

Pedestrian Re-Identification Based on CNN and TransFormer Multi-scale Learning
-
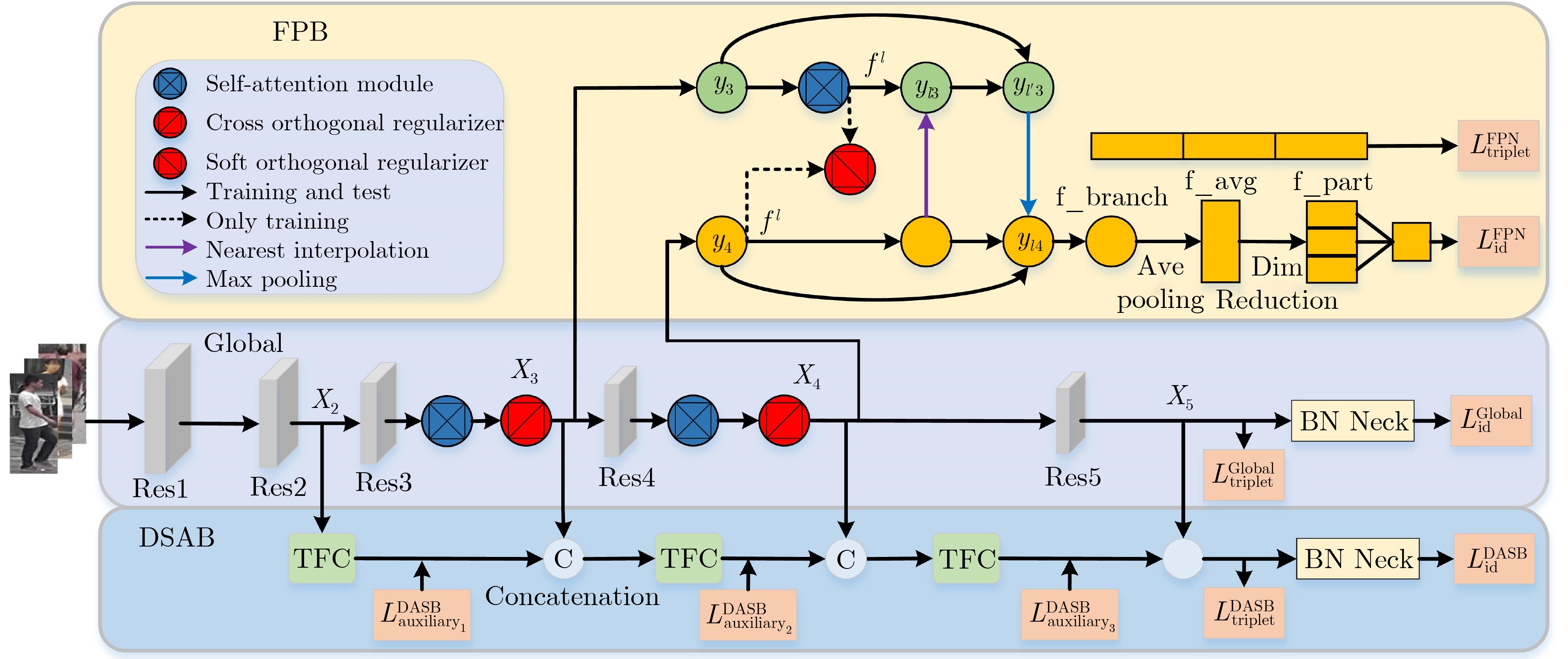
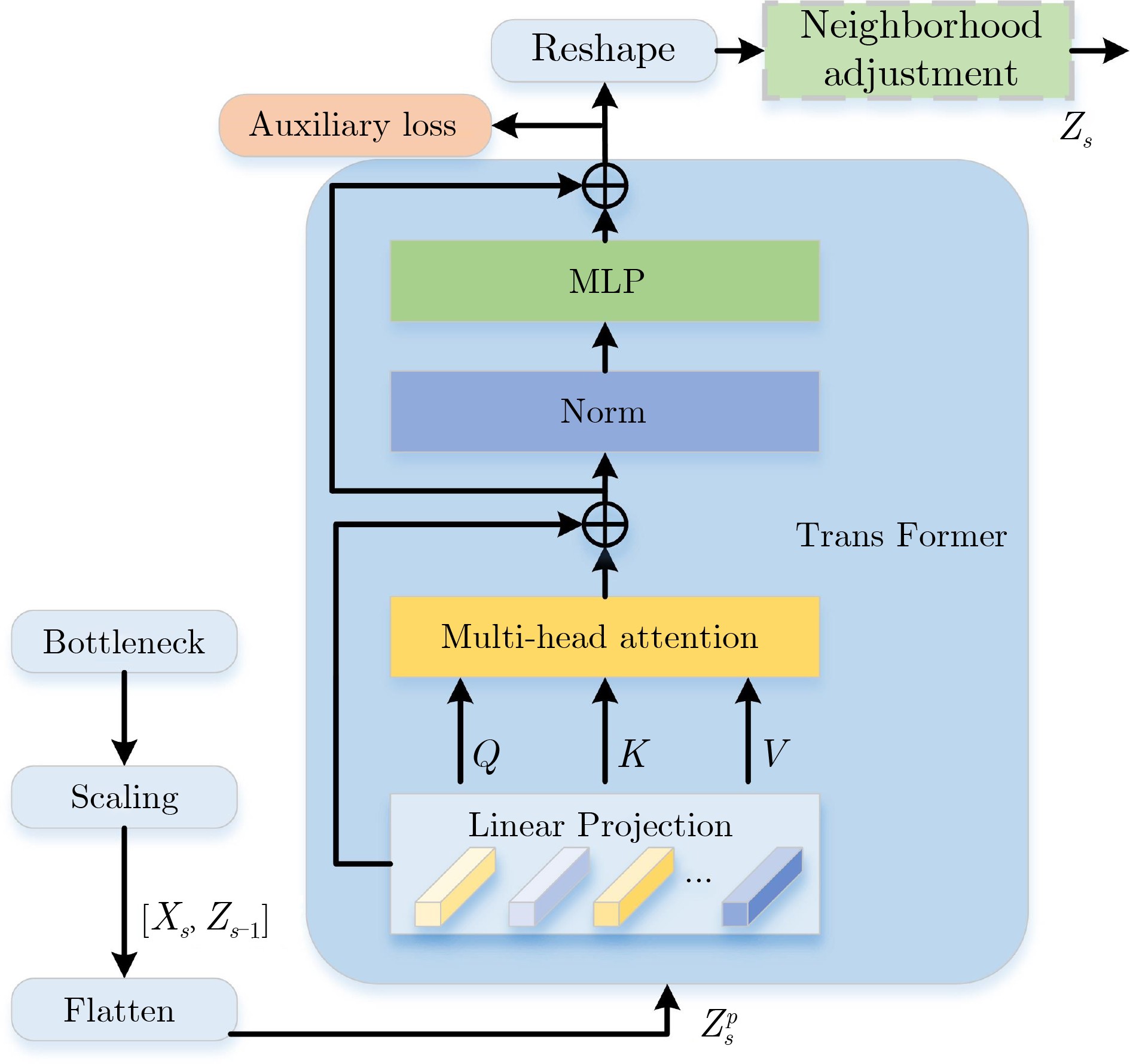
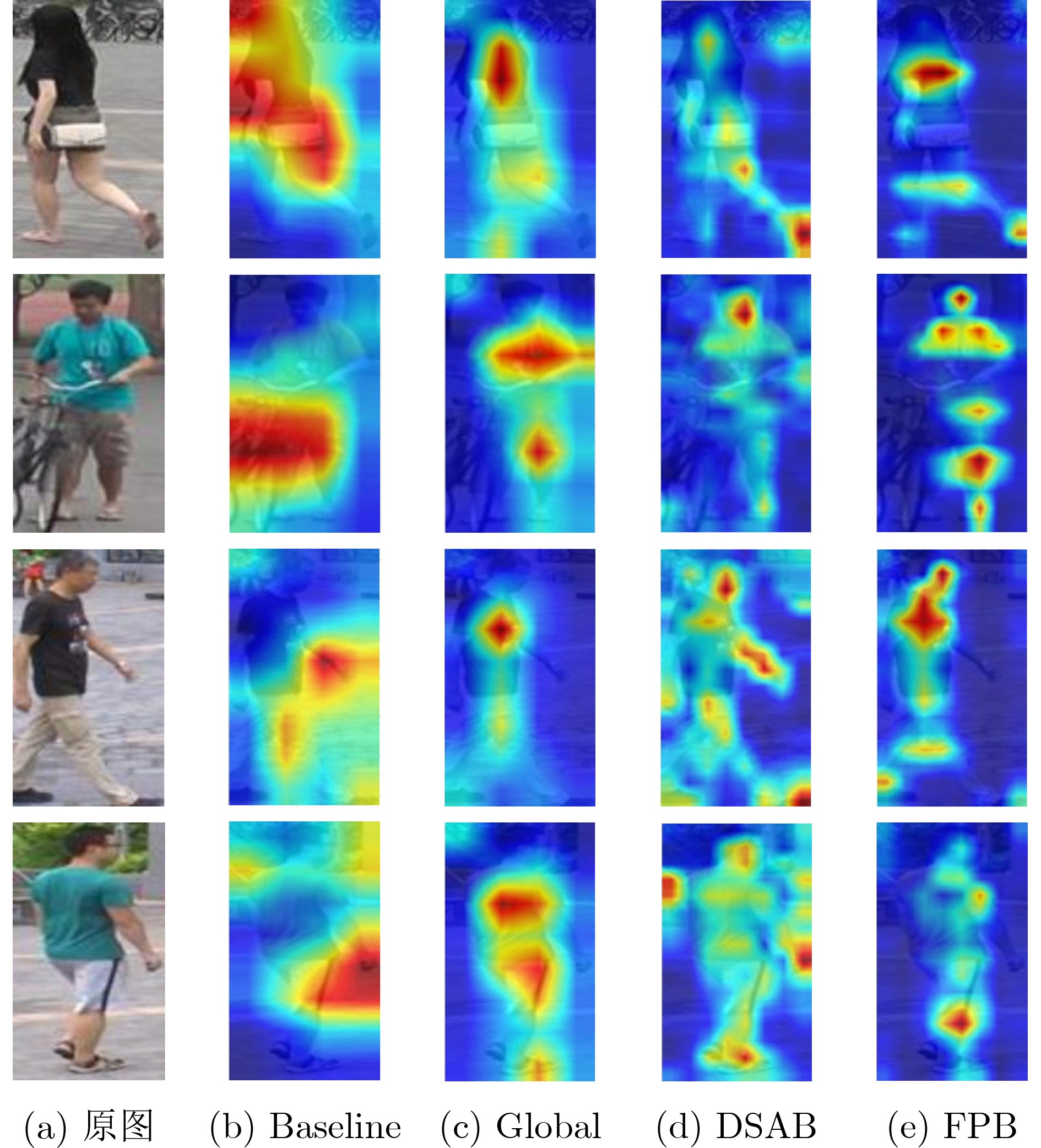
摘要: 行人重识别(ReID)旨在跨监控摄像头下检索出特定的行人目标。为聚合行人图像的多粒度特征并进一步解决深层特征映射相关性的问题,该文提出基于CNN和TransFormer多尺度学习行人重识别方法(CTM)进行端对端的学习。CTM网络由全局分支、深度聚合分支和特征金字塔分支组成,其中全局分支提取行人图像全局特征,提取具有不同尺度的层次特征;深度聚合分支循环聚合CNN的层次特征,提取多尺度特征;特征金字塔分支是一个双向的金字塔结构,在注意力模块和正交正则化操作下,能够显著提高网络的性能。大量实验结果表明了该文方法的有效性,在Market1501, DukeMTMC-reID和MSMT17数据集上,mAP/Rank-1分别达到了90.2%/96.0%, 82.3%/91.6%和63.2%/83.7%,优于其他现有方法。
-
关键词:
- 行人重识别 /
- TransFormer /
- CNN /
- 金字塔结构
Abstract: Person Re-IDentification (ReID) aims to retrieve specific pedestrian targets across surveillance cameras. For the purpose of aggregating the multi-granularity features of pedestrian images and further solving the problem of deep feature mapping correlation, Person Re-Identification based on CNN and TransFormer Multi-scale learning (CTM) is proposed. The CTM network is composed of a global branch, a deep aggregation branch and a feature pyramid branch. Global branch extracts global features of pedestrian images, and extracts hierarchical features with different scales. The deep aggregation branch aggregates recursively the hierarchical features of CNN and extracts multi-scale features. The feature pyramid branch is a two-way pyramid structure, under the attention module and orthogonal regularization operation, it can significantly improve the performance of the network. Experiments on three large scale datasets show the effectiveness of CTM. On the Market1501, DukeMTMC-reID and MSMT17 datasets, mAP/Rank-1 reached 90.2%/96.0%, 82.3%/91.6% and 63.2%/83.7%, which is superior to other existing methods.-
Key words:
- Pedestrian Re-IDentification (ReID) /
- TransFormer /
- CNN /
- Pyramid structure
-
表 1 不同方法在公开数据集上的性能比较(%)
方法 出处 Market-1501 DukeMTMC-reID MSMT17 mAP Rank-1 mAP Rank-1 mAP Rank-1 MHN[8] CVPR2019 85.0 95.1 77.2 89.1 – – SONA[25] ICCV2019 88.6 95.6 78.1 89.3 – – OSNet[5] ICCV2019 84.9 94.8 73.5 88.6 52.9 78.7 HOReID[26] CVPR2020 84.9 94.2 75.6 86.9 – – SNR[27] CVPR2020 84.7 94.4 72.9 84.4 – – CACE-Net[28] CVPR2020 90.3 96.0 81.3 90.1 62.0 83.5 ISP[29] ECCV2020 88.6 95.3 80.0 89.6 – – CDNet[30] CVPR2021 86.0 95.1 76.8 88.6 54.7 78.9 HAT[16] MM2021 89.8 95.8 81.4 90.4 61.2 82.3 L3DS[31] CVPR2021 87.3 95.0 76.1 88.2 – – PAT[32] CVPR2021 88.0 85.4 78.2 88.8 – – 本文 90.2 96.0 82.3 91.6 63.2 83.7  下载: 导出CSV
下载: 导出CSV
表 2 不同分支对实验结果的影响(DukeMTMC-reID)(%)
Branch mAP Rank-1 Rank-5 Rank-10 HAT(Baseline) 81.4 90.4 95.6 97.1 +DSAB 82.1 91.0 95.7 96.8 +FPB 82.0 91.2 95.7 97.2 CTM 82.3 91.6 95.9 97.5 注:+表示网络中仅使用该分支
下载: 导出CSV
表 3 分块策略对比实验(DukeMTMC-reID)(%)
Part-Level mAP Rank-1 Rank-5 Rank-10 +2 part-level 81.9 90.8 95.3 96.8 +3 part-level 82.3 91.6 95.9 97.5 +4 part-level 82.3 91.2 95.4 97.0 +5 part-level 81.8 90.2 95.6 97.2
下载: 导出CSV
表 4 正交正则化对实验的影响(DukeMTMC-reID)(%)
Method mAP Rank-1 Rank-5 Rank-10 HAT(Baseline) 81.4 90.4 95.6 97.1 –SOR, COR 82.0 91.2 95.8 96.9 +COR 82.1 91.4 95.6 97.2 +SOR 82.3 91.5 95.6 97.1 CTM 82.3 91.6 95.9 97.5 (注:+表示网络中仅使用该操作,-表示均不使用操作)
下载: 导出CSV
表 5 注意力模块对实验结果的影响(DukeMTMC-reID)(%)
Attention mAP Rank-1 Rank-5 Rank-10 HAT(Baseline) 81.4 90.4 95.6 97.1 +RGA-C 82.1 91.2 95.8 96.8 +RGA-S 82.0 91.4 95.6 97.4 +Attention on backone 81.9 91.4 95.4 96.9 +Attention on FPB 82.2 91.3 95.9 97.2 CTM 82.3 91.6 95.9 97.5
下载: 导出CSV
-
[1] 邹国锋, 傅桂霞, 高明亮, 等. 行人重识别中度量学习方法研究进展[J]. 控制与决策, 2021, 36(7): 1547–1557. doi: 10.13195/j.kzyjc.2020.0801ZOU Guofeng, FU Guixia, GAO Mingliang, et al. A survey on metric learning in person re-identification[J]. Control and Decision, 2021, 36(7): 1547–1557. doi: 10.13195/j.kzyjc.2020.0801 [2] 贲晛烨, 徐森, 王科俊. 行人步态的特征表达及识别综述[J]. 模式识别与人工智能, 2012, 25(1): 71–81. doi: 10.16451/j.cnki.issn1003-6059.2012.01.010BEN Xianye, XU Sen, and WANG Kejun. Review on pedestrian gait feature expression and recognition[J]. Pattern Recognition and Artificial Intelligence, 2012, 25(1): 71–81. doi: 10.16451/j.cnki.issn1003-6059.2012.01.010 [3] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [4] SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]. The 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. [5] ZHOU Kaiyang, YANG Yongxin, CAVALLARO A, et al. Omni-scale feature learning for person re-identification[C]. The 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 3701–3711. [6] WIECZOREK M, RYCHALSKA B, and DABROWSKI J. On the unreasonable effectiveness of centroids in image retrieval[C]. The 28th International Conference on Neural Information Processing, Sanur, Indonesia, 2021: 212–223. [7] 匡澄, 陈莹. 基于多粒度特征融合网络的行人重识别[J]. 电子学报, 2021, 49(8): 1541–1550. doi: 10.12263/DZXB.20200974KUANG Cheng and CHEN Ying. Multi-granularity feature fusion network for person re-identification[J]. Acta Electronica Sinica, 2021, 49(8): 1541–1550. doi: 10.12263/DZXB.20200974 [8] CHEN Binghui, DENG Weihong, and HU Jiani. Mixed high-order attention network for person re-identification[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 371–381. [9] CHEN Xuesong, FU Canmiao, ZHAO Yong, et al. Salience-guided cascaded suppression network for person re-identification[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 3297–3307. [10] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [11] HAN Kai, WANG Yunhe, CHEN Hanting, et al. A survey on visual transformer[EB/OL]. https://doi.org/10.48550/arXiv.2012.12556, 2012. [12] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv: 2010.11929, 2020. [13] HE Shuting, LUO Hao, WANG Pichao, et al. TransReID: Transformer-based object re-identification[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 14993–15002. [14] PENG Zhiliang, HUANG Wei, GU Shanzhi, et al. Conformer: Local features coupling global representations for visual recognition[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 357–366. [15] WANG Wenhai, XIE Enze, LI Xiang, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021. [16] ZHANG Guowen, ZHANG Pingping, QI Jinqing, et al. HAT: Hierarchical aggregation transformers for person re-identification[C]. The 29th ACM International Conference on Multimedia, Chengdu, China, 2021: 516–525. [17] ZHANG Suofei, YIN Zirui, WU X, et al. FPB: Feature pyramid branch for person re-identification[EB/OL]. https://doi.org/10.48550/arXiv.2108.01901, 2021. [18] ZHENG Liang, SHEN Liyue, TIAN Lu, et al. Scalable person re-identification: A benchmark[C]. The 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1116–1124. [19] RISTANI E, SOLERA F, ZOU R, et al. Performance measures and a data set for multi-target, multi-camera tracking[C]. The European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 17–35. [20] WEI Longhui, ZHANG Shiliang, GAO Wen, et al. Person transfer GAN to bridge domain gap for person re-identification[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 79–88. [21] ZHANG Zhizheng, LAN Cuiling, ZENG Wenjun, et al. Relation-aware global attention for person re-identification[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 3183–3192. [22] CHEN Tianlong, DING Shaojin, XIE Jingyi, et al. ABD-net: Attentive but diverse person re-identification[C]. The 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 8350–8360. [23] HERMANS A, BEYER L, and LEIBE B. In defense of the triplet loss for person re-identification[EB/OL]. https://doi.org/10.48550/arXiv.1809.05864, 2017. [24] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2818–2826. [25] BRYAN B, GONG Yuan, ZHANG Yizhe, et al. Second-order non-local attention networks for person re-identification[C]. The 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 3759–3768. [26] WANG Guan'an, YANG Shuo, LIU Huanyu, et al. High-order information matters: Learning relation and topology for occluded person re-identification[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 6448–6457. [27] JIN Xin, LAN Cuiling, ZENG Wenjun, et al. Style normalization and restitution for generalizable person re-identification[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 3140–3149. [28] YU Fufu, JIANG Xinyang, GONG Yifei, et al. Devil's in the details: Aligning visual clues for conditional embedding in person re-identification[EB/OL]. https://doi.org/10.48550/arXiv.2009.05250, 2020. [29] ZHU Kuan, GUO Haiyun, LIU Zhiwei, et al. Identity-guided human semantic parsing for person re-identification[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 346–363. [30] LI Hanjun, WU Gaojie, and ZHENG Weishi. Combined depth space based architecture search for person re-identification[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 6725–6734. [31] CHEN Jiaxing, JIANG Xinyang, WANG Fudong, et al. Learning 3D shape feature for texture-insensitive person re-identification[C]. The 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 8142–8151. [32] LI Yulin, HE Jianfeng, ZHANG Tianzhu, et al. Diverse part discovery: Occluded person re-identification with part-aware transformer[C]. The 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 2897–2906. [33] ZHOU Kaiyang and XIANG Tao. Torchreid: A library for deep learning person re-identification in pytorch[EB/OL]. https://doi.org/10.48550/arXiv.1910.10093, 2019. -

 下载:
下载:


图(3) / 表(5)
计量
- 文章访问数: 1969
- HTML全文浏览量: 2486
- PDF下载量: 270
- 被引次数: 0
