

AccFed: Federated Learning Acceleration Based on Model Partitioning in Internet of Things
-
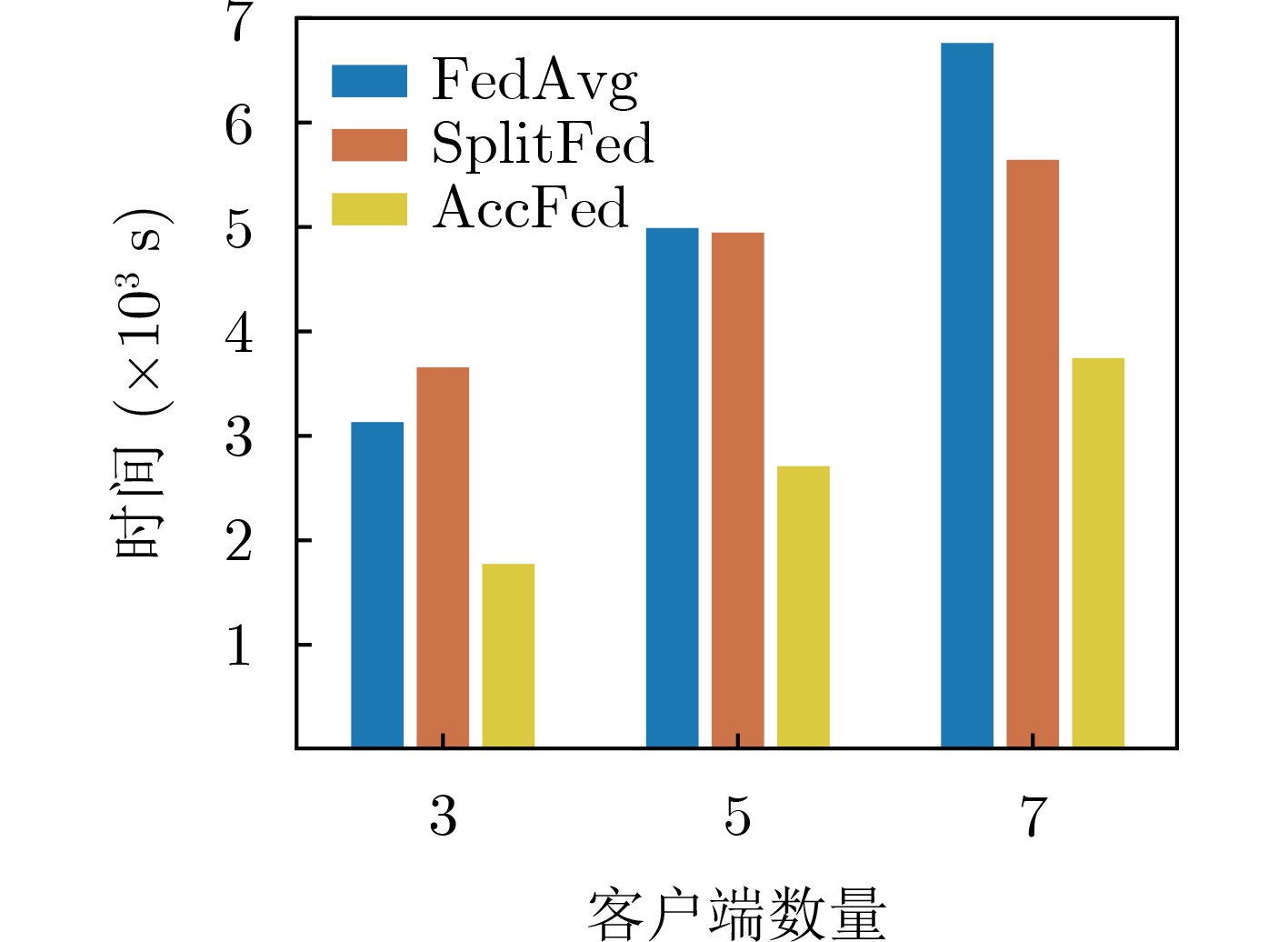
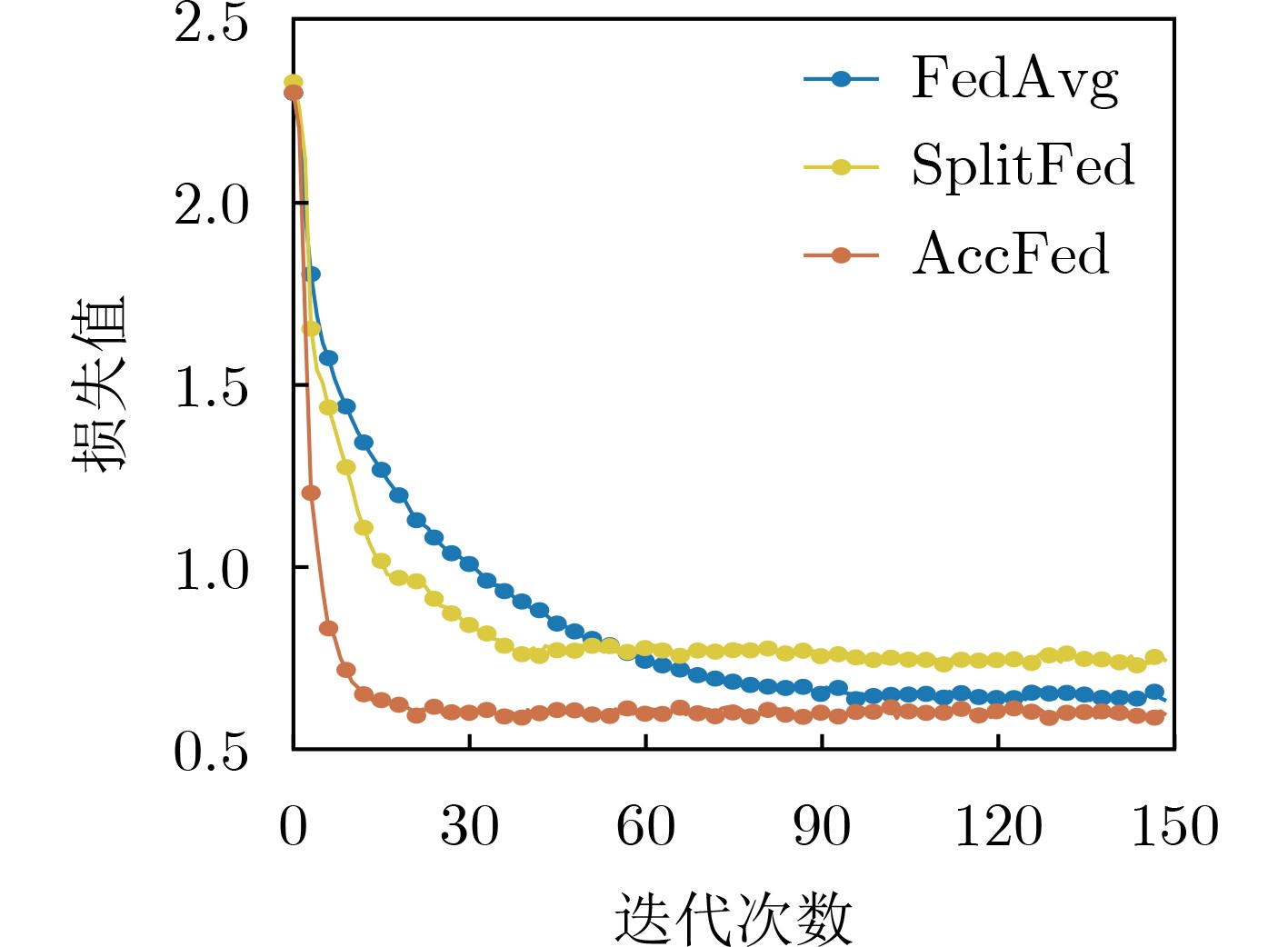
摘要: 随着物联网(IoT)的快速发展,人工智能(AI)与边缘计算(EC)的深度融合形成了边缘智能(Edge AI)。但由于IoT设备计算与通信资源有限,并且这些设备通常具有隐私保护的需求,那么在保护隐私的同时,如何加速Edge AI仍然是一个挑战。联邦学习(FL)作为一种新兴的分布式学习范式,在隐私保护和提升模型性能等方面,具有巨大的潜力,但是通信及本地训练效率低。为了解决上述难题,该文提出一种FL加速框架AccFed。首先,根据网络状态的不同,提出一种基于模型分割的端边云协同训练算法,加速FL本地训练;然后,设计一种多轮迭代再聚合的模型聚合算法,加速FL聚合;最后实验结果表明,AccFed在训练精度、收敛速度、训练时间等方面均优于对照组。Abstract: With the rapid development of Internet of Things (IoT), the deep integration of Artificial Intelligence (AI) and Edge Computing (EC) has formed Edge AI. However, since IoT devices are computationally and communicationally constrained and these devices often require privacy-preserving, it is still a challenge to accelerate Edge AI while protecting privacy. Federated Learning (FL), an emerging distributed learning paradigm, has great potential in terms of privacy preservation and improving model performance, but communication and local training are inefficient. To address the above challenges, a FL acceleration framework AccFed is proposed in this paper. Firstly, a Device-Edge-Cloud synergy training algorithm based on model partitioning is proposed to accelerate FL local training according to the different network states; Then, a multi-iteration and reaggregation algorithm is designed to accelerate FL aggregation; Finally, experimental results show that AccFed outperforms the control group in terms of training accuracy, convergence speed, training time, etc.
-
算法1 DPS算法 输入:用户所需延迟latency,输入数据量${D_{{\text{in}}}}$,分支网络拓扑(包
括${N_{{\text{ex}}}}$,${N_i}$),$f({L_j})$输出:切分点$ p $,最小时延 $ T $ (1) while true do (2) 通过“ping”监视网络状态 (3) if 需要进行计算卸载 then (4) if 网络动态为静态then (5) for $ i={1:N}_{\mathrm{e}\mathrm{x}} $ do (6) 选择第$ i $个退出点 (7) for $ j=1:{N}_{i} $ do (8) $ j=1:{N}_{i} $${\rm{T}}{{\rm{E}}_j} \leftarrow {f_{\text{e} } }\left( { {L_j} } \right)$ (9) ${\rm{T}}{{\rm{D}}_j} \leftarrow {f_{\text{d} } }\left( { {L_j} } \right)$ (10) end for (11) ${T_{i,p}} = \arg {\min _p}\left( {{T_{\text{d}}} + {T_{\text{t}}} + {T_{\text{e}}}} \right)$ (12) if ${T_{i,p} } \le$latency then (13) Return $ i,p,{T}_{i,p} $ (14) end if (15) end for (16) Return NULL (17) else (18) ${T_{\max }} \leftarrow + \infty $ (19) for $\alpha = 0:\dfrac{T}{ {\min \left( { {T_i} } \right)} };\alpha \leftarrow \alpha + \sigma$ do (20) for $\gamma = 0:\dfrac{T}{ {\min \left( { {T_i} } \right)} };\gamma \leftarrow \gamma + \sigma$do (21) 执行4~16行,更新${T_{\max }}$ (22) end for (23) 若发现小于阈值,则缩小搜索空间 (24) end for (25) end if (26) end if (27) end while  下载: 导出CSV
下载: 导出CSV
算法2 Device-Edge-Cloud Synergy FL算法 输入:客户端数量$ N $,参与者数量$ K $,网络带宽$ B $ 输出:全局模型 (1) 从$ N $个客户端中随机选取$ K $个客户端进行FL (2) 根据$ B $,执行DPS()得到$ p $ Procedure Device (3) for each epoch do (4) for each batch $ {b}_{i} $ do (5) ${O}_{p}\leftarrow \text{Output}\left({b}_{i},{W}_{{\rm{d}}}\right)$ (6) 将前$ p $层的输出$ {O}_{p} $与激活函数发送给边 (7) 从边接收$ \nabla L\left({O}_{p}\right) $ (8) ${W}_{{\rm{d}}}\leftarrow {W}_{{\rm{d}}}-\eta \cdot \nabla L\left({O}_{p}\right)\cdot \nabla {{O} }_{{p} }({W}_{{\rm{d}}})$ (9) 将${W}_{{\rm{d}}}$的变化进行参数裁剪 (10) end for (11) 计算${W}_{{\rm{d}}}$平均变化量${\delta }_{ {W}_{{\rm{d}}} }$,如果${\delta }_{ {W}_{{\rm{d}}} }$变小,则增加本
地迭代次数Procedure Edge (12) 从云获取最新全局模型${W}_{{\rm{c}}}$ (13) ${W}_{{\rm{e}}}\leftarrow {W}_{{\rm{c}}}$ (14) while true do (15) 从设备接收$ {O}_{p} $与激活函数 (16) ${W}_{{\rm{e}}}\leftarrow {W}_{{\rm{e}}}-\eta \cdot \nabla L\left({W}_{{\rm{e}}}\right)$ (17) 将$ \nabla L\left({O}_{p}\right) $发给设备 (18) end while Procedure Cloud (19) 初始化${W}_{{\rm{c}}}$ (20) for each round do (21) 将${W}_{{\rm{c}}}$发送给边 (22) 从设备接收${W}_{{\rm{d}}}$ (23) 执行联邦平均算法更新${W}_{{\rm{c}}}$ (24) 对${W}_{{\rm{c}}}$进行裁剪,求取高斯噪声方差$ \sigma $ (25) ${W}_{{\rm{c}}}\leftarrow {W}_{{\rm{c}}}+N(0,{\sigma }^{2})$ (26) end for
下载: 导出CSV
-
[1] AAZAM M, ZEADALLY S, and HARRAS K A. Deploying fog computing in industrial internet of things and industry 4.0[J]. IEEE Transactions on Industrial Informatics, 2018, 14(10): 4674–4682. doi: 10.1109/TII.2018.2855198 [2] UR REHMAN M H, AHMED E, YAQOOB I, et al. Big data analytics in industrial IoT using a concentric computing model[J]. IEEE Communications Magazine, 2018, 56(2): 37–43. doi: 10.1109/MCOM.2018.1700632 [3] SHI Weisong, CAO Jie, ZHANG Quan, et al. Edge computing: vision and challenges[J]. IEEE Internet of Things Journal, 2016, 3(5): 637–646. doi: 10.1109/JIOT.2016.2579198 [4] MOHAMMED T, JOE-WONG C, BABBAR R, et al. Distributed inference acceleration with adaptive DNN partitioning and offloading[C]. Proceedings of 2020 IEEE Conference on Computer Communications, Toronto, Canada, 2020: 854–863. [5] ZHANG Peiying, WANG Chao, JIANG Chunxiao, et al. Deep reinforcement learning assisted federated learning algorithm for data management of IIoT[J]. IEEE Transactions on Industrial Informatics, 2021, 17(12): 8475–8484. doi: 10.1109/TII.2021.3064351 [6] GAO Yansong, KIM M, ABUADBBA S, et al. End-to-end evaluation of federated learning and split learning for internet of things[C]. Proceedings of 2020 International Symposium on Reliable Distributed Systems (SRDS), Shanghai, China, 2020. [7] YU Keping, TAN Liang, ALOQAILY M, et al. Blockchain-enhanced data sharing with traceable and direct revocation in IIoT[J]. IEEE Transactions on Industrial Informatics, 2021, 17(11): 7669–7678. doi: 10.1109/TII.2021.3049141 [8] MCMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, USA, 2017: 1273–1282. [9] GUO Yeting, LIU Fang, CAI Zhiping, et al. FEEL: A federated edge learning system for efficient and privacy-preserving mobile healthcare[C]. Proceedings of the 49th International Conference on Parallel Processing-ICPP. Edmonton, Canada, 2020: 9. [10] CAO Xiaowen, ZHU Guangxu, XU Jie, et al. Optimized power control for over-the-air federated edge learning[C]. ICC 2021-IEEE International Conference on Communications, Montreal, Canada, 2021: 1–6. [11] LO S K, LU Qinghua, WANG Chen, et al. A systematic literature review on federated machine learning: From a software engineering perspective[J]. ACM Computing Surveys, 2022, 54(5): 95. doi: 10.1145/3450288 [12] LI En, ZHOU Zhi, and CHEN Xu. Edge intelligence: On-demand deep learning model co-inference with device-edge synergy[C]. Proceedings of 2018 Workshop on Mobile Edge Communications, Budapest, Hungary, 2018: 31–36. [13] KANG Yiping, HAUSWALD J, GAO Cao, et al. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge[J]. ACM SIGARCH Computer Architecture News, 2017, 45(1): 615–629. doi: 10.1145/3093337.3037698 [14] ESHRATIFAR A E, ABRISHAMI M S, and PEDRAM M. JointDNN: an efficient training and inference engine for intelligent mobile cloud computing services[J]. IEEE Transactions on Mobile Computing, 2021, 20(2): 565–576. doi: 10.1109/TMC.2019.2947893 [15] TANG Xin, CHEN Xu, ZENG Liekang, et al. Joint multiuser DNN partitioning and computational resource allocation for collaborative edge intelligence[J]. IEEE Internet of Things Journal, 2021, 8(12): 9511–9522. doi: 10.1109/JIOT.2020.3010258 [16] LI En, ZENG Liekang, ZHOU Zhi, et al. Edge AI: On-demand accelerating deep neural network inference via edge computing[J]. IEEE Transactions on Wireless Communications, 2020, 19(1): 447–457. doi: 10.1109/TWC.2019.2946140 [17] ELGAMAL T and NAHRSTEDT K. Serdab: An IoT framework for partitioning neural networks computation across multiple enclaves[C]. Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 2020: 519–528. [18] ZHU Guangxu, DU Yuqing, GÜNDÜZ D, et al. One-bit over-the-air aggregation for communication-efficient federated edge learning: Design and convergence analysis[J]. IEEE Transactions on Wireless Communications, 2021, 20(3): 2120–2135. doi: 10.1109/TWC.2020.3039309 [19] DU Yuqing, YANG Sheng, and HUANG Kaibin. High-dimensional stochastic gradient quantization for communication-efficient edge learning[J]. IEEE Transactions on Signal Processing, 2020, 68: 2128–2142. doi: 10.1109/TSP.2020.2983166 [20] THAPA C, CHAMIKARA M A P, CAMTEPE S, et al. Splitfed: When federated learning meets split learning[J]. arXiv: 2004.12088, 2020. [21] VEPAKOMMA P, GUPTA O, SWEDISH T, et al. Split learning for health: Distributed deep learning without sharing raw patient data[J]. arXiv: 1812.00564, 2018. [22] ROMANINI D, HALL A J, PAPADOPOULOS P, et al. PyVertical: A vertical federated learning framework for multi-headed SplitNN[J]. arXiv: 2104.00489, 2021. [23] TEERAPITTAYANON S, MCDANEL B, and KUNG H T. Branchynet: Fast inference via early exiting from deep neural networks[C]. Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 2016: 2464–2469. [24] MCMAHAN H B, ANDREW G, ERLINGSSON U, et al. A general approach to adding differential privacy to iterative training procedures[J]. arXiv: 1812.06210, 2018. [25] MCMAHAN H B, RAMAGE D, TALWAR K, et al. Learning differentially private language models without losing accuracy[J]. arXiv: 1710.06963, 2018. [26] ABADI M, CHU A, GOODFELLOW I, et al. Deep learning with differential privacy[C]. Proceedings of 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 2016: 308–318. -


 下载:
下载:












图(11) / 表(4)
计量
- 文章访问数: 2087
- HTML全文浏览量: 1405
- PDF下载量: 258
- 被引次数: 0
