

Parkinson's Disease Detection Method Based on Masked Self-supervised Speech Feature Extraction
-
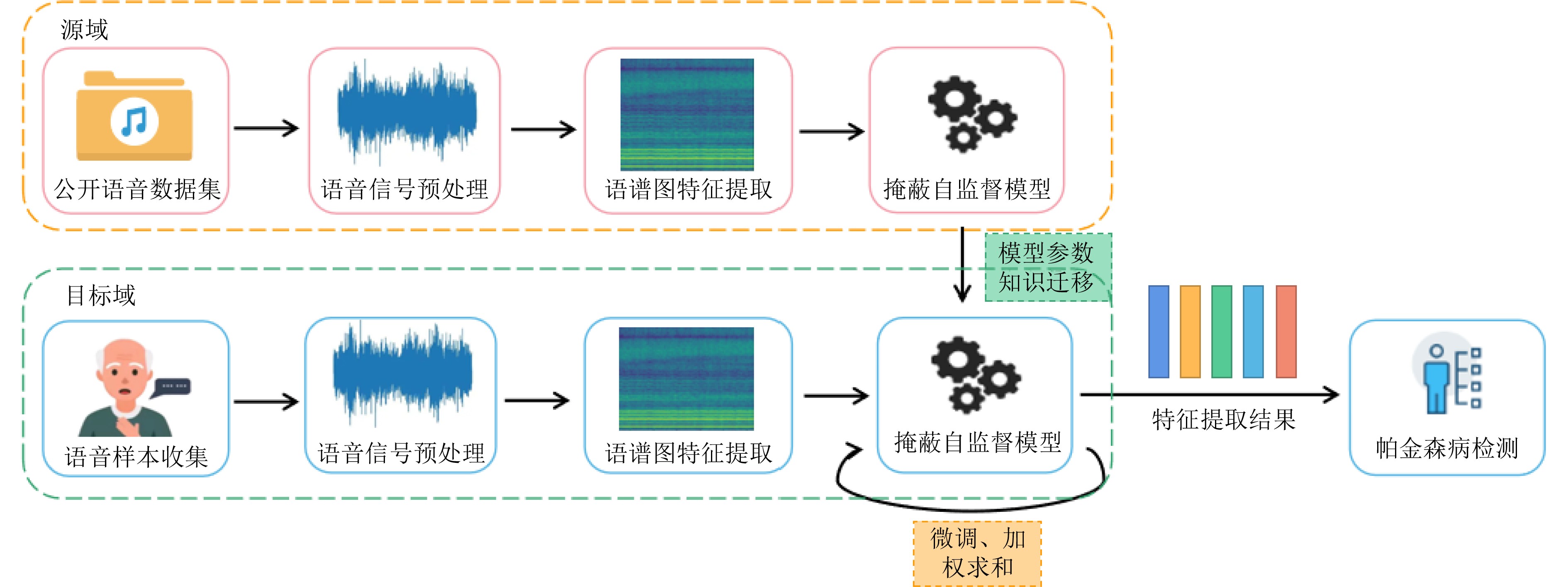
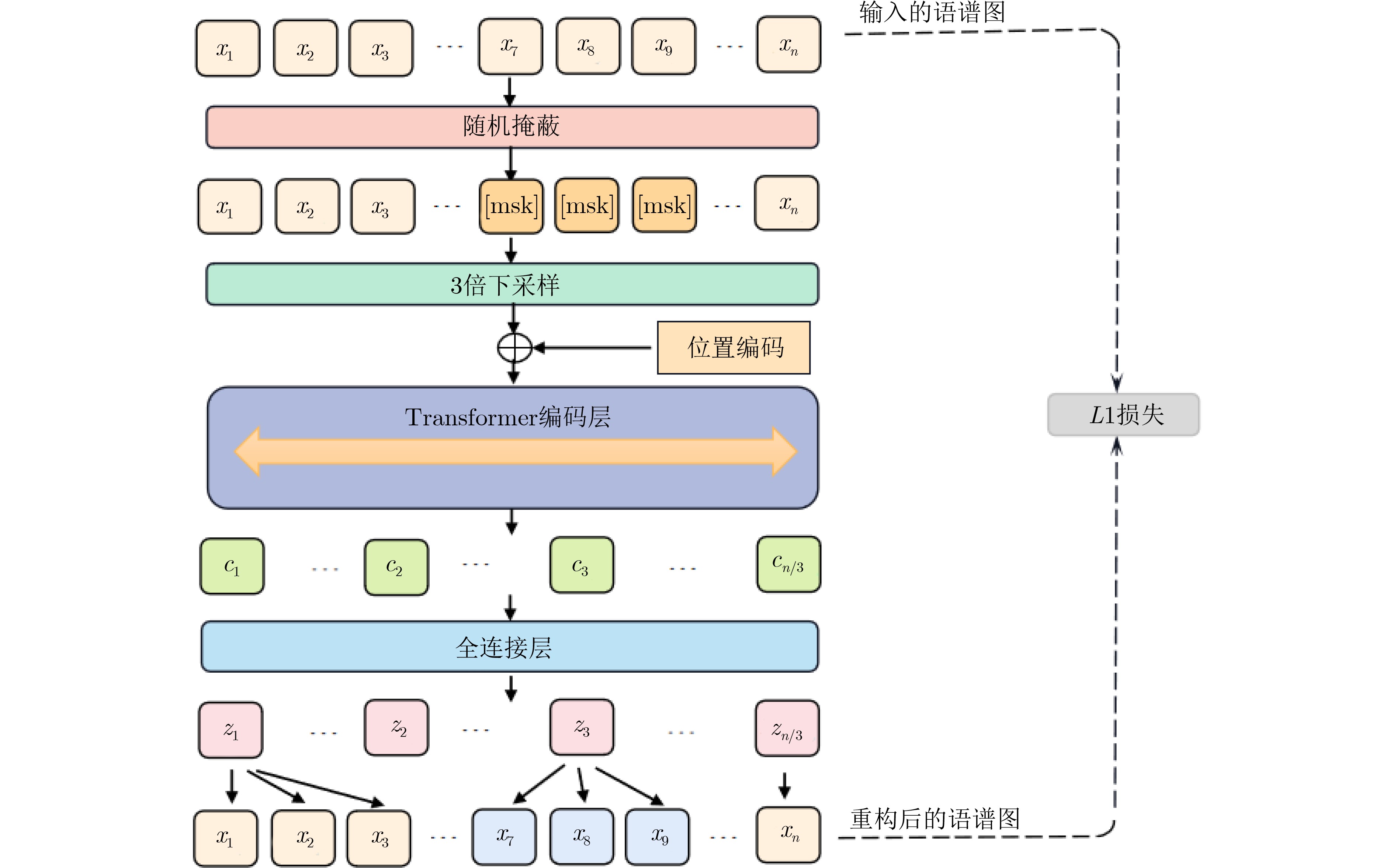
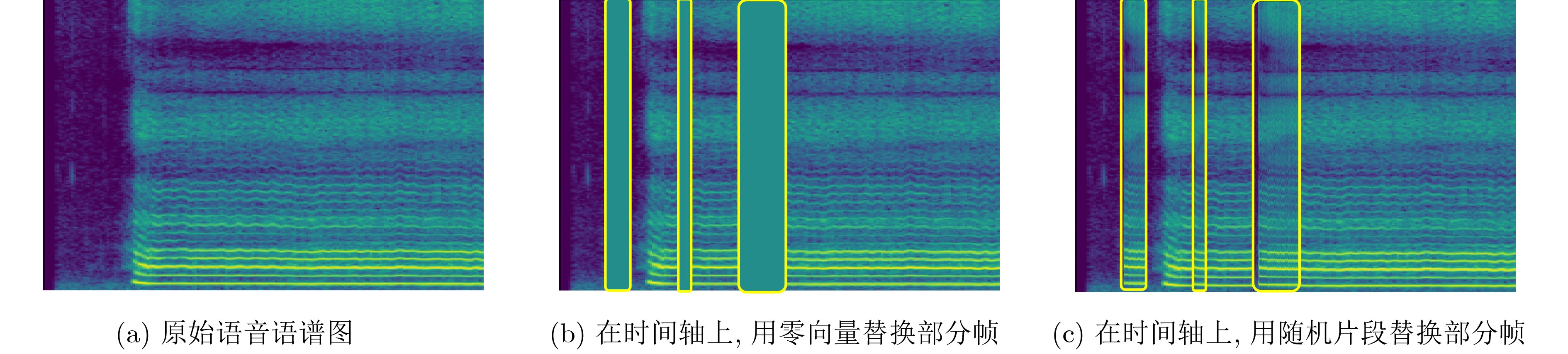
摘要: 帕金森病是一种常见的慢性神经系统疾病,构音障碍是帕金森病的早期症状之一。基于语音进行帕金森病的辅助诊疗有助于更早发现病情和观测病情的发展。传统方法常通过对语音特征(如频率微扰、振幅微扰等)的参数计算来进行疾病评估,然而这些特征可能无法全面反映所有的病理现象,从而影响了检测和评估的准确率。为更好地提取帕金森病患者语音中的病理信息,提升检测和评估的准确率,该文提出一种基于掩蔽自监督语音特征提取的帕金森病检测方法。首先,从帕金森病患者的原始语音中提取Mel语谱图特征,得到患者富含病理特征的全局时序化表示;然后,对部分Mel语谱图特征进行掩蔽,并通过掩蔽自监督模型对掩蔽部分进行重构,从而学习到帕金森病患者语音特征的更高级表示。为解决帕金森病语音数据稀缺的问题,该文先在LibriSpeech公开数据集上进行掩蔽自监督模型的预训练,然后基于迁移学习的思想,利用帕金森病语音数据对预训练好的掩蔽自监督模型进行微调和加权求和,以提升该模型特征表示学习的性能。最终,使用随机森林和支持向量机分类器分别对提取好的语音特征进行分类,以实现帕金森病的检测。该文在MaxLittle公开数据集和课题组自采数据集上,采用10折交叉验证的方法验证了所提方法的有效性。结果表明,与传统的Mel语谱图特征检测方法和其他经典的自监督特征提取方法相比,所提方法在准确率、敏感度、特异度性能方面均有明显提升。Abstract: Parkinson’s disease is a common chronic neurological disease, and dysarthria is one of the early symptoms of this disease. The auxiliary diagnosis and treatment of Parkinson’s disease based on speech is helpful for early detection and observation of the development of this disease. Traditional methods evaluate often Parkinson’s disease by calculating the parameters of speech features (such as Jitter, Shimmer, etc.). However, these features may not fully reflect all pathological phenomena, which affects the accuracy of detection and evaluation. In order to extract better the pathological information from speech of patients with Parkinson’s disease and improve the accuracy of detection and evaluation, a Parkinson’s disease detection method based on masking self-supervised speech feature extraction is proposed. First, Mel spectrogram features are extracted from the original speech of Parkinson’s disease patients, and the global temporal representation with rich pathological features is obtained. Then, partial Mel spectrogram features are masked, and the masked parts are reconstructed by masking self-supervised model, so as to learn a higher-level representation of speech features of Parkinson’s disease patients. In order to solve the problem of the scarcity of Parkinson’s disease speech data, the masking self-supervised model will first be pre-trained on LibriSpeech public data set, and then based on the idea of transfer learning, the pre-trained model will be fine-tuned and weighted summed on Parkinson’s disease speech data. Thus, the feature representation learning performance of the proposed masking self-supervised model can be improved. Finally, random forest classifier and support vector machine classifier are used to classify the extracted speech features to achieve the detection of Parkinson’s disease. The effectiveness of the masking self-supervised model is verified on MaxLittle public data set and our self-collected data set by ten-fold cross-validation. The results show that, compared with the traditional Mel spectrogram feature detection method and other classical self-supervised feature extraction methods, the proposed method has significantly improved the Accuracy, True Positive Rate and True Negative Rate performance.
-
Key words:
- Parkinson’s disease /
- Self-supervised learning /
- Transfer learning /
- Feature extraction
-
表 1 自采帕金森病语音数据集信息统计
PD HC 受试者 [女/男] 25/31 10/12 语音样本数 [女/男] 25/31 25/34 年龄 [女/男] 69.2(7.4)/68.9(8.8) 72.6(5.4)/66(9.3) 患病时间 [女/男] 6.7(4.3)/7.8(4.1) – HY分期 [女/男] 2.6(0.4)/2.2(0.6) –  下载: 导出CSV
下载: 导出CSV
表 2 结合支持向量机分类器进行帕金森病检测的实验结果(%)
方法 性别 ACC TPR TNR Fbank 男 79.5 76.2 79.6 女 74.2 70.8 75.0 全部 78.8 80.7 78.6 Fbank-unsupervised 男 92.5 89.8 95.0 女 83.5 81.6 86.2 全部 90.5 89.0 90.5 MFCC 男 78.5 63.7 78.3 女 75.0 67.5 70.1 全部 77.0 73.4 75.6 MFCC-unsupervised 男 90.1 81.8 85.0 女 88.5 75.1 78.3 全部 89.8 77.9 79.1 Mel 男 80.5 75.8 82.5 女 75.1 60.8 70.1 全部 79.1 74.9 81.0 Mel-unsupervised 男 93.5 94.1 92.5 女 85.8 82.8 87.5 全部 91.5 89.8 91.3
下载: 导出CSV
表 3 结合随机森林分类器进行帕金森病检测的实验结果(%)
方法 性别 ACC TPR TNR Fbank 男 78.5 69.0 66.3 女 69.1 68.3 70.0 全部 71.5 66.4 65.8 Fbank-unsupervised 男 83.5 81.6 86.3 女 73.9 66.3 68.4 全部 79.7 68.1 63.3 MFCC 男 78.5 70.7 70.0 女 62.5 63.7 65.4 全部 72.6 63.2 63.5 MFCC-unsupervised 男 87.0 73.7 74.1 女 77.5 75.8 77.0 全部 78.3 74.4 70.3 Mel 男 83.8 81.7 80.3 女 70.8 70.0 72.5 全部 78.5 62.5 68.0 Mel-unsupervised 男 85.0 79.1 87.9 女 75.8 70.8 77.0 全部 82.3 77.5 71.0
下载: 导出CSV
表 4 MaxLittle数据集上的对比实验结果(%)
方法 ACC TPR TNR Mel+SVM 80.2 81.7 79.4 CPC 86.5 85.2 83.4 APC 88.7 87.3 87.0 本文 96.2 96.1 95.9 本文-ft2 98.5 97.7 98.2 本文-ws 96.9 96.6 95.4
下载: 导出CSV
表 5 自采数据集上的对比实验结果(%)
方法 ACC TPR TNR Mel+SVM 79.1 74.9 81.0 CPC 83.7 85.0 82.5 APC 87.2 84.7 86.9 本文 91.5 89.0 91.3 本文-ft2 94.2 93.1 92.3 本文-ws 93.9 93.3 91.5
下载: 导出CSV
-
[1] BENBA A, JILBAB A, SANDABAD S, et al. Voice signal processing for detecting possible early signs of Parkinson’s disease in patients with rapid eye movement sleep behavior disorder[J]. International Journal of Speech Technology, 2019, 22(1): 121–129. doi: 10.1007/s10772-018-09588-0 [2] SUPHINNAPONG P, PHOKAEWVARANGKUL O, THUBTHONG N, et al. Objective vowel sound characteristics and their relationship with motor dysfunction in Asian Parkinson's disease patients[J]. Journal of the Neurological Sciences, 2021, 426: 117487. doi: 10.1016/j.jns.2021.117487 [3] KING N O, ANDERSON C J, and DORVAL A D. Deep brain stimulation exacerbates hypokinetic dysarthria in a rat model of Parkinson’s disease[J]. Journal of Neuroscience Research, 2016, 94(2): 128–138. doi: 10.1002/jnr.23679 [4] 沈珺, 张天宇, 黄菲菲, 等. 帕金森病构音障碍声学特点的初步探索[J]. 中华神经科杂志, 2019, 52(8): 613–619. doi: 10.3760/cma.j.issn.1006-7876.2019.08.003SHEN Jun, ZHANG Tianyu, HUANG Feifei, et al. Study of voice disorder based on acoustic assessment in Parkinson's disease[J]. Chinese Journal of Neurology, 2019, 52(8): 613–619. doi: 10.3760/cma.j.issn.1006-7876.2019.08.003 [5] SCHALLING E, JOHANSSON K, and HARTELIUS L. Speech and communication changes reported by people with Parkinson’s disease[J]. Folia Phoniatrica et Logopaedica, 2017, 69(3): 131–141. doi: 10.1159/000479927 [6] LITTLE M A, MCSHARRY P E, HUNTER E J, et al. Suitability of dysphonia measurements for telemonitoring of Parkinson's disease[J]. IEEE Transactions on Biomedical Engineering, 2009, 56(4): 1015–1022. doi: 10.1109/TBME.2008.2005954 [7] TSANAS A, LITTLE M A, MCSHARRY P E, et al. Novel speech signal processing algorithms for high-accuracy classification of Parkinson’s disease[J]. IEEE Transactions on Biomedical Engineering, 2012, 59(5): 1264–1271. doi: 10.1109/TBME.2012.2183367 [8] MORO-VELAZQUEZ L, GOMEZ-GARCIA J A, GODINO-LLORENTE J I, et al. A forced Gaussians based methodology for the differential evaluation of Parkinson’s Disease by means of speech processing[J]. Biomedical Signal Processing and Control, 2019, 48: 205–220. doi: 10.1016/j.bspc.2018.10.020 [9] KANINIKA and TAYAL A. Determination of Parkinson’s disease utilizing machine learning methods[C]. 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 2018: 170–173. [10] KARAMAN O, ÇAKIN H, ALHUDHAIF A, et al. Robust automated Parkinson disease detection based on voice signals with transfer learning[J]. Expert Systems with Applications, 2021, 178: 115013. doi: 10.1016/j.eswa.2021.115013 [11] FRID A, SAFRA E J, HAZAN H, et al. Computational diagnosis of Parkinson's disease directly from natural speech using machine learning techniques[C]. 2014 IEEE International Conference on Software Science, Technology and Engineering, Ramat Gan, Israel, 2014: 50–53. [12] RAHMAN A, RIZVI S S, KHAN A, et al. Parkinson's disease diagnosis in cepstral domain using MFCC and dimensionality reduction with SVM classifier[J]. Mobile Information Systems, 2021, 2021: 8822069. doi: 10.1155/2021/8822069 [13] LI Yongming, ZHANG Xinyue, WANG Pin, et al. Insight into an unsupervised two-step sparse transfer learning algorithm for speech diagnosis of Parkinson's disease[J]. Neural Computing and Applications, 2021, 33(15): 9733–9750. doi: 10.1007/s00521-021-05741-0 [14] JIANG Dongwei, LI Wubo, CAO Miao, et al. Speech SimCLR: Combining contrastive and reconstruction objective for self-supervised speech representation learning[C]. The Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 2021: 1544–1548. [15] VAN DEN OORD A, LI Yazhe, and VINYALS O. Representation learning with contrastive predictive coding[J]. arXiv: 1807.03748, 2018. doi: 10.48550/arXiv.1807.03748. [16] CHUNG Y A, HSU W N, TANG Hao, et al. An unsupervised autoregressive model for speech representation learning[C]. The Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 2019: 146–150. [17] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. The 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, America, 2019: 4171–4186. [18] JIANG Dongwei, LI Wubo, ZHANG Ruixiong, et al. A further study of unsupervised pretraining for transformer based speech recognition[C]. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, Canada, 2021: 6538–6542. [19] LIU A H, CHUNG Y A, and GLASS J R. Non-autoregressive predictive coding for learning speech representations from local dependencies[C]. The Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 2021: 3730–3734. [20] LIU A T, LI Shangwei, and LEE H Y. TERA: Self-supervised learning of transformer encoder representation for speech[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 2351–2366. doi: 10.1109/TASLP.2021.3095662 [21] 赵力. 语音信号处理[M]. 3版. 北京: 机械工业出版社, 2016.ZHAO Li. Speech Signal Processing[M]. 3rd ed. Beijing: China Machine Press, 2016. [22] 张涛, 蒋培培, 张亚娟, 等. 基于时频混合域局部统计的帕金森病语音障碍分析方法研究[J]. 生物医学工程学杂志, 2021, 38(1): 21–29. doi: 10.7507/1001-5515.202001024ZHANG Tao, JIANG Peipei, ZHANG Yajuan, et al. Parkinson's disease diagnosis based on local statistics of speech signal in time-frequency domain[J]. Journal of Biomedical Engineering, 2021, 38(1): 21–29. doi: 10.7507/1001-5515.202001024 [23] PANAYOTOV V, CHEN Guoguo, POVEY D, et al. Librispeech: An ASR corpus based on public domain audio books[C]. 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 2015: 5206–5210. [24] LIU A T, YANG Shuwen, CHI P H, et al. Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders[C]. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 6419–6423. [25] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [26] PHAM N Q, NGUYEN T S, NIEHUES J, et al. Very deep self-attention networks for end-to-end speech recognition[C]. The Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 2019: 66–70. [27] LITTLE M A, MCSHARRY P E, ROBERTS S J, et al. Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection[J]. BioMedical Engineering OnLine, 2007, 6: 23. doi: 10.1186/1475-925X-6-23 [28] KINGMA D and BA J. Adam: A method for stochastic optimization[C]. The 3rd International Conference for Learning Representations, San Diego, USA, 2015. -

 下载:
下载:


图(3) / 表(5)
计量
- 文章访问数: 1672
- HTML全文浏览量: 1074
- PDF下载量: 139
- 被引次数: 0
