

Video Request Prediction and Cooperative Caching Strategy Based on Federated Learning in Mobile Edge Computing
-
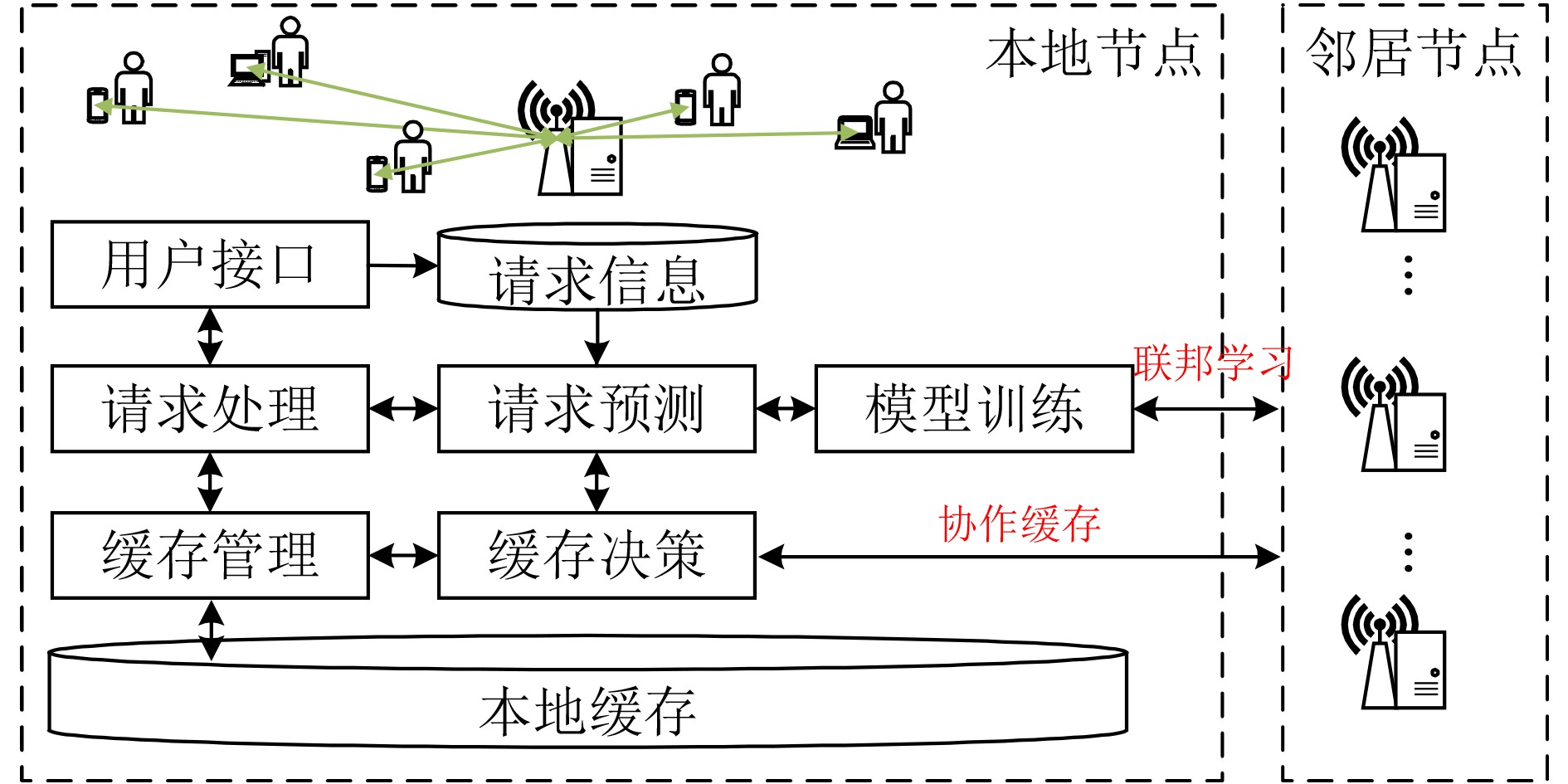
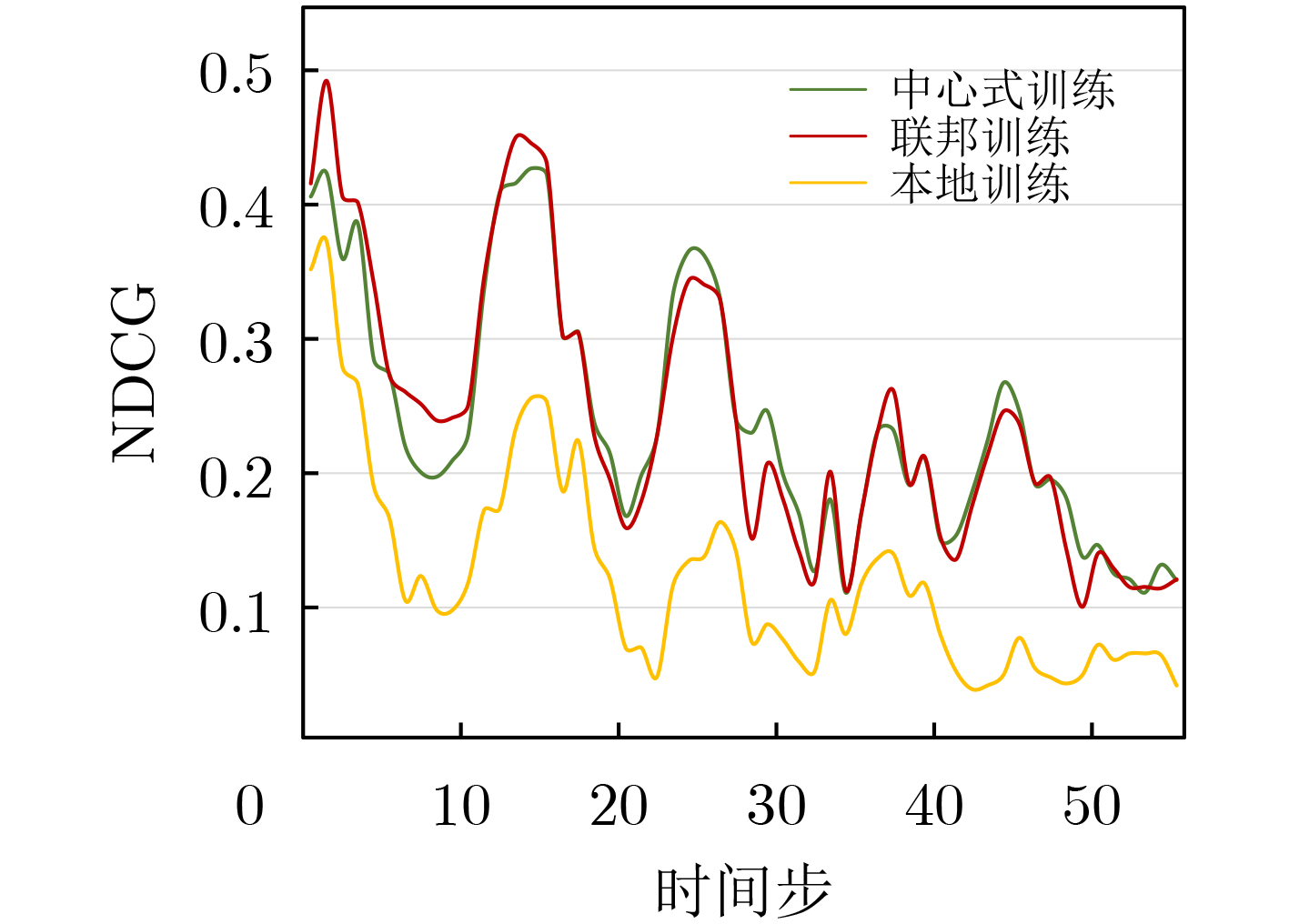
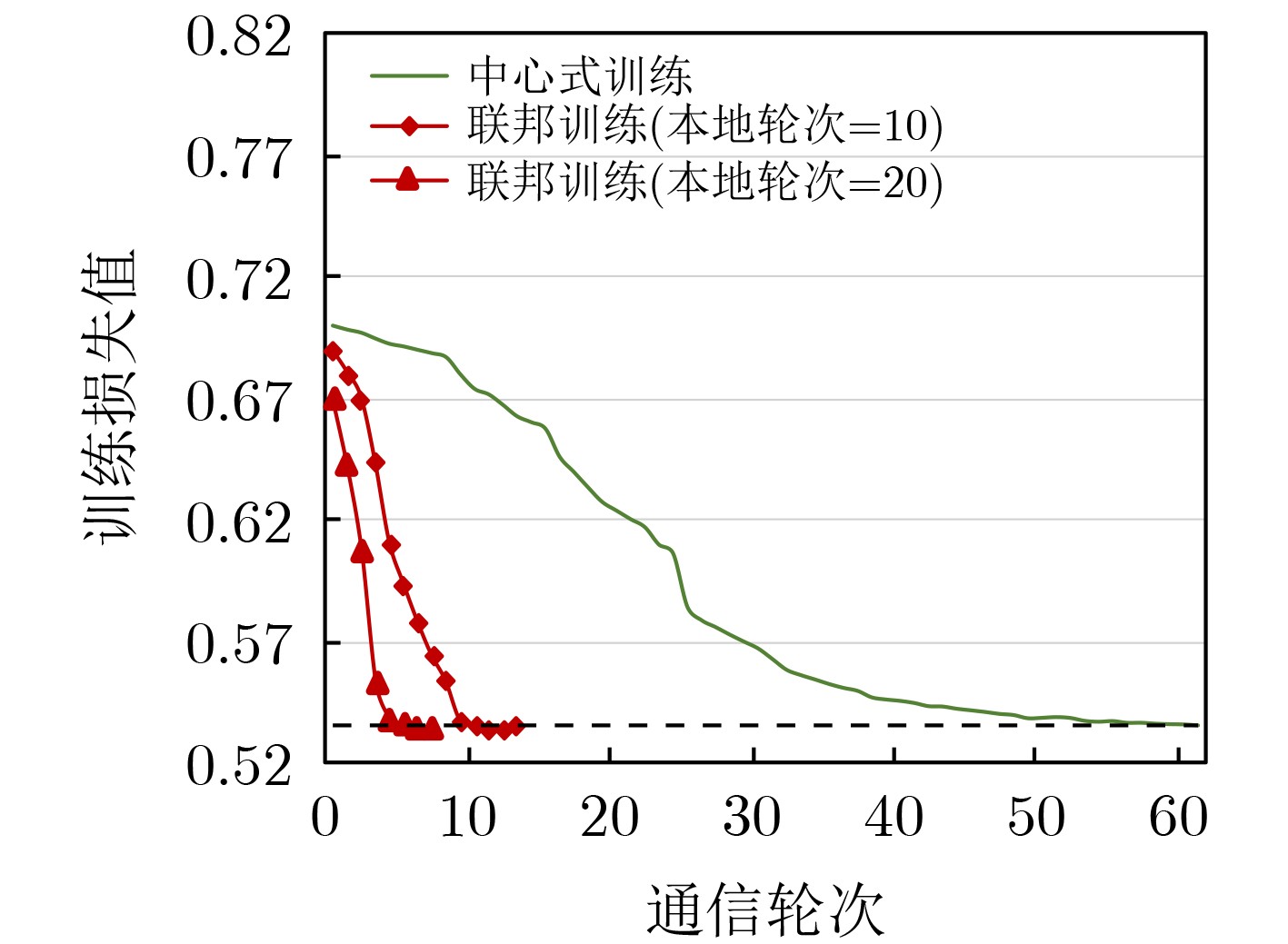
摘要: 随着互联网社交平台的崛起和移动智能终端设备的普及,自媒体短视频、直播等视频业务蓬勃发展,人们对高质量视频服务的需求也急剧上升。与此同时,连接到核心网络的大量智能设备增加了回程链路的负载,传统的云计算难以满足用户对视频服务的低延迟要求。移动边缘计算(MEC)通过在网络边缘部署具有计算和存储能力的边缘节点,通过在更靠近用户的边缘侧提高计算和存储服务,降低了数据传输时延进而缓解了网络阻塞。因此,基于MEC架构,该文充分利用网络边缘资源,提出了基于联邦学习的视频请求预测和视频协作缓存策略。通过利用多个边缘节点对提出的深度请求预测模型(DRPN)视频请求预测模型进行联邦训练,预测视频未来的请求情况,然后量化缓存内容所带来的时延收益并协作地以最大化该时延收益为目的进行缓存决策。该文分析了真实数据集MovieLens,模拟了视频请求缓存场景并进行实验。仿真结果表明,相比于其他策略,所提策略不仅能有效降低用户等待时延,在有限的缓存空间中提高内容多样性,从而提高缓存命中率,降低缓存成本,还能降低整个系统的通信成本。Abstract: With the rise of Internet social platforms and the popularization of mobile smart terminal devices, people's demand for high-quality and real-time data has risen sharply, especially for video services such as short videos and live streams. At the same time, too many terminal devices connected to the core network increase the load of the backhaul link, so that the traditional cloud computing is difficult to meet the low-latency requirements of users for video services. By deploying edge nodes with computing and storage capabilities at the edge of the network, Mobile Edge Computing (MEC) can calculate and store closer to the users, which will reduce the data transmission delay and alleviate the network congestion. Therefore, making full use of the computing and storage resources at the edge of the network under MEC, a video request prediction method and a cooperative caching strategy based on federated learning are proposed. By federally training the proposed model Deep Request Prediction Network (DRPN) with multiple edge nodes, the video requests in the future can be predicted and then cache decisions can be made cooperatively. The simulation results show that compared with other strategies, the proposed strategy can not only effectively improve the cache hit rate and reduce the user waiting delay, but also reduce the communication cost and cache cost of the whole system to a certain extent.
-
Key words:
- Mobile Edge Computing(MEC) /
- Federated learning /
- Video caching /
- Request prediction
-
算法1 DRPN模型的分布式联邦训练 输入:$\mathcal{N}{{n} }$, $\mathcal{D}$, $k$, ${\boldsymbol{w}}_n^0$, $T$, $E$, $\eta $ 输出:${{\boldsymbol{w}}^{t + 1} }$ (1) $ N \leftarrow \;|\mathcal{N}| $ (2) $ K\leftarrow \mathrm{max}\left(\lceil kN\rceil ,1\right) $ #$k$为每轮参与训练的边缘节点占比,
$k \in (0,1]$(3) for $t{\text{ } } = {\text{ } }1,{\text{ } }2,{\text{ } }\cdots,{\text{ } }T$ do #全局训练轮次 (4) 从节点集合$ \mathcal{N} $中随机选择$K$个节点形成子集$ \mathcal{N}' $ (5) for $n \in \mathcal{N}'$ do #各节点并行执行 (6) ${\boldsymbol{w}}_n^{t + 1} \leftarrow { {\rm{LOCALUPDATE} } } \left( {n,{ {\boldsymbol{w} }^t} } \right)$ (7) end for (8) 中心作为聚合器,负责计算、汇总并分发下一轮权重
${{\boldsymbol{w}}^{t + 1} }$
(9) ${{\boldsymbol{w}}^{t + 1} } \leftarrow \displaystyle\sum\limits_{n = 1}^N {\frac{ {\left| { {D_n} } \right|} }{D}{{\boldsymbol{w}}^{t + 1} } }$(10) end for (11) function ${{\rm{LOCALUPDATE}}} \left( {n,{{\boldsymbol{w}}^t} } \right)$ #本地训练 (12) for $e{\text{ } } = {\text{ } }1,{\text{ } }2,{\text{ } }\cdots,{\text{ } }E$ do #本地训练轮次 (13) ${\boldsymbol{w} }_n^{t + 1} \leftarrow {\boldsymbol{w} }_n^t - \eta \nabla {F_n}\left( { { {\boldsymbol{w} }^t} } \right)$ #$\eta $为学习率 (14) end for (15) return ${\boldsymbol{w} }_n^{t + 1}$ (16) end function  下载: 导出CSV
下载: 导出CSV
算法2 基于贪心算法的协作缓存策略(GCCS) 输入:$\mathcal{N}_{{n} }$, $ \mathcal{L} = \left[ {{L_1},\cdots,{L_n},\cdots,{L_N}} \right] $, $ \mathcal{C} = \left[ {{C_1},\cdots,{C_n},\cdots,{C_N}} \right] $ 输出:$\mathcal{L}' = \left[ { { L'_1},\cdots,{ L'_n},\cdots,{ L'_N} } \right]$ (1)初始化$ \mathcal{C} $中的每一项为实际最大可用缓存容量 (2)初始化$ \mathcal{L}' $中的每一项为空的缓存列表 (3)记$ \mathcal{F} $为$ \mathcal{L} $中每一个列表所涉及的内容标识符$f$的全集 (4)repeat (5) $ {\text{best\_gain}} \leftarrow 0 $ (6) for $ n $ in $\mathcal{N}{{n} }$ (7) for $ f $ in $\mathcal{F}$ (8) if $ f $ not in $ L' $ and ${s_f} \le {C_n}$ then (9) ${\text{gain} } \leftarrow {{\rm{CALCULATEGAIN}}} \left( {n,f} \right)$ (10) ${\text{best\_gain} } \leftarrow \max \left( { {\text{best\_gain} },{{\rm{gain}}} } \right)$ (11) end if (12) end for (13) end for (14) if $ {\text{best\_gain}} \ne 0 $ then (15) $ f' \leftarrow $产生最大增益时所对应的内容标识符 (16) $ n' \leftarrow $产生最大增益时所对应的节点 (17) Add $ f' $ to $ {L'_{n'}} $ (18) $ {C_{n'}} \leftarrow {C_{n'}} - {s_{f'}} $ (19) end if (20)until $ {\text{best\_gain}} = 0 $ (21)function $ {\rm CALCULATEGAIN} \left( {n',f'} \right) $ (22) $ {\text{total\_gain}} \leftarrow 0 $ (23) 记$ \mathcal{F}' $为$ \mathcal{L}' $中每一个列表所涉及的内容标识符$f$的全集 (24) for $ n $ in $\mathcal{N}{{n} }$ (25) if $ f' $ in $ {L_n} $ then (26) $ c \leftarrow $$ {L_n} $中对于$ f' $的流行度预测值${\text{pred\_pop}}$ (27) if $ f' $ not in $ \mathcal{F}' $ then (28) $ {\text{total\_gain}} \leftarrow {\text{total\_gain}} + c $ #命中状态由云端命
中变换为邻居命中(29) end if (30) if $ n = n' $ then (31) ${\text{total\_gain} } \leftarrow {\text{total\_gain} } + \alpha{\text{c} }$ #命中状态由邻
居命中变换为本地命中(32) end if (33) end if (34) end for (35) return $ {\text{total\_gain}} $ (36) end function
下载: 导出CSV
-
[1] Intel. How 5G will transform the business of media and entertainment[R]. 2018. [2] MANSOURI Y and BABAR M A. A review of edge computing: Features and resource virtualization[J]. Journal of Parallel and Distributed Computing, 2021, 150: 155–183. doi: 10.1016/j.jpdc.2020.12.015 [3] LI Suoheng, XU Jie, VAN DER SCHAAR M, et al. Trend-aware video caching through online learning[J]. IEEE Transactions on Multimedia, 2016, 18(12): 2503–2516. doi: 10.1109/TMM.2016.2596042 [4] THAR K, TRAN N H, OO T Z, et al. DeepMEC: Mobile edge caching using deep learning[J]. IEEE Access, 2018, 6: 78260–78275. doi: 10.1109/ACCESS.2018.2884913 [5] RATHORE S, RYU J H, SHARMA P K, et al. DeepCachNet: A proactive caching framework based on deep learning in cellular networks[J]. IEEE Network, 2019, 33(3): 130–138. doi: 10.1109/MNET.2019.1800058 [6] 杨静, 李金科. 带有特征感知的D2D内容缓存策略[J]. 电子与信息学报, 2020, 42(9): 2201–2207. doi: 10.11999/JEIT190691YANG Jing and LI Jinke. Feature-aware D2D content caching strategy[J]. Journal of Electronics &Information Technology, 2020, 42(9): 2201–2207. doi: 10.11999/JEIT190691 [7] SAPUTRA Y M, HOANG D T, NGUYEN D N, et al. Distributed deep learning at the edge: A novel proactive and cooperative caching framework for mobile edge networks[J]. IEEE Wireless Communications Letters, 2019, 8(4): 1220–1223. doi: 10.1109/LWC.2019.2912365 [8] 刘浩洋, 王钢, 杨文超, 等. 基于随机几何理论的流行度匹配边缘缓存策略[J]. 电子与信息学报, 2021, 43(12): 3427–3433. doi: 10.11999/JEIT210493LIU Haoyang, WANG Gang, YANG Wenchao, et al. Popularity matching edge caching policy based on stochastic geometry theory[J]. Journal of Electronics &Information Technology, 2021, 43(12): 3427–3433. doi: 10.11999/JEIT210493 [9] MCMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]. The 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, USA, 2017: 1273–1282. [10] GroupLens. Recommended for new research[EB/OL]. https://grouplens.org/datasets/movielens/, 2020. [11] MÜLLER S, ATAN O, VAN DER SCHAAR M, et al. Context-aware proactive content caching with service differentiation in wireless networks[J]. IEEE Transactions on Wireless Communications, 2017, 16(2): 1024–1036. doi: 10.1109/TWC.2016.2636139 [12] JIANG Yanxiang, MA Miaoli, BENNIS M, et al. User preference learning-based edge caching for fog radio access network[J]. IEEE Transactions on Communications, 2019, 67(2): 1268–1283. doi: 10.1109/TCOMM.2018.2880482 [13] GUO Dandan, CHEN Bo, LU Ruiying, et al. Recurrent hierarchical topic-guided RNN for language generation[C/OL]. The 37th International Conference on Machine Learning, 2020: 3810–3821. [14] CUI Zhiyong, KE Ruimin, PU Ziyuan, et al. Stacked bidirectional and unidirectional LSTM recurrent neural network for forecasting network-wide traffic state with missing values[J]. Transportation Research Part C:Emerging Technologies, 2020, 118: 102674. doi: 10.1016/j.trc.2020.102674 [15] ALE L, ZHANG Ning, WU Huici, et al. Online proactive caching in mobile edge computing using bidirectional deep recurrent neural network[J]. IEEE Internet of Things Journal, 2019, 6(3): 5520–5530. doi: 10.1109/JIOT.2019.2903245 [16] CHEN Mingzhe, YANG Zhaoyang, SAAD W, et al. A joint learning and communications framework for federated learning over wireless networks[J]. IEEE Transactions on Wireless Communications, 2021, 20(1): 269–283. doi: 10.1109/TWC.2020.3024629 -


 下载:
下载:






图(8) / 表(2)
计量
- 文章访问数: 1562
- HTML全文浏览量: 812
- PDF下载量: 200
- 被引次数: 0
