

Combinatorial Adversarial Defense for Environmental Sound Classification Based on GAN
-
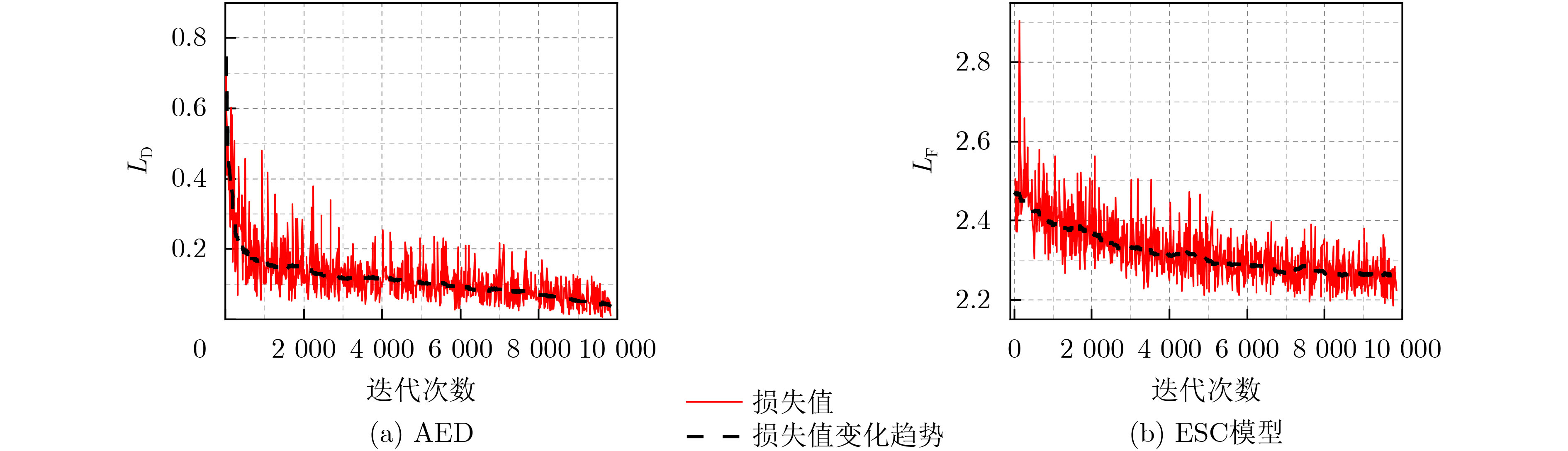
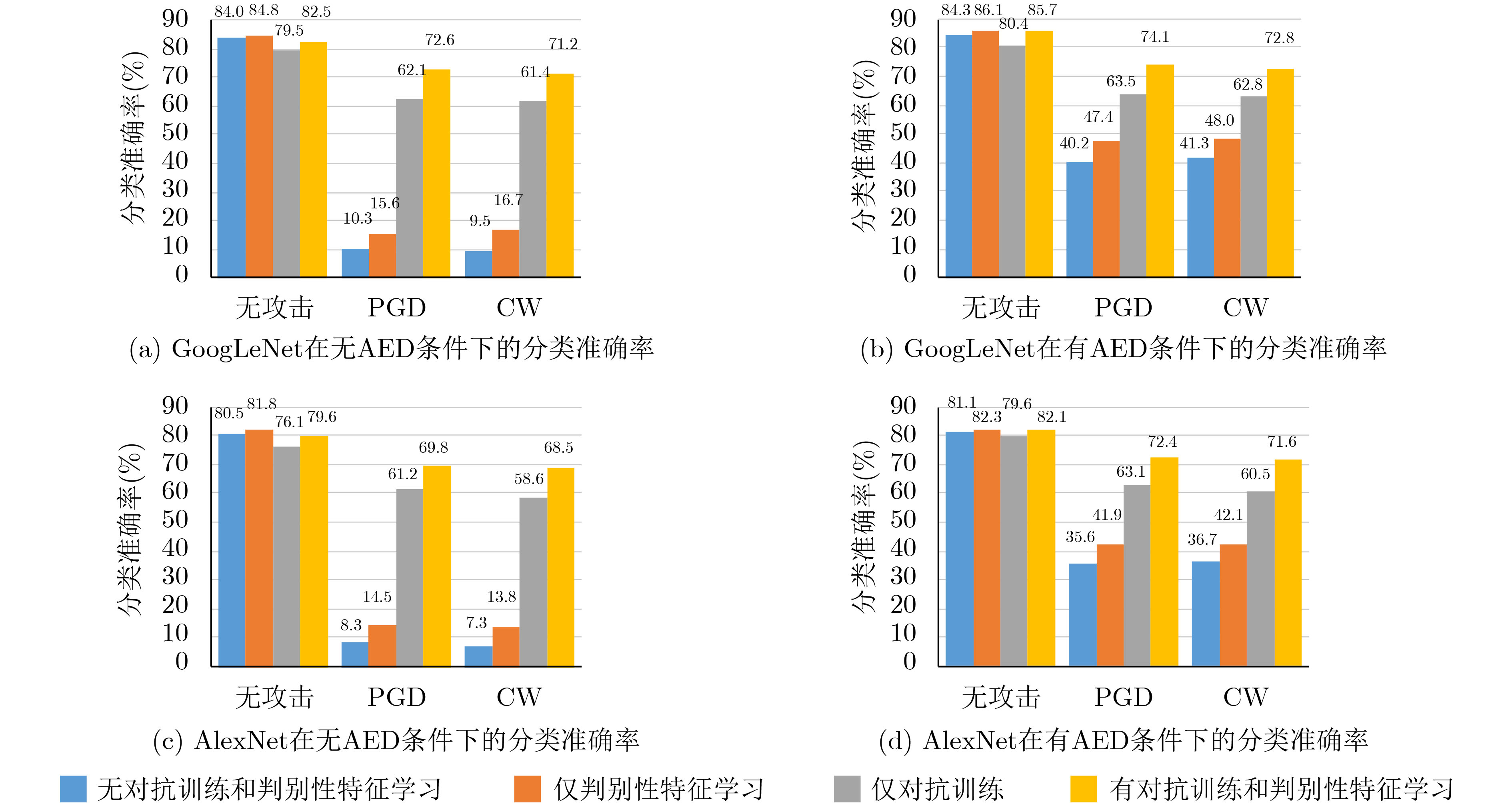
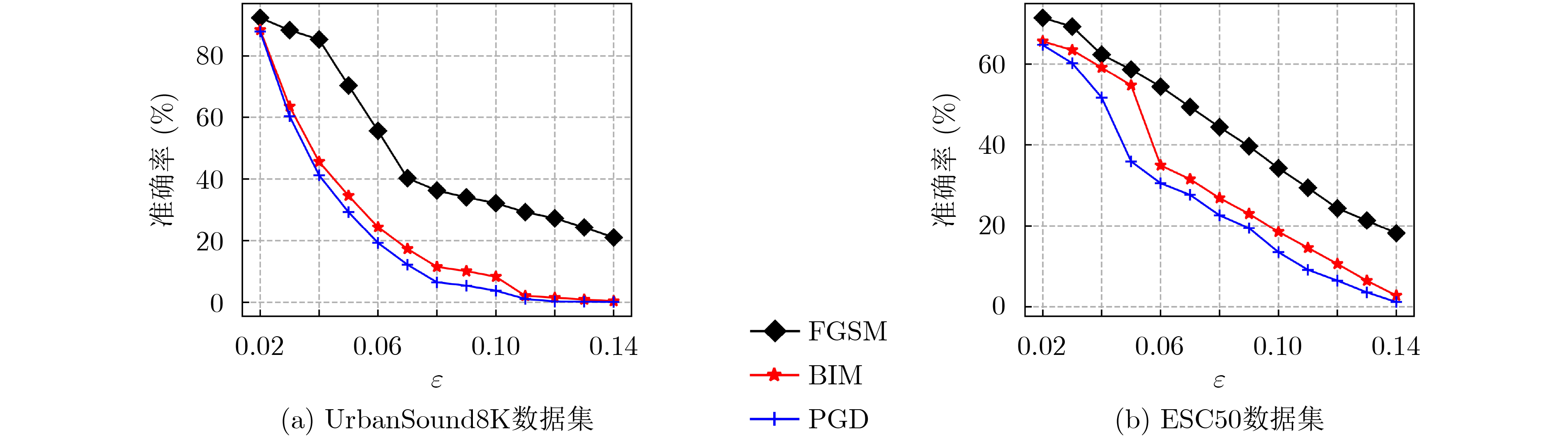
摘要: 虽然深度神经网络可以有效改善环境声音分类(ESC)性能,但对对抗样本攻击依然具有脆弱性。已有对抗防御方法通常只对特定攻击有效,无法适应白盒、黑盒等不同攻击场景。为提高ESC模型在各种场景下对各种攻击的防御能力,该文提出一种结合对抗检测、对抗训练和判别性特征学习的ESC组合对抗防御方法。该方法使用对抗样本检测器(AED)对输入ESC模型的样本进行检测,基于生成对抗网络(GAN)同时对AED和ESC模型进行对抗训练,其中,AED作为GAN的判别器使用。同时,该方法将判别性损失函数引入ESC模型的对抗训练中,以驱使模型学习到的样本特征类内更加紧凑、类间更加远离,进一步提升模型的对抗鲁棒性。在两个典型ESC数据集,以及白盒、自适应白盒、黑盒攻击设置下,针对多种模型开展了防御对比实验。实验结果表明,该方法基于GAN实现多种防御方法的组合,可以有效提升ESC模型防御对抗样本攻击的能力,对应的ESC准确率比其他方法对应的ESC准确率提升超过10%。同时,实验验证了所提方法的有效性不是由混淆梯度引起的。Abstract: Although deep neural networks can effectively improve Environmental Sound Classification (ESC) performance, they are still vulnerable to adversarial attacks. The existing adversarial defense methods are usually effective only for specific attacks and can not be adapted to different attack settings such as white-box and black-box. To improve the defense capability of ESC models in various attacking scenarios, an ESC adversarial defense method is proposed in this paper, which combines adversarial detection, adversarial training, and discriminative feature learning. This method uses an Adversarial Example Detector (AED) to detect samples input to the ESC model, and trains both the AED and ESC model simultaneously via Generative Adversarial Network (GAN), where the AED is used as the discriminator of GAN. Meanwhile, this method introduces discriminative loss functions into the adversarial training of the ESC model, so as to drive the model to learn deep features more compact within classes and more distant between classes, which helps to improve further the adversarial robustness of the model. Comparative experiments of multiple defense methods on two typical ESC datasets under white-box, adaptive white-box, and black-box attack settings are conducted. The experimental results show that by implementing a combination of multiple defense methods based on GAN, the proposed method can effectively improve the defense capability of ESC models against various attacks, and the corresponding ESC accuracy is at least 10% higher than that achieved by other defense methods. Meanwhile, it is verified that the effectiveness of the proposed method is not due to the obfuscated gradients.
-
表 1 典型ESC数据集简要信息
数据集 类别数 样本数 训练样本数 测试样本数 样本时长 声道数 ESC50 50 2 000 1 800 200 5 s 1 UrbanSound8K 10 8 732 7 858 874 ≤4 s 2  下载: 导出CSV
下载: 导出CSV
表 2 不同模型在典型ESC数据集上的分类准确率(%)
数据集 模型 GoogLeNet AlexNet ResNet18 EnvNet-v2 SoundNet8 VGGish ESC50 84.0 80.5 82.0 80.5 81.0 82.5 UrbanSound8K 96.6 94.5 96.3 93.3 96.5 97.8
下载: 导出CSV
表 3 在UrbanSound8K数据集上不同防御方法在白盒攻击场景下的性能比较(%)
分类模型 GoogLeNet AlexNet Nature MAD[11] FGSM[12] WNA[14] 本文 Nature MAD[11] FGSM[12] WNA[14] 本文 不使用攻击 96.6 89.2 82.3 87.2 98.1 94.5 84.3 71.1 83.1 95.5 FGSM攻击 32.4 77.8 40.2 38.5 92.7 27.3 73.5 34.6 45.2 92.3 PGD攻击 12.6 72.1 27.4 30.1 88.5 11.4 68.6 24.5 34.3 87.9 BIM攻击 13.8 73.2 28.5 31.3 89.7 13.2 69.3 25.1 35.1 88.4 CW攻击 13.3 71.4 26.7 59.2 88.1 10.3 67.9 23.8 60.4 87.6 最小值 12.6 71.4 26.7 30.1 88.1 10.3 67.9 23.8 34.3 87.6
下载: 导出CSV
表 4 在UrbanSound8K数据集上所提方法在自适应白盒攻击场景下的性能表现(%)
GoogLeNet AlexNet FGSM攻击 92.5 92.0 PGD攻击 88.3 87.6 BIM攻击 89.4 88.2 CW攻击 87.8 87.3 最小值 87.8 87.3
下载: 导出CSV
表 5 在ESC50数据集上不同防御方法在黑盒攻击场景下的性能比较(%)
SoundNet8 VGGish EnvNet-v2 Nature PGD CW 本文 Nature PGD CW 本文 Nature PGD CW 本文 FGSM攻击 40.5 69.3 58.3 76.2 42.8 68.1 48.5 77.3 37.2 69.4 66.7 75.8 PGD攻击 27.4 59.2 40.3 72.3 24.2 58.5 38.4 70.5 25.1 57.4 55.8 69.5 BIM攻击 28.5 58.6 39.8 73.2 25.3 56.2 38.7 70.7 26.3 60.5 56.3 70.1 CW攻击 35.6 59.8 42.5 74.4 32.5 57.5 41.8 71.2 39.7 58.6 54.9 72.3 最小值 27.4 58.6 39.8 72.3 24.2 56.2 38.4 70.5 25.1 57.4 54.9 69.5
下载: 导出CSV
表 6 检测阈值对所提方法防御性能的影响
检测
阈值AED的对抗样本
检测正确率(%)AED的真实样本
检测正确率(%)ESC模型的分类准确率(%) 真实样本 对抗样本 0.1 35.2 94.0 90.1 73.4 0.3 53.3 91.3 93.4 76.2 0.5 76.6 88.2 96.4 80.3 0.7 87.6 85.6 95.7 79.4 0.9 92.2 81.7 94.6 78.2
下载: 导出CSV
表 7 在ESC50数据集上所提方法在白盒攻击场景下的性能表现(%)
SoundNet8 VGGish EnvNet-v2 FGSM攻击 70.7 71.4 71.3 PGD攻击 65.2 64.7 65.4 BIM攻击 67.0 65.6 66.2 CW攻击 66.1 65.3 65.8 最小值 65.2 64.7 65.4
下载: 导出CSV
-
[1] PICZAK K J. ESC: Dataset for environmental sound classification[C]. The 23rd ACM Multimedia Conference, Brisbane, Australia, 2015: 1015–1018. [2] SALAMON J, JACOBY C, and BELLO J P. A dataset and taxonomy for urban sound research[C]. The 22nd ACM International Conference on Multimedia, Orlando, USA, 2014: 1041–1044. [3] GEMMEKE J F, ELLIS D P W, FREEDMAN D, et al. Audio set: An ontology and human-labeled dataset for audio events[C]. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, USA, 2017: 776–780. [4] GONG Yuan, CHUNG Y A, and GLASS J. AST: Audio spectrogram transformer[C]. The 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 2021: 571–575. [5] AYTAR Y, VONDRICK C, and TORRALBA A. SoundNet: Learning sound representations from unlabeled video[C]. The 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 892–900. [6] HERSHEY S, CHAUDHURI S, ELLIS D P W, et al. CNN architectures for large-scale audio classification[C]. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, USA, 2017: 131–135. [7] TOKOZUME Y, USHIKU Y, and HARADA T. Learning from between-class examples for deep sound recognition[C]. 6th International Conference on Learning Representations, Vancouver, Canada, 2018: 1–13. [8] ZEGHIDOUR N, TEBOUL O, DE CHAUMONT QUITRY F, et al. LEAF: A learnable frontend for audio classification[C]. The 9th International Conference on Learning Representations, Virtual Event, Austria, 2021: 1–16. [9] XIE Yi, LI Zhuohang, SHI Cong, et al. Enabling fast and universal audio adversarial attack using generative model[C/OL]. The 35th Conference on Artificial Intelligence, Virtual Event, 2021: 14129–14137. [10] ESMAEILPOUR M, CARDINAL P, and KOERICH A L. A robust approach for securing audio classification against adversarial attacks[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 2147–2159. doi: 10.1109/TIFS.2019.2956591 [11] OLIVIER R, RAJ B, and SHAH M. High-frequency adversarial defense for speech and audio[C]. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 2995–2999. [12] SALLO R A, ESMAEILPOUR M, and CARDINAL P. Adversarially training for audio classifiers[C]. The 25th International Conference on Pattern Recognition, Milan, Italy, 2020: 9569–9576. [13] ESMAEILPOUR M, CARDINAL P, and KOERICH A L. Detection of adversarial attacks and characterization of adversarial subspace[C]. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020: 3097–3101. [14] SUBRAMANIAN V, BENETOS E, and SANDLER M B. Robustness of adversarial attacks in sound event classification[C]. The Workshop on Detection and Classification of Acoustic Scenes and Events 2019, New York City, USA, 2019: 239–243. [15] POURSAEED O, JIANG Tianxing, YANG H, et al. Robustness and generalization via generative adversarial training[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 15711–15720. [16] LEE H, HAN S, and LEE J. Generative adversarial trainer: Defense to adversarial perturbations with GAN[EB/OL]. http://arxiv.org/abs/1705.03387v2, 2017. [17] JANG Y, ZHAO Tianchen, HONG S, et al. Adversarial defense via learning to generate diverse attacks[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 2740–2749. [18] WANG Huaxia and YU C N. A direct approach to robust deep learning using adversarial networks[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019: 1–15. [19] 孔锐, 蔡佳纯, 黄钢. 基于生成对抗网络的对抗攻击防御模型[J/OL]. 自动化学报, 2020. https://doi.org/10.16383/j.aas.c200033, 2020.KONG Rui, CAI Jiachun, and HUANG Gang. Defense to adversarial attack with generative adversarial network[J/OL]. Acta Automatica Sinica, 2020. https://doi.org/10.16383/j.aas.c200033, 2020. [20] SAMANGOUEI P, KABKAB M, and CHELLAPPA R. Defense-GAN: Protecting classifiers against adversarial attacks using generative models[C]. The 6th International Conference on Learning Representations, Vancouver, Canada, 2018: 1–17. [21] WU Haibin, HSU P C, GAO Ji, et al. Adversarial sample detection for speaker verification by neural vocoders[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 2022: 236–240. [22] AGARWAL C, NGUYEN A, and SCHONFELD D. Improving robustness to adversarial examples by encouraging discriminative features[C]. 2019 IEEE International Conference on Image Processing, Taipei, China, 2019: 3801–3805. [23] MUSTAFA A, KHAN S H, HAYAT M, et al. Deeply supervised discriminative learning for adversarial defense[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(9): 3154–3166. doi: 10.1109/TPAMI.2020.2978474 [24] ATHALYE A, CARLINI N, and WAGNER D A. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 274–283. [25] GOODFELLOW I J, SHLENS J, and SZEGEDY C. Explaining and harnessing adversarial examples[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015: 1–11. [26] CARLINI N and WAGNER D. Towards evaluating the robustness of neural networks[C]. 2017 IEEE Symposium on Security and Privacy, San Jose, USA, 2017: 39–57. [27] KURAKIN A, GOODFELLOW I J, and BENGIO S. Adversarial examples in the physical world[C]. The 5th International Conference on Learning Representations, Toulon, France, 2017: 1–14. [28] LAN Jiahe, ZHANG Rui, YAN Zheng, et al. Adversarial attacks and defenses in speaker recognition systems: A survey[J]. Journal of Systems Architecture, 2022, 127: 102526. doi: 10.1016/j.sysarc.2022.102526 [29] WEN Yandong, ZHANG Kaipeng, LI Zhifeng, et al. A discriminative feature learning approach for deep face recognition[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 499–515. [30] SCHROFF F, KALENICHENKO D, and PHILBIN J. FaceNet: a unified embedding for face recognition and clustering[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 815–823. [31] 张强, 杨吉斌, 张雄伟, 等. CS-Softmax: 一种基于余弦相似性的Softmax损失函数[J]. 计算机研究与发展, 2022, 59(4): 936–949. doi: 10.7544/issn1000-1239.20200879ZHANG Qiang, YANG Jibin, ZHANG Xiongwei, et al. CS-Softmax: A cosine similarity-based Softmax loss[J]. Journal of Computer Research and Development, 2022, 59(4): 936–949. doi: 10.7544/issn1000-1239.20200879 [32] SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs[C]. The 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016, 29: 2234–2242. [33] YANG Dingdong, HONG S, JANG Y, et al. Diversity-sensitive conditional generative adversarial networks[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019: 1–23. [34] SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. [35] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[C]. The 25th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2012: 1097–1105. [36] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [37] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791 [38] ENGSTROM L, ILYAS A, and ATHALYE A. Evaluating and understanding the robustness of adversarial logit pairing[EB/OL]. http://arxiv.org/abs/1807.10272, 2018. [39] MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks[C]. The 6th International Conference on Learning Representations, Vancouver, Canada, 2018: 1–28. [40] KIM H. Torchattacks: A PyTorch repository for adversarial attacks[EB/OL]. http://arxiv.org/abs/2010.01950v3, 2020. [41] TRAMÈR F, PAPERNOT N, GOODFELLOW I, et al. The space of transferable adversarial examples[EB/OL]. http://arxiv.org/abs/1704.03453, 2017. [42] TSIPRAS D, SANTURKAR S, ENGSTROM L, et al. Robustness may be at odds with accuracy[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019: 1–24. -


 下载:
下载:


图(4) / 表(7)
计量
- 文章访问数: 1012
- HTML全文浏览量: 882
- PDF下载量: 154
- 被引次数: 0
