

Attribute Based Privacy Protection Encryption Scheme Based on Inner Product Predicate
-
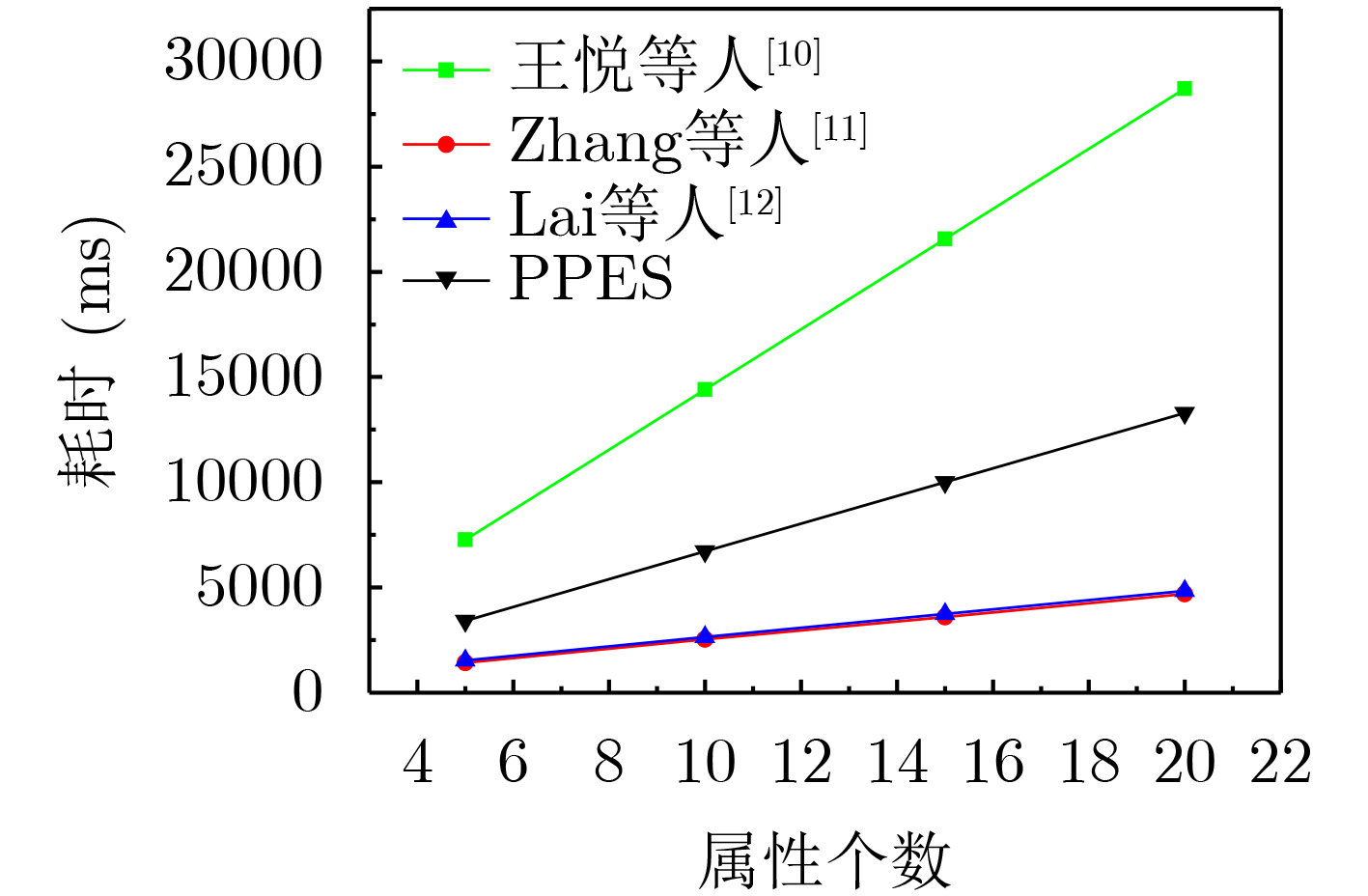
摘要: 隐私保护是信息安全中的热点话题,其中属性基加密(ABE)中的隐私问题可分为数据内容隐私、策略隐私及属性隐私。针对数据内容、策略和属性3方面隐私保护需求,该文提出基于内积谓词的属性基隐私保护加密方案(PPES)。所提方案利用加密算法的机密性保障数据内容隐私,并通过向量承诺协议构造策略属性及用户属性盲化方法,实现策略隐私及属性隐私。基于混合论证技术,该文证明了所提方案满足标准模型下适应性选择明文安全,且具备承诺不可伪造性。性能分析结果显示,与现有方法相比,所提方案具有更优的运行效率。Abstract: Privacy protection is a hot topic in information security, where the privacy issues in Attribute Based Encryption(ABE) can be divided into data content privacy, policy privacy and attribute privacy. Considering the three privacy protection needs of data content, policy and attributes, an attribute-based Privacy-Preserving Encryption Scheme based on inner product predicates (PPES) is proposed. The privacy of data content is ensured by using confidentiality of encryption algorithm, furthermore the blind method of policy attributes and user attributes is constructed through vector commitment protocol to achieve policy privacy and attribute privacy. Based on the hybrid argument technology, adaptive chosen plaintext security of the scheme is proved under standard model. Besides commitment unforgeability of the scheme is also illustrated. The performance analysis results show that the proposed scheme has better operation efficiency compared to existing methods.
-
[1] SAHAI A and WATERS B. Fuzzy identity-based encryption[C]. Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques on Advances in Cryptology, Aarhus, Denmark, 2005: 457–473. [2] ZHANG Yinghui, DENG R H, XU Shenmin, et al. Attribute-based encryption for cloud computing access control: A survey[J]. ACM Computing Surveys, 2021, 53(4): 83. doi: 10.1145/3398036 [3] LI Hang, YU Keping, LIU Bing, et al. An efficient ciphertext-policy weighted attribute-based encryption for the internet of health things[J]. IEEE Journal of Biomedical and Health Informatics, 2022, 26(5): 1949–1960. doi: 10.1109/JBHI.2021.3075995 [4] XU Runhua, JOSHI J, and KRISHNAMURTHY P. An integrated privacy preserving attribute-based access control framework supporting secure deduplication[J]. IEEE Transactions on Dependable and Secure Computing, 2021, 18(2): 706–721. doi: 10.1109/TDSC.2019.2946073 [5] WANG Jin, CHEN Jiahao, XIONG N, et al. S-BDS: An effective blockchain-based data storage scheme in zero-trust IoT[J]. ACM Transactions on Internet Technology, To be published. [6] ZHANG Yinghui, CHEN Xiaofeng, LI Jin, et al. Ensuring attribute privacy protection and fast decryption for outsourced data security in mobile cloud computing[J]. Information Sciences, 2017, 379: 42–61. doi: 10.1016/j.ins.2016.04.015 [7] KATZ J, SAHAI A, and WATERS B. Predicate encryption supporting disjunctions, polynomial equations, and inner products[C]. The 27th Annual International Conference on the Theory and Applications of Cryptographic Techniques on Advances in Cryptology, Istanbul, Turkey, 2008: 146–162. [8] 赵志远, 王建华, 朱智强, 等. 面向物联网数据安全共享的属性基加密方案[J]. 计算机研究与发展, 2019, 56(6): 1290–1301. doi: 10.7544/issn1000-1239.2019.20180288ZHAO Zhiyuan, WANG Jianhua, ZHU Zhiqiang, et al. Attribute-based encryption for data security sharing of internet of things[J]. Journal of Computer Research and Development, 2019, 56(6): 1290–1301. doi: 10.7544/issn1000-1239.2019.20180288 [9] 张嘉伟, 马建峰, 马卓, 等. 云计算中基于时间和隐私保护的可撤销可追踪的数据共享方案[J]. 通信学报, 2021, 42(10): 81–94. doi: 10.11959/j.issn.1000−436x.2021206ZHANG Jiawei, MA Jianfeng, MA Zhuo, et al. Time-based and privacy protection revocable and traceable data sharing scheme in cloud computing[J]. Journal on Communications, 2021, 42(10): 81–94. doi: 10.11959/j.issn.1000−436x.2021206 [10] 王悦, 樊凯. 隐藏访问策略的高效CP-ABE方案[J]. 计算机研究与发展, 2019, 56(10): 2151–2159. doi: 10.7544/issn1000-1239.2019.20190343WANG Yue and FAN Kai. Effective CP-ABE with hidden access policy[J]. Journal of Computer Research and Development, 2019, 56(10): 2151–2159. doi: 10.7544/issn1000-1239.2019.20190343 [11] ZHANG Yinghui, ZHENG Dong, and DENG R H. Security and privacy in smart health: Efficient policy-hiding attribute-based access control[J]. IEEE Internet of Things Journal, 2018, 5(3): 2130–2145. doi: 10.1109/JIOT.2018.2825289 [12] LAI Junzuo, DENG R H, and LI Yingjiu. Expressive CP-ABE with partially hidden access structures[C]. Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security, Seoul, Korea, 2012: 18–19. [13] HUR J. Attribute-based secure data sharing with hidden policies in smart grid[J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(11): 2171–2180. doi: 10.1109/TPDS.2012.61 [14] MICHALEVSKY Y and JOYE M. Decentralized policy-hiding ABE with receiver privacy[C]. The 23rd European Symposium on Research in Computer Security, Barcelona, Spain, 2018: 548–567. [15] QIAN Huiling, LI Jiguo, and ZHANG Yichen. Privacy-preserving decentralized ciphertext-policy attribute-based encryption with fully hidden access structure[C]. The 15th International Conference on Information and Communications Security, Beijing, China, 2013: 363–372. [16] HAN Jinguang, SUSILO W, MU Yi, et al. Privacy-preserving decentralized key-policy attribute-based encryption[J]. IEEE Transactions on Parallel and Distributed Systems, 2012, 23(11): 2150–2162. doi: 10.1109/TPDS.2012.50 [17] GE Aijun, ZHANG Jiang, ZHANG Rui, et al. Security analysis of a privacy-preserving decentralized key-policy attribute-based encryption scheme[J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(11): 2319–2321. doi: 10.1109/TPDS.2012.328 [18] HAN Jinguang, SUSILO W, MU Yi, et al. Improving privacy and security in decentralized ciphertext-policy attribute-based encryption[J]. IEEE Transactions on Information Forensics and Security, 2015, 10(3): 665–678. doi: 10.1109/TIFS.2014.2382297 [19] WANG Minqian, ZHANG Zhenfeng, and CHEN Cheng. Security analysis of a privacy-preserving decentralized ciphertext-policy attribute-based encryption scheme[J]. Concurrency and Computation:Practice and Experience, 2016, 28(4): 1237–1245. doi: 10.1002/cpe.3623 [20] CATALANO D and FIORE D. Vector commitments and their applications[C]. The 16th International Conference on Practice and Theory in Public-Key Cryptography, Nara, Japan, 2013: 55–72. -


 下载:
下载:




图(4) / 表(3)
计量
- 文章访问数: 1542
- HTML全文浏览量: 939
- PDF下载量: 175
- 被引次数: 0
