

An Analog Neuron Circuit for Spiking Convolutional Neural Networks Based on Flash Array
-
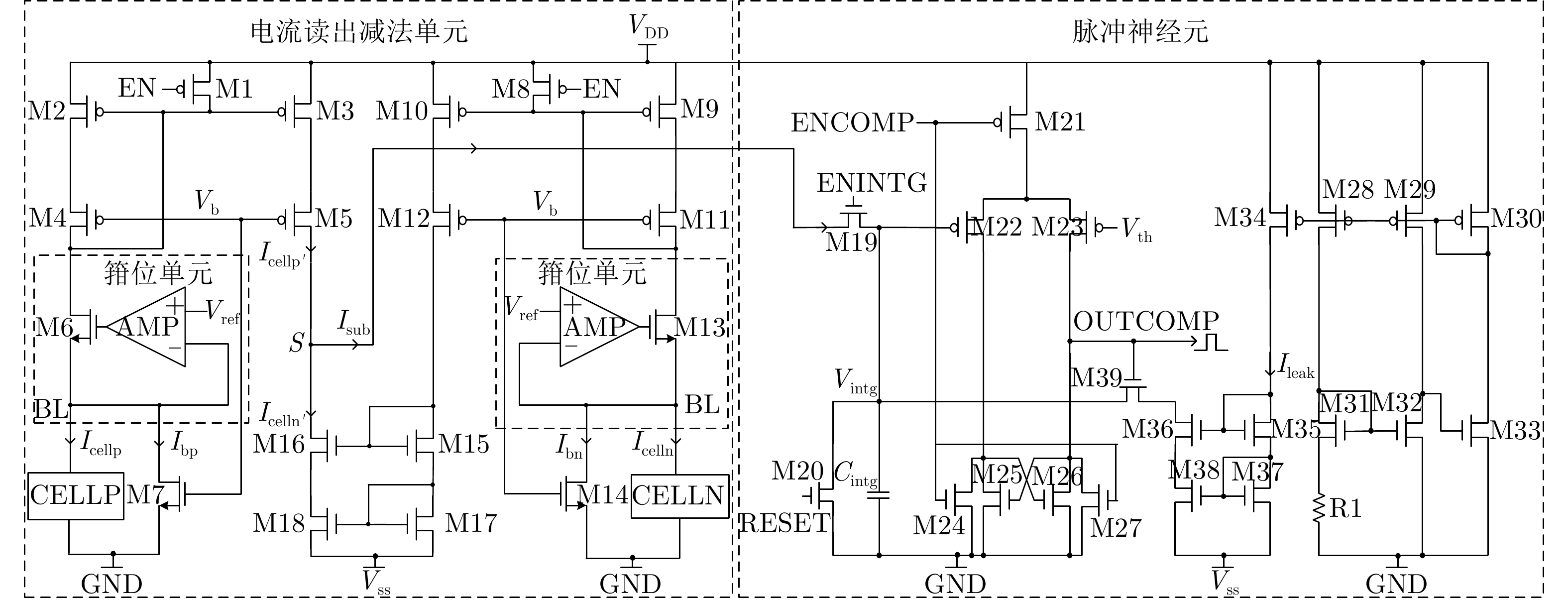
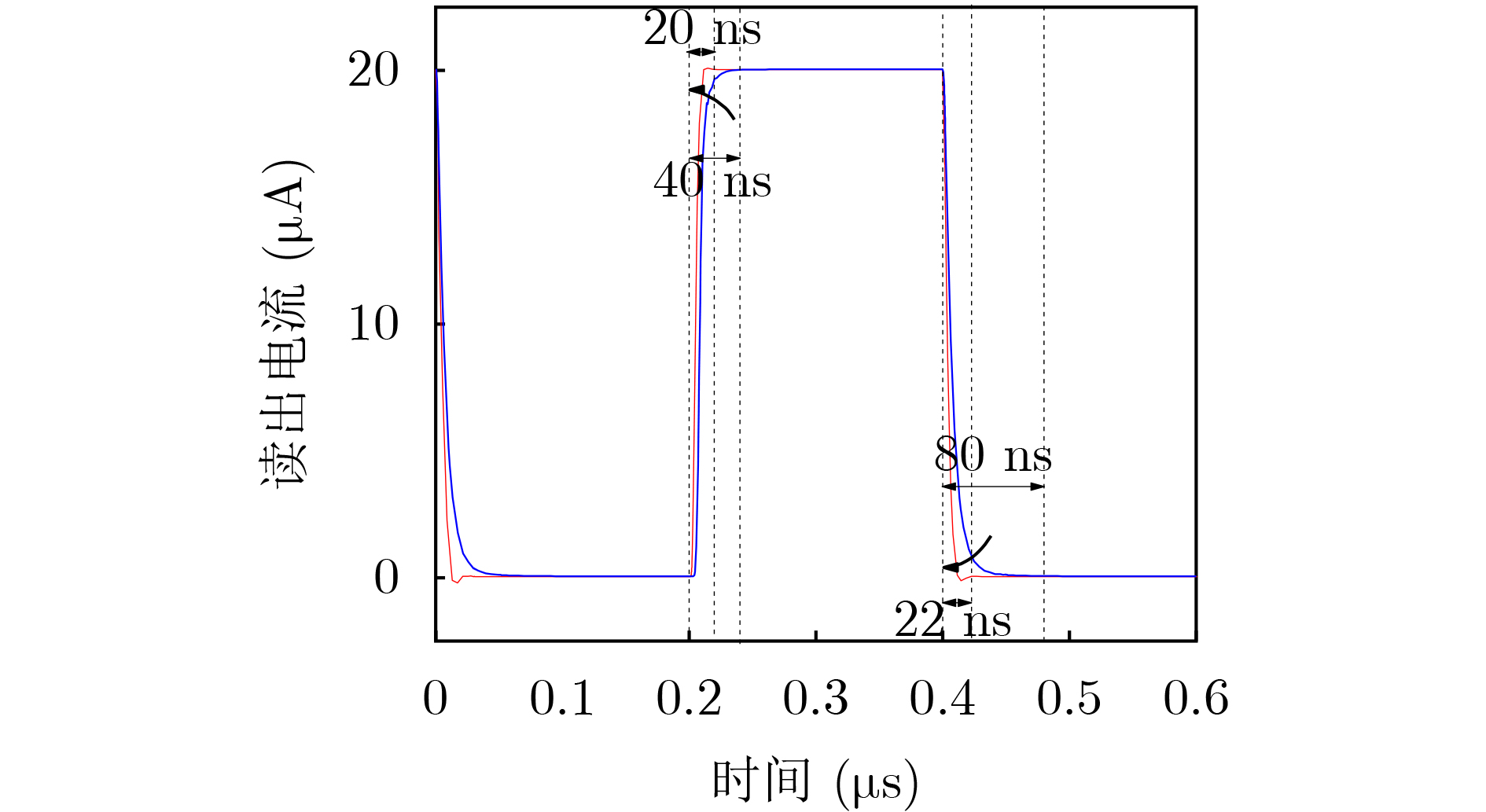
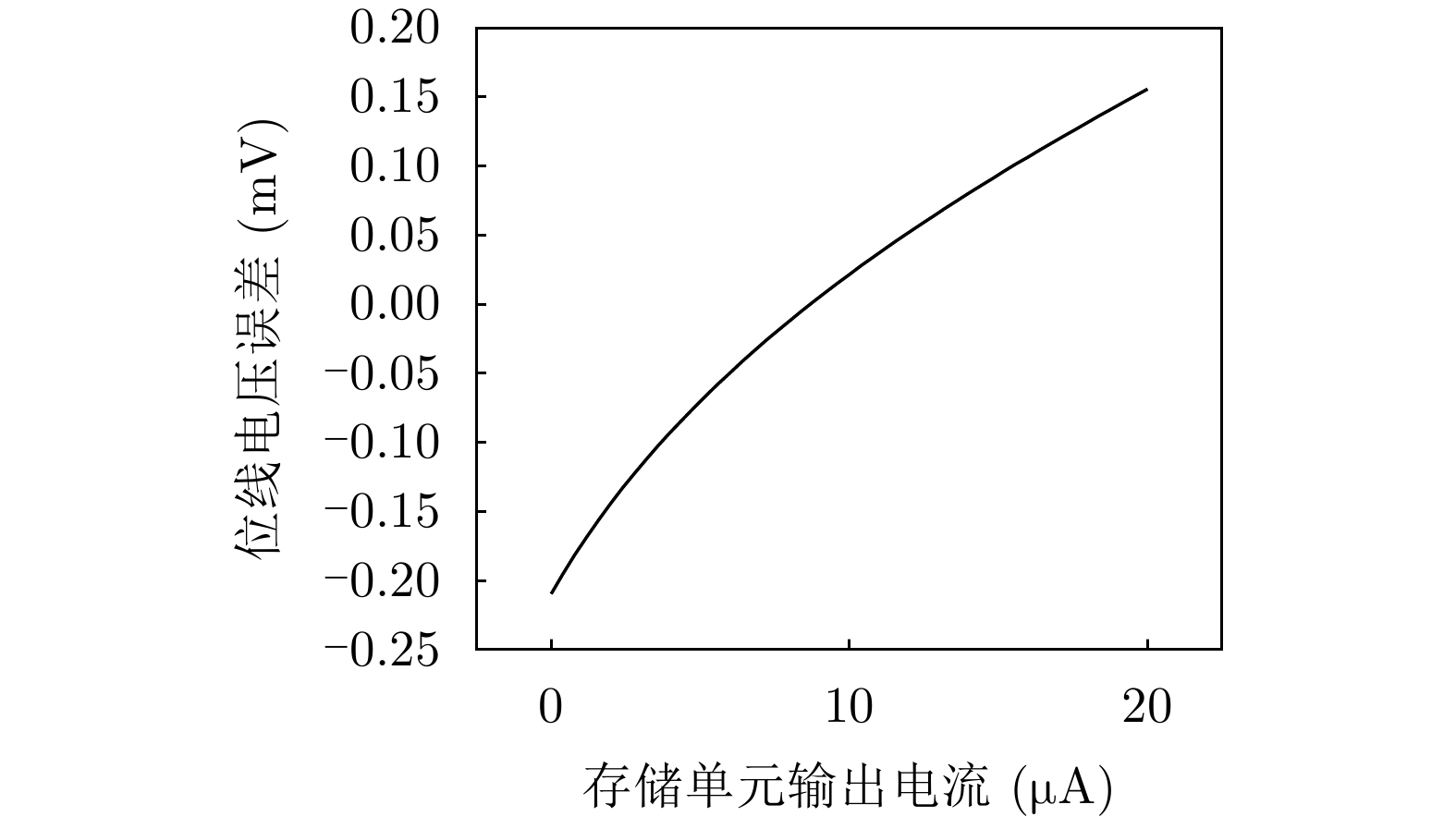
摘要: 该文面向基于闪存(Flash)的脉冲卷积神经网络(SCNN)提出一种积分发放(IF)型模拟神经元电路,该电路实现了位线电压箝位、电流读出减法和积分发放功能。为解决低电流读出速度较慢的问题,该文设计一种通过增加旁路电流大幅提高电流读出范围和读出速度的方法;针对传统模拟神经元复位方案造成的阵列信息丢失问题,提出一种固定泄放阈值电压的脉冲神经元复位方案,提高了阵列电流信息的完整性和神经网络的精度。基于55 nm 互补金属氧化物半导体(CMOS)工艺对电路进行设计并流片。后仿结果表明,在20 μA电流输出时,读出速度提高了100%,在0 μA电流输出时,读出速度提升了263.6%,神经元电路工作状态良好。测试结果表明,在0~20 μA电流输出范围内,箝位电压误差小于0.2 mV,波动范围小于0.4 mV,电流读出减法线性度可达到99.9%。为了研究所提模拟神经元电路的性能,分别通过LeNet和AlexNet对MNIST和CIFAR-10数据集进行识别准确率测试,结果表明,神经网络识别准确率分别提升了1.4%和38.8%。Abstract: In this paper, an Integrate-and-Fire (IF) analog readout neuron circuit is proposed for Spiking Convolutional Neural Network (SCNN) based on flash array. The circuit realizes the following functions: bit line voltage clamping, current readout, current subtraction, and integrate-and-fire. A current readout method is proposed to improve the current readout range and speed by increasing by-pass current. To avoid the loss of array information caused by the traditional analog neuron reset scheme, a reset scheme with subtracting threshold voltage is proposed, which improves the integrity of information and the accuracy of the neural network. The circuit is implemented in 55 nm Complementary Metal Oxide Semiconductor (CMOS) process. Simulation results show that when output current is 20 μA and 0 μA, the read speed can be accelerated 100% and 263.6% respectively; The neuron circuit works well. And test results show that, in the current output range of 0~20 μA, the clamp voltage error is less than 0.2 mV and the fluctuation is less than 0.4 mV; The linearity of current subtraction can reach 99.9%. To study the performance of the analog neuron circuit, LeNet and AlexNet algorithm with circuit model for the recognition of the MNIST and CIFAR-10 database is tested. Test results illustrate that the neural network accuracy is improved by 1.4% and 38.8%.
-
表 2 位线箝位电压误差(mV)
PVT 0 μA 20 μA 测试 –0.20 0.15 tt(25°C) –0.16 0.12 ss(80°C) –0.23 0.18 ff(–20°C) –0.11 0.10  下载: 导出CSV
下载: 导出CSV
-
[1] LECUN Y, BENGIO Y, and HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436–444. doi: 10.1038/nature14539 [2] MOONS B and VERHELST M. A 0.3–2.6 TOPS/W precision-scalable processor for real-time large-scale ConvNets[C]. 2016 IEEE Symposium on VLSI Circuits, Honolulu, USA, 2016: 1–2. [3] CHIU C C, SAINATH T N, WU Yonghui, et al. State-of-the-art speech recognition with sequence-to-sequence models[C]. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, Canada, 2018: 4774–4778. [4] KANG J F, GAO B, HUANG P, et al. Oxide-based RRAM: Requirements and challenges of modeling and simulation[C]. 2015 IEEE International Electron Devices Meeting, Washington, USA, 2015: 5.4. 1–5.4. 4. [5] TANG Tianqi, XIA Lixue, LI Boxun, et al. Binary convolutional neural network on RRAM[C]. The 2017 22nd Asia and South Pacific Design Automation Conference, Chiba, Japan, 2017: 782–787. [6] CHUNG S W, KISHI T, PARK J W, et al. 4Gbit density STT-MRAM using perpendicular MTJ realized with compact cell structure[C]. 2016 IEEE International Electron Devices Meeting, San Francisco, USA, 2016: 27.1. 1–27.1. 4. [7] BEZ R, CAMERLENGHI E, MODELLI A, et al. Introduction to flash memory[J]. Proceedings of the IEEE, 2003, 91(4): 489–502. doi: 10.1109/JPROC.2003.811702 [8] HAN Runze, HUANG Peng, XIANG Yachen, et al. A novel convolution computing paradigm based on NOR flash array with high computing speed and energy efficiency[J]. IEEE Transactions on Circuits and Systems I:Regular Papers, 2019, 66(5): 1692–1703. doi: 10.1109/TCSI.2018.2885574 [9] GUO X, MERRIKH BAYAT F, BAVANDPOUR M, et al. Fast, energy-efficient, robust, and reproducible mixed-signal neuromorphic classifier based on embedded NOR flash memory technology[C]. 2017 IEEE International Electron Devices Meeting, San Francisco, USA, 2017: 6.5. 1–6.5. 4. [10] CHEN Paiyu, PENG Xiaochen, and YU Shimeng. NeuroSim+: An integrated device-to-algorithm framework for benchmarking synaptic devices and array architectures[C]. 2017 IEEE International Electron Devices Meeting, San Francisco, USA, 2017: 6.1. 1–6.1. 4. [11] EMER J. Design efficient deep learning accelerator: Challenges and opportunities[C]. Kyoto, Japan, VLSI Short Course, 2017: 1–121. [12] MALAVENA G, FILIPPI M, SPINELLI A S, et al. Unsupervised learning by spike-timing-dependent plasticity in a mainstream NOR flash memory array—Part I: Cell operation[J]. IEEE Transactions on Electron Devices, 2019, 66(11): 4727–4732. doi: 10.1109/TED.2019.2940602 [13] HUANG Xiaoyu, JONES E, ZHANG Siru, et al. An FPGA implementation of convolutional spiking neural networks for radioisotope identification[C]. 2021 IEEE International Symposium on Circuits and Systems, Daegu, Korea, 2021: 1–5. [14] XIANG Yachen, HUANG Peng, HAN Runze, et al. Efficient and robust spike-driven deep convolutional neural networks based on NOR flash computing array[J] IEEE Transactions on Electron Devices, 2020, 67(6): 2329–2335. [15] ZHOU Shibo, CHEN Ying, LI Xiaohua, et al. Deep SCNN-based real-time object detection for self-driving vehicles using LiDAR temporal data[J]. IEEE Access, 2020, 8: 76903–76912. doi: 10.1109/ACCESS.2020.2990416 [16] PARK J, KWON M W, KIM H, et al. Compact neuromorphic system with four-terminal Si-based synaptic devices for spiking neural networks[J]. IEEE Transactions on Electron Devices, 2017, 64(5): 2438–2444. doi: 10.1109/TED.2017.2685519 [17] SEO J, MIN K S, KIM D H, et al. A low power integrate and fire neuron circuit for spiking neural network[C]. 2020 International Conference on Electronics, Information, and Communication, Barcelona, Spain, 2020: 1–5. [18] YAN Bonan, YANG Qing, CHEN Weihao, et al. RRAM-based spiking nonvolatile computing-in-memory processing engine with precision-configurable in situ nonlinear activation[C]. 2019 Symposium on VLSI Technology, Kyoto, Japan, 2019: T86–T87. -


 下载:
下载:








图(13) / 表(4)
计量
- 文章访问数: 1180
- HTML全文浏览量: 989
- PDF下载量: 124
- 被引次数: 0
