

Character-level Adversarial Samples Generation Approach for Chinese Text Classification
-
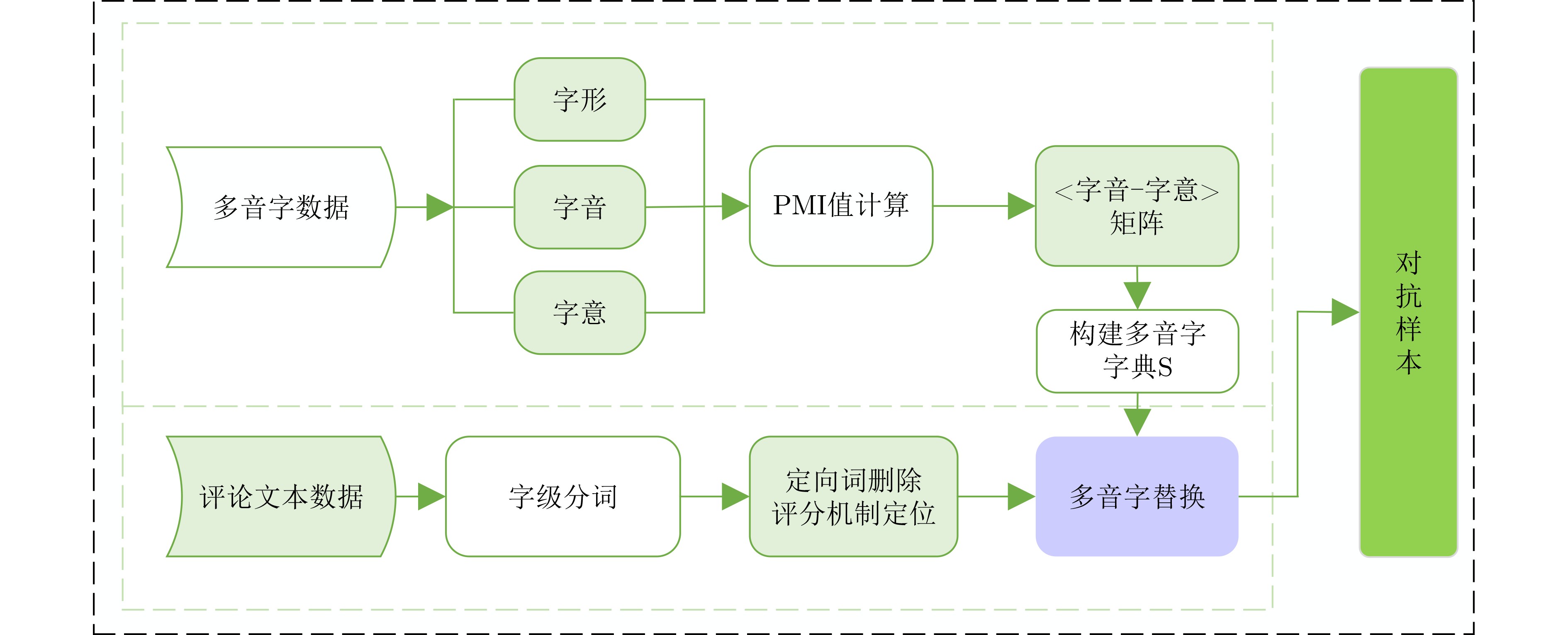
摘要: 对抗样本生成是一种通过添加较小扰动信息,使得神经网络产生误判的技术,可用于检测文本分类模型的鲁棒性。目前,中文领域对抗样本生成方法主要有繁体字和同音字替换等,这些方法都存在对抗样本扰动幅度大,生成对抗样本质量不高的问题。针对这些问题,该文提出一种字符级对抗样本生成方法(PGAS),通过对多音字进行替换可以在较小扰动下生成高质量的对抗样本。首先,构建多音字字典,对多音字进行标注;然后对输入文本进行多音字替换;最后在黑盒模式下进行对抗样本攻击实验。实验在多种情感分类数据集上,针对多种最新的分类模型验证了该方法的有效性。Abstract: Adversarial sample generation is a technique that makes the neural network produce misjudgments by adding small disturbance information. Which can be used to detect the robustness of text classification models. At present, the methods of sample generation in the Chinese domain include mainly traditional characters and homophones substitution, which have the problems of large disturbance amplitude of sample generation and low quality of sample generation. Polyphonic characters Generation Adversarial Sample (PGAS), a character-level countermeasure samples generation approach, is proposed in this paper. Which can generate high-quality adversarial samples with minor disturbance by replacing polyphonic characters. First, a polyphonic word dictionary to label polyphonic words is constructed. Then, the input text with polyphonic words is replaced. Finally, an adversarial sample attack experiment in the black-box model is conducted. Experiments on multiple sentiment classification datasets verify the effectiveness of the proposed method for a variety of the latest classification models.
-
表 1 实验数据集
项目 酒店评论数据 微博评论数据 商品评论数据 任务类型 情感倾向性分类 情感倾向性分类 情感倾向性分类 分类数目 2 2 2 训练集(条) 4120 70000 42130 测试集(条) 1766 30000 18056 多音字数量(个) 2556952 7391456 6585441  下载: 导出CSV
下载: 导出CSV
表 2 在酒店评论数据集上的对比试验结果(%)
测试模型 无修改 对比方法 本文方法 WordHandling CWordAttacker DeepWordBug FastWordBug PGAS 准确率 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 SVM 76.35 72.19 4.16 71.03 5.32 69.18 7.17 70.15 6.20 52.36 23.99 LSTM 83.21 76.25 6.96 74.29 8.92 72.51 10.70 75.22 7.99 62.17 21.04 MemNet 77.12 70.31 6.81 72.59 4.53 70.15 6.97 69.19 7.93 58.63 18.49 IAN 86.31 81.25 5.06 83.26 3.05 78.32 7.99 78.29 8.02 64.92 21.39 AOA 79.91 71.26 8.65 73.29 6.62 68.25 11.66 70.53 9.38 60.15 19.76 AEN-GloVe 86.32 79.81 6.51 81.07 5.25 77.16 9.16 80.09 6.23 68.37 17.95 LSTM+SynATT 88.61 83.59 5.02 82.56 6.05 78.39 10.22 81.37 7.24 61.84 26.77 TD-GAT 78.36 72.20 6.16 73.21 5.15 72.19 6.17 71.24 7.12 60.23 18.13 ASGCN 82.97 77.18 5.79 77.41 5.56 71.05 11.92 73.08 9.89 61.08 21.89 CNN 82.36 74.21 8.15 76.38 5.98 69.91 12.45 69.51 12.85 59.39 22.97 pos-ACNN-CNN 76.28 70.15 6.13 72.53 3.75 68.25 8.03 66.19 10.09 58.18 18.10
下载: 导出CSV
表 3 在微博评论数据集上的对比试验结果(%)
测试模型 无修改 对比方法 本文方法 WordHandling CWordAttacker DeepWordBug FastWordBug PGAS 准确率 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 SVM 74.25 68.32 5.93 69.04 5.21 66.03 8.22 63.51 10.74 53.21 21.04 LSTM 79.66 72.58 7.08 71.22 8.44 68.25 11.41 69.79 9.87 59.74 19.92 MemNet 73.28 66.82 6.46 65.39 7.89 64.51 8.77 59.21 14.07 54.09 19.19 IAN 80.39 74.41 5.98 76.28 4.11 73.28 7.11 74.07 6.32 59.74 20.65 AOA 77.21 68.25 8.96 63.05 14.16 62.89 14.32 64.19 13.02 53.66 23.55 AEN-GloVe 85.31 74.29 11.02 73.08 12.23 74.85 10.46 76.28 9.03 66.23 19.08 LSTM+SynATT 89.07 72.14 16.93 75.44 13.63 77.60 11.47 81.18 7.89 67.04 22.03 TD-GAT 83.06 76.33 6.73 73.98 9.08 72.56 10.50 74.61 8.45 54.39 28.67 ASGCN 80.17 69.19 10.98 71.04 9.13 69.04 11.13 62.88 17.29 56.18 23.99 CNN 76.33 68.38 7.95 66.37 9.96 69.71 6.62 69.44 6.89 57.20 19.13 pos-ACNN-CNN 70.94 61.25 9.69 59.37 11.57 61.43 9.51 60.07 10.87 59.33 11.61
下载: 导出CSV
表 4 在商品评论数据集上的对比试验结果(%)
测试模型 无修改 对比方法 本文方法 WordHandling CWordAttacker DeepWordBug FastWordBug PGAS 准确率 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 准确率 降低幅度 SVM 73.28 64.21 9.07 66.07 7.21 63.19 10.09 65.03 8.25 54.64 18.64 LSTM 77.04 69.07 7.97 67.45 9.59 68.17 8.87 68.29 8.75 53.21 23.83 MemNet 82.36 73.85 8.51 71.04 11.32 73.22 9.14 72.94 9.42 63.02 19.34 IAN 74.07 62.25 11.82 66.38 7.69 65.31 8.76 65.83 8.24 56.41 17.66 AOA 78.25 69.44 8.81 68.51 9.74 67.14 11.11 68.07 10.18 54.20 24.05 AEN-GloVe 81.33 70.03 11.30 73.09 8.24 70.25 11.08 72.55 8.78 55.97 25.36 LSTM+SynATT 85.60 76.49 9.11 78.21 7.39 73.21 12.39 74.54 11.06 61.08 24.52 TD-GAT 84.92 72.17 12.75 75.60 9.32 75.09 9.83 74.60 10.32 62.04 22.88 ASGCN 83.64 76.05 7.59 79.03 4.61 74.32 9.32 76.59 7.05 64.29 19.35 CNN 75.91 63.21 12.70 64.24 11.67 65.39 10.52 65.02 10.89 59.31 16.60 pos-ACNN-CNN 86.49 72.71 13.78 77.30 9.19 79.02 7.47 72.74 13.75 68.03 18.46
下载: 导出CSV
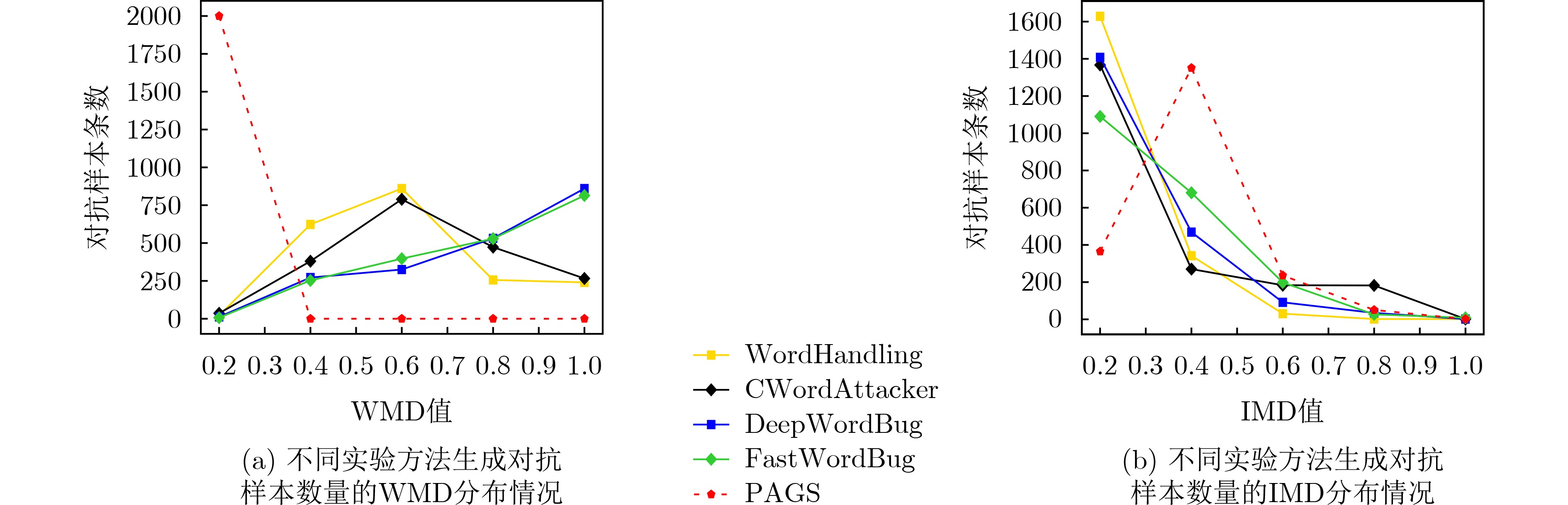
表 5 不同实验方法生成对抗样本数量的WMD和IMD分布情况(条)
项目 值 对比方法 本文方法 WordHandling CWordAttacker DeepWordBug FastWordBug PGAS WMD 0-0.2 21 36 12 7 2000 0.2-0.4 623 380 272 253 0 0.4-0.6 860 789 325 397 0 0.6-0.8 256 473 531 529 0 0.8-1 240 266 860 814 0 IMD 0-0.2 1630 1368 1409 1091 364 0.2-0.4 341 269 468 680 1352 0.4-0.6 29 182 90 197 235 0.6-0.8 0 181 33 25 49 0.8-1 0 0 0 7 0
下载: 导出CSV
-
[1] PAPERNOT N, MCDANIEL P, SWAMI A, et al. Crafting adversarial input sequences for recurrent neural networks[C]. MILCOM 2016 - 2016 IEEE Military Communications Conference, Baltimore, USA, 2016: 49–54. [2] WANG Boxin, PEI Hengzhi, PAN Boyuan, et al. T3: Tree-autoencoder constrained adversarial text generation for targeted attack[C/OL]. The 2020 Conference on Empirical Methods in Natural Language Processing, 2020: 6134–6150. [3] LE T, WANG Suhang, and LEE D. MALCOM: Generating malicious comments to attack neural fake news detection models[C]. 2020 IEEE International Conference on Data Mining, Sorrento, Italy, 2020: 282–291. [4] MOZES M, STENETORP P, KLEINBERG B, et al. Frequency-guided word substitutions for detecting textual adversarial examples[C/OL]. The 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021: 171–186. [5] TAN S, JOTY S, VARSHNEY L, et al. Mind your Inflections! Improving NLP for non-standard Englishes with Base-Inflection encoding[C/OL]. The 2020 Conference on Empirical Methods in Natural Language Processing, 2020: 5647–5663. [6] 潘文雯, 王新宇, 宋明黎, 等. 对抗样本生成技术综述[J]. 软件学报, 2020, 31(1): 67–81. doi: 10.13328/j.cnki.jos.005884PAN Wenwen, WANG Xinyu, SONG Mingli, et al. Survey on generating adversarial examples[J]. Journal of Software, 2020, 31(1): 67–81. doi: 10.13328/j.cnki.jos.005884 [7] MILLER D, NICHOLSON L, DAYOUB F, et al. Dropout sampling for robust object detection in open-set conditions[C]. 2018 IEEE International Conference on Robotics and Automation, Brisbane, Australia, 2018: 3243–3249. [8] 王文琦, 汪润, 王丽娜, 等. 面向中文文本倾向性分类的对抗样本生成方法[J]. 软件学报, 2019, 30(8): 2415–2427. doi: 10.13328/j.cnki.jos.005765WANG Wenqi, WANG Run, WANG Li’na, et al. Adversarial examples generation approach for tendency classification on Chinese texts[J]. Journal of Software, 2019, 30(8): 2415–2427. doi: 10.13328/j.cnki.jos.005765 [9] 仝鑫, 王罗娜, 王润正, 等. 面向中文文本分类的词级对抗样本生成方法[J]. 信息网络安全, 2020, 20(9): 12–16. doi: 10.3969/j.issn.1671-1122.2020.09.003TONG Xin, WANG Luona, WANG Runzheng, et al. A generation method of word-level adversarial samples for Chinese text classiifcation[J]. Netinfo Security, 2020, 20(9): 12–16. doi: 10.3969/j.issn.1671-1122.2020.09.003 [10] BLOHM M, JAGFELD G, SOOD E, et al. Comparing attention-based convolutional and recurrent neural networks: Success and limitations in machine reading comprehension[C]. The 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 2018: 108–118. [11] NIU Tong and BANSAL M. Adversarial over-sensitivity and over-stability strategies for dialogue models[C]. The 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 2018: 486–496. [12] EBRAHIMI J, LOWD D, and DOU Dejing. On adversarial examples for character-level neural machine translation[C]. The 27th International Conference on Computational Linguistics, Santa Fe, USA, 2018: 653–663. [13] GAO Ji, LANCHANTIN J, SOFFA M L, et al. Black-box generation of adversarial text sequences to evade deep learning classifiers[C]. 2018 IEEE Security and Privacy Workshops, San Francisco, USA, 2018: 50–56. [14] GOODMAN D, LV Zhonghou, and WANG Minghua. FastWordBug: A fast method to generate adversarial text against NLP applications[J]. arXiv preprint arXiv: 2002.00760, 2020. [15] EBRAHIMI J, RAO Anyi, LOWD D, et al. HotFlip: White-box adversarial examples for text classification[C]. The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 31–36. [16] SONG Liwei, YU Xinwei, PENG H T, et al. Universal adversarial attacks with natural triggers for text classification[C/OL]. The 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021: 3724–3733. [17] LI Dianqi, ZHANG Yizhe, PENG Hao, et al. Contextualized perturbation for textual adversarial attack[C/OL]. The 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021: 5053–5069. [18] TAN S, JOTY S, KAN M Y, et al. It's Morphin' time! Combating linguistic discrimination with inflectional perturbations[C/OL]. The 58th Annual Meeting of the Association for Computational Linguistics, 2020: 2920–2935. [19] LI Linyang, MA Ruotian, GUO Qipeng, et al. BERT-ATTACK: Adversarial attack against BERT using BERT[C/OL]. The 2020 Conference on Empirical Methods in Natural Language Processing, 2020: 6193–6202. [20] ZANG Yuan, QI Fanchao, YANG Chenghao, et al. Word-level textual adversarial attacking as combinatorial optimization[C/OL]. The 58th Annual Meeting of the Association for Computational Linguistics, 2020: 6066–6080. [21] CHENG Minhao, YI Jinfeng, CHEN Pinyu, et al. Seq2Sick: Evaluating the robustness of sequence-to-sequence models with adversarial examples[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 3601–3608. [22] JIA R and LIANG P. Adversarial examples for evaluating reading comprehension systems[C]. The 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 2017: 2021–2031. [23] MINERVINI P and RIEDEL S. Adversarially regularising neural NLI models to integrate logical background knowledge[C]. The 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 2018: 65–74. [24] WANG Yicheng and BANSAL M. Robust machine comprehension models via adversarial training[C]. The 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, USA, 2018: 575–581. [25] RIBEIRO M T, SINGH S, and GUESTRIN C. Semantically equivalent adversarial rules for debugging NLP models[C]. The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 856–865. [26] IYYER M, WIETING J, GIMPEL K, et al. Adversarial example generation with syntactically controlled paraphrase networks[C]. The 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, USA, 2018: 1875–1885. [27] HAN Wenjuan, ZHANG Liwen, JIANG Yong, et al. Adversarial attack and defense of structured prediction models[C/OL]. The 2020 Conference on Empirical Methods in Natural Language Processing, 2020: 2327–2338. [28] WANG Tianlu, WANG Xuezhi, QIN Yao, et al. CAT-Gen: Improving robustness in NLP models via controlled adversarial text generation[C/OL]. The 2020 Conference on Empirical Methods in Natural Language Processing, 2020: 5141–5146. [29] 魏星, 王小辉, 魏亮, 等. 基于规范科技术语数据库的科技术语多音字研究与读音推荐[J]. 中国科技术语, 2020, 22(6): 25–29. doi: 10.3969/j.issn.1673-8578.2020.06.005WEI Xing, WANG Xiaohui, WEI Liang, et al. Pronunciation recommendations on polyphonic characters in terms based on the database of standardized terms[J]. China Terminology, 2020, 22(6): 25–29. doi: 10.3969/j.issn.1673-8578.2020.06.005 [30] KIRITCHENKO S, ZHU Xiaodan, CHERRY C, et al. NRC-Canada-2014: Detecting aspects and sentiment in customer reviews[C]. The 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 2014: 437–442. [31] TANG Duyu, QIN Bing, FENG Xiaocheng, et al. Effective LSTMs for target-dependent sentiment classification[C]. COLING 2016, the 26th International Conference on Computational Linguistics, Osaka, Japan, 2016: 3298–3307. [32] TANG Duyu, QIN Bing, and LIU Ting. Aspect level sentiment classification with deep memory network[C]. The 2016 Conference on Empirical Methods in Natural Language Processing, Austin, USA, 2016: 214–224. [33] MA Dehong, LI Sujian, ZHANG Xiaodong, et al. Interactive attention networks for aspect-level sentiment classification[C]. The 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 2017: 4068–4074. [34] HUANG Binxuan, OU Yanglan, and CARLEY K M. Aspect level sentiment classification with attention-over-attention neural networks[C]. The 11th International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, Washington, USA, 2018: 197–206. [35] SONG Youwei, WANG Jiahai, JIANG Tao, et al. Targeted sentiment classification with attentional encoder network[C]. The 28th International Conference on Artificial Neural Networks, Munich, Germany, 2019: 93–103. [36] HE Ruidan, LEE W S, NG H T, et al. Effective attention modeling for aspect-level sentiment classification[C]. The 27th International Conference on Computational Linguistics, Santa Fe, USA, 2018: 1121–1131. [37] HUANG Binxuan and CARLEY K M. Syntax-aware aspect level sentiment classification with graph attention networks[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 2019: 5469–5477. [38] ZHANG Chen, LI Qiuchi, and SONG Dawei. Aspect-based sentiment classification with aspect-specific graph convolutional networks[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 2019: 4568–4578. [39] WANG Yuanchao, LI Mingtao, PAN Zhichen, et al. Pulsar candidate classification with deep convolutional neural networks[J]. Research in Astronomy and Astrophysics, 2019, 19(9): 133. doi: 10.1088/1674-4527/19/9/133 [40] 唐恒亮, 尹棋正, 常亮亮, 等. 基于混合图神经网络的方面级情感分类[J]. 计算机工程与应用, 2023, 59(4): 175–182. doi: 10.3778/j.ssn.1002-8331.2109-0172TANG Hengliang, YIN Qizheng, CHANG Liangliang, et al. Aspect-level sentiment classification based on mixed graph neural network[J]. Computer Engineering and Applications, 2023, 59(4): 175–182. doi: 10.3778/j.ssn.1002-8331.2109-0172 [41] KUSNER M J, SUN Yu, KOLKIN N I, et al. From word embeddings to document distances[C]. The 32nd International Conference on Machine Learning, Lille, France, 2015: 957–966. -

 下载:
下载:




图(5) / 表(5)
计量
- 文章访问数: 1694
- HTML全文浏览量: 1351
- PDF下载量: 178
- 被引次数: 0
