

A Research on Collaborative UAVs Intelligent Decision Optimization for AoI-driven Federated Learning
-
摘要: 联邦学习是6G关键技术之一,其可以在保护数据隐私的前提下,利用跨设备的数据训练一个可用且安全的共享模型。然而,大部分终端设备由于处理能力有限,无法支持复杂的机器学习模型训练过程。在异构网络融合环境下移动边缘计算(MEC)框架中,多个无人机(UAVs)作为空中边缘服务器以协作的方式灵活地在目标区域内移动,并且及时收集新鲜数据进行联邦学习本地训练以确保数据学习的实时性。该文综合考虑数据新鲜程度、通信代价和模型质量等多个因素,对无人机飞行轨迹、与终端设备的通信决策以及无人机之间的协同工作方式进行综合优化。进一步,该文使用基于优先级的可分解多智能体深度强化学习算法解决多无人机联邦学习的连续在线决策问题,以实现高效的协作和控制。通过采用多个真实数据集进行仿真实验,仿真结果验证了所提出的算法在不同的数据分布以及快速变化的动态环境下都能取得优越的性能。Abstract: Federated learning is one of the key technologies of 6G, which can use cross-device data to train a usable and safe sharing model on the premise of protecting data privacy. However, most end devices have limited processing capabilities and can not support complex machine learning model training processes. In the framework of Mobile Edge Computing (MEC) in a heterogeneous network convergence environment, multiple Unmanned Aerial Vehicles (UAVs) are used as aerial edge servers to move flexibly within the target area in a collaborative manner, and collect fresh data in time for federated learning and local training to ensure real-time data learning. Multiple factors, such as data freshness, communication cost and model quality, are considered, and the flight trajectories of UAVs, the communication decisions with the user equipment, and the collaborative work between UAVs are comprehensively optimized. Moreover, a priority-based decomposable multi-agent deep reinforcement learning algorithm is used to solve the continuous online decision-making problem of multiple UAVs federated learning to achieve effective collaboration and control. By using multiple real data sets for simulation experiments, simulation results verify that the proposed algorithm can achieve superior performance under different data distributions and in rapidly changing complex dynamic environments.
-
表 1 系统参数及其定义
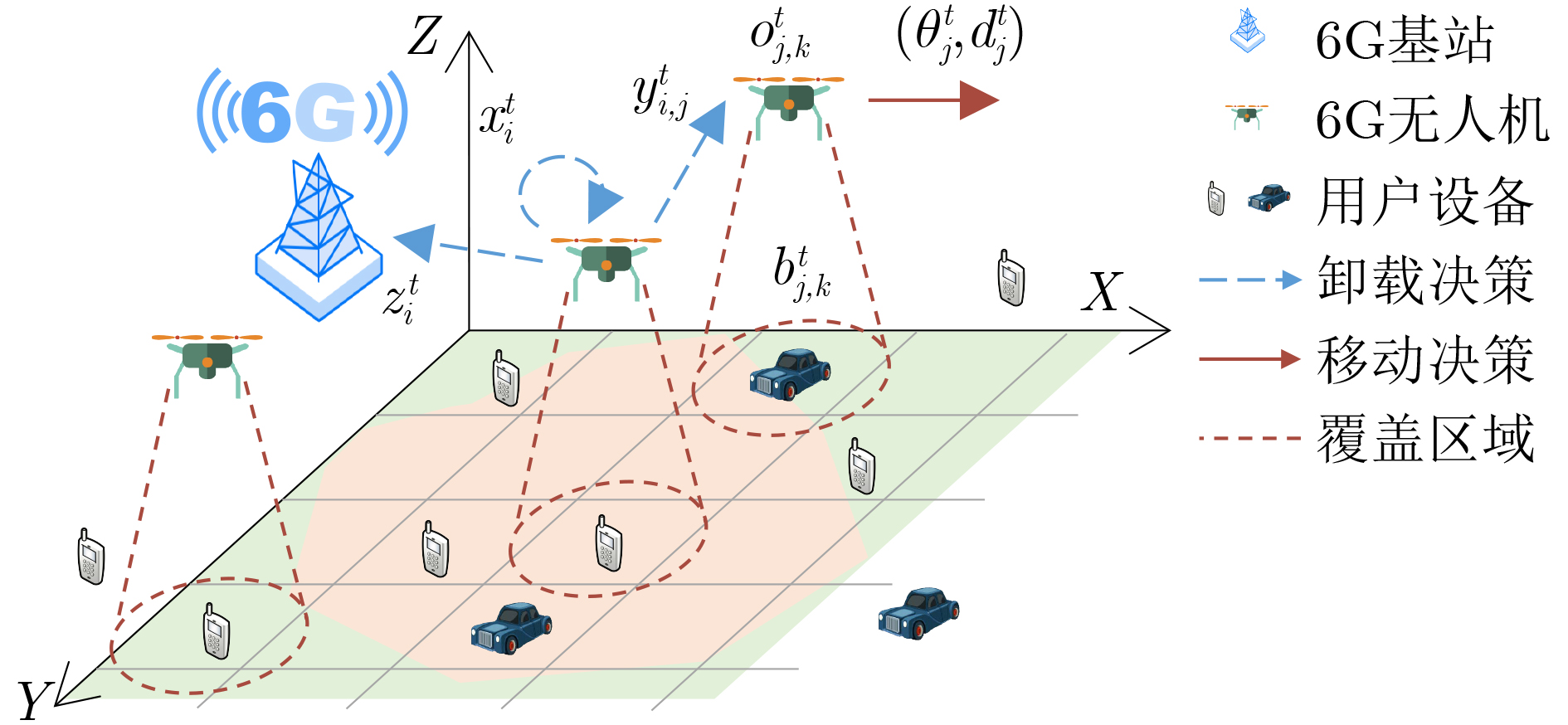
参数 定义 参数 定义 ${{R} }_{{i}\text{,}{k} }^{\text{}{t} }$ 无人机$ {i} $与用户设备$ {k} $的欧氏距离 ${ {c} }_{{i} }$, ${ {c} }_{{j} }$, ${ {c} }_{{B} }$ 无人机$ {i} $、无人机$ {j} $、基站的计算能力 ${W}$ 通信带宽 $ \sigma $, $ {{g}}_{\text{0}} $ 噪声功率和每米的信道功率增益 ${{p} }_{{i}\text{,B} }^{\text{tra} }$, ${{p} }_{{i}\text{,U} }^{\text{tra} }$ U2B, U2U数据传输功率 ${{ \lambda } }_{\text{B} }^{{t} }$, ${ { \lambda } }_{{j} }^{ {t} }$ 在基站、无人机$ {j} $上的排队时延 ${{d} }_{{i}\text{,B} }$, ${{d} }_{{i}\text{,}\text{j} }$ 无人机$ {i} $与基站、无人机$ {j} $的欧氏距离 ${ {d} }_{ {{k} }_{\text{1} }\text{,}{ {k} }_{\text{2} } }$ 无人机从用户设备$ {{k}}_{\text{1}} $到$ {{k}}_{\text{2}} $的移动距离 ${{v} }_{{i} }^{\text{mov} }$, ${{p} }_{{i} }^{\text{mov} }$ 无人机$ {i} $的移动速率、移动功率 $ {{p}}_{{i}}^{\text{cmp}} $, $ {{p}}_{{i}}^{\text{rev}} $ 无人机$ {i} $的数据计算功率、数据接收功率  下载: 导出CSV
下载: 导出CSV
表 2 联邦学习算法(算法1)
初始化最大全局模型训练回合数${ {T} }^{ {}{{\rm{max}}} }$、最大本地模型训练回合数${ {N} }^{{{\rm{max}}} }$、学习率$\eta $、目标准确率$ \epsilon $和全局模型参数${{ \omega } }^{{0} }$; 调用执行算法2函数INIT(); for全局回合${t}{}{=}{}{1,}{}{2,}{}\cdots {,}{ {}{T} }^{ {{\rm{max}}} }$ 调用执行算法2的函数EXPLORATION(),获取无人机的决策; for无人机$ {i}{}{=}{}{1,}{}{2,}{}\cdots {,}{}{N} $ 执行无人机与用户设备的通信,获取训练数据; 下载全局模型${ { \omega } }_{ {i} }^{ {t}{,0} }{}\leftarrow{}{ { \omega } }^{ {t}{-1} }$; for局部回合${n}{}{=}{}{1,}{}{2,}{}\cdots {,}{}{ {N} }^{ {}{{\rm{max}}} }$ 更新局部模型参数${ { \omega } }_{ {i} }^{ {t}{,}{n} }{}{=}{}{ { \omega } }_{ {i} }^{ {t}{,}{n}{-1} }-{}\eta{{\text{∇}}}{ {L} }_{ {i} }\left({ { \omega } }_{ {i} }^{ {t}{,}{n}{-1} }\right)$; if $\left\|{{\text{∇}}}{ {L} }_{ {i} }\left({ { \omega } }_{ {i} }^{ {t}{,}{n} }\right)\right\|{}{\le}{}\epsilon \left\|{{\text{∇}}}{ {L} }_{ {i} }\left({ { \omega } }_{ {i} }^{ {t}{,}{n}{-1} }\right)\right\|$ then break; $ {{I}}_{{i}}^{{}{t}}\left(\epsilon\right){}{=}{}{n} $; 无人机$ {i} $上传局部模型${ { \omega } }_{ {i} }^{ {t} }{}{(}{ { \omega } }_{ {i} }^{ {t} }{}\leftarrow{}{ { \omega } }_{ {i} }^{ {t}{,}{n} }{)}$; 进行全局模型聚合,调用执行算法2的函数EXPLOITATION($ {{I}}^{{}{t}}\left(\epsilon\right) $, ${ {{\rm{Acc}}} }^{ {t} }$)。
下载: 导出CSV
表 3 PD-MADDPG算法(算法2)
函数INIT( ): for无人机$ {i}{}{=}{}{1,}{}{2,}{}\cdots {,}{}{N} $ 初始化局部critic、actor网络的权值为$ {\phi}_{{i}} $和$ {\vartheta}_{{i}} $、局部目标critic、actor网络的权值为$ {\phi}_{{i}}^{{'}}{}\leftarrow{}{\phi}_{{i}} $和${\vartheta }_{{i} }^{{'} }{}\leftarrow{}{\vartheta}_{{i} }$; 初始化全局critic网络的权值为$ {\psi} $、全局目标critic 网络的权值为$ {\psi'}{}\leftarrow{}{\psi} $、基于优先级的经验回放缓存PER。 函数EXPLORATION( ): 获得当前环境状态${ {{\boldsymbol{s}}} }^{ {t} }{}{=}{}\left[{ {{\boldsymbol{s}}} }_{ {1} }^{ {t} }{,}{ {}{{\boldsymbol{s}}} }_{ {2} }^{ {t} }{,}{}\cdots {,}{ {}{{\boldsymbol{s}}} }_{ {N} }^{ {t} }\right]$,当${t}{=0}$时随机初始化状态${ {{\boldsymbol{s}}} }^{ {0} }$; for无人机$ {i}{}{=}{}{1,}{}{2,}{}\cdots {,}{}{N} $ while True 根据当前策略选择动作${ { {\boldsymbol{a} } } }_{ {i} }^{ {t} }{}{=}{}{ \pi }_{ {i} }\left({ {s} }_{ {i} }^{ {t} }\right){}{+}{}\rho \mathcal {O}$,其中${\mathcal O}$是高斯随机噪声,$ \rho $随着$ {t} $衰减; if无人机$ {i} $没有飞越边界,或与其它他人机的位置重合then break; return $ {{a}}^{{t}}{}{=}{}\left[{{a}}_{{1}}^{{t}}{,}{}{{a}}_{{2}}^{{t}}{,}{}\cdots {,}{}{{a}}_{{N}}^{{t}}\right] $。 函数EXPLOITATION($ {{I}}^{{}{t}}\left({\epsilon}\right) $, $ {\rm{Acc}}^{{t}} $): 执行动作${ {{\boldsymbol{a}}} }^{ {t} }{}{=}{}\left[{ {{\boldsymbol{a}}} }_{ {1} }^{ {t} }{,}{}{ {{\boldsymbol{a}}} }_{ {2} }^{ {t} }{,}{}\cdots {,}{}{ {{\boldsymbol{a}}} }_{ {N} }^{ {t} }\right]$,获取新状态$ {{s}}^{{t}{+1}} $,计算全局奖励$ {{r}}_{{g}}^{{}{t}} $和局部奖励$ {{r}}_{{l}}^{{}{t}} $; 将${[}{ {{\boldsymbol{s}}} }^{ {t} }{,}{}{ {{\boldsymbol{a}}} }^{ {t} }{,}{}{ {r} }_{ {g} }^{ {}{t} }{,}{}{ {r} }_{ {l} }^{ {}{t} }{,}{}{ {{\boldsymbol{s}}} }^{ {t}{+1} }{]}$ 保存到PER; if PER满then 从PER抽取一批样本$\left[{ {{\boldsymbol{s}}} }^{ {t} }{,}{}{ {{\boldsymbol{a}}} }^{ {t} }{,}{}{ {r} }_{ {g} }^{ {}{t} }{,}{}{ {{\boldsymbol{s}}} }^{ {t}{+1} }\right]$; 更新全局critic 网络,根据${\psi'}{}\leftarrow{}{\xi\psi}{}{+}{}{(1}{}{-}{}{\xi}{)}{\psi'}$更新全局目标critic网络,$ {ξ} $是更新速率; for无人机$ {i}{}{=}{}{1,}{}{2,}{}\cdots {,}{}{N} $ 从PER抽取一批样本${[}{ {{\boldsymbol{s}}} }^{ {t} }{,}{}{ {{\boldsymbol{a}}} }^{ {t} }{,}{}{ {r} }_{ {l} }^{ {}{t} }{,}{}{ {{\boldsymbol{s}}} }^{ {t}{+1} }{]}$; 更新局部critic, actor网络,根据${\phi}^{ {'} }\leftarrow{\xi}\phi{}{+}\left({1}{}-{}{\xi}\right){\phi}^{ {'} },\vartheta{'}{}\leftarrow{}{\xi}\vartheta{}{+}{}\left({1}{}-{}{\xi}\right){\vartheta'}$更新目标局部网络。
下载: 导出CSV
表 4 各算法在不同数据集的不同非独立同分布程度时的全局模型预测准确率
算法 MNIST Fashion-MNIST CIFAR-10 D = 0 D = 0.5 D = 1 D = 2 D = 0 D = 0.5 D = 1 D = 2 D = 0 D = 0.5 D = 1 D = 2 PDMADDPG 0.661 0.590 0.519 0.533 0.451 0.371 0.288 0.379 0.343 0.338 0.336 0.328 PMADDPG 0.619 0.384 0.483 0.442 0.361 0.370 0.190 0.367 0.324 0.305 0.302 0.312 PDDPG 0.558 0.450 0.453 0.521 0.435 0.336 0.261 0.359 0.323 0.320 0.306 0.311 GREEDY 0.561 0.544 0.487 0.515 0.400 0.344 0.282 0.358 0.320 0.309 0.325 0.320 RANDOM 0.479 0.278 0.463 0.407 0.291 0.292 0.194 0.289 0.322 0.330 0.326 0.319
下载: 导出CSV
-
[1] PHAM Q V, FANG Fang, HA V N, et al. A survey of multi-access edge computing in 5G and beyond: Fundamentals, technology integration, and state-of-the-art[J]. IEEE Access, 2020, 8: 116974–117017. doi: 10.1109/ACCESS.2020.3001277 [2] LIM W Y B, LUONG N C, HOANG D T, et al. Federated learning in mobile edge networks: A comprehensive survey[J]. IEEE Communications Surveys & Tutorials, 2020, 22(3): 2031–2063. doi: 10.1109/COMST.2020.2986024 [3] WANG Jingrong, LIU Kaiyang, and PAN Jianping. Online UAV-mounted edge server dispatching for mobile-to-mobile edge computing[J]. IEEE Internet of Things Journal, 2020, 7(2): 1375–1386. doi: 10.1109/JIOT.2019.2954798 [4] BRIK B, KSENTINI A, and BOUAZIZ M. Federated learning for UAVs-enabled wireless networks: Use cases, challenges, and open problems[J]. IEEE Access, 2020, 8: 53841–53849. doi: 10.1109/ACCESS.2020.2981430 [5] JEONG S, SIMEONE O, and KANG J. Mobile edge computing via a UAV-mounted cloudlet: Optimization of bit allocation and path planning[J]. IEEE Transactions on Vehicular Technology, 2018, 67(3): 2049–2063. doi: 10.1109/TVT.2017.2706308 [6] MAO Yuyi, YOU Changsheng, ZHANG Jun, et al. A survey on mobile edge computing: The communication perspective[J]. IEEE Communications Surveys & Tutorials, 2017, 19(4): 2322–2358. doi: 10.1109/COMST.2017.2745201 [7] POUYANFAR S, SADIQ S, YAN Yilin, et al. A survey on deep learning: Algorithms, techniques, and applications[J]. ACM Computing Surveys, 2019, 51(5): 92. doi: 10.1145/3234150 [8] SUN Yin, UYSAL-BIYIKOGLU E, YATES R D, et al. Update or wait: How to keep your data fresh[J]. IEEE Transactions on Information Theory, 2017, 63(11): 7492–7508. doi: 10.1109/TIT.2017.2735804 [9] DAI Zipeng, LIU C H, HAN Rui, et al. Delay-sensitive energy-efficient UAV crowdsensing by deep reinforcement learning[J]. IEEE Transactions on Mobile Computing, To be published. [10] KAUL S, YATES R, and GRUTESER M. Real-time status: How often should one update?[C]. 2012 Proceedings IEEE INFOCOM, Orlando, USA, 2012: 2731–273. [11] LUO Siqi, CHEN Xu, WU Qiong, et al. HFEL: Joint edge association and resource allocation for cost-efficient hierarchical federated edge learning[J]. IEEE Transactions on Wireless Communications, 2020, 19(10): 6535–6548. doi: 10.1109/TWC.2020.3003744 [12] WANG Liang, WANG Kezhi, PAN Cunhua, et al. Deep reinforcement learning based dynamic trajectory control for UAV-assisted mobile edge computing[J]. IEEE Transactions on Mobile Computing, To be published. [13] SHEIKH H U and BŐLŐNI L. Multi-agent reinforcement learning for problems with combined individual and team reward[C]. 2020 International Joint Conference on Neural Networks, Glasgow, UK, 2020: 1–8. [14] CAO Xi, WAN Huaiyu, LIN Youfang, et al. High-value prioritized experience replay for off-policy reinforcement learning[C]. The 31st International Conference on Tools with Artificial Intelligence, Portland, USA, 2019: 1510–1514. -

 下载:
下载:





图(4) / 表(4)
计量
- 文章访问数: 2379
- HTML全文浏览量: 1284
- PDF下载量: 336
- 被引次数: 0
