

A Selective Defense Strategy for Federated Learning Against Attacks
-
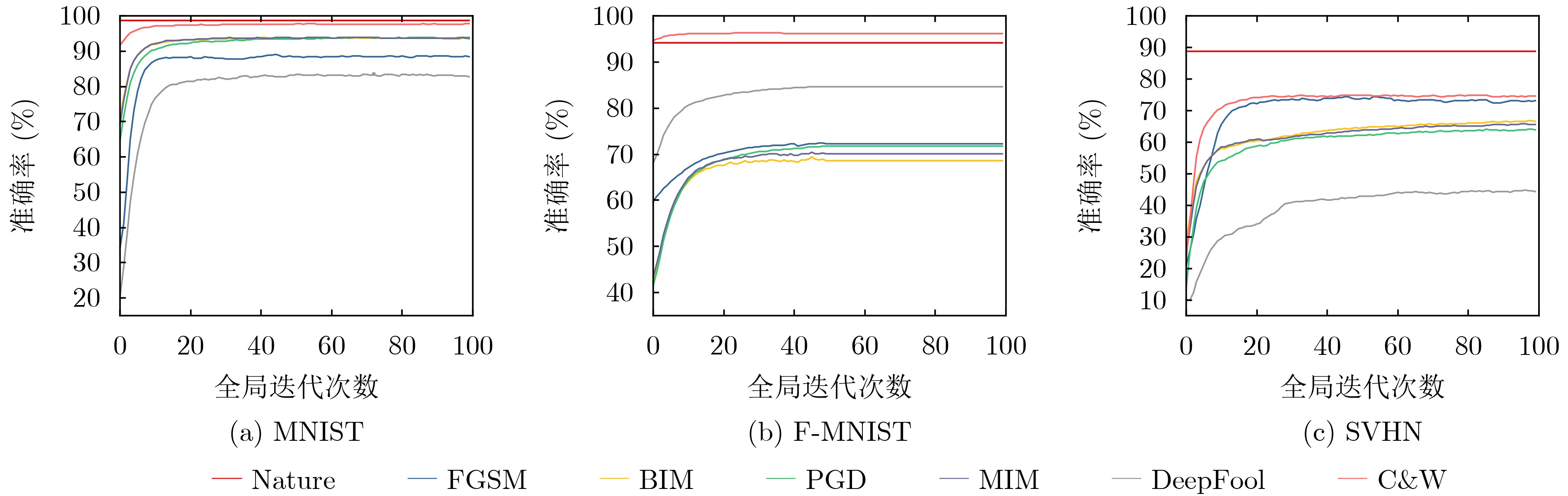
摘要: 联邦学习(FL)基于终端本地的学习以及终端与服务器之间持续地模型参数交互完成模型训练,有效地解决了集中式机器学习模型存在的数据泄露和隐私风险。但由于参与联邦学习的多个恶意终端能够在进行本地学习的过程中通过输入微小扰动即可实现对抗性攻击,并进而导致全局模型输出不正确的结果。该文提出一种有效的联邦防御策略-SelectiveFL,该策略首先建立起一个选择性联邦防御框架,然后通过在终端进行对抗性训练提取攻击特性的基础上,在服务器端对上传的本地模型更新的同时根据攻击特性进行选择性聚合,最终得到多个适应性的防御模型。该文在多个具有代表性的基准数据集上评估了所提出的防御方法。实验结果表明,与已有研究工作相比能够提升模型准确率提高了2%~11%。Abstract: Federated Learning (FL) performs model training based on local training on clients and continuous model parameters interaction between terminals and server, which effectively solving data leakage and privacy risks in centralized machine learning models. However, since multiple malicious terminals participating in FL can achieve adversarial attacks by inputting small perturbations in the process of local learning, and then lead to incorrect results output by the global model. An effective federated defense strategy – SelectiveFL is proposed in this paper. This strategy first establishes a selective federated defense framework, and then updates the uploaded local model on the server on the basis of extracting attack characteristics through adversarial training at the terminals. At the same time, selective aggregation is carried out according to the attack characteristics, and finally multiple adaptive defense models can be obtained. Finally, the proposed defense method is evaluated on several representative benchmark datasets. The experimental results show that compared with the existing research work, the accuracy of the model can be improved by 2% to 11%.
-
Key words:
- Federated Learning (FL) /
- Adversarial attack /
- Defense strategy /
- Adversarial training
-
表 1 主要符号汇总
符号 含义 ${\boldsymbol{\omega}} _{\rm{g}}^t$ 迭代轮次t的全局防御模型 ${\boldsymbol{\omega}} _k^t$ 迭代轮次t的终端k的本地防御模型 $\left| { {{\boldsymbol{D}}_k} } \right|$ 终端k数据集的大小 N 终端数量 $L({\boldsymbol{\omega}} _g^t)$ 迭代轮次t的全局损失 $L({\boldsymbol{\omega}} _k^t)$ 迭代轮次t的终端k的本地损失 $ \eta $ 学习率 ${\boldsymbol{x}}$ 自然样本示例 ${\boldsymbol{y}}$ 分类标签 $ {x_{{\text{adv}}}} $ 对抗样本示例 ${\boldsymbol{\omega} }$ 全局防御模型 ${{\boldsymbol{\omega}} ^k}$ 终端k的本地防御模型 ${L_{{\rm{att}}} }({\boldsymbol{x} },{ {\boldsymbol{x} }_{{\rm{adv}}} },{\boldsymbol{y} }|{\boldsymbol{\omega} } )$ 模型在att攻击下的损失函数 ${\left| { {{\boldsymbol{D}}_k} } \right|_{{\rm{attack}} = {\rm{att}}} }$ 遭受att攻击的终端k所拥有的数据量 ${\boldsymbol{\omega}} _{\rm{g}}^{{\rm{att}},t}$ 迭代轮次t中攻击att对应的全局防御模型 ${\boldsymbol{\omega}} _k^{{\rm{att}},t}$ 迭代轮次t中受到att攻击的终端k对应的本地防御模型 $ \delta $ 对抗攻击扰动  下载: 导出CSV
下载: 导出CSV
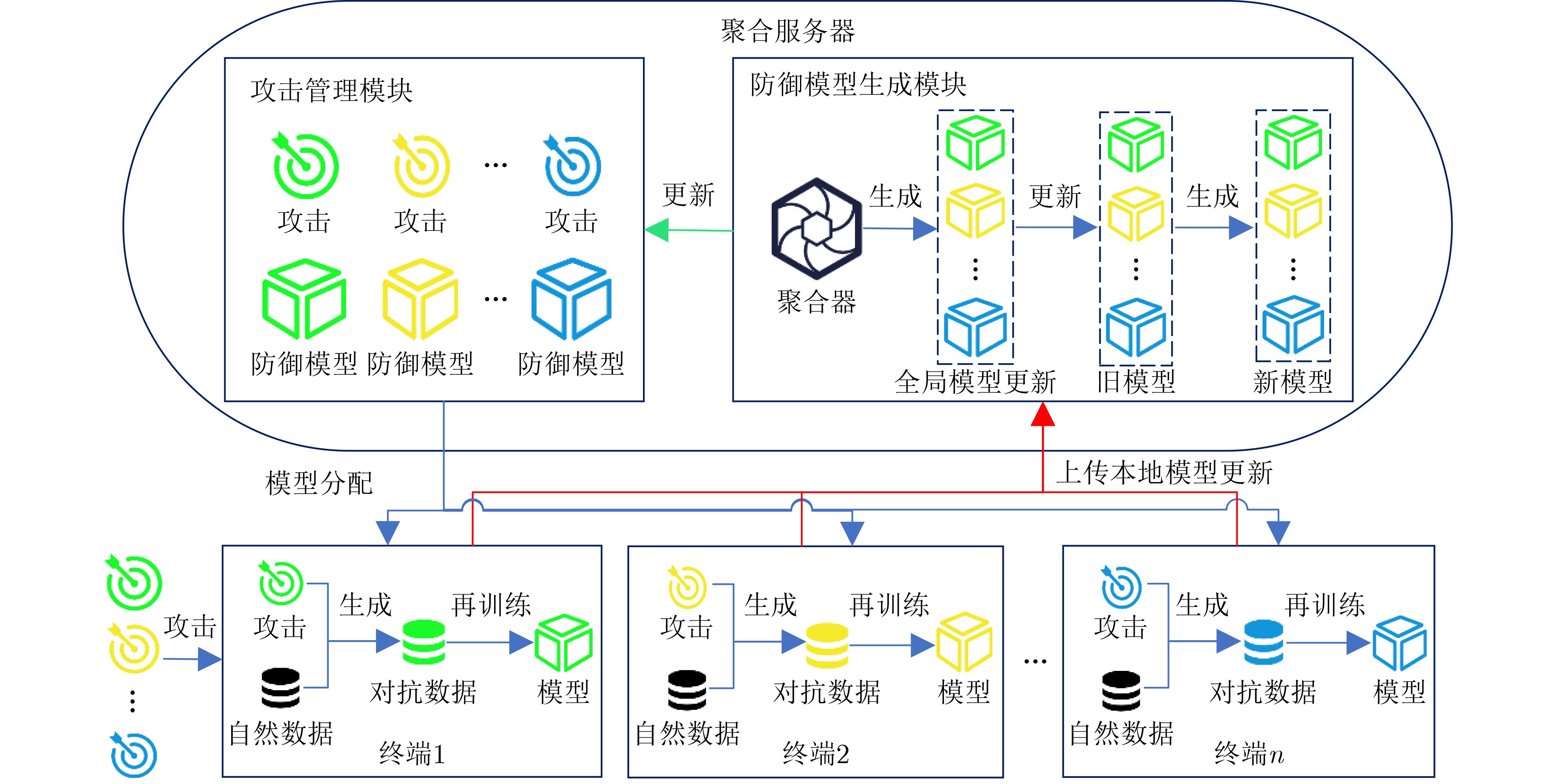
算法1 聚合服务器部署的算法伪码 输入:数据集${{\boldsymbol{D}}_i}$,终端数量N,全局迭代数量T (1) 初始化各攻击的全局防御模型${\boldsymbol{\omega}} _{\rm{g}}^{{\rm{att}},0}$; (2) for t=0,1,···,T–1 do (3) 随机抽取一组终端集合${ {{S} }_t}$; (4) for $ i \in {{\boldsymbol{S}}_t} $ in parallel do (5) 事件:接收终端的攻击方案att; (6) 发送att攻击的全局防御模型${\boldsymbol{\omega}} _{\rm{g}}^{{\rm{att}},t}$给终端; (7) 事件:接收终端的本地模型更新$\Delta {\boldsymbol{\omega}} _i^{{\rm{att}},t + 1}$; (8) end (9) ${\boldsymbol{\omega} } _{\rm{g} }^{ {\rm{att} },t + 1} = {\boldsymbol{\omega} } _{\rm{g} }^{ {\rm{att} },t}$
$+\displaystyle\sum\limits_{j \in {S_t} } {\frac{ { { {\left| { { {\boldsymbol{D} }_j} } \right|}_{ {\rm{attack = {\rm{att} } } }} } } }{ {\displaystyle\sum\limits_{i \in {S_t} } { { {\left| { { {\boldsymbol{D} }_i} } \right|}_{ {\rm{attack} } = {\rm{att} } } } } } }\Delta {\boldsymbol{\omega} } _j^{ {\rm{att} },t + 1} }$(10) end
下载: 导出CSV
算法2 FL终端部署的算法伪码 输入:数据集${{\boldsymbol{D}}_i}$,终端模型F,本地mini-batch大小B,本地迭
代数量E,学习率$ \eta $,超参数$ \alpha $(1) 上传攻击方案att到聚合服务器; (2) 事件:接收att攻击的全局防御模型${\boldsymbol{\omega}} _{\rm{g}}^{{\rm{att}},t}$; (3) 转换为本地防御模型:${\boldsymbol{\omega}} _i^{{\rm{att}},t} \leftarrow {\boldsymbol{\omega}} _{\rm{g}}^{{\rm{att}},t}$; (4) ${{\boldsymbol{x}}_{i,{\rm{adv}}} } = {\rm{AdvGen}}({x_i},{\rm{att}},F,{\boldsymbol{\omega}} _i^{{\rm{att}},t})$ //对抗工具箱 (5) for e=0,1,···,E–1 do (6) for b=0,1,…,$\left\lceil {\dfrac{ {\left| { {{\boldsymbol{D}}_i} } \right|} }{B} } \right\rceil - 1$ do (7) ${\boldsymbol{y} }_i^* = {\boldsymbol{F} }({ {\boldsymbol{x} }_i},{\boldsymbol{\omega} } _i^{ {{{\rm{att}},t} } })$ (8) ${\boldsymbol{y}}_{i,{\rm{adv}}}^* = {\boldsymbol{F}}({{\boldsymbol{x}}_{i,{\rm{adv}}} },{\boldsymbol{\omega}} _i^{{\rm{att}},t})$ (9) ${{\rm{nat}}_ - }{\rm{loss}} = {\rm{CrossEntropy}}({\boldsymbol{y}}_i^*,{{\boldsymbol{y}}_i})$ (10) ${{\rm{adv}}_ - }{\rm{loss}} = {\rm{CrossEntropy}}({\boldsymbol{y}}_{i,{\rm{adv}}}^*,{{\boldsymbol{y}}_i})$ (11) $L = \alpha \cdot {{\rm{nat}}_ - }{\rm{loss}} + (1 - \alpha ) \cdot {{\rm{adv}}_ - }{\rm{loss}}$ (12) ${\boldsymbol{\omega} } _i^{ {\rm{att} },t + 1} = {\boldsymbol{\omega} } _i^{ {\rm{att} },t} - \eta \cdot \nabla L({\boldsymbol{\omega} } _i^{ {{{\rm{att}},t} } },{ {\boldsymbol{x} }_i},{ {\boldsymbol{x} }_{i,{\rm{adv} } } },{ {\boldsymbol{y} }_i})$ (13) end (14) end (15) 计算本地模型更新; (16) $\Delta {\boldsymbol{\omega}} _i^{{\rm{att}},t + 1} = {\boldsymbol{\omega}} _i^{{\rm{att}},t + 1} - {\boldsymbol{\omega}} _i^{{\rm{att}},t}$ (17) 上传本地模型更新到聚合服务器;
下载: 导出CSV
表 2 不同攻击类型数量的鲁棒准确性(%)
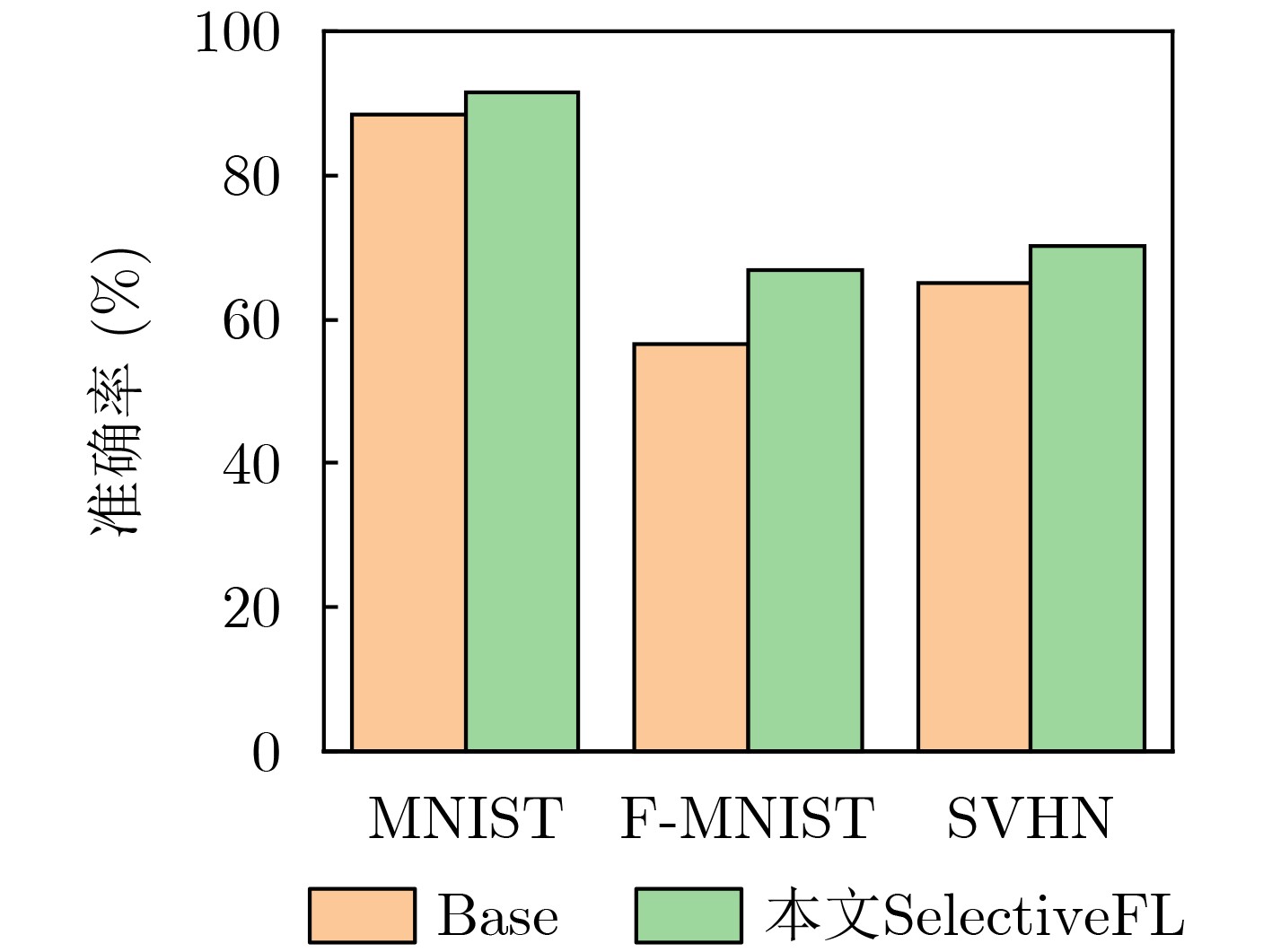
数据集 算法 攻击类型数量 2 3 4 5 6 MNIST Base 86.50 90.77 88.47 88.24 88.32 本文SelectiveFL 90.89 90.92 91.39 89.95 89.77 F-MNIST Base 60.71 53.64 56.60 53.33 54.26 本文SelectiveFL 67.81 67.87 66.62 60.42 61.27 SVHN Base 63.81 63.94 65.28 69.35 73.39 本文SelectiveFL 70.40 70.93 70.33 73.31 77.15
下载: 导出CSV
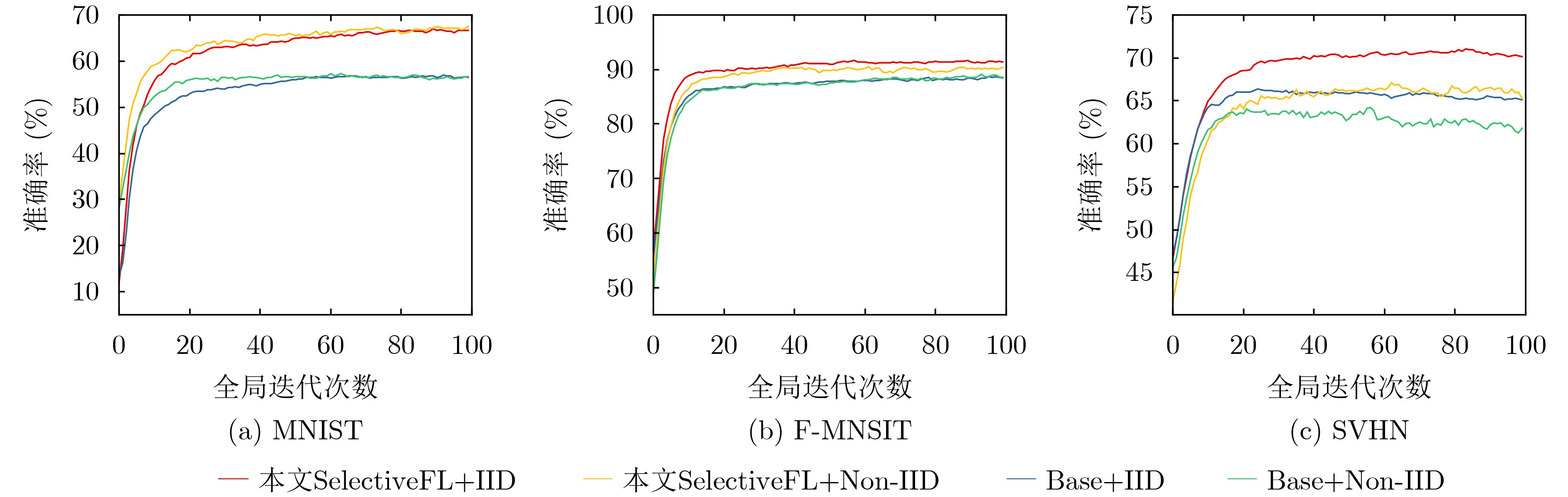
表 3 不同终端数目的鲁棒准确性(%)
数据集 算法 终端数目 10 20 30 40 50 MNIST Base 88.47 89.23 89.37 89.53 89.53 本文SelectiveFL 91.39 91.95 92.12 92.31 92.30 F-MNIST Base 56.60 55.56 57.00 57.26 56.95 本文SelectiveFL 66.62 66.11 67.64 67.81 67.87 SVHN Base 65.28 65.68 65.11 65.46 65.66 本文SelectiveFL 70.33 70.73 70.80 70.89 70.88
下载: 导出CSV
-
[1] WU Yulei, DAI Hongning, and WANG Hao. Convergence of blockchain and edge computing for secure and scalable IIoT critical infrastructures in industry 4.0[J]. IEEE Internet of Things Journal, 2021, 8(4): 2300–2317. doi: 10.1109/JIOT.2020.3025916. [2] LIU Yi, YU J J Q, KANG Jiawen, et al. Privacy-preserving traffic flow prediction: A federated learning approach[J]. IEEE Internet of Things Journal, 2020, 7(8): 7751–7763. doi: 10.1109/JIOT.2020.2991401. [3] KHAN L U, YAQOOB I, TRAN N H, et al. Edge-computing-enabled smart cities: A comprehensive survey[J]. IEEE Internet of Things Journal, 2020, 7(10): 10200–10232. doi: 10.1109/JIOT.2020.2987070. [4] WAN C P and CHEN Qifeng. Robust federated learning with attack-adaptive aggregation[EB/OL]. https://doi.org/10.48550/arXiv.2102.05257, 2021. [5] HONG Junyuan, WANG Haotao, WANG Zhangyang, et al. Federated robustness propagation: Sharing adversarial robustness in federated learning[C/OL]. The Tenth International Conference on Learning Representations, 2022. [6] REN Huali, HUANG Teng, and YAN Hongyang. Adversarial examples: Attacks and defenses in the physical world[J]. International Journal of Machine Learning and Cybernetics, 2021, 12(11): 3325–3336. doi: 10.1007/s13042–020-01242-z. [7] GOODFELLOW I J, SHLENS J, and SZEGEDY C. Explaining and harnessing adversarial examples[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015: 1–11. [8] KURAKIN A, GOODFELLOW I J, and BENGIO S. Adversarial examples in the physical world[C]. The 5th International Conference on Learning Representations, Toulon, France, 2017: 1–14. [9] MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks[C]. The 6th International Conference on Learning Representations, Vancouver, Canada, 2018. [10] DONG Yinpeng, LIAO Fangzhou, PANG Tianyu, et al. Boosting adversarial attacks with momentum[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 9185–9193. [11] MOOSAVI-DEZFOOLI S M, FAWZI A, and FROSSARD P. DeepFool: A simple and accurate method to fool deep neural networks[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 2574–2582. [12] CARLINI N and WAGNER D. Towards evaluating the robustness of neural networks[C]. 2017 IEEE Symposium on Security and Privacy (SP), San Jose, USA, 2017: 39–57. [13] CHEN Peng, DU Xin, LU Zhihui, et al. Universal adversarial backdoor attacks to fool vertical federated learning in cloud-edge collaboration[EB/OL]. https://doi.org/10.48550/arXiv.2304.11432, 2023. [14] CHEN Jinyin, HUANG Guohan, ZHENG Haibin, et al. Graph-fraudster: Adversarial attacks on graph neural network-based vertical federated learning[J]. IEEE Transactions on Computational Social Systems, 2023, 10(2): 492–506. doi: 10.1109/TCSS.2022.3161016. [15] PAPERNOT N, MCDANIEL P, WU Xi, et al. Distillation as a defense to adversarial perturbations against deep neural networks[C]. 2016 IEEE Symposium on Security and Privacy (SP), San Jose, USA, 2016: 582–597. [16] GUO Feng, ZHAO Qingjie, LI Xuan, et al. Detecting adversarial examples via prediction difference for deep neural networks[J]. Information Sciences, 2019, 501: 182–192. doi: 10.1016/j.ins.2019.05.084. [17] CHEN Chen, LIU Yuchen, MA Xingjun, et al. CalFAT: Calibrated federated adversarial training with label skewness[EB/OL]. https://doi.org/10.48550/arXiv.2205.14926, 2022. [18] IBITOYE O, SHAFIQ M O, and MATRAWY A. Differentially private self-normalizing neural networks for adversarial robustness in federated learning[J]. Computers & Security, 2022, 116: 102631. doi: 10.1016/j.cose.2022.102631. [19] SONG Yunfei, LIU Tian, WEI Tongquan, et al. FDA3: Federated defense against adversarial attacks for cloud-based IIoT applications[J]. IEEE Transactions on Industrial Informatics, 2021, 17(11): 7830–7838. doi: 10.1109/TII.2020.3005969. [20] FENG Jun, YANG L T, ZHU Qing, et al. Privacy-preserving tensor decomposition over encrypted data in a federated cloud environment[J]. IEEE Transactions on Dependable and Secure Computing, 2020, 17(4): 857–868. doi: 10.1109/TDSC.2018.2881452. [21] FENG Jun, YANG L T, REN Bocheng, et al. Tensor recurrent neural network with differential privacy[J]. IEEE Transactions on Computers, 2023: 1–11. -


 下载:
下载:


图(5) / 表(5)
计量
- 文章访问数: 1341
- HTML全文浏览量: 932
- PDF下载量: 108
- 被引次数: 0
