: 148
- 被引次数: 0
