

Research on Hierarchical Federated Learning Incentive Mechanism Based on Master-Slave Game
-
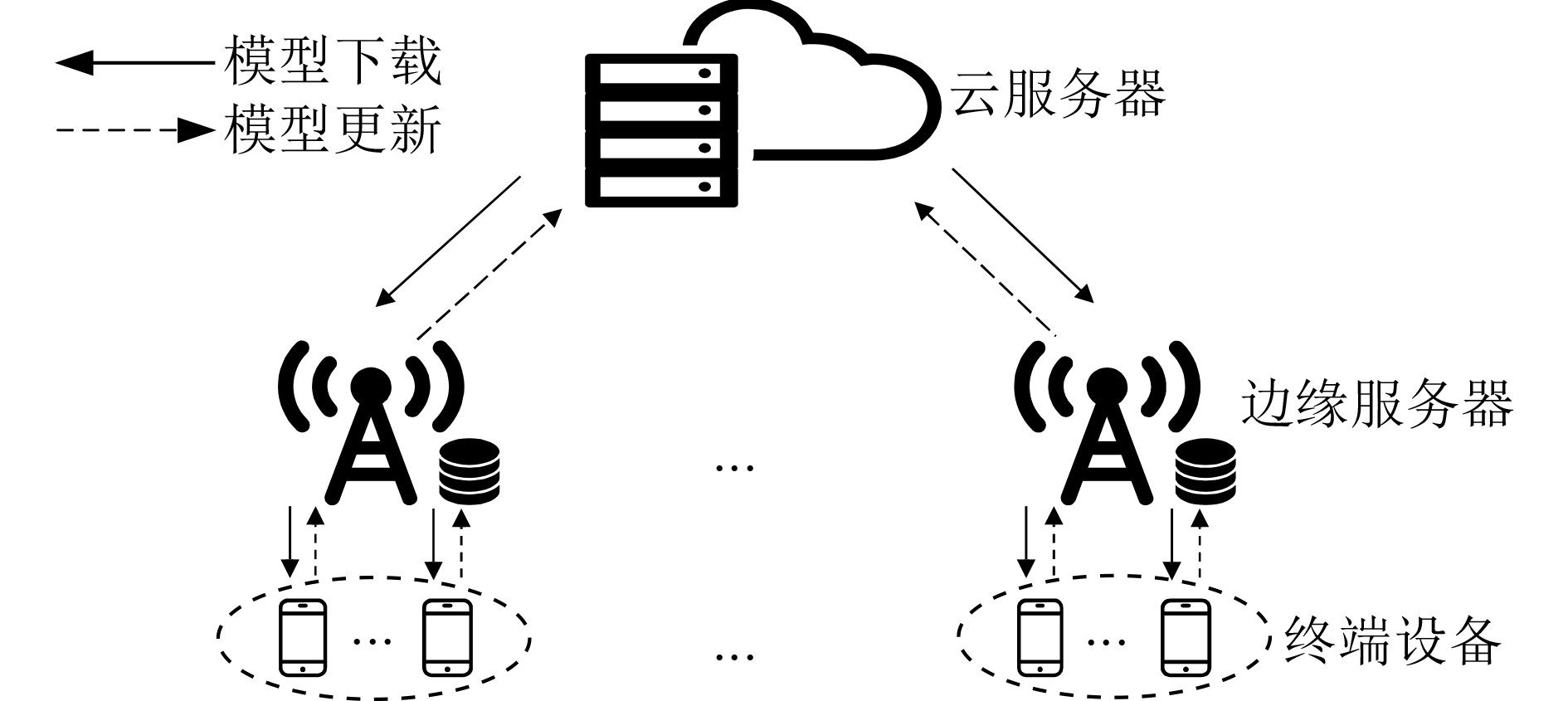
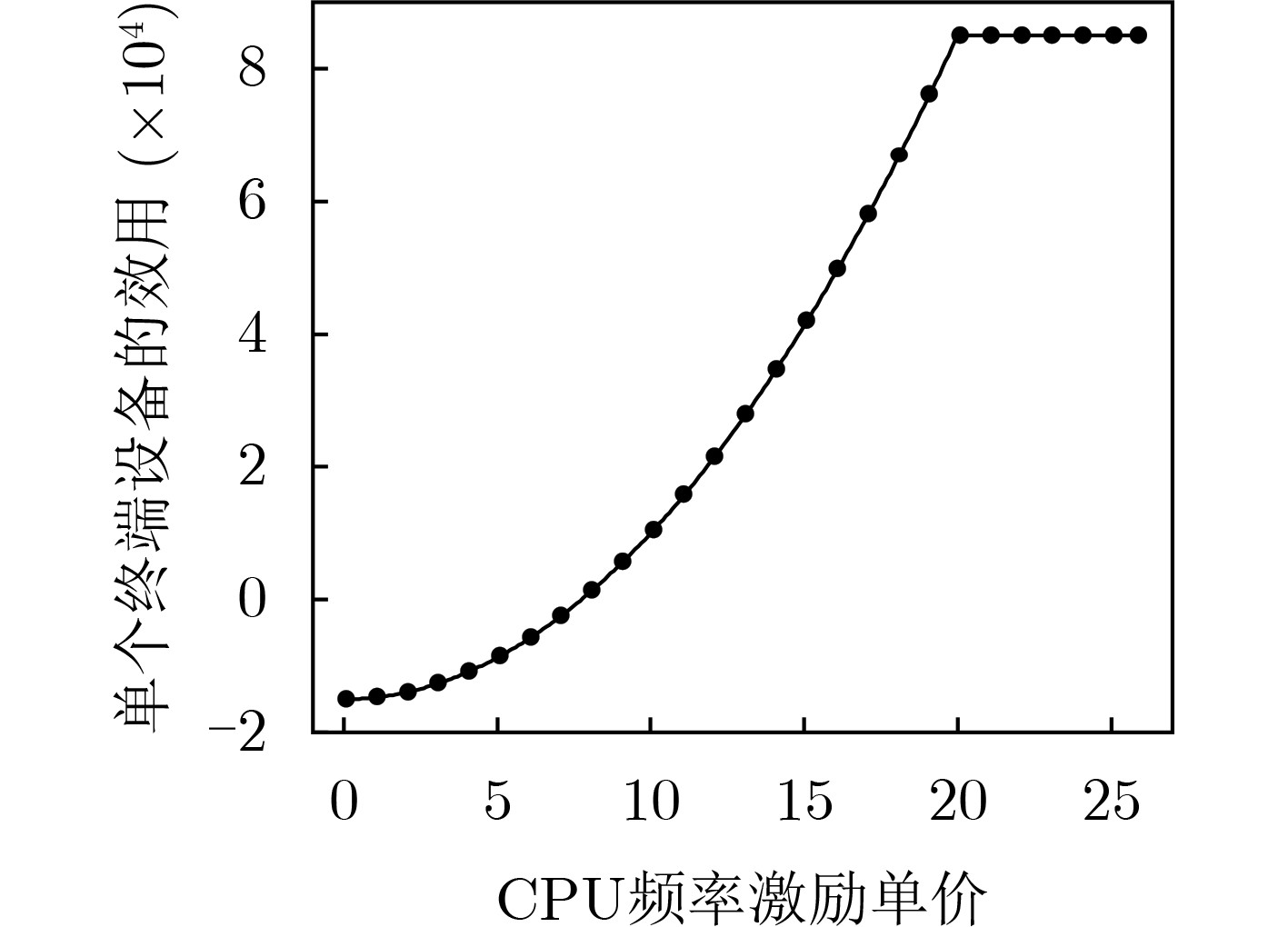
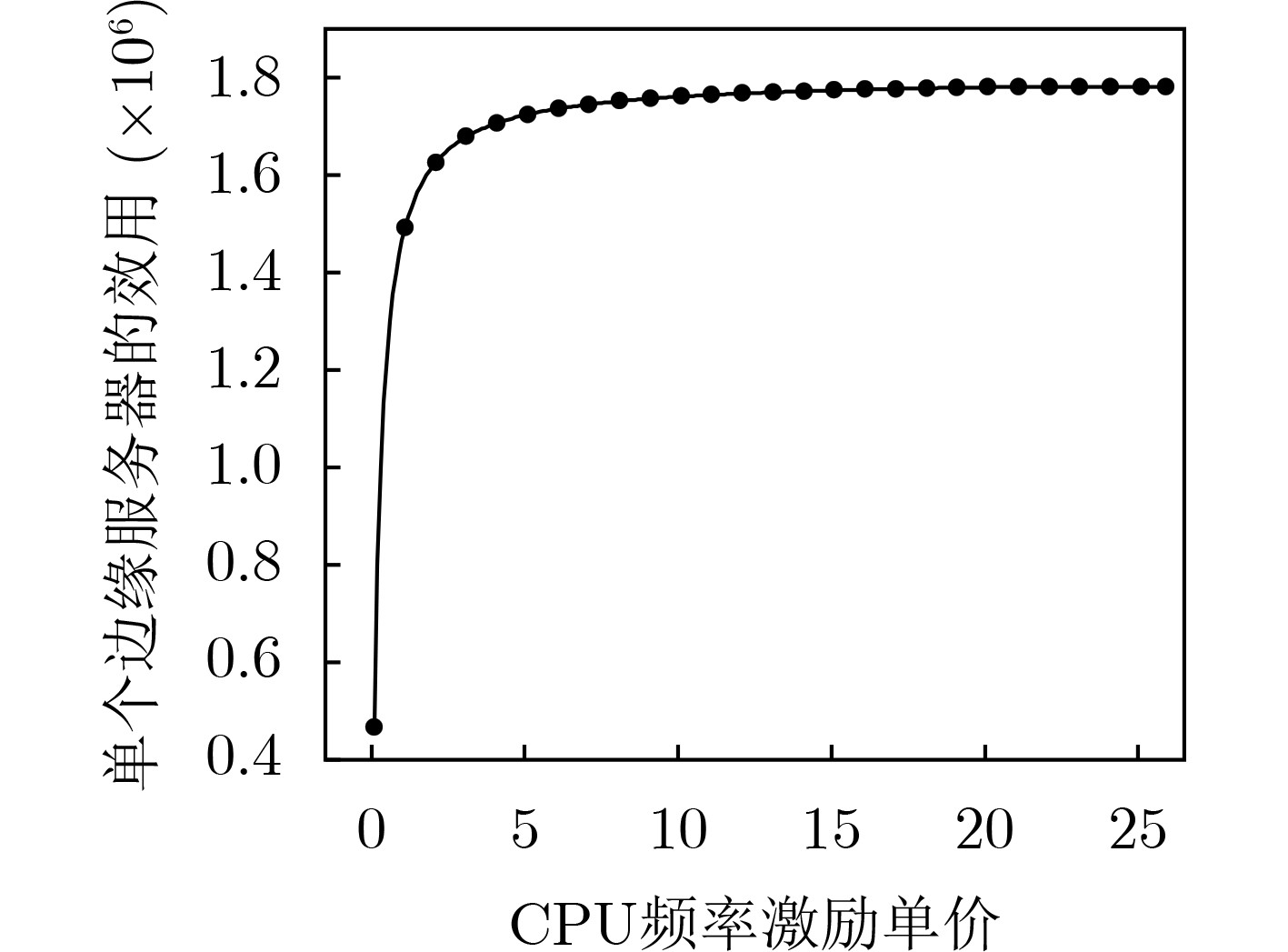
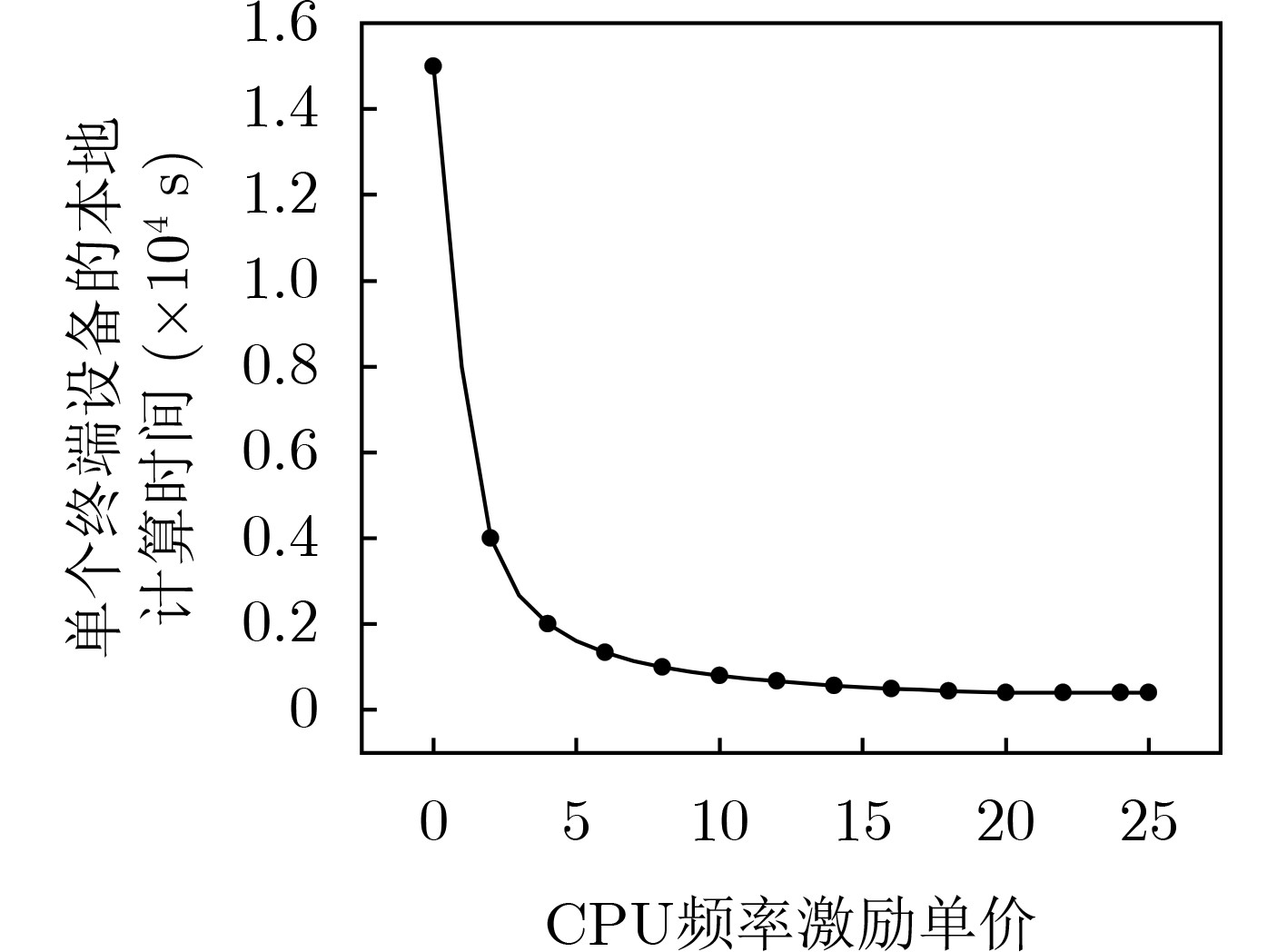
摘要: 为了优化分层联邦学习(FL)全局模型的训练时延,针对实际场景中终端设备存在自私性的问题,该文提出一种基于博弈论的激励机制。在激励预算有限的条件下,得到了终端设备和边缘服务器之间的均衡解和最小的边缘模型训练时延。考虑终端设备数量不同,设计了基于主从博弈的可变激励训练加速算法,使得一次全局模型训练时延达到最小。仿真结果显示,所提出的算法能够有效降低终端设备自私性带来的影响,提高分层联邦学习全局模型的训练速度。Abstract: In order to optimize the training delay of the hierarchical Federated Learning (FL) global model, focusing on the selfishness of the terminal devices in the actual scene, an incentive mechanism based on game theory is proposed. Under the condition of limited incentive budget, the equilibrium solution between terminal devices and edge servers and the minimum edge model training delay are obtained. Considering the different number of terminal devices, a variable incentive training acceleration algorithm based on Stackelberg game is designed to minimize the training delay of a global model. Simulation results demonstrate that the proposed algorithm can effectively reduce the impact of terminal devices selfishness and improve the training speed of hierarchical federated learning global model.
-
Key words:
- Hierarchical Federated Learning (FL) /
- Game theory /
- Incentive mechanism
-
算法1 基于主从博弈的可变激励训练加速算法 输入:$ \mathcal{N} = \{ {i}:{i = }1,2, \cdots ,{N}\} $,$ {\mathcal{M}_{i}} = \{ {m}:{m = }{\text{1,2,}} \cdots {\text{,}}{M}\} $,计算任务Task,数据集$ D $, $ {W_1} = {W_2} = \cdots = {W_i} = \dfrac{V}{i} $。 输出:激励预算分配的均衡点$ {\mathcal{W}_i} = \{ {W_i},i \in \mathcal{N}\} $,$ {\mathcal{Q}_{i:m}} = \{ {q_{i:m}},m \in {\mathcal{M}_i}\} $ ,终端设备$ m $提供的算力均衡解$ \mathcal{F}_{i:m}^{\text{*}} = \{ f_{i:m}^ * ,m \in {\mathcal{M}_i}\} $。 (1) repeat (2) for $ i $ in $ N $ do
(3) 边缘服务器$ i $分配激励单价$ \{ {q_{i:m}},m \in {\mathcal{M}_i}\} $,激励单价需满足条件$\displaystyle\sum\limits_{m \in {\mathcal{M}_i} } { {q_{i:m} } } {f_{i:m} } \le {W_i}$。终端设备$ m $会提供相应的算力
$\left\{ f_{i:m}^ * = {\rm{max}}\left\{ \dfrac{ { {q_{i:m} } } }{ {2\eta k{C_m} } },f_{i:m}^{\max }\right\} ,m \in {\mathcal{M}_i}\right\}$,使得自己的效用$ {U_{i:m}} $达到最大。(4) if $t_{i:m}^{{\rm{cmp}}} \ne t_{i:n}^{{\rm{cmp}}}(m \ne n)$ then (5) 边缘服务器$ i $重新分配$ {q_{i:m}} $,使得自己的效用函数$ {U_i} $达到最大,同时得到时间$ {T_i} $。 (6) end for (7) if $ {T_i} < {T_j}(i \ne j) $ then (8) 云服务器重新分配$ V $(减小$ {W_i} $,增大$ {W_j} $)。 (9) Until $ {T_i} = {T_j}(i \ne j) $  下载: 导出CSV
下载: 导出CSV
-
[1] MCMAHAN B and RAMAGE D. Federated learning: Collaborative machine learning without centralized training data[EB/OL]. https://starrymind.tistory.com/180, 2017. [2] NIKNAM S, DHILLON H S, and REED J H. Federated learning for wireless communications: Motivation, opportunities, and challenges[J]. IEEE Communications Magazine, 2020, 58(6): 46–51. doi: 10.1109/MCOM.001.1900461 [3] LIU Yi, PENG Jialiang, KANG Jiawen, et al. A secure federated learning framework for 5G networks[J]. IEEE Wireless Communications, 2020, 27(4): 24–31. doi: 10.1109/MWC.01.1900525 [4] McMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]. The 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, USA, 2017: 1273–1282. [5] LI Tian, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks[C]. Machine Learning and Systems 2020, Austin, USA, 2020, 2: 429–450. [6] MILLS J, HU Jia, and MIN Geyong. Communication-efficient federated learning for wireless edge intelligence in IoT[J]. IEEE Internet of Things Journal, 2020, 7(7): 5986–5994. doi: 10.1109/JIOT.2019.2956615 [7] LI Tian, SANJABI M, BEIRAMI A, et al. Fair resource allocation in federated learning[C]. The 8th International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 2019: 1–27. [8] LIU Lumin, ZHANG Jun, SONG S H, et al. Client-edge-cloud hierarchical federated learning[C]. 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 2020: 1–6. [9] ABAD M S H, OZFATURA E, GUNDUZ D, et al. Hierarchical federated learning ACROSS heterogeneous cellular networks[C]. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 8866–8870. [10] SUN Haifeng, LI Shiqi, YU F R, et al. Toward communication-efficient federated learning in the internet of things with edge computing[J]. IEEE Internet of Things Journal, 2020, 7(11): 11053–11067. doi: 10.1109/JIOT.2020.2994596 [11] SHI Yuanming, YANG Kai, JIANG Tao, et al. Communication-efficient edge AI: Algorithms and systems[J]. IEEE Communications Surveys & Tutorials, 2020, 22(4): 2167–2191. doi: 10.1109/COMST.2020.3007787 [12] LUO Siqi, CHEN Xu, WU Qiong, et al. HFEL: Joint edge association and resource allocation for cost-efficient hierarchical federated edge learning[J]. IEEE Transactions on Wireless Communications, 2020, 19(10): 6535–6548. doi: 10.1109/TWC.2020.3003744 [13] KHAN L U, RAJ PANDEY S, TRAN N H, et al. Federated learning for edge networks: Resource optimization and incentive mechanism[J]. IEEE Communications Magazine, 2020, 58(10): 88–93. doi: 10.1109/MCOM.001.1900649 [14] TRAN N H, BAO Wei, ZOMAYA A, et al. Federated learning over wireless networks: Optimization model design and analysis[C]. IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 2019: 1387–1395. [15] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791 -

 下载:
下载:









图(7) / 表(1)
计量
- 文章访问数: 1334
- HTML全文浏览量: 1377
- PDF下载量: 253
- 被引次数: 0
