

Multi-core Chip Dynamic Power Management Framework Based on Reinforcement Learning
-
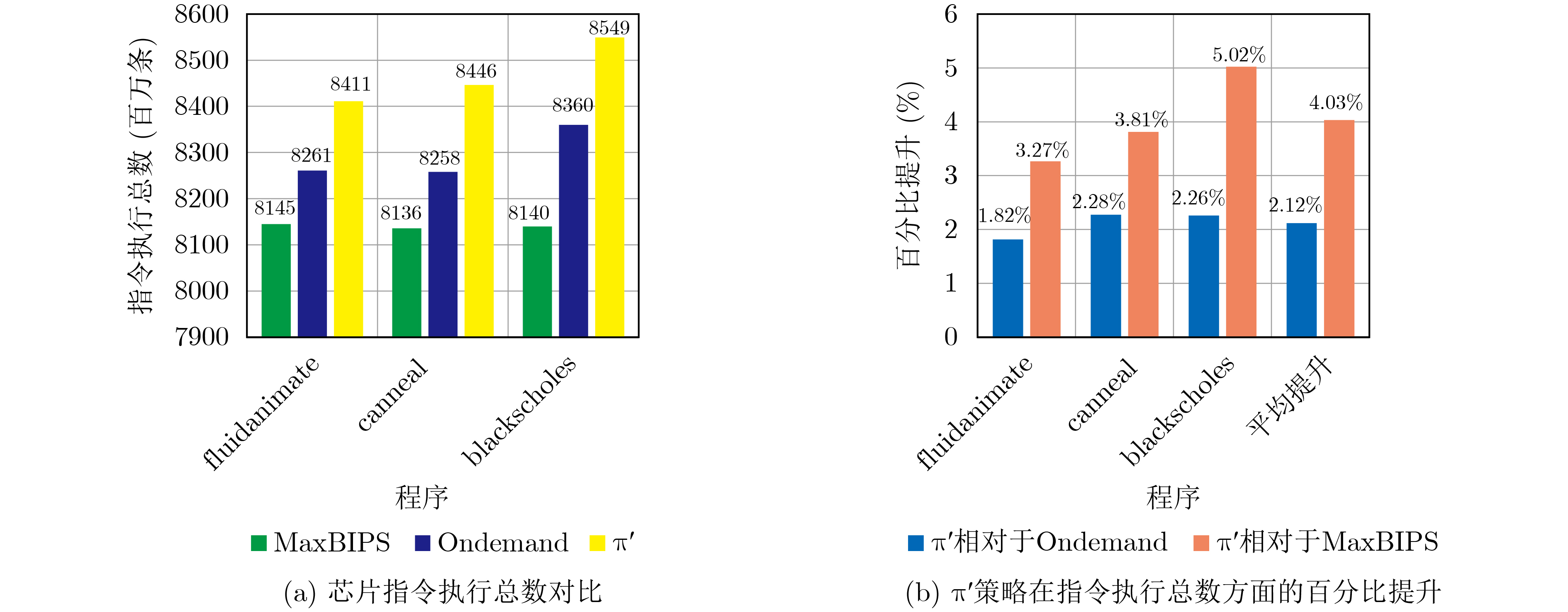
摘要: 多核芯片可以为移动智能终端提供强大算力,但功耗和温度问题始终制约着其性能表现。针对这个问题,该文提出了一种基于强化学习的多核芯片动态功耗管理框架。首先,建立了一个基于GEM5的多核芯片动态电压频率调节仿真系统。然后,采用了一种考虑CMOS芯片物理特性的功耗模型构建方法以实现在线实时功耗监测。最后,设计了一种面向多核芯片的梯度式奖励方法,并使用深度Q神经网络(Deep Q Network, DQN)算法对多核芯片的功耗管理策略进行学习。仿真结果表明,相比于常规的Ondemand,MaxBIPS方案,该文所提出的框架分别实现了2.12%, 4.03%的多核芯片计算性能提升。Abstract: Multi-core chips can provide mighty computing capability for mobile intelligent terminals, but their performance is constraint by thermal and power issues. For this problem, this paper proposes a multi-core chip dynamic power management framework based on reinforcement learning. First, based on GEM5, a dynamic voltage and frequency scaling simulation system of the multi-core chips is established. Second, a chip power model characterization method is adopted, which takes CMOS physical characteristics into consideration to realize online real-time power monitoring. Finally, a gradient reward method for the multi-core chips is designed, and a Deep Q Network (DQN) algorithm is used to learn the power management strategy for the multi-core chips. Compared with conventional Ondemand and MaxBIPS schemes, the simulation results show that the proposed framework achieves 2.12% and 4.03% improvement in computational performance of the multi-core chips respectively.
-
表 1 梯度式奖励
中等性能指令
执行数(百万条)指令数梯度$G$
(百万条)奖励梯度$R$ ${I_{{\rm{bench}}} }$ $ + {g_0}$ ${r_0}$ $+ g_1$ ${r_1}$ $ \vdots$ $\vdots$ $+ g_n$ ${r_n}$  下载: 导出CSV
下载: 导出CSV
表 2 环境奖励梯度
中等性能指令执行数
(百万条)指令数梯度$G$
(百万条)奖励梯度$R$ 8322 –222 +1 –122 +10 –68 +100 –22 +1000 +28 +10000 +78 +100000
下载: 导出CSV
-
[1] PAGANI S, MANOJ P D S, JANTSCH A, et al. Machine learning for power, energy, and thermal management on multi-core processors: A survey[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(1): 101–116. doi: 10.1109/TCAD.2018.2878168 [2] JIANG Honglan, SANTIAGO F J H, MO Hai, et al. Approximate arithmetic circuits: A survey, characterization, and recent applications[J]. Proceedings of the IEEE, 2020, 108(12): 2108–2135. doi: 10.1109/JPROC.2020.3006451 [3] CHEN Chuangtao, QIAN Weikang, IMANI M, et al. PAM: A piecewise-linearly-approximated floating-point multiplier with unbiasedness and configurability[J]. IEEE Transactions on Computers, 2022, 77(10): 2473–2486. [4] 李光辉, 周辉, 胡世红. 面向移动边缘计算中多应用服务的虚拟机部署算法[J]. 电子与信息学报, 2022, 44(7): 2431–2439. doi: 10.11999/JEIT210415LI Guanghui, ZHOU Hui, and HU Shihong. Virtual machine placement algorithm for supporting multiple applications in mobile edge computing[J]. Journal of Electronics &Information Technology, 2022, 44(7): 2431–2439. doi: 10.11999/JEIT210415 [5] XIE Qing, KIM J, WANG Yanzhi, et al. Dynamic thermal management in mobile devices considering the thermal coupling between battery and application processor[C]. Proceedings of 2013 IEEE/ACM International Conference on Computer-aided Design, San Jose, USA, 2013: 242–247. [6] CAI Ermao and MARCULESCU D. TEI-Turbo: Temperature effect inversion-aware turbo boost for finfet-based multi-core systems[C]. Proceedings of 2015 IEEE/ACM International Conference on Computer-Aided Design, Austin, USA, 2015: 500–507. [7] HAJIAMINI S, SHIRAZI B, CRANDALL A, et al. A dynamic programming framework for DVFS-based energy-efficiency in multicore systems[J]. IEEE Transactions on Sustainable Computing, 2020, 5(1): 1–12. doi: 10.1109/TSUSC.2019.2911471 [8] CAO Yuan, SHEN Tianhao, ZHANG Li, et al. An efficient and flexible learning framework for dynamic power and thermal Co-management[C]. Proceedings of 2020 ACM/IEEE Workshop on Machine Learning for CAD, Reykjavik, Iceland, 2020: 117–122. [9] MENG Ke, JOSEPH R, DICK R P, et al. Multi-optimization power management for chip multiprocessors[C]. Proceedings of 2008 Parallel Architectures and Compilation Techniques (PACT), Toronto, Canada, 2008: 177–186. [10] HOWARD J, DIGHE S, VANGAL S R, et al. A 48-Core IA-32 processor in 45 nm CMOS using on-die message-passing and DVFS for performance and power scaling[J]. IEEE Journal of Solid-State Circuits, 2011, 46(1): 173–183. doi: 10.1109/JSSC.2010.2079450 [11] ZHUO Cheng, LUO Shaoheng, GAN Houle, et al. Noise-aware DVFS for efficient transitions on battery-powered IoT devices[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(7): 1498–1510. doi: 10.1109/TCAD.2019.2917844 [12] ISCI C, BUYUKTOSUNOGLU A, CHER C Y, et al. An analysis of efficient multi-core global power management policies: Maximizing performance for a given power budget[C]. Proceedings of the 39th Annual IEEE/ACM International Symposium on Microarchitecture, Orlando, USA, 2006: 347–358. [13] TEODORESCU R and TORRELLAS J. Variation-aware application scheduling and power management for chip multiprocessors[C]. Proceedings of 2008 International Symposium on Computer Architecture, Beijing, China, 2008: 363–374. [14] BHAT G, SINGLA G, UNVER A K, et al. Algorithmic optimization of thermal and power management for heterogeneous mobile platforms[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2018, 26(3): 544–557. doi: 10.1109/TVLSI.2017.2770163 [15] GE Yang and QIU Qinru. Dynamic thermal management for multimedia applications using machine learning[C]. Proceedings of the 48th ACM/EDAC/IEEE Design Automation Conference, San Diego, USA, 2011: 95–100. [16] HUANG Hui, LIN Man, YANG L T, et al. Autonomous power management with double-Q reinforcement learning method[J]. IEEE Transactions on Industrial Informatics, 2020, 16(3): 1938–1946. doi: 10.1109/TII.2019.2953932 [17] BINKERT N, BECKMANN B, BLACK G, et al. The gem5 simulator[J]. ACM SIGARCH Computer Architecture News, 2011, 39(2): 1–7. doi: 10.1145/2024716.2024718 [18] LI Sheng, AHN J H, STRONG R D, et al. McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures[C]. Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, New York, USA, 2009: 469–480. [19] HUANG Wei, STAN M R, and SKADRON K. Parameterized physical compact thermal modeling[J]. IEEE Transactions on Components and Packaging Technologies, 2005, 28(4): 615–622. doi: 10.1109/TCAPT.2005.859737 [20] BERTRAN R, GONZALEZ M, MARTORELL X, et al. Decomposable and responsive power models for multicore processors using performance counters[C]. Proceedings of the 24th ACM International Conference on Supercomputing, Tsukuba, Japan, 2010: 147–158. [21] LI Yaguang, ZHUO Cheng, and ZHOU Pingqiang. A cross-layer framework for temporal power and supply noise prediction[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2019, 38(10): 1914–1927. doi: 10.1109/TCAD.2018.2871820 [22] WALKER M J, DIESTELHORST S, HANSSON A, et al. Accurate and stable run-time power modeling for mobile and embedded CPUs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2017, 36(1): 106–119. doi: 10.1109/TCAD.2016.2562920 [23] KIM N S, AUSTIN T, BAAUW D, et al. Leakage current: Moore's law meets static power[J]. Computer, 2003, 36(12): 68–75. doi: 10.1109/MC.2003.1250885 [24] BHAT G, GUMUSSOY S, and OGRAS U Y. Power-temperature stability and safety analysis for multiprocessor systems[J]. ACM Transactions on Embedded Computing Systems, 2017, 16(5s): 145. doi: 10.1145/3126567 [25] KUTNER M H, NACHTSHEIM C J, and NETER J. Applied Linear Regression Models[M]. 4th ed. Chicago: McGraw-Hill/Irwin, 2004: 136–178. [26] SUTTON R S and BARTO A G. Reinforcement Learning: An Introduction[M]. 2nd ed. Bradford: Bradford Book, 2018: 1–13. [27] TAN Bin, PENG Yinyin, and LIN Jiugen. A local path planning method based on Q-learning[C]. Proceedings of 2021 International Conference on Signal Processing and Machine Learning, Stanford, USA, 2021: 80–84. [28] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529–533. doi: 10.1038/nature14236 [29] WATKINS C J C H and DAYAN P. Q-learning[J]. Machine Learning, 1992, 8(3): 279–292. doi: 10.1007/BF00992698 [30] PALLIPADI V and STARIKOVSKIY A. The ondemand governor[C]. Proceedings of 2006 Linux Symposium, Ottawa, Canada, 2006: 215–230. [31] BIENIA C. Benchmarking modern multiprocessors[D]. [Ph. D. dissertation]. Princeton University, 2011. -


 下载:
下载:





图(8) / 表(2)
计量
- 文章访问数: 2365
- HTML全文浏览量: 1505
- PDF下载量: 281
- 被引次数: 0
