

Deep Image Prior Acceleration Method for Target Offset in Low-dose CT Images Denoising
-
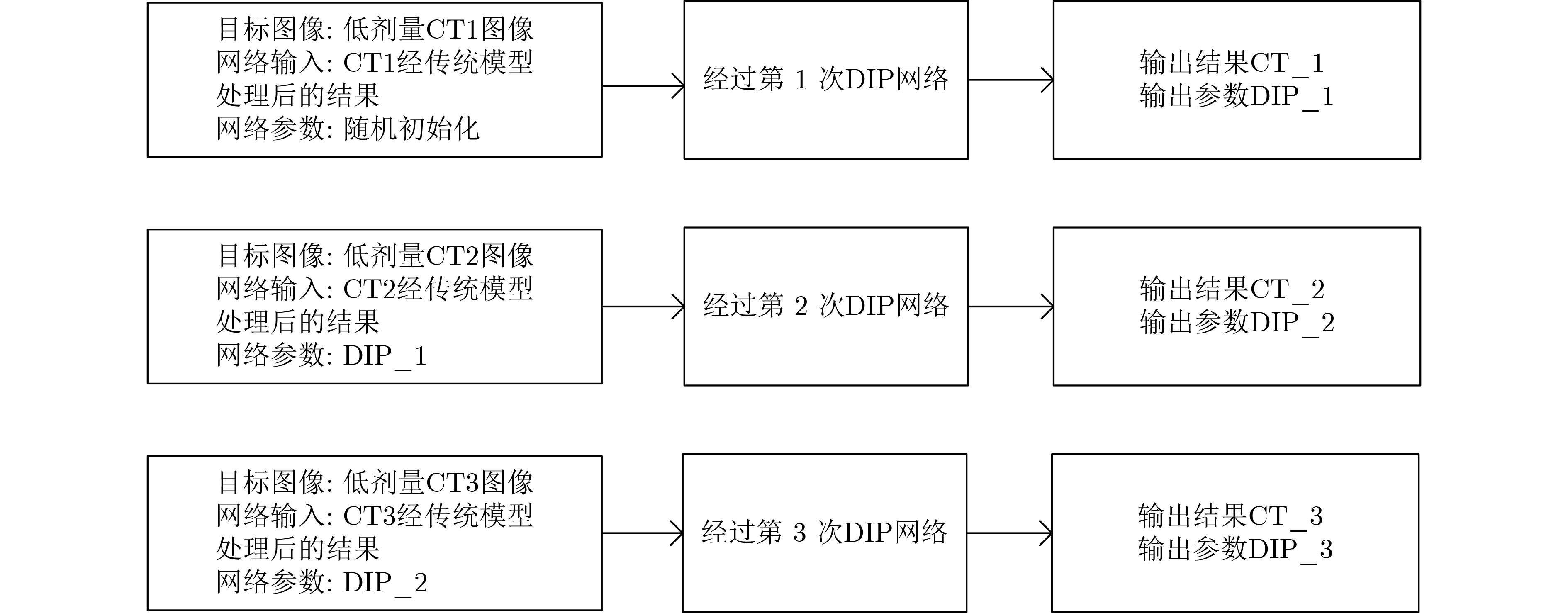
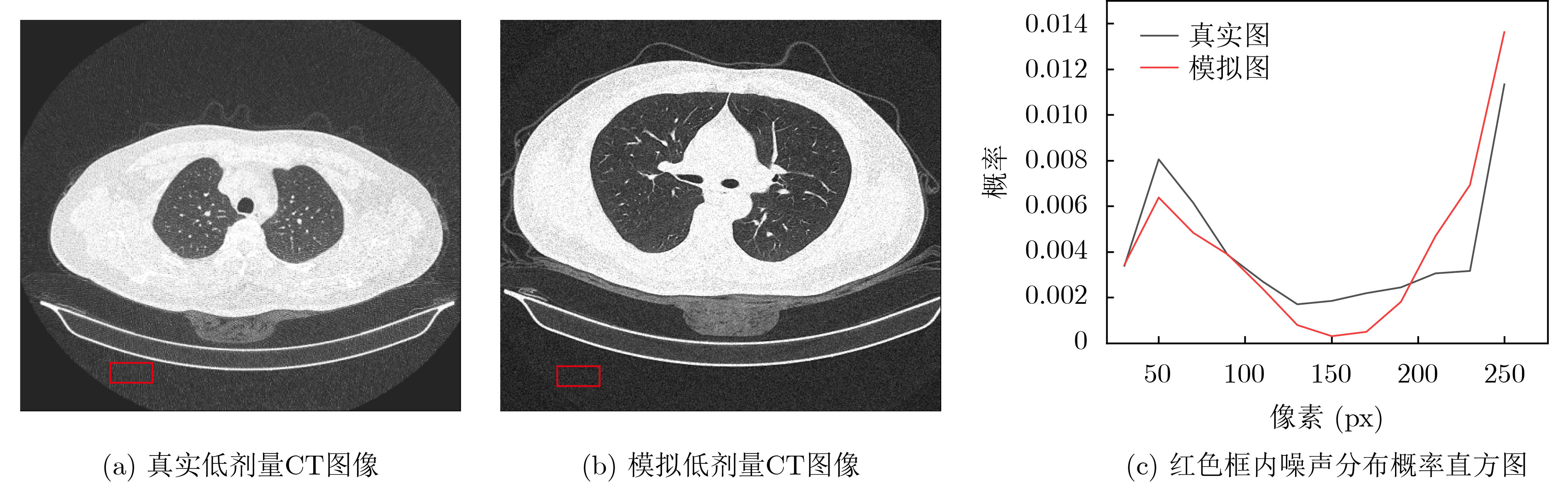
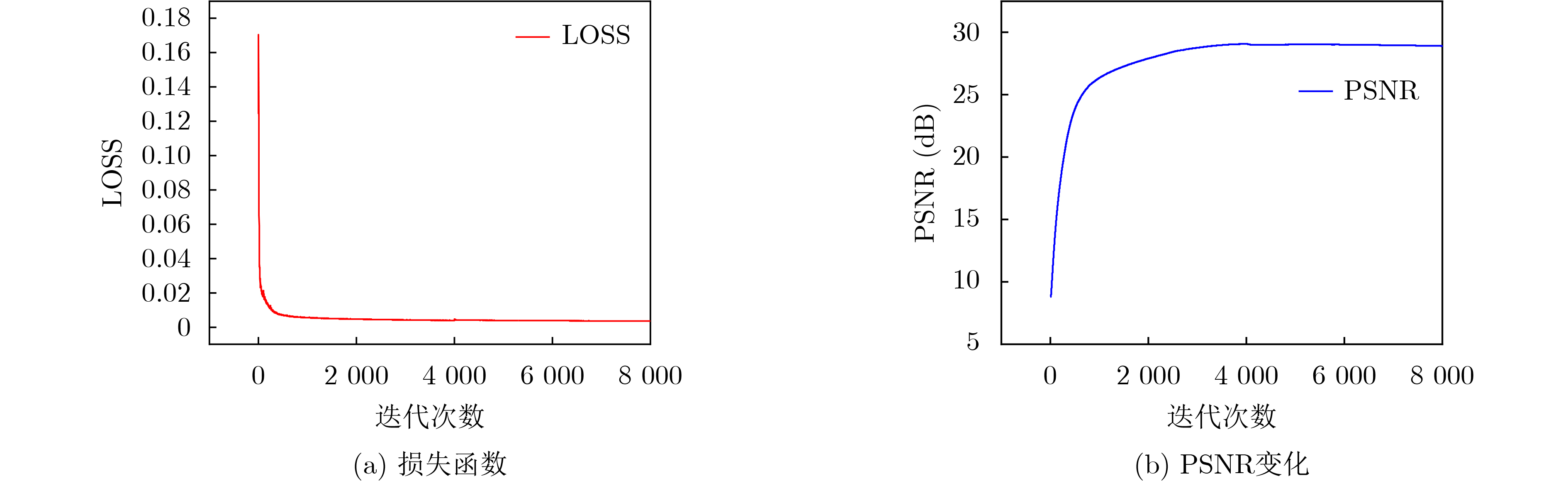
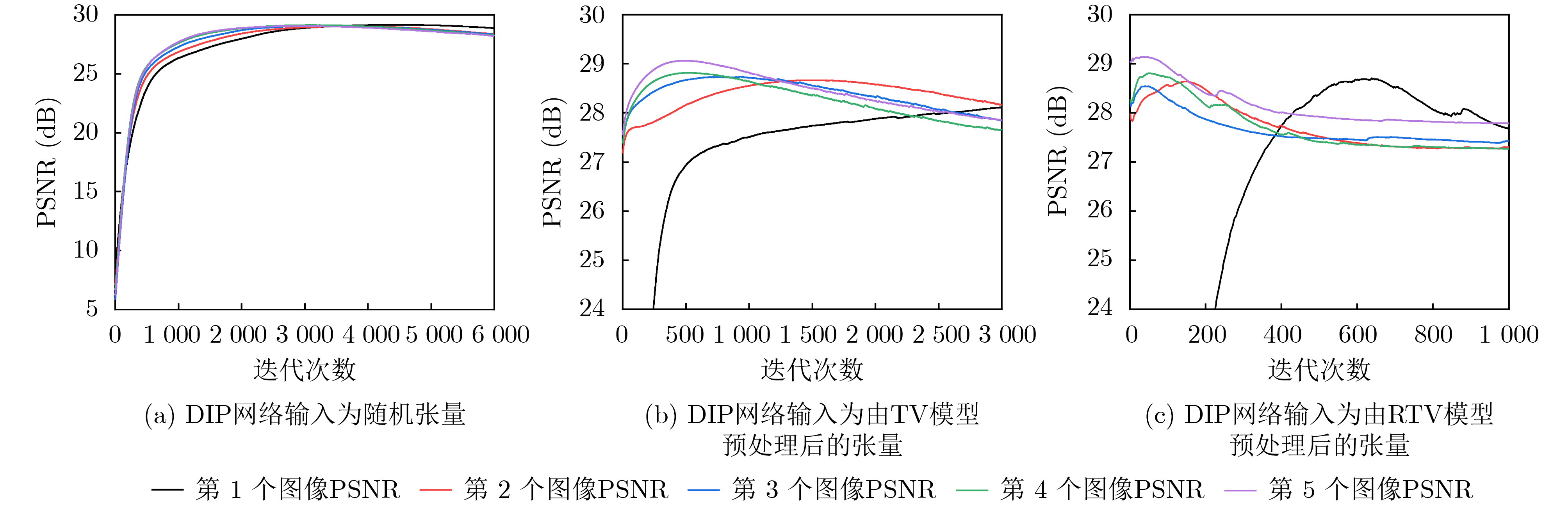
摘要: 低剂量CT(LDCT)图像可大幅降低X射线辐射剂量,但存在大量噪声影响医生诊断。深度图像先验(DIP)是用随机张量作为神经网络的输入图像,以单张LDCT图像为目标进行迭代的无监督深度学习算法。但DIP方法需经过上千次的网络迭代才能得到最佳降噪结果,导致该方法运行速度过慢。因此,该文提出一种用于LDCT降噪的目标偏移DIP加速算法,旨在保持降噪图像质量的基础上提高运行速度。根据一个器官(如肺部)LDCT切片序列图像的相似性,该算法将以各切片分别作为目标图像对应的相互独立的网络迭代通过继承参数关联起来,在上一切片对应的网络参数的基础上更新当前切片对应的网络参数,并将当前切片对应的网络参数作为下一切片对应的网络迭代的基础;由于DIP网络的输入是固定的随机张量,与目标图像差距较大,该文利用传统降噪模型预处理后的LDCT图像作为网络输入,进一步提高网络迭代速度。实验表明,不使用传统模型预处理时,与原DIP网络运行速度相比,该文所提出的加速算法可以将迭代速度提高10.45%;当使用经过相对全变分(RTV)模型预处理的LDCT作为网络输入时,图像峰值信噪比不仅可以达到29.13,而且总迭代速度可以提高94.31%。综上所述,该文算法可在保持DIP降噪效果的基础上,大幅度提高运行速度,特别是RTV模型预处理后的CT图像作为网络输入时,对提高运行速度的效果更加明显。Abstract: Low Dose CT (LDCT) images can significantly reduce the X-ray radiation dose, but there is a lot of noise that affects doctors' diagnosis. Deep Image Prior (DIP) is an unsupervised deep learning algorithm that uses random tensor as the input of neural network and iterates with a single LDCT image as the target. However, DIP needs thousands of iterations to get the best denoised results, resulting in the slow running speed of this method. Therefore, a DIP acceleration method for target offset in low-dose CT images is proposed, which aims to improve the running speed while maintaining the quality of denoised image. According to the similarity of LDCT slice images of an organ (such as lungs), the algorithm associates independent networks whose target images are different slices by inheriting parameters, updates the network parameters corresponding to the current slice based on the network parameters corresponding to the previous slice, and takes the network parameters corresponding to the current slice as the basis of next network corresponding to next slice to update parameters; Since the input of DIP network is a fixed random tensor, which is different from the target image greatly, this paper uses the LDCT image preprocessed by the traditional models as the network input to improve further the network iteration speed. Experiments show that the proposed acceleration algorithm can improve the iteration speed by 10.45% compared with the original DIP network without traditional model preprocessing. When LDCT preprocessed by Relative Total Variation (RTV) model is used as the network input, the image peak signal-to-noise ratio can not only reach 29.13, but also the total iterative speed can be increased by 94.31%. Therefore, this algorithm can greatly improve the running speed while maintaining the denoised quality of DIP, especially when the CT image preprocessed by RTV model is used as the network input, the effect of improving the running speed is more obvious.
-
Key words:
- Image denoising /
- Low Dose CT (LDCT) /
- Deep learning /
- Deep Image Prior (DIP) /
- Acceleration method
-
表 1 DIP网络改变输入前后质量对比
网络输入 DIP处理前PSNR (dB) DIP处理后PSNR (dB) 迭代时间(s) 此刻SSIM 固定的随机张量 29.16 1132.43 0.87 经TV模型作为预处理所得张量 27.01 28.77 1092.46 0.87 经RTV模型作为预处理所得张量 28.30 28.60 196.08 0.88  下载: 导出CSV
下载: 导出CSV
表 2 5个不同的图像经本加速算法处理结果
目标图像 固定的随机张量作为
DIP网络输入TV模型处理后的张量作为DIP网络输入 RTV模型处理后的张量作为DIP网络输入 PSNR最大值(dB) 迭代时间(s) SSIM PSNR最大值(dB) 迭代时间(s) SSIM PSNR最大值(dB) 迭代时间(s) SSIM 1 29.16 1132.43 0.87 28.77 1092.46 0.87 28.60 196.08 0.88 2 29.04 969.01 0.87 28.65 767.31 0.86 28.59 26.62 0.88 3 29.07 847.19 0.88 28.74 226.01 0.87 28.68 33.25 0.88 4 29.14 778.07 0.88 28.82 128.02 0.87 28.43 16.22 0.88 5 29.05 726.38 0.88 29.18 122.54 0.87 29.13 17.24 0.88
下载: 导出CSV
-
[1] BAI Ti, WANG Biling, NGUYEN D, et al. Deep interactive denoiser (DID) for X-ray computed tomography[J]. IEEE Transactions on Medical Imaging, 2021, 40(11): 2965–2975. doi: 10.1109/TMI.2021.3101241 [2] RUDIN L I, OSHER S, and FATEMI E. Nonlinear total variation based noise removal algorithms[J]. Physica D:Nonlinear Phenomena, 1992, 60(1/4): 259–268. doi: 10.1016/0167-2789(92)90242-F [3] 王大凯, 侯榆青, 彭进业. 图像处理的偏微分方程方法[M]. 北京: 科学出版社, 2008: 146–147.WANG Dakai, HOU Yuqing, and PENG Jinye. Partial Differential Equation Method for Image Processing[M]. Beijing: Science Press, 2008: 146–147. [4] XU Li, YAN Qiong, XIA Yang, et al. Structure extraction from texture via relative total variation[J]. ACM Transactions on Graphics, 2012, 31(6): 139. doi: 10.1145/2366145.2366158 [5] ZHANG Kai, ZUO Wangmeng, CHEN Yunjin, et al. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising[J]. IEEE Transactions on Image Processing, 2017, 26(7): 3142–3155. doi: 10.1109/TIP.2017.2662206 [6] MORAN N, SCHMIDT D, ZHONG Yu, et al. Noisier2Noise: Learning to denoise from unpaired noisy data[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 12061–12069. [7] YIE S Y, KANG S K, HWANG D, et al. Self-supervised PET denoising[J]. Nuclear Medicine and Molecular Imaging, 2020, 54(6): 299–304. doi: 10.1007/s13139-020-00667-2 [8] LEMPITSKY V, VEDALDI A, and ULYANOV D. Deep image prior[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 9446–9454. [9] PAN Xingang, ZHAN Xiaohang, DAI Bo, et al. Exploiting deep generative prior for versatile image restoration and manipulation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(11): 7474–7489. doi: 10.1109/TPAMI.2021.3115428 [10] DITTMER S, KLUTH T, MAASS P, et al. Regularization by Architecture: A deep prior approach for inverse problems[J]. Journal of Mathematical Imaging and Vision, 2020, 62(3): 456–470. doi: 10.1007/s10851-019-00923-x [11] CHENG Zezhou, GADELHA M, MAJI S, et al. A Bayesian perspective on the deep image prior[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5438–5446. [12] CUI Jianan, GONG Kuang, GUO Ning, et al. PET image denoising using unsupervised deep learning[J]. European Journal of Nuclear Medicine and Molecular Imaging, 2019, 46(13): 2780–2789. doi: 10.1007/s00259-019-04468-4 [13] HASHIMOTO F, OHBA H, OTE K, et al. Dynamic PET image denoising using deep convolutional neural networks without prior training datasets[J]. IEEE Access, 2019, 7: 96594–96603. doi: 10.1109/ACCESS.2019.2929230 [14] MATAEV G, ELAD M, and MILANFAR P. DeepRED: Deep image prior powered by RED[J]. arXiv: 1903.10176, 2019. [15] ONISHI Y, HASHIMOTO F, OTE K, et al. Anatomical-guided attention enhances unsupervised pet image denoising performance[J]. Medical Image Analysis, 2021, 74: 102226. doi: 10.1016/j.media.2021.102226 [16] DABOV K, FOI A, KATKOVNIK V, et al. Image denoising by sparse 3-D transform-domain collaborative filtering[J]. IEEE Transactions on Image Processing, 2007, 16(8): 2080–2095. doi: 10.1109/TIP.2007.901238 -


 下载:
下载:





图(8) / 表(3)
计量
- 文章访问数: 1009
- HTML全文浏览量: 1024
- PDF下载量: 108
- 被引次数: 0
