

A Dynamic Pre-Deployment Strategy of UAVs Based on Multi-Agent Deep Reinforcement Learning
-
摘要: 针对传统优化算法在求解长时间尺度内通信无人机(UAV)动态部署时复杂度过高且难以与动态环境信息匹配等缺陷,该文提出一种基于多智能体深度强化学习(MADRL)的UAV动态预部署策略。首先利用一种深度时空网络模型预测用户的预期速率需求以捕捉动态环境信息,定义用户满意度的概念以刻画用户所获得UAV提供服务的公平性,并以最大化长期总体用户满意度和最小化UAV移动及发射能耗为目标建立优化模型。其次,将上述模型转化为部分可观测马尔科夫博弈过程(POMG),并提出一种基于MADRL的H-MADDPG算法求解该POMG中轨迹规划、用户关联和功率分配的最佳决策。该H-MADDPG算法使用混合网络结构以实现对多模态输入的特征提取,并采用集中式训练-分布式执行的机制以高效地训练和执行决策。最后仿真结果证明了所提算法的有效性。
-
关键词:
- 无人机通信 /
- 动态部署 /
- 部分可观测马尔科夫博弈 /
- 多智能体深度强化学习
Abstract: It’s challenging to use traditional optimization algorithms to solve the long-term dynamic deployment problem of Unmanned Aerial Vehicles (UAVs) due to their high complexity and difficulty in matching dynamic environment. Aiming at solving these shortcomings, a dynamic pre-deployment strategy of UAV based on Multi-Agent Deep Reinforcement Learning (MADRL) is proposed. Firstly, a deep spatio-temporal network model is used to predict the expected rate demand of users in the coverage area to capture the dynamic environment information. The concept of users’ satisfaction is defined to describe the fairness of users. An optimization problem is modeled with the goal of maximizing the long-term overall users’ satisfaction, minimizing the mobile and radio energy consumption of the UAVs. Secondly, the problem above is transformed into a Partially Observable Markov Game (POMG) process. An H-MADDPG algorithm based on MADRL is proposed to solve the optimal decision of trajectory design, user association and power allocation. The H-MADDPG algorithm uses a hybrid network structure to extract the features of multi-modal inputs, and adopts a centralized training-distributed execution mechanism to realize efficient training and decision execution. Finally, the effectiveness of the algorithm is verified by simulation experiments. -
算法1 H-MADDP算法 输入:$ {{\hat {\boldsymbol X}}^{{\text{Tr}}}}(t) $,$ {{\hat {\boldsymbol X}}^{\text{U}}}(t) $($ t \in {\mathcal{T}} $),最大回合数E,最大时间步长
T,$ \gamma $,$ \tau $,I,最大代数(epoch)K输出:$ {\omega _m} $,$ {\omega '_m} $,$ {\theta _m} $,$ {\theta '_m} $ 1 随机初始化所有智能体的在线/目标评判者网络、在线/目标
执行者网络2 for episode=1~E: 3 初始化全局状态s和所有智能体经验回放池 4 for t=1~T: 5 所有智能体基于观测状态执行动作 6 全局状态由s跳变至$ s' $,所有智能体得到相应奖励,并
将样本存储至经验回放池7 if 经验回放池已满: 8 for m=1~M: 9 for epoch=1~K: 10 循环采样I个样本直至所有样本参与训练 11 每次采样根据式(12)和式(13)更新$ {\omega _m} $,根据
式(14)和式(15)更新$ {\theta _m} $12 end for 13 end for 14 清空经验回放池 15 $ s \leftarrow s' $ 16 根据式(16)、式(17)更新$ {\omega '_m} $和$ {\theta '_m} $ 17 end for 18 end for  下载: 导出CSV
下载: 导出CSV
表 1 仿真参数设置
仿真参数 数值 仿真参数 数值 载波频率fc 5 GHz 环境常量a/b 9.6/0.2 天线增益G 10 dB 权重系数$ \varphi $/$ \lambda $/$ \beta $ 10–1/10–3/10–1 总带宽B 10 MHz 惩罚系数$ {\eta _1} $/$ {\eta _2} $/$ {\eta _3} $ 10–2/10–1/102 噪声功率谱密度N0 –174 dBm/Hz UAV数量M 3 $ {\mu _{{\text{LoS}}}} $/$ {\sigma _{{\text{LoS}}}} $/$ {\mu _{\text{N}}}_{{\text{LoS}}} $/$ {\sigma _{{\text{NLoS}}}} $ 1.6/8.41/23/33.78 Pmax/dmax/dmin 30 W/1000 m/100 m 区域长度L/宽度W 10(×200 m)/10(×200 m) 训练参数E/T/K/I/τ 1000/200/100/5/0.1
下载: 导出CSV
表 2 H-MADDPG与MADDPG网络结构对比
H-MADDPG结构参数 MADDPG结构参数
执行者网络卷积层1 32个3×3卷积核
无池化层1 2×2 平均池化 卷积层2 16个3×3卷积核 池化层2 2×2 平均池化 全连接层1 256个神经元 512个神经元 全连接层2 128个神经元 256个神经元 全连接层3 无 50个神经元
评判者网络卷积层1 32个3×3卷积核
无池化层1 2×2 平均池化 卷积层2 16个3×3卷积核 池化层2 2×2 平均池化 全连接层1 512个神经元 1024个神经元 全连接层2 256个神经元 512个神经元 全连接层3 128个神经元 200个神经元 全连接层3 无 20个神经元
下载: 导出CSV
表 3 算法对应权重系数
总体用户满意度
权重系数$ \varphi $UAV单位移动功耗
权重系数$ \beta $H-MADDPG1 1×10–1 1×10–3 H-MADDPG2 0.9×10–1 1.05×10–3 H-MADDPG3 0.7×10–1 1.1×10–3 EED 1×10–1 1×10–3
下载: 导出CSV
-
[1] SAAD W, BENNIS M, and CHEN Mingzhe. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems[J]. IEEE Network, 2020, 34(3): 134–142. doi: 10.1109/MNET.001.1900287 [2] 陈新颖, 盛敏, 李博, 等. 面向6G的无人机通信综述[J]. 电子与信息学报, 2022, 44(3): 781–789. doi: 10.11999/JEIT210789CHEN Xinying, SHENG Min, LI Bo, et al. Survey on unmanned aerial vehicle communications for 6G[J]. Journal of Electronics &Information Technology, 2022, 44(3): 781–789. doi: 10.11999/JEIT210789 [3] WANG Qian, CHEN Zhi, LI Hang, et al. Joint power and trajectory design for physical-layer secrecy in the UAV-aided mobile relaying system[J]. IEEE Access, 2018, 6: 62849–62855. doi: 10.1109/ACCESS.2018.2877210 [4] ZHANG Guangchi, WU Qingqing, CUI Miao, et al. Securing UAV communications via joint trajectory and power control[J]. IEEE Transactions on Wireless Communications, 2019, 18(2): 1376–1389. doi: 10.1109/TWC.2019.2892461 [5] GAO Ying, TANG Hongying, LI Baoqing, et al. Joint trajectory and power design for UAV-enabled secure communications with no-fly zone constraints[J]. IEEE Access, 2019, 7: 44459–44470. doi: 10.1109/ACCESS.2019.2908407 [6] ZHANG Shuhang, ZHANG Hongliang, HE Qichen, et al. Joint trajectory and power optimization for UAV relay networks[J]. IEEE Communications Letters, 2018, 22(1): 161–164. doi: 10.1109/LCOMM.2017.2763135 [7] YANG Gang, DAI Rao, and LIANG Yingchang. Energy-efficient UAV backscatter communication with joint trajectory design and resource optimization[J]. IEEE Transactions on Wireless Communications, 2021, 20(2): 926–941. doi: 10.1109/TWC.2020.3029225 [8] LIU C H, CHEN Zheyu, TANG Jian, et al. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach[J]. IEEE Journal on Selected Areas in Communications, 2018, 36(9): 2059–2070. doi: 10.1109/JSAC.2018.2864373 [9] ZHAO Nan, CHENG Yiqiang, PEI Yiyang, et al. Deep reinforcement learning for trajectory design and power allocation in UAV networks[C]. 2020 IEEE International Conference on Communications, Dublin, Ireland, 2020: 1–6. [10] WANG Liang, WANG Kezhi, PAN Cunhua, et al. Deep reinforcement learning based dynamic trajectory control for UAV-assisted mobile edge computing[J]. IEEE Transactions on Mobile Computing, 2022, 21(10): 3536–3550. [11] CHEN Xiaming, JIN Yaohui, QIANG Siwei, et al. Analyzing and modeling spatio-temporal dependence of cellular traffic at city scale[C]. 2015 IEEE International Conference on Communications, London, the United Kingdom, 2015: 3585–3591. [12] ZHANG Chuanting, ZHANG Haixia, QIAO Jingping, et al. Deep transfer learning for intelligent cellular traffic prediction based on cross-domain big data[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(6): 1389–1401. doi: 10.1109/JSAC.2019.2904363 [13] 唐伦, 蒲昊, 汪智平, 等. 基于注意力机制ConvLSTM的UAV节能预部署策略[J]. 电子与信息学报, 2022, 44(3): 960–968. doi: 10.11999/JEIT211368TANG Lun, PU Hao, WANG Zhiping, et al. Energy-efficient predictive deployment strategy of UAVs based on ConvLSTM with attention mechanism[J]. Journal of Electronic &Information Technology, 2022, 44(3): 960–968. doi: 10.11999/JEIT211368 [14] OSBORNE M J. An Introduction to Game Theory[M]. London: Oxford University Press, 2003: 8–10. [15] SUTTON R S and BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 2018: 324–326. [16] ZHANG Qianqian, SAAD W, BENNIS M, et al. Predictive deployment of UAV base stations in wireless networks: Machine learning meets contract theory[J]. IEEE Transactions on Wireless Communications, 2021, 20(1): 637–652. doi: 10.1109/TWC.2020.3027624 [17] YIN Sixing and YU R F. Resource allocation and trajectory design in UAV-Aided cellular networks based on multiagent reinforcement learning[J]. IEEE Internet of Things Journal, 2022, 9(4): 2933–2943. doi: 10.1109/JIOT.2021.3094651 -

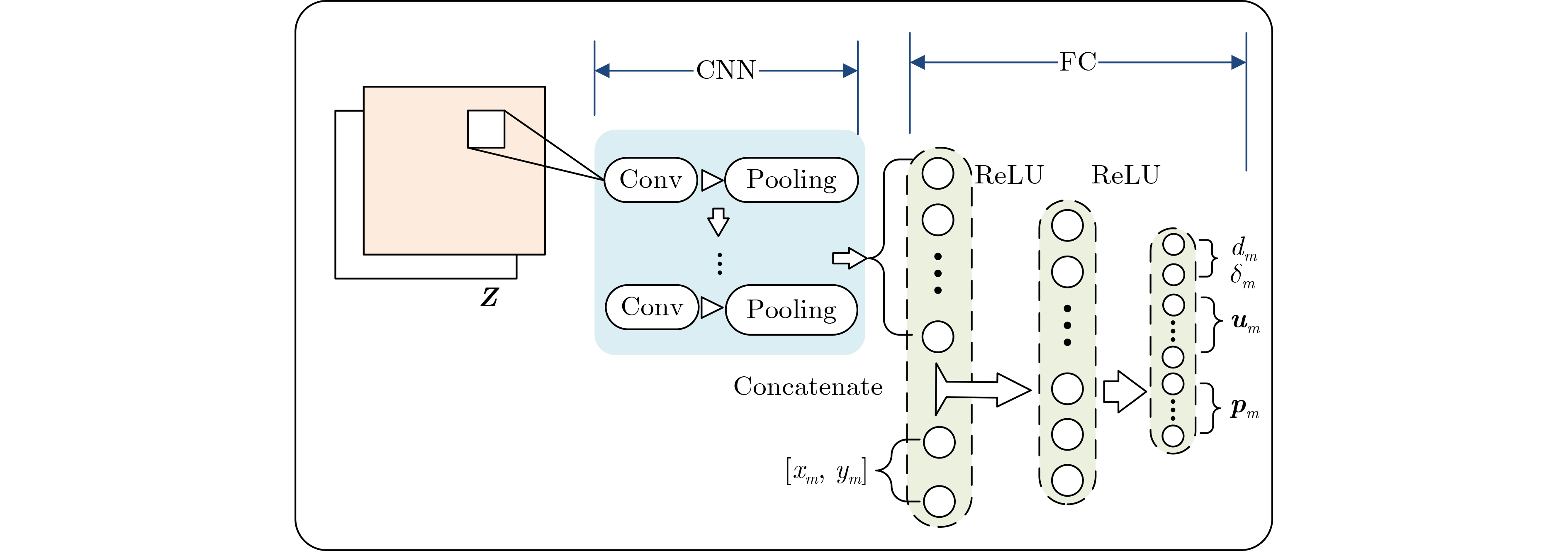
 下载:
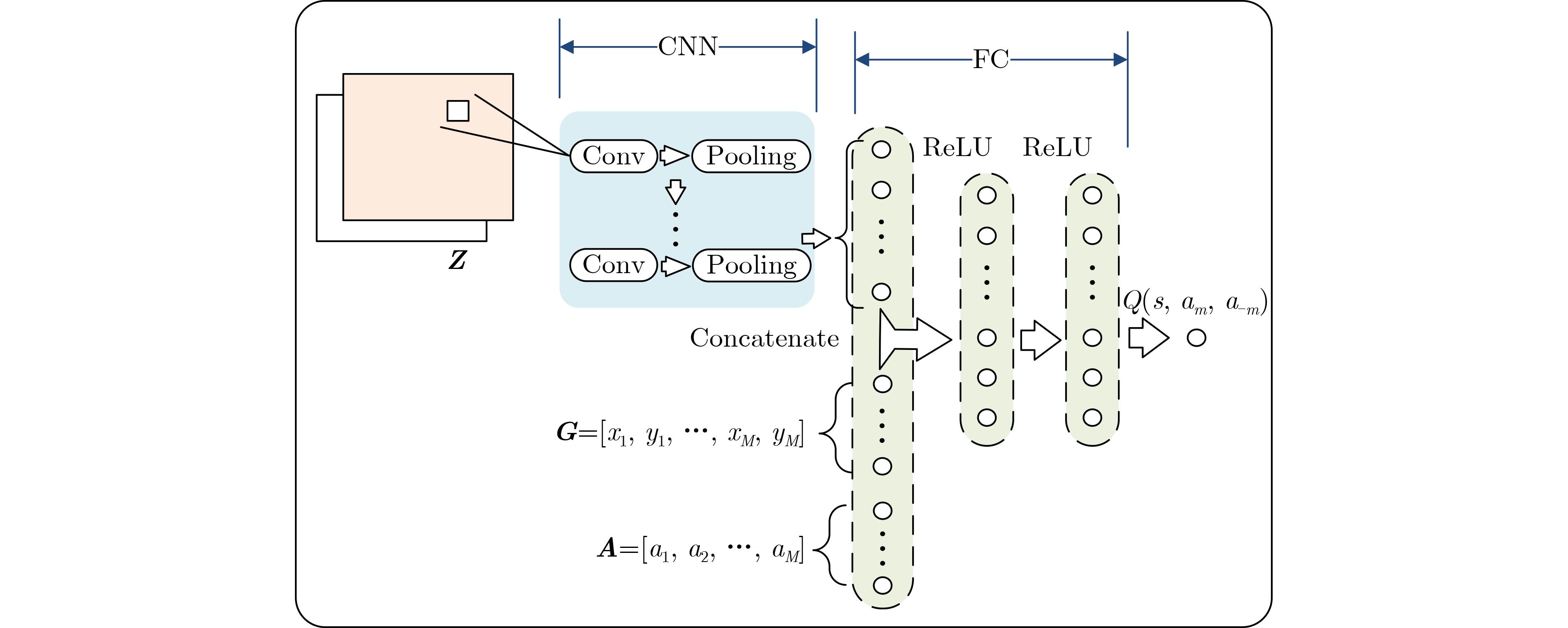
下载:




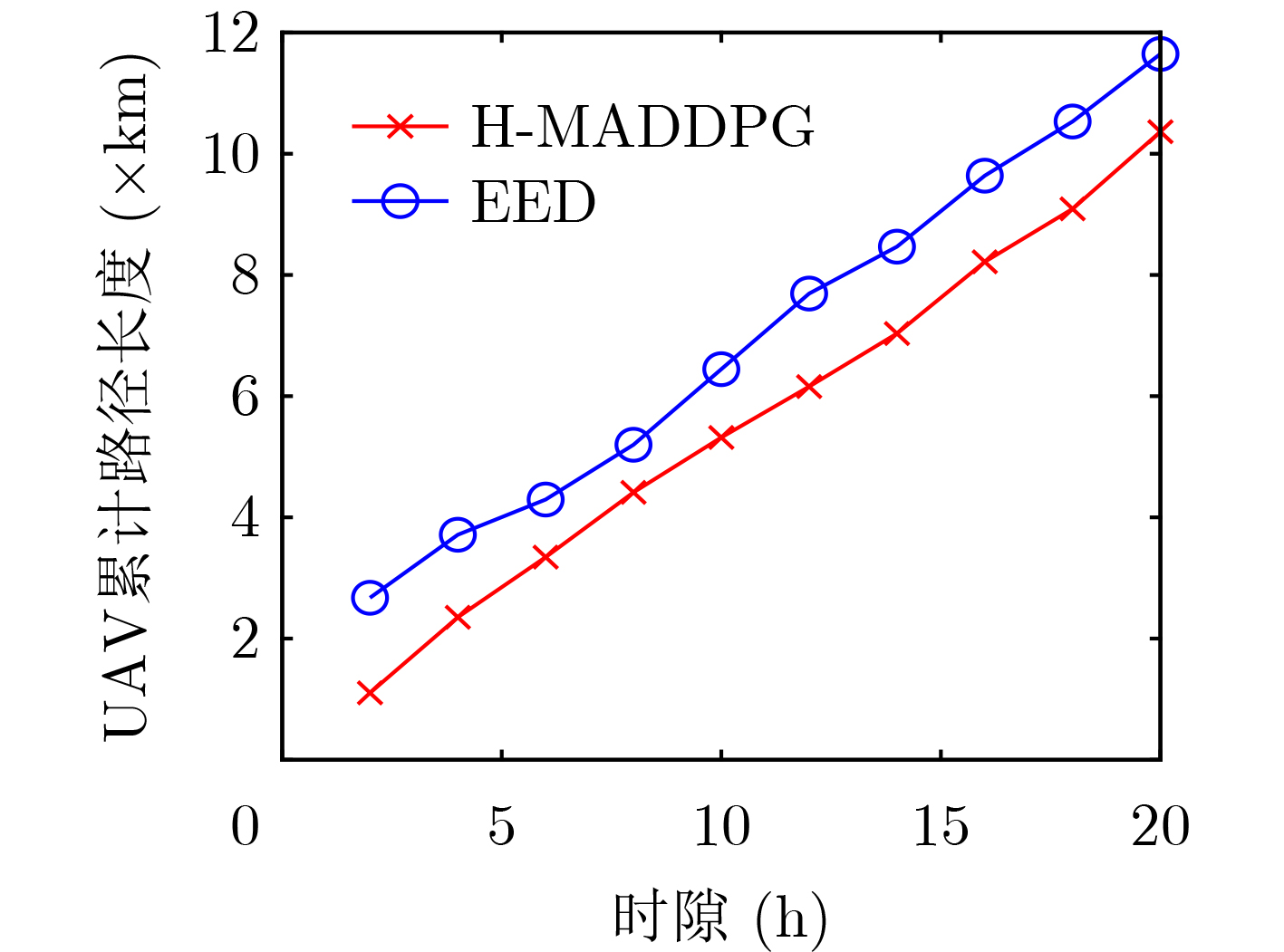


图(7) / 表(4)
计量
- 文章访问数: 1953
- HTML全文浏览量: 584
- PDF下载量: 345
- 被引次数: 0
