

Study of Coarse-to-Fine Class Activation Mapping Algorithms Based on Contrastive Layer-wise Relevance Propagation
-
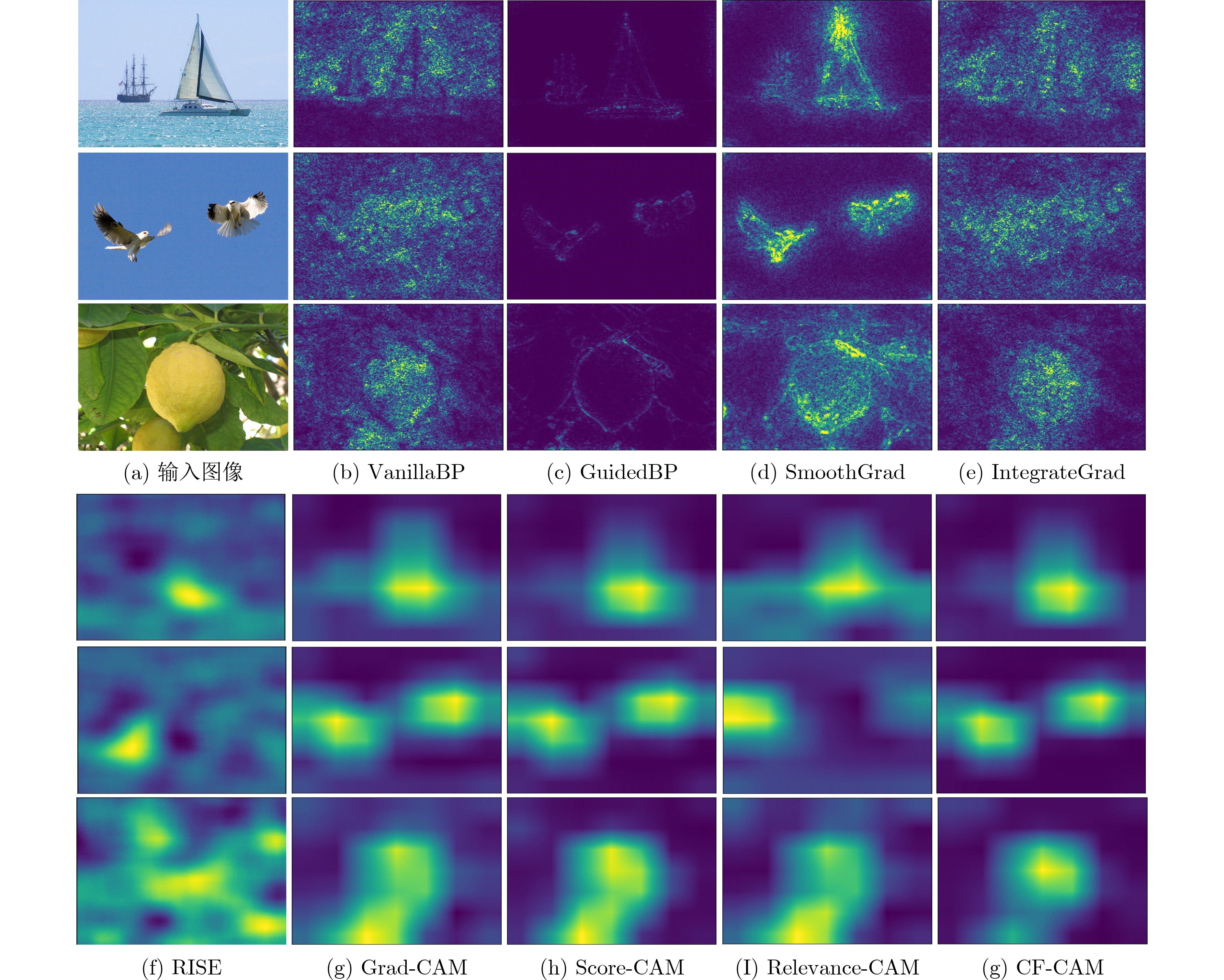
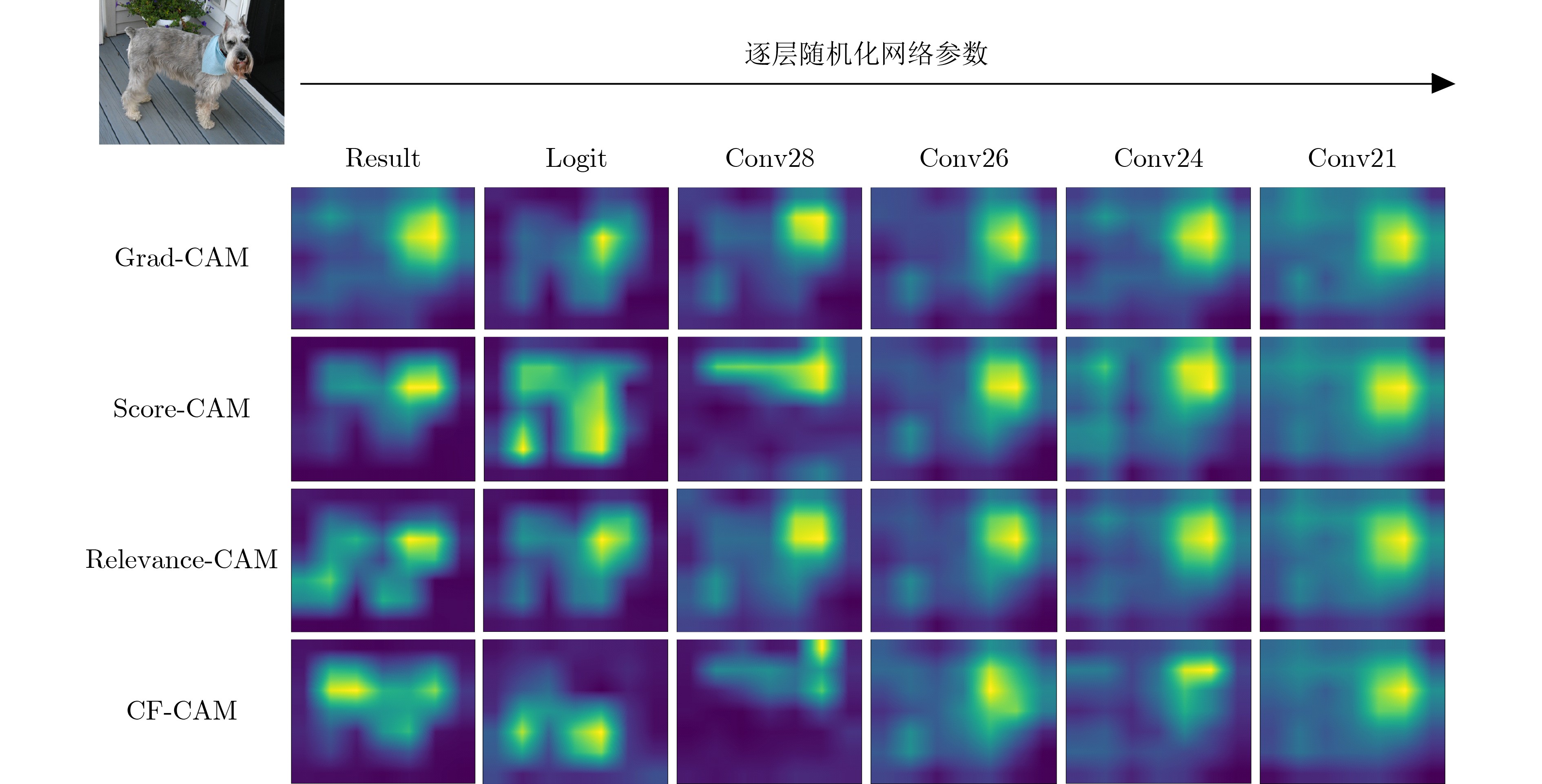
摘要: 以卷积神经网络为代表的深度学习算法高度依赖于模型的非线性和调试技术,在实际应用过程中普遍存在黑箱属性,严重限制了其在安全敏感领域的进一步发展。为此,该文提出一种由粗到细的类激活映射算法(CF-CAM),用于对深度神经网络的决策行为进行诊断。该算法重新建立了特征图和模型决策之间的关系,利用对比层级相关性传播理论获取特征图中每个位置对网络决策的贡献生成空间级的相关性掩码,找到影响模型决策的重要性区域,再与经过模糊化操作的输入图像进行线性加权重新输入到网络中得到特征图的目标分数,从空间域和通道域实现对深度神经网络进行由粗到细的解释。实验结果表明,相较于其他方法该文提出的CF-CAM在忠实度和定位性能上具有显著提升。此外,该文将CF-CAM作为一种数据增强策略应用于鸟类细粒度分类任务,对困难样本进行学习,可以有效提高网络识别的准确率,进一步验证了CF-CAM算法的有效性和优越性。Abstract: Deep learning algorithms represented by Convolutional Neural Networks (CNN) are highly dependent on the nonlinearity of the model and debugging techniques, which have generally black-box properties during practical applications, limiting severely their further development in security-sensitive fields. To this end, a Coarse-to-Fine Class Activation Mapping (CF-CAM) algorithm is proposed for diagnosing the decision-making behaviors of deep neural networks. The algorithm re-establishes the relationship between the feature map and the model decision, uses the contrastive layer-wise relevance propagation theory to obtain the contribution of each position in the feature map to the network decision, generates a spatial-level correlation mask and finds the important area that affects the model decision. After that, the mask is linearly weighted with the fuzzed input image and re-input into the network to obtain the target score of the feature map, and the deep neural network is explained from the coarse stage to the fine stage in the spatial domain and the channel domain. The experimental results show that the CF-CAM proposed in this paper has obvious advantages in terms of faithfulness and localization performance compared to other methods. In addition, this paper applies CF-CAM as a data enhancement strategy for the task of fine-grained classification of birds, which can effectively improve the accuracy of network recognition by learning difficult samples, further verify the effectiveness and superiority of this method.
-
算法1 CF-CAM算法 输入: Image I, Baseline Image Ib, Class c, Model f(x), target
layer l, Gaussian blur parameters: ksize, sigma.(1) Initialization: Initial Lc CF-CAM←0, αc←[ ], Baseline
Input ${I_b} = {\text{Guassian\_blur2d} }(I,{\text{ksize,sigma} })$;(2) Get feature maps of target layer Ak, C is the number of
channels in Ak, Relevance weights Rc;(3) for k in [0, 1, ···, C–1] do $ M_k^c = {\text{upsample}}(R_k^c{A_k}) $; $ I' = I \odot M_k^c + {I_b} \odot (1 - M_k^c) $; $ \alpha _k^c = {f^c}(I') - {f^c}({I_b}) $; $ L_{{\text{CF - CAM}}}^c = L_{{\text{CF - CAM}}}^c + \alpha _k^cM_k^c $; end (4) Return Lc CF-CAM 输出:Saliency map Lc CF-CAM  下载: 导出CSV
下载: 导出CSV
表 1 CF-CAM忠实度评估结果(%)
RISE Grad-CAM Grad-CAM++ Score-CAM Relevance-CAM CF-CAM A.D. 57.4 46.3 43.9 41.4 45.2 39.8 A.I. 8.7 15.2 18.6 20.5 17.5 21.3
下载: 导出CSV
表 2 CF-CAM的定位性能评估结果
方法 RISE Grad-CAM Grad-CAM++ Score-CAM Relevance-CAM CF-CAM 比例 40.5 52.3 54.6 61.8 53.9 62.7
下载: 导出CSV
-
[1] 时增林, 叶阳东, 吴云鹏, 等. 基于序的空间金字塔池化网络的人群计数方法[J]. 自动化学报, 2016, 42(6): 866–874. doi: 10.16383/j.aas.2016.c150663SHI Zenglin, YE Yangdong, WU Yunpeng, et al. Crowd counting using rank-based spatial pyramid pooling network[J]. Acta Automatica Sinica, 2016, 42(6): 866–874. doi: 10.16383/j.aas.2016.c150663 [2] 付晓薇, 杨雪飞, 陈芳, 等. 一种基于深度学习的自适应医学超声图像去斑方法[J]. 电子与信息学报, 2020, 42(7): 1782–1789. doi: 10.11999/JEIT190580FU Xiaowei, YANG Xuefei, CHEN Fang, et al. An adaptive medical ultrasound images despeckling method based on deep learning[J]. Journal of Electronics &Information Technology, 2020, 42(7): 1782–1789. doi: 10.11999/JEIT190580 [3] PU Fangling, DING Chujiang, CHAO Zeyi, et al. Water-quality classification of inland lakes using Landsat8 images by convolutional neural networks[J]. Remote Sensing, 2019, 11(14): 1674. doi: 10.3390/rs11141674 [4] SAMBASIVAM G and OPIYO G D. A predictive machine learning application in agriculture: Cassava disease detection and classification with imbalanced dataset using convolutional neural networks[J]. Egyptian Informatics Journal, 2021, 22(1): 27–34. doi: 10.1016/j.eij.2020.02.007 [5] ZEILER M D and FERGUS R. Visualizing and understanding convolutional networks[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 818–833. [6] ZHOU Bolei, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in deep scene CNNs[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015. [7] PETSIUK V, DAS A, and SAENKO K. RISE: Randomized input sampling for explanation of black-box models[C]. British Machine Vision Conference 2018, Newcastle, UK, 2018. [8] FONG R C and VEDALDI A. Interpretable explanations of black boxes by meaningful perturbation[C]. The IEEE International Conference on Computer Vision, Venice, Italy, 2017: 3449–3457. [9] AGARWAL C, SCHONFELD D, and NGUYEN A. Removing input features via a generative model to explain their attributions to an image classifier's decisions[EB/OL]. https://arxiv.org/abs/1910.042562019, 2019. [10] CHANG Chunhao, CREAGER E, GOLDENBERG A, et al. Explaining image classifiers by counterfactual generation[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019. [11] SIMONYAN K, VEDALDI A, and ZISSERMAN A. Deep inside convolutional networks: Visualising image classification models and saliency maps[C]. The 2nd International Conference on Learning Representations, Banff, Canada, 2014. [12] SPRINGENBERG J T, DOSOVITSKIY A, BROX T, et al. Striving for simplicity: The all convolutional net[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015. [13] BACH S, BINDER A, MONTAVON G, et al. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation[J]. PloS One, 2015, 10(7): e0130140. doi: 10.1371/journal.pone.0130140 [14] ZHOU Bolei, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2921–2929. [15] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]. The IEEE International Conference on Computer Vision, Venice, Italy, 2017: 618–626. [16] CHATTOPADHAY A, SARKAR A, HOWLADER P, et al. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks[C]. 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, USA, 2018: 839–847. [17] OMEIZA D, SPEAKMAN S, CINTAS C, et al. Smooth grad-cam++: An enhanced inference level visualization technique for deep convolutional neural network models[EB/OL]. https://arxiv.org/abs/1908.01224, 2019. [18] WANG Haofan, WANG Zifan, DU Mengnan, et al. Score-CAM: Score-weighted visual explanations for convolutional neural networks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2020: 111–119. [19] GU Jindong, YANG Yinchong, and TRESP V. Understanding individual decisions of CNNs via contrastive backpropagation[C]. The 14th Asian Conference on Computer Vision, Perth, Australia, 2018: 119–134. [20] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386 [21] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015. [22] SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. [23] LEE J R, KIM S, PARK I, et al. Relevance-CAM: Your model already knows where to look[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 14939–14948. [24] SATTARZADEH S, SUDHAKAR M, PLATANIOTIS K N, et al. Integrated Grad-CAM: Sensitivity-aware visual explanation of deep convolutional networks via integrated gradient-based scoring[C]. ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 1775–1779. [25] ZHANG Qinglong, RAO Lu, and YANG Yubin. Group-CAM: Group score-weighted visual explanations for deep convolutional networks[EB/OL]. https://arxiv.org/abs/2103.13859, 2021. [26] WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD birds-200-2011 dataset[R]. CNS-TR-2011-001, 2011. [27] RUSSAKOVSKY O, DENG Jia, SU Hao, et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211–252. doi: 10.1007/s11263-015-0816-y [28] SMILKOV D, THORAT N, KIM B, et al. SmoothGrad: Removing noise by adding noise[EB/OL]. https://arxiv.org/abs/1706.03825, 2017. [29] SUNDARARAJAN M, TALY A, and YAN Qiqi. Axiomatic attribution for deep networks[C]. The 34th International Conference on Machine Learning, Sydney, Australia, 2017: 3319–3328. [30] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [31] WU Pingyu, ZHAI Wei, and CAO Yang. Background activation suppression for weakly supervised object localization[EB/OL]. https://arxiv.org/abs/2112.00580, 2022. -


 下载:
下载:






图(7) / 表(3)
计量
- 文章访问数: 982
- HTML全文浏览量: 934
- PDF下载量: 112
- 被引次数: 0
