

Resource Management Based on Deep Reinforcement Learning for UAV Communication Considering Power-Consumption Outage
-
摘要: 最新研究表明,高速传输导致的手机温度变化会影响相应的传输性能。针对高速传输下未考虑与手机温度有关的能耗中断而导致传输性能降低的问题,该文提出一种基于深度强化学习的资源管理方案去考虑无人机(UAV)通信场景下的能耗中断。首先,给出无人机通信的网络模型与智能手机热传递模型的分析;其次,将能耗中断的影响以约束条件的形式整合到无人机场景的优化问题中,并通过联合考虑带宽分配、功率分配和轨迹设计优化系统吞吐量;最后,采用马尔可夫决策过程描述相应的优化问题并通过名为归一化优势函数的深度强化学习算法求解。仿真表明,所提方案能有效提升系统吞吐量并得到合理的无人机飞行轨迹。Abstract: Recent research has demonstrated that the temperature variation of smartphone caused by high data rate transmission could affect the corresponding performance on transmission. Considering the problem of performance degradation on transmission caused by the ignorance of the power-consumption outage which is related with the temperature of smartphone, a deep reinforcement learning based resource management scheme is proposed to consider the power-consumption outage for Unmanned Aerial Vehicle (UAV) communication scenario. Firstly, the analysis for the network model of UAV communication and heat transfer model in smartphone is established. Then, the influence of power-consumption outage is integrated into the optimization problem of UAV scenario in the form of constraint, and the system throughput is optimized via the joint consideration of bandwidth allocation, power allocation and trajectory design. Finally, Markov decision process is adopted to depict the problem and the optimization target is achieved by a deep reinforcement learning algorithm named normalized advantage function. Simulation results manifest that the proposed scheme can effectively enhance the system throughput and achieve appropriate trajectory of UAV.
-
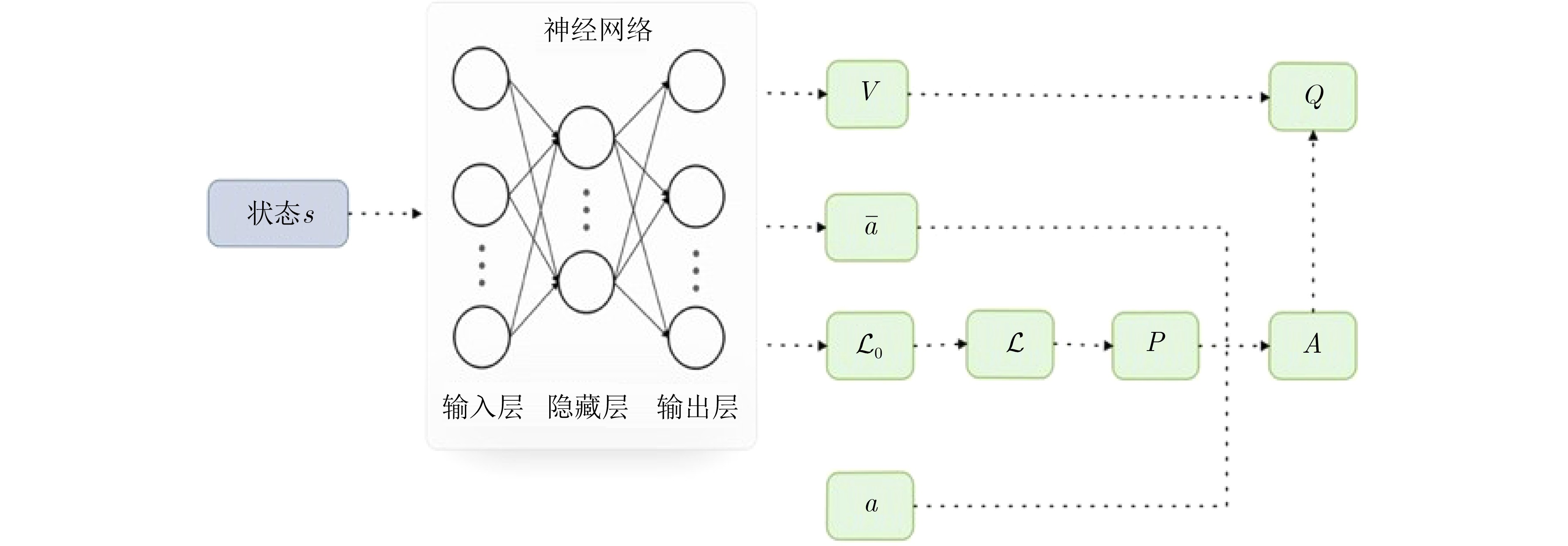
算法1 求解问题$ {\mathcal{P}}_{1} $的NAF算法 输入:主网络$ Q $的参数集$ \boldsymbol{v} $,目标网络$ \widehat{Q} $的参数集$ {\boldsymbol{v}}^{-}=\boldsymbol{v} $,经验
池$ X=\varnothing $,计数器$ t=0 $,$ T=0 $输出:动作向量$ \boldsymbol{a}\left(t\right) $ Repeat: 获得当前时隙状态$ {\boldsymbol{s}}_{t} $,$ {t}_{\mathrm{s}\mathrm{t}\mathrm{a}\mathrm{r}\mathrm{t}}=t $ Repeat: 产生随机噪声向量$ {\mathcal{N}}_{t} $ 选择当前时隙动作$ {\boldsymbol{a}}_{t}={\alpha }^{\text{'}}\left({\boldsymbol{s}}_{\boldsymbol{t}}|{\boldsymbol{v}}_{\boldsymbol{t}}\right)+{\mathcal{N}}_{t} $ 执行动作$ \boldsymbol{a}\left(t\right) $并获得即时奖励$ {r}_{t} $和下一时隙状态$ {\boldsymbol{s}}_{\boldsymbol{t}+1} $ 将经验($ {\boldsymbol{s}}_{t},{\boldsymbol{a}}_{t},{r}_{t},{\boldsymbol{s}}_{t+1} $)存储到经验池$ X $ 从经验池$ X $中随机抽样包含$ M $条经验的Mini-batch 对于经验$ m $计算:$ {y}_{m}={r}_{m}+\gamma \widehat{V}\left({\boldsymbol{s}}_{\boldsymbol{m}+1}|{\boldsymbol{v}}_{\boldsymbol{t}}^{-}\right) $ 计算损失函数:
$ L\left({\boldsymbol{v}}_{\boldsymbol{t}}\right)=\dfrac{1}{M}\displaystyle\sum _{m=1}^{M}{\left({y}_{m}-Q\left({\boldsymbol{s}}_{\boldsymbol{m}},{\boldsymbol{a}}_{\boldsymbol{m}}|{\boldsymbol{v}}_{\boldsymbol{t}}\right)\right)}^{2} $使用梯度下降法对主网络进行更新:
$ {\boldsymbol{v}}_{\boldsymbol{t}}:={\boldsymbol{v}}_{\boldsymbol{t}}-\alpha \nabla L\left({\boldsymbol{v}}_{\boldsymbol{t}}\right) $$ t:=t+1 $,每隔$ Y $个时隙更新目标网络$ {\boldsymbol{v}}_{\boldsymbol{t}}^{-}={\boldsymbol{v}}_{\boldsymbol{t}} $ Until $ t=={t}_{\mathrm{s}\mathrm{t}\mathrm{a}\mathrm{r}\mathrm{t}}+\stackrel{~}{T} $ $ T:=T+1 $ Until $ T > {T}_{\mathrm{m}\mathrm{a}\mathrm{x}} $  下载: 导出CSV
下载: 导出CSV
表 1 仿真参数
参数 值 参数 值 参数 值 $\tilde{T}\left(\mathrm{回}\mathrm{合}\right)$ $ 30 $ $ {I}_{\mathrm{c}} $ $ {10}^{2} $ $ G\left(\mathrm{d}\mathrm{B}\mathrm{i}\right) $ $ 10 $ $ M\left(\mathrm{经}\mathrm{验}\right) $ $ 128 $ $ \eta $ $ 0.59 $ $ {f}_{\mathrm{C}\mathrm{F}}\left(\mathrm{G}\mathrm{H}\mathrm{z}\right) $ $ 40 $ $ Y\left(\mathrm{时}\mathrm{隙}\right) $ $ 300 $ $ {F}_{\mathrm{B}\mathrm{P}} $ $ 3 $ $ {H}_{\mathrm{u}}\left(\mathrm{m}\right) $ $ 70 $ $ {N}_{\mathrm{T}\mathrm{x}}\left(\mathrm{天}\mathrm{线}\right) $ $ 64 $ $ {F}_{\mathrm{A}\mathrm{P}} $ $ 4 $ $ {T}_{\mathrm{e}\mathrm{n}\mathrm{v}}\left(\mathrm{K}\right) $ $ 298 $ $ {N}_{\mathrm{R}\mathrm{x}}\left(\mathrm{天}\mathrm{线}\right) $ $ 4 $ $ B\left(\mathrm{G}\mathrm{H}\mathrm{z}\right) $ $ 1 $ $ {T}_{0}^{\mathrm{s}\mathrm{u}\mathrm{r}}\left(\mathrm{K}\right) $ $ 303 $ $ \theta $ $ \pi /2 $ $ {m}_{\mathrm{c}}\left(\mathrm{g}\right) $ $ 1 $ $ {K}_{\mathrm{B}\mathrm{P}} $ $8\times {10}^{7}$ $ {\chi }_{\mathrm{N}\mathrm{L}\mathrm{o}\mathrm{s}} $ $ 2.4 $ $ {P}_{\mathrm{t}\mathrm{x}}\left(\mathrm{W}\right) $ $ 5 $ $ {K}_{\mathrm{A}\mathrm{P}} $ $6{\times 10}^{7}$ $ {\psi }_{\mathrm{N}\mathrm{L}\mathrm{o}\mathrm{S}} $ $ 5.27 $ $ {d}_{0}\left(\mathrm{m}\right) $ $ 5 $ $ {P}_{\mathrm{L}\mathrm{N}\mathrm{A}}\left(\mathrm{m}\mathrm{W}\right) $ $ 24.3 $ $ {\chi }_{\mathrm{L}\mathrm{o}\mathrm{s}} $ $ 2 $ $ L\left(\mathrm{m}\mathrm{m}\right) $ $ 2 $ $ {N}_{0}\left(\mathrm{d}\mathrm{B}\mathrm{m}/\mathrm{H}\mathrm{z}\right) $ $ -174 $ $ {\psi }_{\mathrm{L}\mathrm{o}\mathrm{S}} $ $ 5.3 $ $ D\left(\mathrm{m}\mathrm{m}\right) $ $ 1 $ ${k}_{1}\left(\mathrm{W}/(\mathrm{m}\cdot \mathrm{K})\right)$ $ 401 $ $ {\alpha }_{1} $ $ 0.1 $ $ A\left({\mathrm{c}\mathrm{m}}^{2}\right) $ $ 1 $ ${k}_{2}\left(\mathrm{W}/(\mathrm{m}\cdot \mathrm{K})\right)$ $ 130 $ $ {\alpha }_{2} $ $ 0.2 $ $ {D}_{\mathrm{m}\mathrm{a}\mathrm{x}}\left(\mathrm{m}\right) $ $ 90 $ ${h}_{\mathrm{a}\mathrm{i}\mathrm{r} }\left(\mathrm{W}/({\mathrm{m} }^{2}\cdot \mathrm{K})\right)$ $ 26.3 $ $ \lambda $ $ 0.3 $ $ {T}_{\mathrm{m}\mathrm{a}\mathrm{x}}\left(\mathrm{回}\mathrm{合}\right) $ $ 600 $ ${c}_{\mathrm{c}\mathrm{h}\mathrm{i}\mathrm{p} }\left(\mathrm{J}/(\mathrm{k}\mathrm{g}\cdot \mathrm{K})\right)$ $ 1030 $
下载: 导出CSV
-
[1] GERACI G, GARCIA-RODRIGUE A, AZARI M M, et al. What will the future of UAV cellular communications be? A flight from 5G to 6G[J]. IEEE Communications Surveys & Tutorials, 2022, 24(3): 1304–1335. doi: 10.1109/COMST.2022.3171135 [2] YANG Jing, GE Xiaohu, THOMPSON J, et al. Power-consumption outage in beyond fifth generation mobile communication systems[J]. IEEE Transactions on Wireless Communications, 2021, 20(2): 897–910. doi: 10.1109/TWC.2020.3029051 [3] GARIMELLA S V, PERSOONS T, WEIBEL J A, et al. Electronics thermal management in information and communications technologies: Challenges and future directions[J]. IEEE Transactions on Components, Packaging and Manufacturing Technology, 2017, 7(8): 1191–1205. doi: 10.1109/TCPMT.2016.2603600 [4] CHIRIAC V, MOLLOY S, ANDERSON J, et al. A figure of merit for mobile device thermal management[C]. The 15th IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm), Las Vegas, USA, 2016: 1393–1397. [5] BHAT G, GUMUSSOY S, and OGRAS U Y. Power and thermal analysis of commercial mobile platforms: Experiments and case studies[C]. 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 2019: 144–149. [6] ARNOMO S A, SIMANJUNTAK P, and NUR SADIKAN S F. Overheating analysis of mobile phone temperature based on multitasking process[C]. 2021 International Conference on Computer Science and Engineering (IC2SE), Padang, Indonesia, 2021: 1–6. [7] MAMMELA A and ANTTONEN A. Why will computing power need particular attention in future wireless devices[J]. IEEE Circuits and Systems Magazine, 2017, 17(1): 12–26. doi: 10.1109/MCAS.2016.2642679 [8] YANG Jing, GE Xiaohu, and ZHONG Yi. How much of wireless rates can smartphones support in 5G networks?[J]. IEEE Network, 2019, 33(3): 122–129. doi: 10.1109/MNET.2018.1800025 [9] 陈新颖, 盛敏, 李博, 等. 面向6G的无人机通信综述[J]. 电子与信息学报, 2022, 44(3): 781–789. doi: 10.11999/JEIT210789CHEN Xinying, SHENG Min, LI Bo, et al. Survey on unmanned aerial vehicle communications for 6G[J]. Journal of Electronics &Information Technology, 2022, 44(3): 781–789. doi: 10.11999/JEIT210789 [10] ZHAN Cheng and HUANG Renjie. Energy efficient adaptive video streaming with rotary-wing UAV[J]. IEEE Transactions on Vehicular Technology, 2020, 69(7): 8040–8044. doi: 10.1109/TVT.2020.2993303 [11] CHEN Yan, ZHANG Hangjing, and HU Yang. Optimal power and bandwidth allocation for multiuser video streaming in UAV relay networks[J]. IEEE Transactions on Vehicular Technology, 2020, 69(6): 6644–6655. doi: 10.1109/TVT.2020.2985061 [12] FU Xiuhua, DING Tian, KADOCH M, et al. Uplink performance analysis of UAV cellular communications with power control[C]. 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 2020: 676–679. [13] LIU Xiao, LIU Yuanwei, CHEN Yue, et al. Trajectory design and power control for multi-UAV assisted wireless networks: A machine learning approach[J]. IEEE Transactions on Vehicular Technology, 2019, 68(8): 7957–7969. doi: 10.1109/TVT.2019.2920284 [14] CHEN Mingzhe, SAAD W, and YIN Changchuan. Echo-liquid state deep learning for 360 content transmission and caching in wireless VR networks with cellular-connected UAVs[J]. IEEE Transactions on Communications, 2019, 67(9): 6386–6400. doi: 10.1109/TCOMM.2019.2917440 [15] GOLDSMITH A. Wireless Communications[M]. Cambridge, USA: Cambridge University Press, 2005: 78–79. [16] ZHAO Pengtao, TIAN Hui, CHEN K C, et al. Context-aware TDD configuration and resource allocation for mobile edge computing[J]. IEEE Transactions on Communications, 2020, 68(2): 1118–1131. doi: 10.1109/tcomm.2019.2952580 [17] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529–533. doi: 10.1038/nature14236 [18] GU Shixiang, LILLICRAP T, SUTSKEVER I, et al. Continuous deep Q-learning with model-based acceleration[C]. The 33rd International Conference on International Conference on Machine Learning, New York, USA, 2016: 2829–2838. -

 下载:
下载:


图(3) / 表(2)
计量
- 文章访问数: 1059
- HTML全文浏览量: 686
- PDF下载量: 122
- 被引次数: 0
