

Multi-Head Attention Time Domain Audiovisual Speech Separation Based on Dual-Path Recurrent Network and Conv-TasNet
-
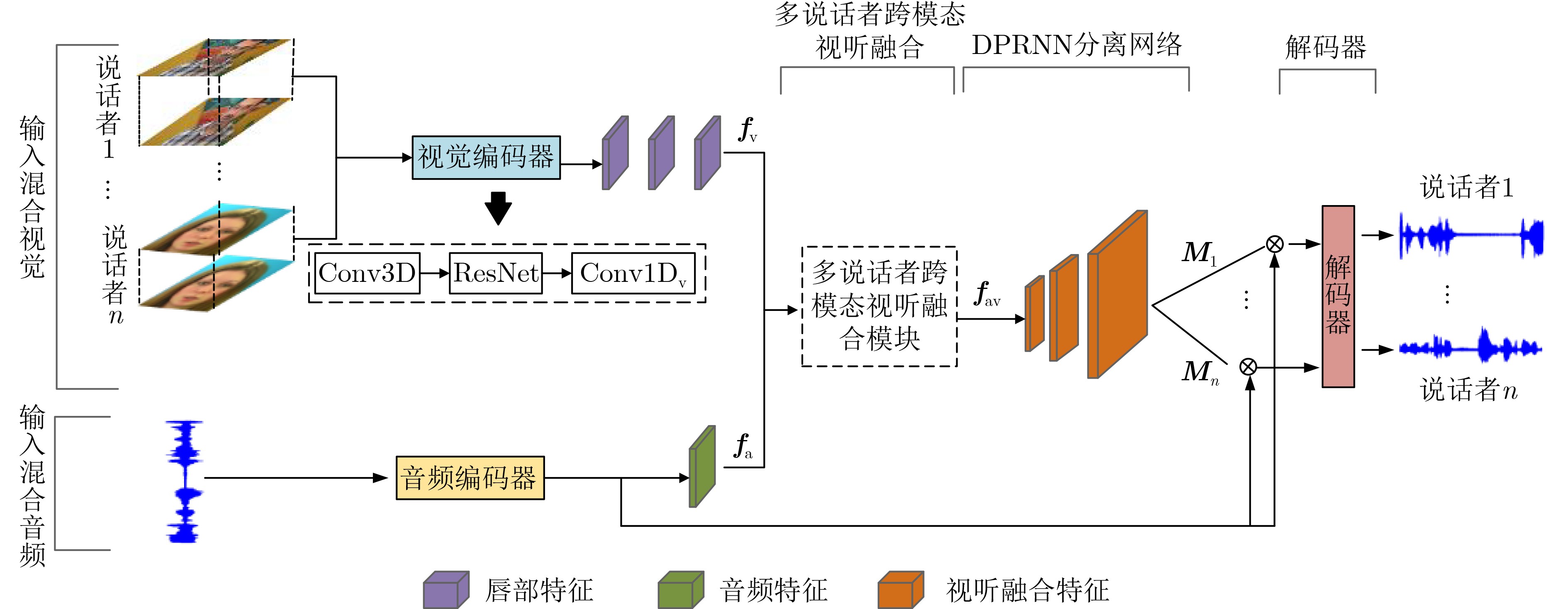
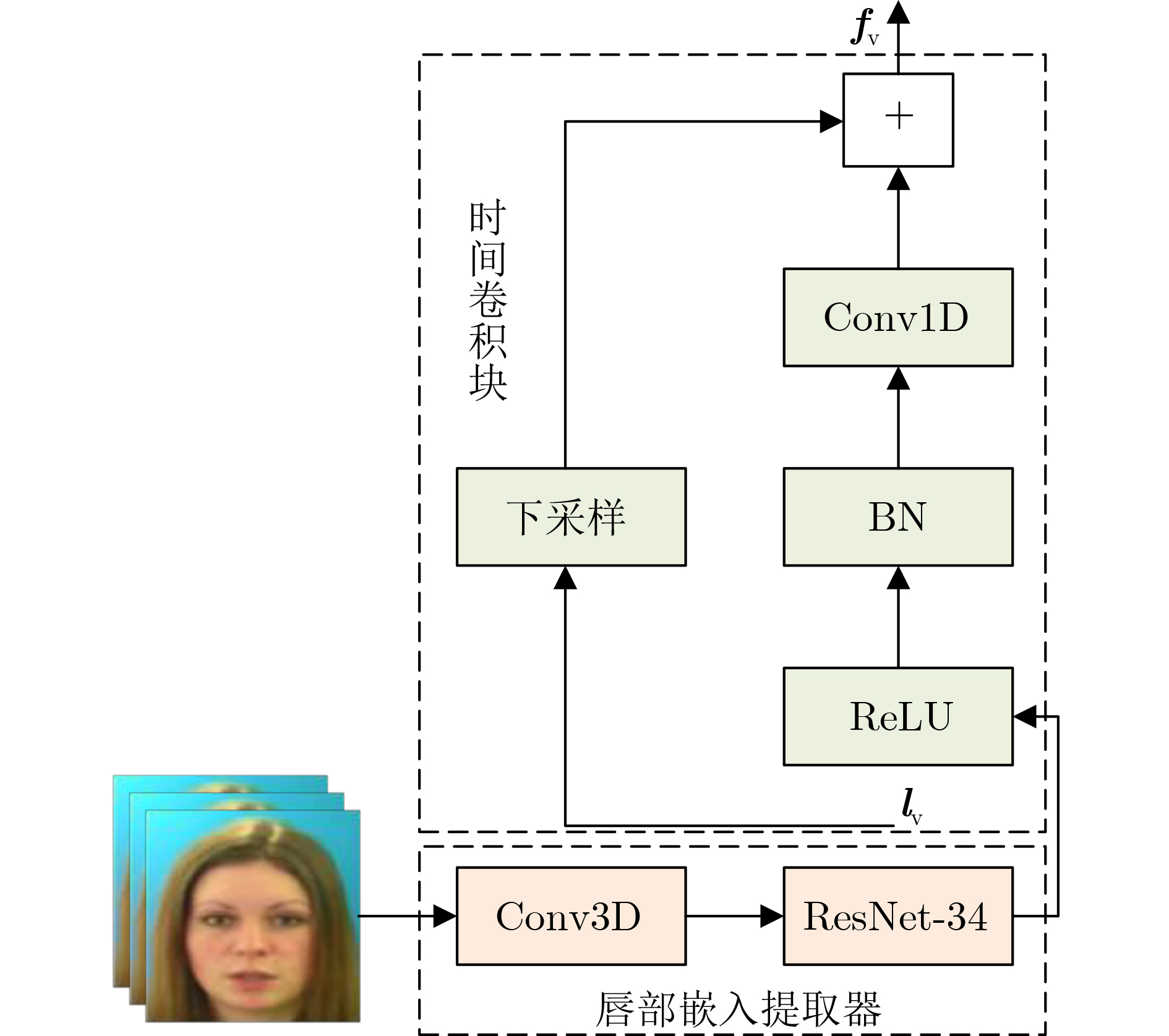
摘要: 目前的视听语音分离模型基本是将视频特征和音频特征进行简单拼接,没有充分考虑各个模态的相互关系,导致视觉信息未被充分利用,分离效果不理想。该文充分考虑视觉特征、音频特征之间的相互联系,采用多头注意力机制,结合卷积时域分离模型(Conv-TasNet)和双路径递归神经网络(DPRNN),提出多头注意力机制时域视听语音分离(MHATD-AVSS)模型。通过音频编码器与视觉编码器获得音频特征与视频的唇部特征,并采用多头注意力机制将音频特征与视觉特征进行跨模态融合,得到融合视听特征,将其经DPRNN分离网络,获得不同说话者的分离语音。利用客观语音质量评估(PESQ)、短时客观可懂度(STOI)及信噪比(SNR)评价指标,在VoxCeleb2数据集进行实验测试。研究表明,当分离两位、3位或4位说话者的混合语音时,该文方法与传统分离网络相比,SDR提高量均在1.87 dB以上,最高可达2.29 dB。由此可见,该文方法能考虑音频信号的相位信息,更好地利用视觉信息与音频信息的相关性,提取更为准确的音视频特性,获得更好的分离效果。
-
关键词:
- 语音分离 /
- 视听融合 /
- 跨模态注意力 /
- 双路径递归网络 /
- Conv-TasNet
Abstract: The current audiovisual speech separation model is essentially the simple splicing of video and audio features without fully considering the interrelationship of each modality, resulting in the underutilization of visual information and unsatisfactory separation effects. The article adequately considers the interconnection between visual features and audio features, adopts a multi-headed attention mechanism, and combines the Convolutional Time-domain audio separation Network (Conv-TasNet) and Dual-Path Recurrent Neural Network (DPRNN), the Multi-Head Attention Time Domain AudioVisual Speech Separation (MHATD-AVSS) model is proposed. The audio encoder and the visual encoder are used to obtain the audio features and the lip features of the video, and the multi-head attention mechanism is used to cross-modality fuse the audio features with the visual features to obtain the audiovisual fusion features, which are passed through the DPRNN separation network to obtain the separated speech of different speakers. The Perceptual Evaluation of Speech Quality (PESQ), Short-Time Objective Intelligibility (STOI), and Signal-to-Noise Ratio (SNR) evaluation metrics are used for experimental testing in the VoxCeleb2 dataset. The research shows that when separating the mixed speech of two, three, or four speakers, the SDR improvement of the method in this paper is above 1.87 dB and up to 2.29 dB compared with the traditional separation network. In summary, this article shows that the method can consider the phase information of the audio signal, better use the correlation between visual information and audio information, extract more accurate audio and video characteristics, and obtain better separation effects. -
表 1 MHATD-AVSS模型的消融实验
模型 SDR(dB) PESQ STOI AV基线[19] 9.15 2.68 0.84 DPRNN+特征拼接 9.53 2.70 0.84 TCN+SCMA 9.83 2.71 0.85 DPRNN+SCMA 10.31 2.73 0.86 MHATD-AVSS 11.02 2.75 0.87  下载: 导出CSV
下载: 导出CSV
-
[1] SUN Peng, WU Dongping, and LIU Chaoran. High-sensitivity tactile sensor based on Ti2C-PDMS sponge for wireless human–computer interaction[J]. Nanotechnology, 2021, 32(29): 295506. doi: 10.1088/1361-6528/ABF59E. [2] CHERRY E C. Some experiments on the recognition of speech, with one and with two ears[J]. The Journal of the Acoustical Society of America, 1953, 25(5): 975–979. doi: 10.1121/1.1907229. [3] LUTFI R A, RODRIGUEZ B, and LEE J. Effect of listeners versus experimental factors in multi-talker speech segregation[J]. The Journal of the Acoustical Society of America, 2021, 149(S4): A105. doi: 10.1121/10.0004656. [4] COMON P. Independent component analysis, a new concept?[J]. Signal Processing, 1994, 36(3): 287–314. doi: 10.1016/0165-1684(94)90029-9. [5] LEE D D and SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755): 788–791. doi: 10.1038/44565. [6] PARSONS T W. Separation of speech from interfering speech by means of harmonic selection[J]. The Journal of the Acoustical Society of America, 1976, 60(4): 911–918. doi: 10.1121/1.381172. [7] HERSHEY J R, CHEN Zhuo, LE ROUX J, et al. Deep clustering: Discriminative embeddings for segmentation and separation[C]. 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 2016: 31–35. [8] YU Dong, KOLBÆK M, TAN Zhenghua, et al. Permutation invariant training of deep models for speaker-independent multi-talker speech separation[C]. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, USA, 2017: 241–245. [9] KOLBæK M, YU Dong, TAN Zhenghua, et al. Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(10): 1901–1913. doi: 10.1109/TASLP.2017.2726762. [10] WAGEMANS J, FELDMAN J, GEPSHTEIN S, et al. A century of gestalt psychology in visual perception: II. Conceptual and theoretical foundations[J]. Psychological Bulletin, 2012, 138(6): 1218–1252. doi: 10.1037/a0029334. [11] GOLUMBIC E Z, COGAN G B, SCHROEDER C E, et al. Visual input enhances selective speech envelope tracking in auditory cortex at a "cocktail party"[J]. The Journal of Neuroscience, 2013, 33(4): 1417–1426. doi: 10.1523/JNEUROSCI.3675-12.2013. [12] TAO Ruijie, PAN Zexu, DAS R K, et al. Is someone speaking?: Exploring long-term temporal features for audio-visual active speaker detection[C]. The 29th ACM International Conference on Multimedia, Chengdu, China, 2021: 3927–3935. [13] LAKHAN A, MOHAMMED M A, KADRY S, et al. Federated learning-aware multi-objective modeling and blockchain-enable system for IIoT applications[J]. Computers and Electrical Engineering, 2022, 100: 107839. doi: 10.1016/j.compeleceng.2022.107839. [14] MORGADO, LI Yi, and VASCONCELOS N. Learning representations from audio-visual spatial alignment[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 397. [15] FLEMING J T, MADDOX R K, and SHINN-CUNNINGHAM B G. Spatial alignment between faces and voices improves selective attention to audio-visual speech[J]. The Journal of the Acoustical Society of America, 2021, 150(4): 3085–3100. doi: 10.1121/10.0006415. [16] LUO Yi and MESGARANI N. TaSNet: Time-domain audio separation network for real-time, single-channel speech separation[C]. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 2018: 696–700. [17] LUO Yi and MESGARANI N. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256–1266. doi: 10.1109/TASLP.2019.2915167. [18] LUO Yi, CHEN Zhuo, and YOSHIOKA T. Dual-path RNN: Efficient long sequence modeling for time-domain single-channel speech separation[C]. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 46–50. [19] WU Jian, XU Yong, ZHANG Shixiong, et al. Time domain audio visual speech separation[C]. 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 2019: 667–673. [20] 范存航, 刘斌, 陶建华, 等. 一种基于卷积神经网络的端到端语音分离方法[J]. 信号处理, 2019, 35(4): 542–548. doi: 10.16798/j.issn.1003-0530.2019.04.003.FAN Cunhang, LIU Bin, TAO Jianhua, et al. An end-to-end speech separation method based on convolutional neural network[J]. Journal of Signal Processing, 2019, 35(4): 542–548. doi: 10.16798/j.issn.1003-0530.2019.04.003. [21] 徐亮, 王晶, 杨文镜, 等. 基于Conv-TasNet的多特征融合音视频联合语音分离算法[J]. 信号处理, 2021, 37(10): 1799–1805. doi: 10.16798/j.issn.1003-0530.2021.10.002.XU Liang, WANG Jing, YANG Wenjing, et al. Multi feature fusion audio-visual joint speech separation algorithm based on Conv-TasNet[J]. Journal of Signal Processing, 2021, 37(10): 1799–1805. doi: 10.16798/j.issn.1003-0530.2021.10.002. [22] GAO Ruohan and GRAUMAN K. VisualVoice: Audio-visual speech separation with cross-modal consistency[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 15490–15500. [23] XIONG Junwen, ZHANG Peng, XIE Lei, et al. Audio-visual speech separation based on joint feature representation with cross-modal attention[J]. arvix: 2203.02655, 2022. [24] ZHANG Peng, XU Jiaming, SUI Jing, et al. Audio-visual speech separation with adversarially disentangled visual representation[J]. arXiv: 2011.14334, 2020. [25] WU Yifei, LI Chenda, BAI Jinfeng, et al. Time-domain audio-visual speech separation on low quality videos[C]. ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 2022: 256–260. [26] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [27] CHUNG J S, NAGRANI A, and ZISSERMAN A. VoxCeleb2: Deep speaker recognition[C]. Interspeech 2018, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2018: 1086–1090. -

 下载:
下载:


图(3) / 表(2)
计量
- 文章访问数: 1294
- HTML全文浏览量: 745
- PDF下载量: 94
- 被引次数: 0
