

Design of Transformer Accelerator with Regular Compression Model and Flexible Architecture
-
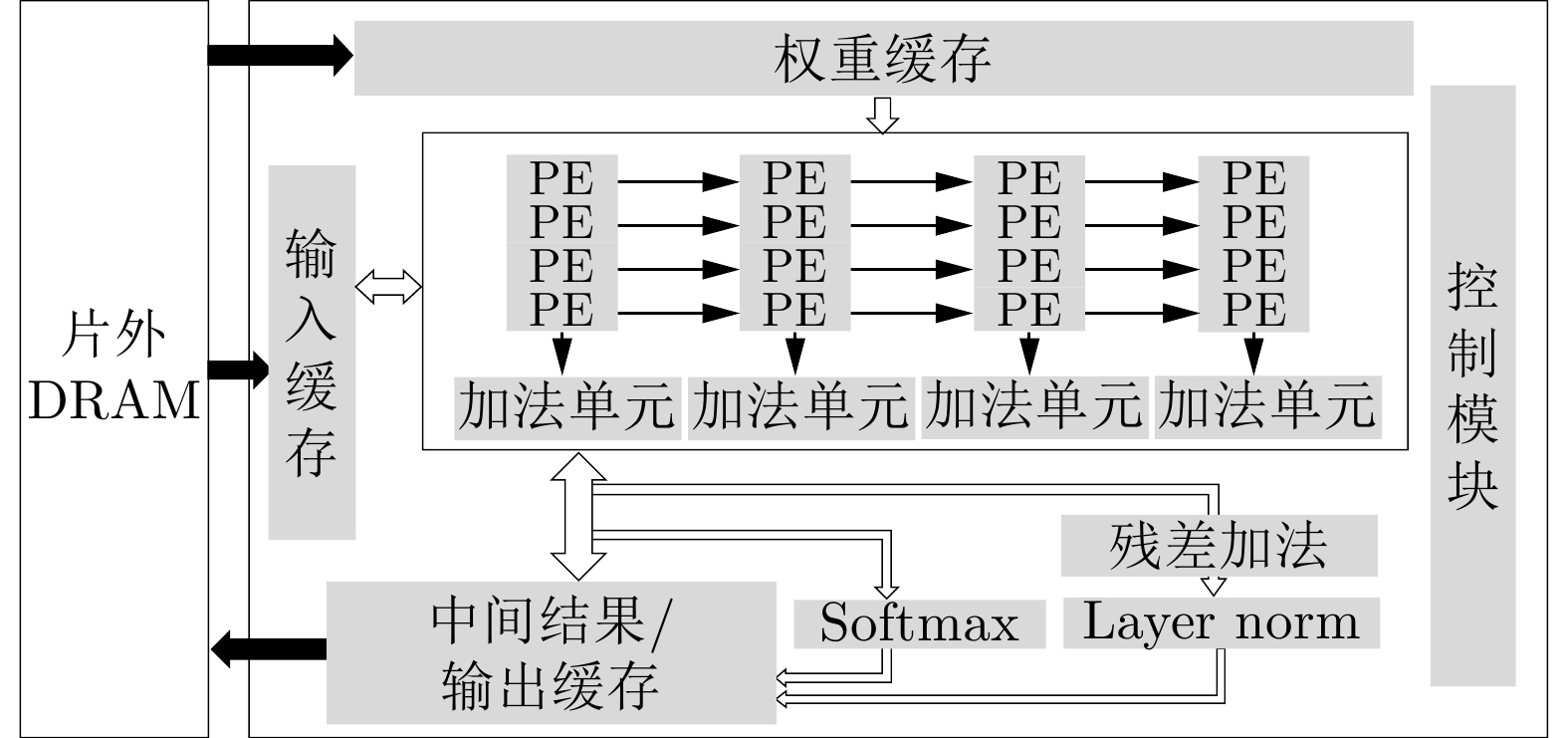
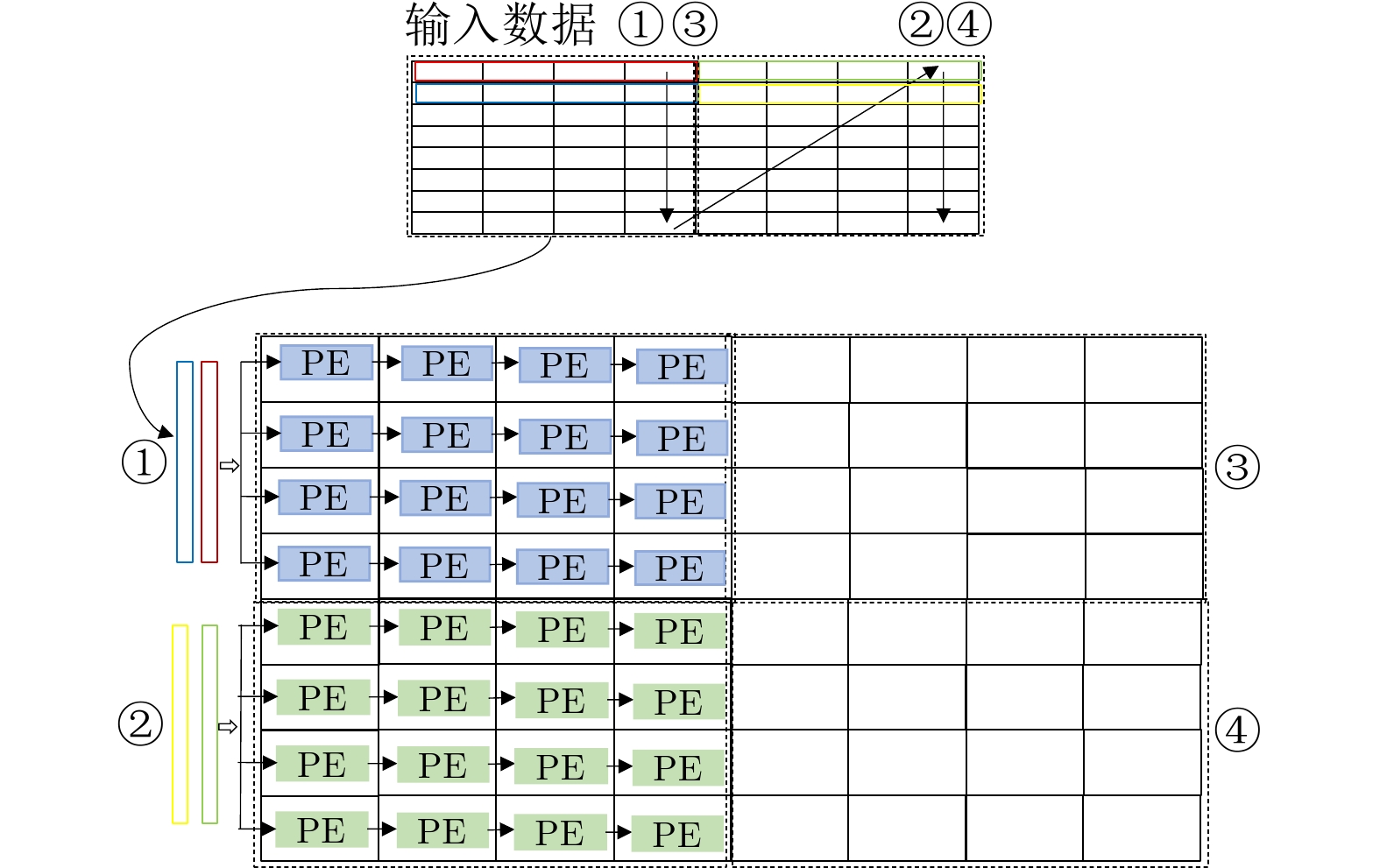
摘要: 基于注意力机制的Transformer模型具有优越的性能,设计专用的Transformer加速器能大幅提高推理性能以及降低推理功耗。Transformer模型复杂性包括数量上和结构上的复杂性,其中结构上的复杂性导致不规则模型和规则硬件之间的失配,降低了模型映射到硬件的效率。目前的加速器研究主要聚焦在解决模型数量上的复杂性,但对如何解决模型结构上的复杂性研究得不多。该文首先提出规则压缩模型,降低模型的结构复杂度,提高模型和硬件的匹配度,提高模型映射到硬件的效率。接着提出一种硬件友好的模型压缩方法,采用规则的偏移对角权重剪枝方案和简化硬件量化推理逻辑。此外,提出一个高效灵活的硬件架构,包括一种以块为单元的权重固定脉动运算阵列,同时包括一种准分布的存储架构。该架构可以高效实现算法到运算阵列的映射,同时实现高效的数据存储效率和降低数据移动。实验结果表明,该文工作在性能损失极小的情况下实现93.75%的压缩率,在FPGA上实现的加速器可以高效处理压缩后的Transformer模型,相比于中央处理器 (CPU)和图形处理器 (GPU)能效分别提高了12.45倍和4.17倍。
-
关键词:
- 自然语音处理 /
- Transformer /
- 模型压缩 /
- 硬件加速器 /
- 机器翻译
Abstract: The Transformer model based on attention mechanism demonstrates superior performance. The complexity of the Transformer model includes both quantity and structural complexity, where the structural complexity leads to a mismatch between irregular models and regular hardware, reducing the efficiency of mapping the model to the hardware. Current accelerator research mainly focuses on addressing the complexity in terms of model quantity, but there is limited research on how to tackle the complexity in model structure. A regularized compressed model is proposd to reduce the structural complexity of the model, improving the matching between the model and the hardware, and increasing the efficiency of mapping the model to the hardware. A hardware-friendly model compression method is introduced, which utilizes a rule-based pruning scheme for weight with offset diagonals and simplifies the hardware quantization inference logic.An efficient and flexible hardware architecture is also present, including a pulsatile operation array with weight fixed at the block level, as well as a quasi-distributed storage architecture. This architecture enables efficient mapping of algorithms to the operation array, while achieving high data storage efficiency and reducing data movement. Experimental results show that the proposed approach achieves a compression rate of 93.75% with minimal performance loss. The accelerator implemented on an FPGA can efficiently handle the compressed Transformer model, resulting in energy efficiency improvements of 12.45 times compared to Central Processing Unit (CPU) and 4.17 times compared to Graphics Processing Unit (GPU).n energy efficiency improvements of 12.45 times compared to Central Processing Unit (CPU) and 4.17 times compared to Graphics Processing Unit (GPU). -
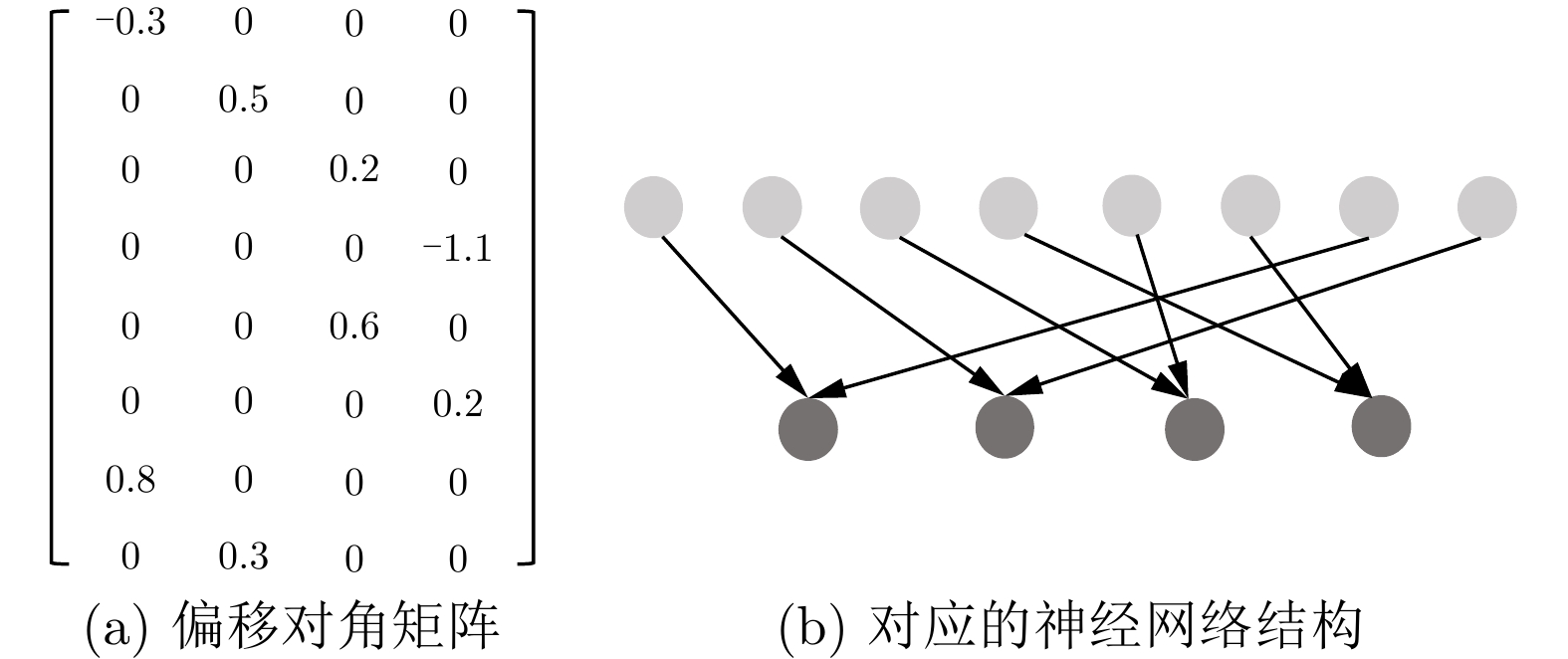
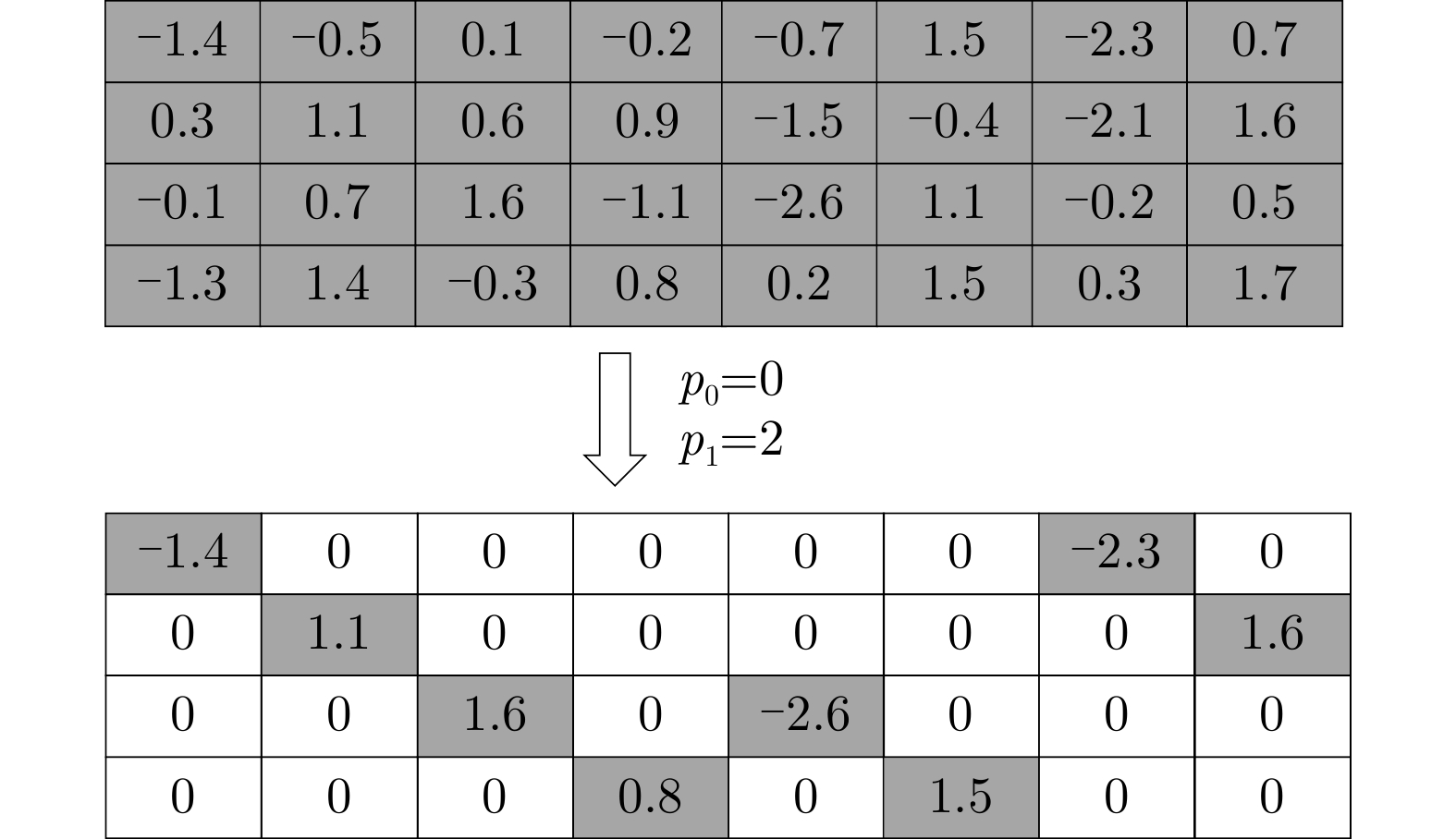
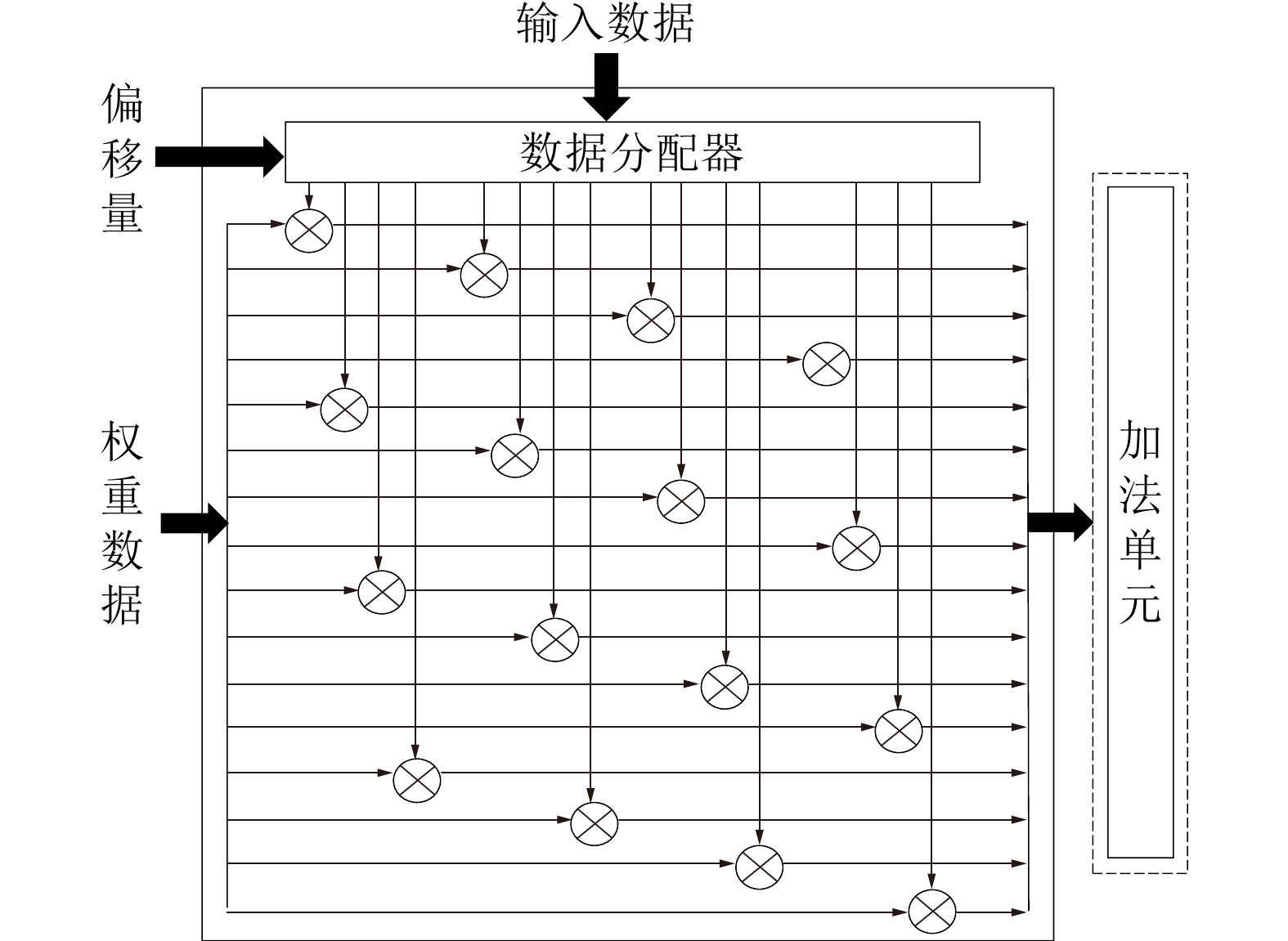
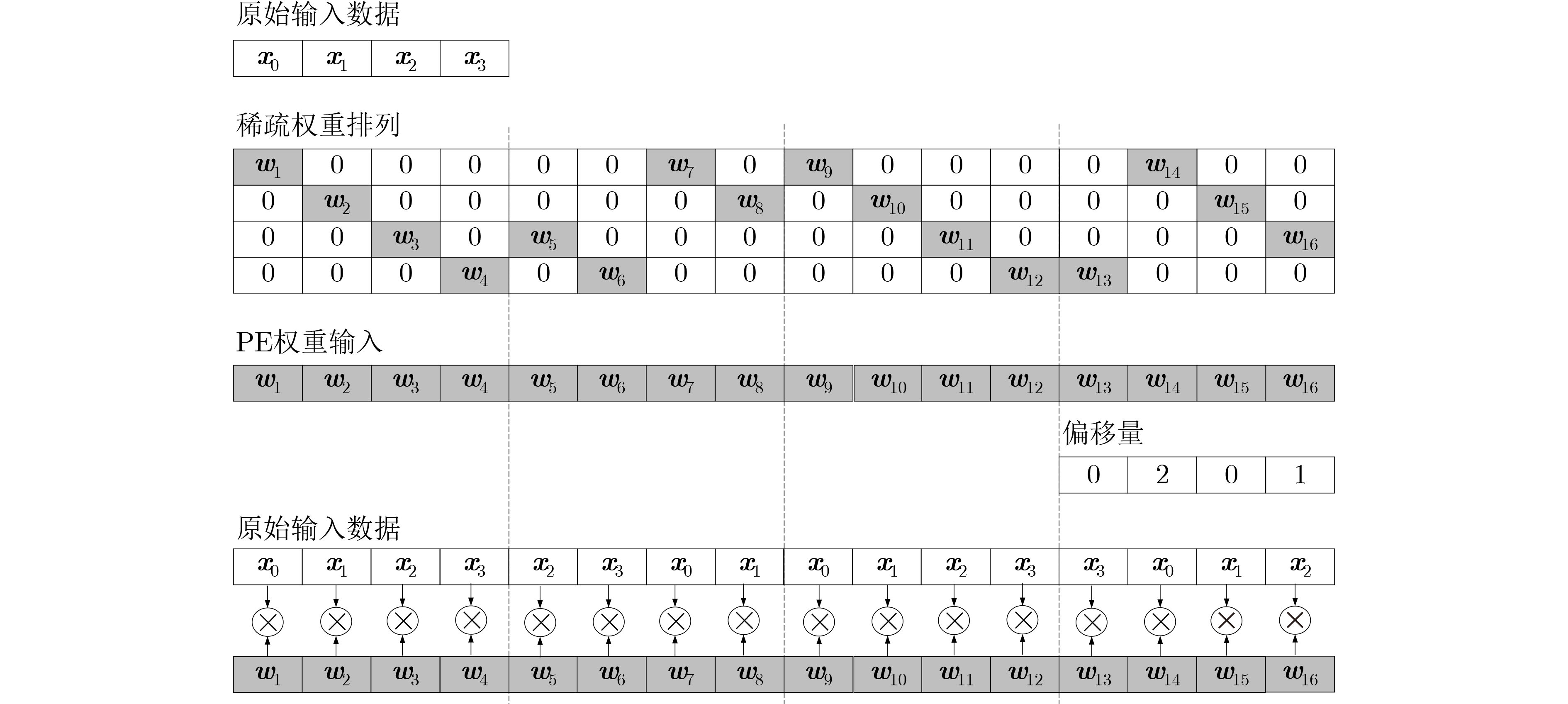
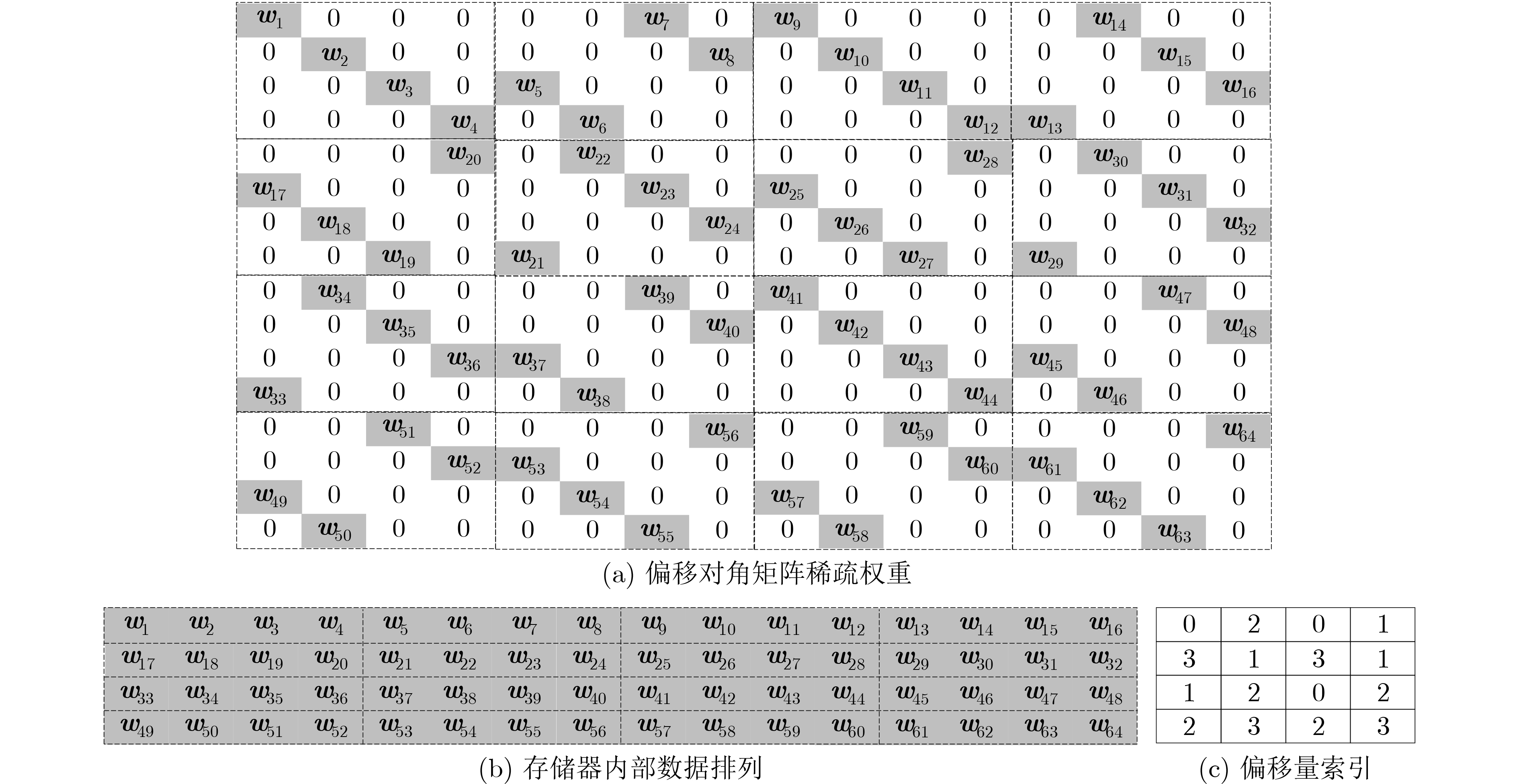
算法1 单位偏移对角剪枝 输入: model 输出: Pruned model model.train; GetOffset(model.weight (Q,K,V)) Prune(model_weight (Q,K,V)) model.train; GetOffset(model.weight (O)) Prune(model_weight (O)) model.train; GetOffset(model.weight (FFN1)) Prune(model_weight (FFN1)) model.train; GetOffset (model.weight (FFN2)) Prune (model_weight (FFN2)) model_train;  下载: 导出CSV
下载: 导出CSV
表 3 Transformer模型(base)实验结果
数据集 参数量(MB) BLEU IWSLT-2014(De-En) 176 34.5 IWSLT-2014(En-De) 176 28.5
下载: 导出CSV
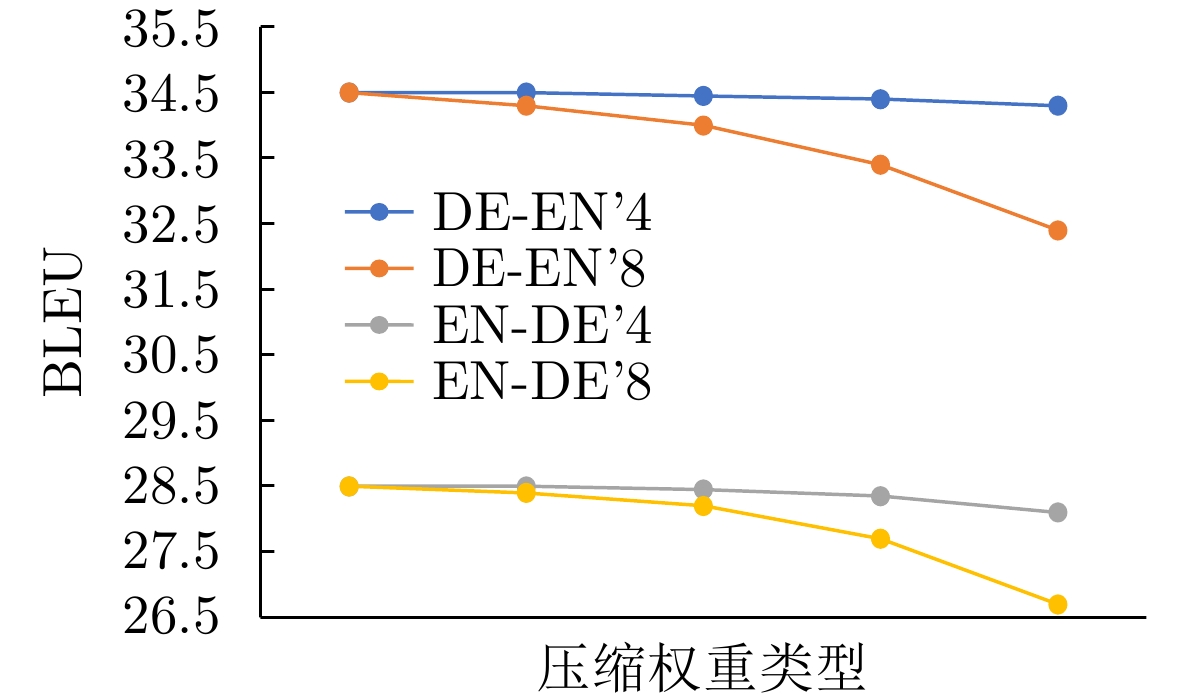
表 4 Transformer模型剪枝实验结果
数据集 参数量(MB) 子矩阵大小 BLEU 压缩率(%) 性能损失(%) IWSLT-2014(De-En) 44 4 34.31 75.0 0.55 IWSLT-2014(De-En) 22 8 32.34 87.5 6.26 IWSLT-2014(En-De) 44 4 28.07 75.0 1.50 IWSLT-2014(En-De) 22 8 26.80 87.5 5.96
下载: 导出CSV
表 5 剪枝后的Transformer模型量化实验结果
数据集 参数量(MB) BLEU 压缩率(%) 性能损失(%) IWSLT-2014(De-En) 11.0 34.16 93.75 0.98 IWSLT-2014(De-En) 5.5 32.14 96.87 6.84 IWSLT-2014(En-De) 11.0 27.95 93.75 1.93 IWSLT-2014(En-De) 5.5 26.58 96.87 6.74
下载: 导出CSV
表 6 算法结果对比(%)
现有研究工作 模型 模型压缩方法 数据集(任务) 压缩率 性能损失 文献[13] RoBERTa 块循环矩阵 IMDB(情感分类) 93.75 4.30 文献[24] Transformer 硬件感知搜索 IWSLT-2014(德英翻译) 28.20 0 文献[23] Transformer 分层剪枝 SST-2(情感分类) 90.00 2.37 文献[14] Transformer 内存感知结构化剪枝 Multi30K(德英翻译) 95.00 0.77 文献[25] BERT 全量化压缩 SST-2(情感分类) 87.50 0.88 文献[15] Transformer 不规则剪枝 WMT-2015(德英翻译) 77.25 1.92 本文 Transformer 偏移对角结构化剪枝、硬件友好INT8量化 IWSLT-2014(德英翻译) 93.75 0.98
下载: 导出CSV
表 7 资源利用报告
LUT FF BRAM DSP 可用数量 218 600 437 200 545 900 使用数 152 425 187 493 262 576 利用率(%) 69.73 42.88 48.07 64.00
下载: 导出CSV
-
[1] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [2] SUN Yu, WANG Shuohuan, LI Yukun, et al. Ernie 2.0: A continual pre-training framework for language understanding[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 8968–8975. [3] LIU Yinhan, OTT M, GOYAL N, et al. Roberta: A robustly optimized BERT pretraining approach[EB/OL]. https://doi.org/10.48550/arXiv.1907.11692, 2019. [4] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, USA, 2018: 4171–4186. [5] YANG Zhilin, DAI Zihang, YANG Yiming, et al. XLNet: Generalized autoregressive pretraining for language understanding[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 517. [6] ROSSET C. Turing-NLG: A 17-billion-parameter language model by microsoft[EB/OL]. https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/, 2020. [7] ZHANG Xiang, ZHAO Junbo, and LECUN Y. Character-level convolutional networks for text classification[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 649–657. [8] LAI Siwei, XU Liheng, LIU Kang, et al. Recurrent convolutional neural networks for text classification[C]. Twenty-ninth AAAI Conference on Artificial Intelligence, Austin, USA, 2015: 2267–2273. [9] VOITA E, TALBOT D, MOISEEV F, et al. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 5797–5808. [10] LIN Zi, LIU J, YANG Zi, et al. Pruning redundant mappings in transformer models via spectral-normalized identity prior[C]. Findings of the Association for Computational Linguistics: EMNLP 2020, 2020: 719–730. [11] PENG Hongwu, HUANG Shaoyi, GENG Tong, et al. Accelerating transformer-based deep learning models on FPGAs using column balanced block pruning[C]. 2021 22nd International Symposium on Quality Electronic Design (ISQED), Santa Clara, USA, 2021: 142–148. [12] QI Panjie, SONG Yuhong, PENG Hongwu, et al. Accommodating transformer onto FPGA: Coupling the balanced model compression and FPGA-implementation optimization[C]. 2021 on Great Lakes Symposium on VLSI, 2021: 163–168. [13] LI Bingbing, PANDEY S, FANG Haowen, et al. FTRANS: Energy-efficient acceleration of transformers using FPGA[C]. ACM/IEEE International Symposium on Low Power Electronics and Design, Boston, USA, 2020: 175–180. [14] ZHANG Xinyi, WU Yawen, ZHOU Peipei, et al. Algorithm-hardware co-design of attention mechanism on FPGA devices[J]. ACM Transactions on Embedded Computing Systems, 2021, 20(5s): 71. doi: 10.1145/3477002. [15] PARK J, YOON H, AHN D, et al. OPTIMUS: OPTImized matrix MUltiplication structure for transformer neural network accelerator[C]. Machine Learning and Systems, Austin, USA, 2020: 363–378. [16] DENG Chunhua, LIAO Siyu, and YUAN Bo. PermCNN: Energy-efficient convolutional neural network hardware architecture with permuted diagonal structure[J]. IEEE Transactions on Computers, 2021, 70(2): 163–173. doi: 10.1109/TC.2020.2981068. [17] WU Shuang, LI Guoqi, DENG Lei, et al. L1-norm batch normalization for efficient training of deep neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(7): 2043–2051. doi: 10.1109/TNNLS.2018.2876179. [18] BARRETT R, BERRY M, CHAN T F, et al. Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods[M]. Philadelphia: Society for Industrial and Applied Mathematics, 1994: 5–37. [19] LIU Weifeng and VINTER B. CSR5: An efficient storage format for cross-platform sparse matrix-vector multiplication[C]. The 29th ACM on International Conference on Supercomputing, Newport Beach, USA, 2015: 339–350. [20] PINAR A and HEATH M T. Improving performance of sparse matrix-vector multiplication[C]. SC'99: Proceedings of 1999 ACM/IEEE Conference on Supercomputing, Portland, USA, 1999: 30. [21] ZACHARIADIS O, SATPUTE N, GÓMEZ-LUNA J, et al. Accelerating sparse matrix–matrix multiplication with GPU tensor cores[J]. Computers & Electrical Engineering, 2020, 88: 106848. doi: 10.1016/j.compeleceng.2020.106848. [22] KANNAN R. Efficient sparse matrix multiple-vector multiplication using a bitmapped format[C]. 20th Annual International Conference on High Performance Computing, Bengaluru, India, 2013: 286–294. [23] QI Panjie, SHA E H M, ZHUGE Q, et al. Accelerating framework of transformer by hardware design and model compression co-optimization[C]. 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Munich, Germany, 2021: 1–9. [24] WANG Hanrui, WU Zhanghao, LIU Zhijian, et al. HAT: Hardware-aware transformers for efficient natural language processing[C]. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020: 7675–7688. [25] LIU Zejian, LI Gang, and CHENG Jian. Hardware acceleration of fully quantized BERT for efficient natural language processing[C]. 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 2021: 513–516. [26] LU Siyuan, WANG Meiqi, LIANG Shuang, et al. Hardware accelerator for multi-head attention and position-wise feed-forward in the transformer[C]. 2020 IEEE 33rd International System-on-Chip Conference (SOCC), Las Vegas, USA, 2020: 84–89. -

 下载:
下载:





图(11) / 表(10)
计量
- 文章访问数: 1815
- HTML全文浏览量: 1070
- PDF下载量: 145
- 被引次数: 0
