

Wireless Communications Interference Avoidance Based on Fast Reinforcement Learning
-
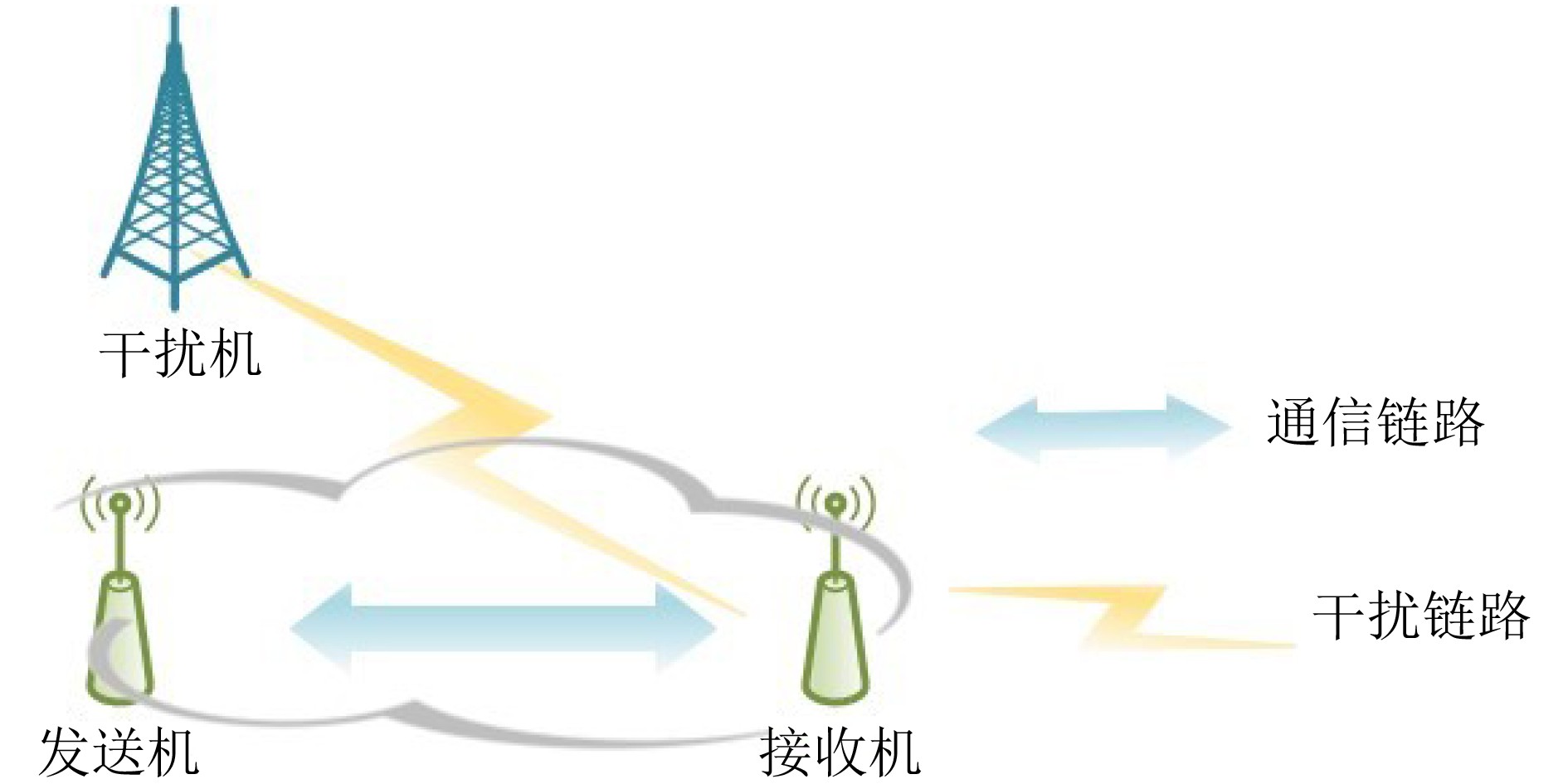
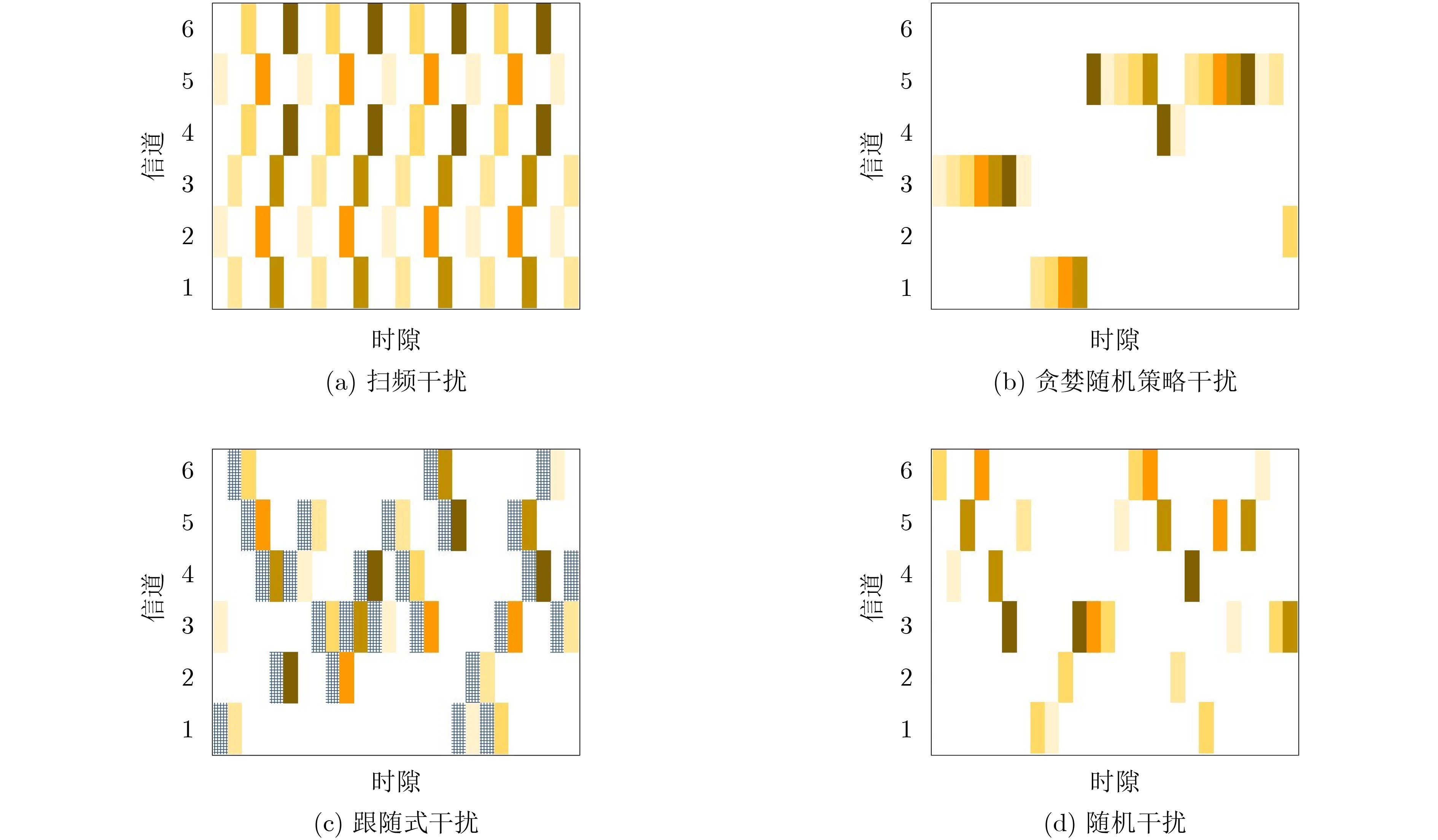
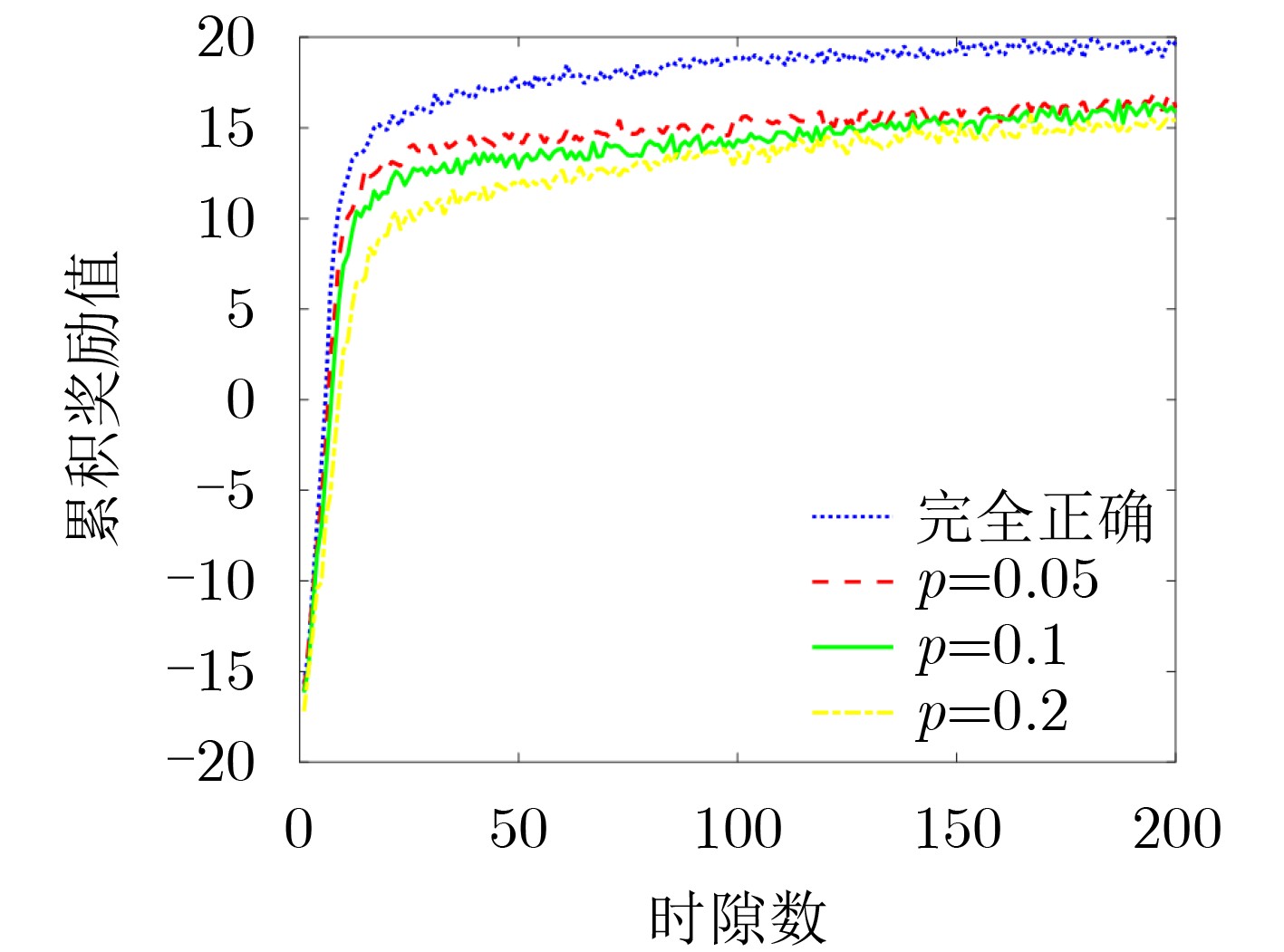
摘要: 针对无线通信环境中存在未知且动态变化的干扰,该文联合考虑通信信道接入和发射功率控制提出了基于快速强化学习的未知干扰规避策略,以确保通信收发端的可靠通信。将干扰规避问题建模为马尔可夫决策过程,其优化目标为在保证通信质量的前提下同时降低系统发射功率和减少信道切换次数。随后,提出一种赢或学习快速策略爬山(WoLF-PHC)学习方法的干扰规避方案,从而实现快速规避干扰的目的。仿真结果表明,在不同干扰模式下,所提WoLF-PHC算法的抗干扰性能、收敛速度均优于传统的随机选择方法和Q学习算法。
-
关键词:
- 干扰规避 /
- 赢或学习快速策略爬山 /
- Q学习 /
- 马尔可夫决策
Abstract: In this article, the unknown and dynamic interference in the wireless communication environment is studied. Jointly considering communication channel access and transmit power control, a fast reinforcement learning strategy is proposed to ensure reliable communication at the transceivers. The interference avoidance problem is firstly modeled as a Markov decision process to lower the transmission power of the system and reduce the number of channel switching while ensuring the communication quality. Subsequently, a Win or Learn Fast Policy Hill-Climbing (WoLF-PHC) learning method is proposed to avoid rapidly interference. Simulation results show that the anti-interference performance and convergence speed of the proposed WoLF-PHC algorithm are superior to the traditional random selection method and Q learning algorithm under different interference situations. -
表 1 基于Q学习的功率和信道选择策略
初始化:设k=0,确定初始状态$ {s^k} = (f_{\text{u}}^k,f_{\text{j}}^k) $,随机选择当前时隙通信信道$f_{\text{u}}^k$,并且进行频谱感知获取当前时隙的干扰信道$f_{\text{j}}^k$以及干扰功
率$ {p_{\text{j}}}^k $;初始化Q表为全0矩阵;设置学习率$\alpha $,折扣因子$\gamma $;学习过程:当$ k < K $时, (1) 利用贪婪策略选取动作$ {a^k} = ({f_{\text{u}}}^{k + 1},{p_{\text{u}}}^{k + 1}) $,然后再根据频谱感知结果,和选取的动作更新下一时隙的状态${s^{k{\text{ + }}1}} = (f_{\text{u}}^{k{\text{ + }}1},f_{\text{j}}^{k{\text{ + }}1})$,
计算出${\text{SIN}}{{\text{R}}^k}$和下一时隙反馈的奖励值$ {R^k} $;(2) 根据式(5),更新Q表,$ k = k + 1 $。  下载: 导出CSV
下载: 导出CSV
表 2 基于WoLF-PHC学习的功率和信道选择策略
初始化:折扣因子$\gamma $,学习率$\alpha $,学习速率${\delta _{\text{l}}}$, ${\delta _{\text{w}}}$;Q表为全0矩阵,$\pi \left( {s,a} \right){\text{ = } }{1}/{ { {\text{|} }A{\text{|} } } }$, $C({{s} }) = 0$; 学习过程:当$ k < K $时, (1) 根据当前策略$\pi (s,a)$和当前状态$s$选择动作$a$; (2) 获取下一时隙的状态$s$并计算$ R $,然后根据式(5),更新Q表; (3) 更新$C({{s} }) \leftarrow C(s) + 1$,再根据式(8)和式(7)更新$\pi (s,a)$和$\bar \pi (s,a)$ (4) $ k{\text{ }} = {\text{ }}k + 1 $。
下载: 导出CSV
表 3 仿真参数
参数 值 信道总数M 6 蒙特卡罗仿真次数${\text{Mont}}$ 1000 时隙数$ {\text{Slots}} $ 10000 学习率$\alpha $ 0.5 折扣因子$\gamma $ 0.9 学习速率${\delta _{\text{l}}}$,${\delta _{\text{w}}}$ 0.1,0.03 信道切换代价${C_{\rm{h}}}$ 0.5 功率代价系数${C_{\rm{p}}}$ 0.5 干扰功率集合${P_{\rm{J}}}$ [2,4,6,8,10,12]×0–3 W 发射功率集合${P_{\rm{U}}}$ [7,14,21,28]×10–3 W 噪声功率${\sigma ^2}$ 10–3 W
下载: 导出CSV
-
[1] ZOU Yulong, ZHU Jia, WANG Xianbin, et al. A survey on wireless security: Technical challenges, recent advances, and future trends[J]. Proceedings of the IEEE, 2016, 104(9): 1727–1765. doi: 10.1109/JPROC.2016.2558521 [2] GROVER K, LIM A, and YANG Qing. Jamming and anti-jamming techniques in wireless networks: A survey[J]. International Journal of Ad Hoc and Ubiquitous Computing, 2014, 17(4): 197–215. doi: 10.1504/IJAHUC.2014.066419 [3] LI Fang, XIONG Jun, ZHAO Xiaodi, et al. An improved FCME algorithm based on differential spectrum envelope for interference detection in satellite communication systems[C]. The 5th International Conference on Computer and Communication Systems (ICCCS), Shanghai, China, 2020: 874–879. [4] SUTTON R S and BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 1998: 216–224. [5] KONG Lijun, XU Yuhua, ZHANG Yuli, et al. A reinforcement learning approach for dynamic spectrum anti-jamming in fading environment[C]. The IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 2018: 51–58. [6] SLIMENI F, CHTOUROU Z, SCHEERS B, et al. Cooperative Q-learning based channel selection for cognitive radio networks[J]. Wireless Networks, 2019, 25(7): 4161–4171. doi: 10.1007/s11276-018-1737-9 [7] WANG Beibei, WU Yongle, LIU K J R, et al. An anti-jamming stochastic game for cognitive radio networks[J]. IEEE Journal on Selected Areas in Communications, 2011, 29(4): 877–889. doi: 10.1109/JSAC.2011.110418 [8] GWON Y, DASTANGOO S, FOSSA C, et al. Competing mobile network game: Embracing antijamming and jamming strategies with reinforcement learning[C]. 2013 IEEE Conference on Communications and Network Security (CNS), National Harbor, USA, 2013: 28–36. [9] SLIMENI F, SCHEERS B, CHTOUROU Z, et al. Jamming mitigation in cognitive radio networks using a modified Q-learning algorithm[C]. 2015 IEEE International Conference on Military Communications and Information Systems (ICMCIS), Cracow, Poland, 2015: 1–7. [10] MPITZIOPOULOS A, GAVALAS D, KONSTANTOPOULOS C, et al. A survey on jamming attacks and countermeasures in WSNs[J]. IEEE Communications Surveys & Tutorials, 2009, 11(4): 42–56. doi: 10.1109/SURV.2009.090404 [11] ZHANG Yuli, XU Yuhua, XU Yitao, et al. A multi-leader one-follower stackelberg game approach for cooperative anti-jamming: No Pains, No Gains[J]. IEEE Communications Letters, 2018, 22(8): 1680–1683. doi: 10.1109/LCOMM.2018.2843374 [12] HANAWAL M K, ABDEL-RAHMAN M J, and KRUNZ M. Joint adaptation of frequency hopping and transmission rate for anti-jamming wireless systems[J]. IEEE Transactions on Mobile Computing, 2016, 15(9): 2247–2259. doi: 10.1109/TMC.2015.2492556 [13] HANAWAL M K, ABDEL-RAHMAN M J, and KRUNZ M. Game theoretic anti-jamming dynamic frequency hopping and rate adaptation in wireless systems[C]. The 12th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt), Hammamet, Tunisia, 2014: 247–254. [14] LI Yangyang, XU Yitao, WANG Ximing, et al. Power and frequency selection optimization in anti-jamming communication: A deep reinforcement learning approach[C]. The IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 2019: 815–820. [15] XIAO Liang, JIANG Donghua, XU Dongjin, et al. Two-dimensional antijamming mobile communication based on reinforcement learning[J]. IEEE Transactions on Vehicular Technology, 2018, 67(10): 9499–9512. doi: 10.1109/TVT.2018.2856854 [16] PEI Xufang, WANG Ximing, YAO Junnan, et al. Joint time-frequency anti-jamming communications: A reinforcement learning approach[C]. The 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi'an, China, 2019: 1–6. [17] BOWLING M and VELOSO M. Multiagent learning using a variable learning rate[J]. Artificial Intelligence, 2002, 136(2): 215–250. doi: 10.1016/S0004-3702(02)00121-2 -

 下载:
下载:



图(4) / 表(3)
计量
- 文章访问数: 1393
- HTML全文浏览量: 1755
- PDF下载量: 246
- 被引次数: 0
