

A Virtual Network Function Migration Algorithm Based on Federated Learning Prediction of Resource Requirements
-
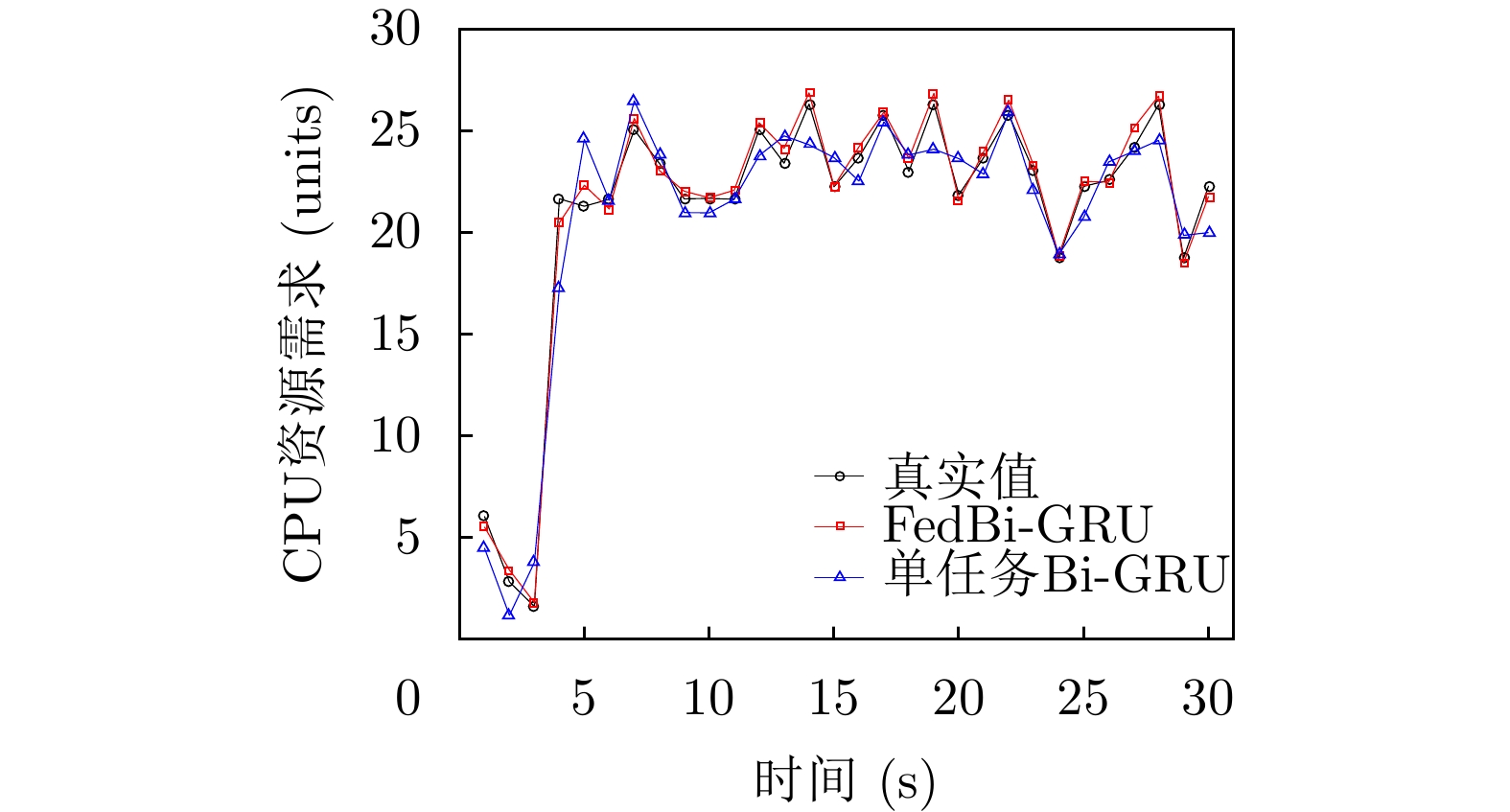
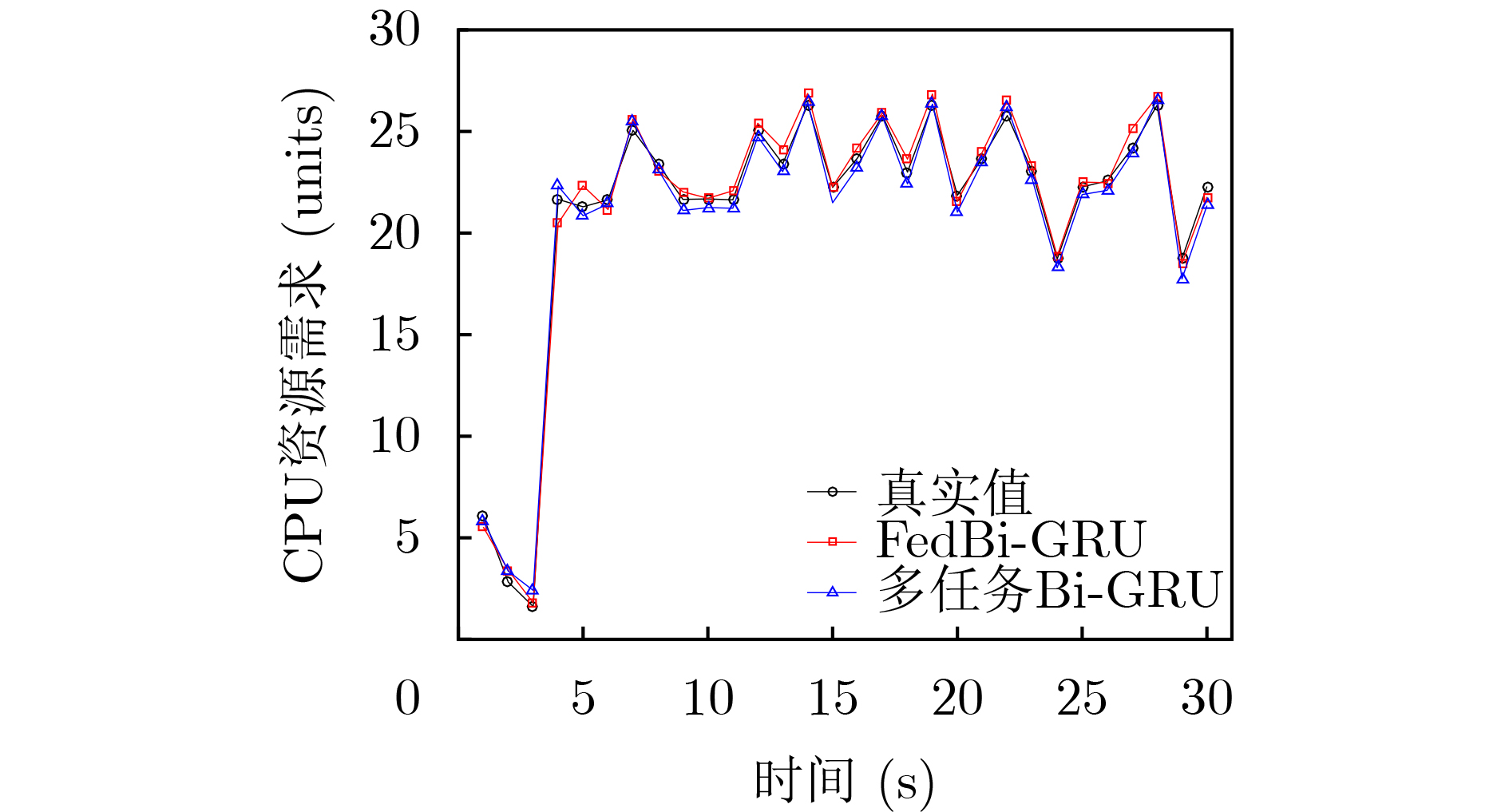
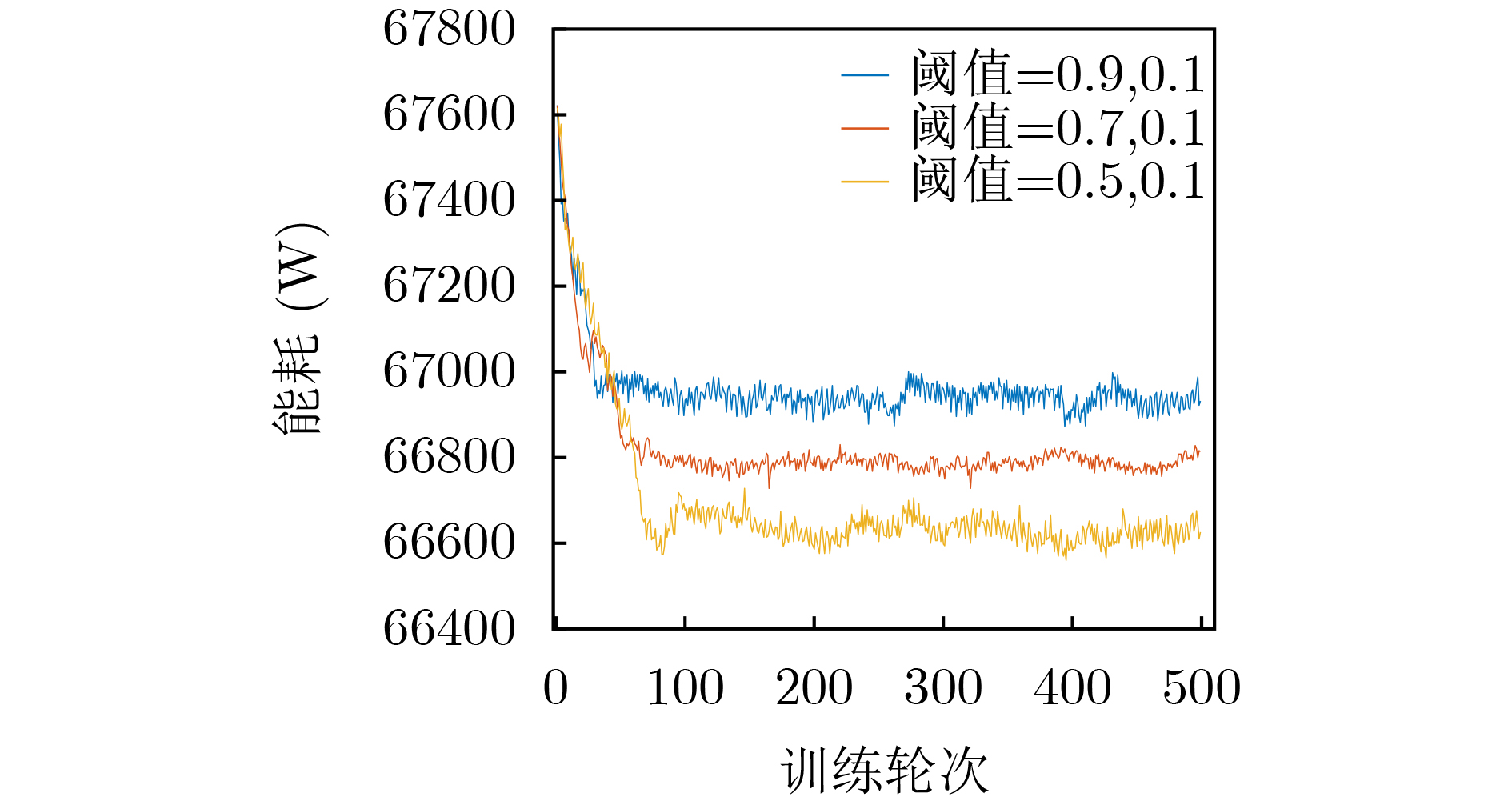
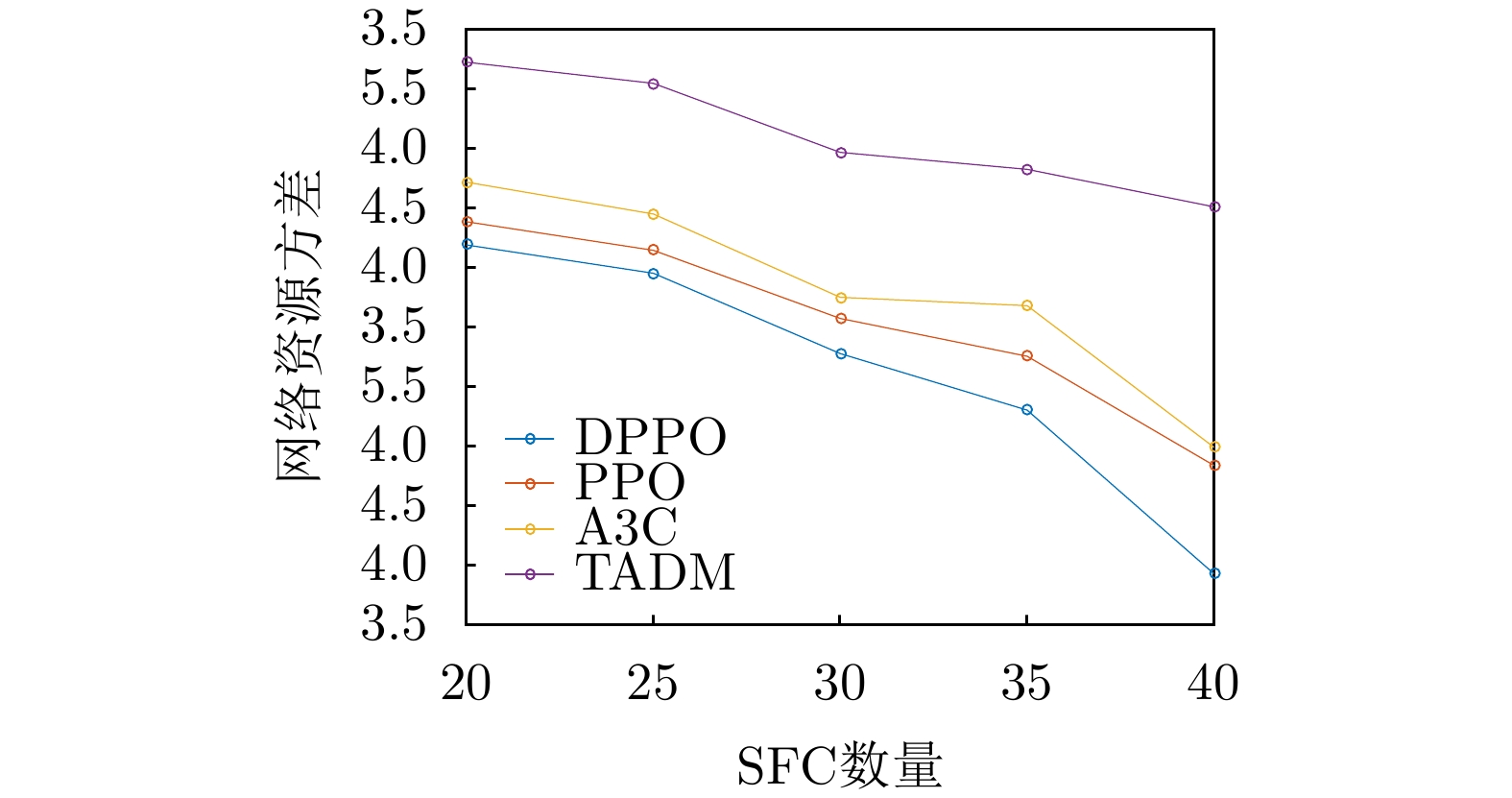
摘要: 针对网络切片场景下时变网络流量引起的虚拟网络功能(VNF)迁移问题,该文提出一种基于联邦学习的双向门控循环单元(FedBi-GRU)资源需求预测的VNF迁移算法。该算法首先建立系统能耗和负载均衡的VNF迁移模型,然后提出一种基于分布式联邦学习框架协作训练预测模型,并在此框架的基础上设计基于在线训练的双向门控循环单元(Bi-GRU)算法预测VNF的资源需求。基于资源预测结果,联合系统能耗优化和负载均衡,提出一种分布式近端策略优化(DPPO)的迁移算法提前制定VNF迁移策略。仿真结果表明,两种算法的结合有效地降低了网络系统能耗并保证负载均衡。Abstract: In order to solve the problem of virtual network function migration caused by time-varying network traffic in network slicing, a Virtual Network Function (VNF) migration algorithm based on Federated learning with Bidirectional Gate Recurrent Units (FedBi-GRU) prediction of resource requirements is proposed. Firstly, a VNF migration model of system energy consumption and load balancing is established, and then a framework based on distributed federated learning is introduced to cooperatively train the predictive model. Secondly, considering predicting the resource requirements of VNF, an online training Bidirectional Gate Recurrent Unit (Bi-GRU) algorithm on the basis of the framework is designed. Finally, on the grounds of the resource prediction results, system energy consumption optimization and load balancing are combined, and a Distributed Proximal Policy Optimization (DPPO) migration algorithm is proposed to formulate a VNF migration strategy in advance. The simulation results show that the combination of the two algorithms reduces effectively the energy consumption of the network system and ensures the load balance.
-
Key words:
- Virtual Network Function(VNF) /
- Prediction /
- Migration /
- Deep reinforcement learning
-
表 1 基于DDPO的VNF迁移算法
输入:VNF的资源需求预测结果$ {r_{t + 1}} = \{ r_{t + 1}^{\text{C}},r_{t + 1}^{\text{M}},r_{t + 1}^{\text{B}}\} $,物理网络图$ {G^{\text{P}}} = ({N^{\text{P}}},{L^{\text{P}}}) $,SFC网络图$ G_i^{\text{V}} = (N_i^{\text{V}},L_i^{\text{V}}) $ 输出:VNF映射策略$ \pi $ (1) 根据VNF的资源需求预测结果,计算各个物理节点的资源利用率${\eta _{\rm{R}}}$ (2) if ${\eta _{\rm{R} } } \le \eta _{\rm{R} }^{\text{d} }\& \& {\eta _{\rm{R} } } \ge \eta _{\rm{R}}^{ {\text{up} } }$ then (3) 初始化全局参数$ ({\theta _{\text{c}}},{\theta _{\text{a}}}) $,局部参数$ (\theta _{\text{c}}^n,\theta _{\text{a}}^n) $,全局PPO网络最大迭代次数$ {K_{{\text{max}}}} $,局部PPO网络最大迭代次数$ M $,线程数$ N $,学习率
$ ({\varepsilon _{\text{c}}},{\varepsilon _{\text{a}}}) $(4) for ${\text{thread} } = 1, 2,\cdots ,N$ do (5) for ${\text{episode} } = 1,2, \cdots ,M$ do (6) 从本地Actor网络的策略$ \pi ({s_n}(t)\left| {{a_n}(t),\theta _{\text{a}}^n} \right.) $中选取映射动作$ a(t) $ (7) if $ {\eta _1} \in (\eta _1^{\text{d}},\eta _1^{{\text{up}}})\& \& {\eta _2} \in (\eta _2^{\text{d}},\eta _2^{{\text{up}}})\& \& {\eta _3} \in (\eta _3^{\text{d}},\eta _3^{{\text{up}}})\& \& T \le {T_{{\text{tot}}}} $ then (8) 执行动作$ a(t) $,根据式(16)得到瞬时奖励$ r(t) $,并转移到状态$ s(t + 1) $ (9) 从本地Actor网络获得优势函数$ A({s_n}(t),{a_n}(t)) $ (10) else (11) 式(16)瞬时奖励$ r(t) = - {1 \mathord{\left/ {\vphantom {1 \varepsilon }} \right. } \varepsilon } $,从本地${\rm{Actor}}$网络重新选取动作$ a(t) $ (12) end if (13) end for (14) 根据式(24)更新全局PPO的Critic网络累计梯度$ \Delta {\theta _{\text{c}}} $ (15) 根据式(26)更新全局PPO的Actor网络累计梯度$ \Delta {\theta _{\text{a}}} $ (16) 将$ \Delta {\theta _{\text{c}}} $和$ \Delta {\theta _a} $推送至全局PPO网络进行异步更新 (17) $ {\theta _{\text{c}}} \leftarrow {\theta _{\text{c}}} + {\varepsilon _{\text{c}}}\Delta {\theta _{\text{c}}} $,$ {\theta _{\text{a}}} \leftarrow {\theta _{\text{a}}} + {\varepsilon _{\text{a}}}\Delta {\theta _{\text{a}}} $ (18) end for (19) 同步全局PPO网络参数至本地PPO网络参数:$ \theta _{\text{c}}^{n'} = {\theta _{\text{c}}} $, $ \theta {_{\text{a}}^{n'}} = \theta _{\text{a}}^{} $ (20) 继续执行步骤4—步骤17 (21) until $ K \ge {K_{{\text{max}}}} $ (22) end if  下载: 导出CSV
下载: 导出CSV
表 2 仿真参数
仿真参数 描述 取值 $ {N^{\text{P}}} $ 物理节点数量 22 $ P_n^{\text{b}} $ 物理节点待机能耗 Uniform[100,150](W) $ P_n^{{\text{cpu}}} $ 物理节点CPU满载能耗 Uniform[250,300](W) $ P_m^{\text{s}} $ 物理节点状态切换能耗 Uniform[15,25](W) $ {C_n} $ 物理节点CPU资源容量 Uniform[200,300](units) $ {M_n} $ 物理节点存储资源容量 Uniform[300,400](Mbps) $ {B_{nm}} $ 物理链路$ {l_{nm}} $带宽容量 Uniform[80,100](Mbps) $ F $ SFC集合数量 30个 $ N_i^{\text{V}} $ VNF集合长度 Uniform[3,5](个) $ {T_{{\text{tot}}}} $ SFC端到端时延限制 30 ms
下载: 导出CSV
-
[1] LI Defang, HONG Peilin, XUE Kaiping, et al. Availability aware VNF deployment in datacenter through shared redundancy and multi-tenancy[J]. IEEE Transactions on Network and Service Management, 2019, 16(4): 1651–1664. doi: 10.1109/TNSM.2019.2936505 [2] QU Kaige, ZHUANG Weihua, YE Qiang, et al. Dynamic flow migration for embedded services in SDN/NFV-enabled 5G core networks[J]. IEEE Transactions on Communications, 2020, 68(4): 2394–2408. doi: 10.1109/TCOMM.2020.2968907 [3] LIU Yicen, LU Hao, LI Xi, et al. An approach for service function chain reconfiguration in network function virtualization architectures[J]. IEEE Access, 2019, 7: 147224–147237. doi: 10.1109/ACCESS.2019.2946648 [4] TANG Lun, HE Xiaoyu, ZHAO Peipei, et al. Virtual network function migration based on dynamic resource requirements prediction[J]. IEEE Access, 2019, 7: 112348–112362. doi: 10.1109/ACCESS.2019.2935014 [5] LIU Yicen, LU Yu, LI Xi, et al. On dynamic service function chain reconfiguration in IoT networks[J]. IEEE Internet of Things Journal, 2020, 7(11): 10969–10984. doi: 10.1109/JIOT.2020.2991753 [6] HUANG Yuzhe, XU Huahu, GAO Honghao, et al. SSUR: An approach to optimizing virtual machine allocation strategy based on user requirements for cloud data center[J]. IEEE Transactions on Green Communications and Networking, 2021, 5(2): 670–681. doi: 10.1109/TGCN.2021.3067374 [7] DAYARATHNA M, WEN Yonggang, and FAN Rui. Data center energy consumption modeling: A survey[J]. IEEE Communications Surveys & Tutorials, 2015, 18(1): 732–794. doi: 10.1109/COMST.2015.2481183 [8] ERAMO V, AMMAR M, and LAVACCA F G. Migration energy aware reconfigurations of virtual network function instances in NFV architectures[J]. IEEE Access, 2017, 5: 4927–4938. doi: 10.1109/ACCESS.2017.2685437 [9] HAN Zhenhua, TAN Haisheng, WANG Rui, et al. Energy-efficient dynamic virtual machine management in data centers[J]. IEEE/ACM Transactions on Networking, 2019, 27(1): 344–360. doi: 10.1109/TNET.2019.2891787 [10] ZHANG Zhongbao, CAO Huafeng, SU Sen, et al. Energy aware virtual network migration[J]. IEEE Transactions on Cloud Computing, 2022, 10(2): 1173–1189. doi: 10.1109/TCC.2020.2976966. [11] GUO Zehua, XU Yang, LIU Yafeng, et al. AggreFlow: Achieving power efficiency, load balancing, and quality of service in data center networks[J]. IEEE/ACM Transactions on Networking, 2020, 29(1): 17–33. doi: 10.1109/TNET.2020.3026015 [12] LI Biyi, CHENG Bo, LIU Xuan, et al. Joint resource optimization and delay-aware virtual network function migration in data center networks[J]. IEEE Transactions on Network and Service Management, 2021, 18(3): 2960–2974. doi: 10.1109/TNSM.2021.3067883 [13] ZHANG Kunpeng, WU Lan, ZHU Zhaoju, et al. A multitask learning model for traffic flow and speed forecasting[J]. IEEE Access, 2020, 8: 80707–80715. doi: 10.1109/ACCESS.2020.2990958 [14] LIU Yi, JAMES J J Q, KANG Jiawen, et al. Privacy-preserving traffic flow prediction: A federated learning approach[J]. IEEE Internet of Things Journal, 2020, 7(8): 7751–7763. doi: 10.1109/JIOT.2020.2991401 [15] ZHANG Zhenyu, LUO Xiangfeng, LIU Tong, et al. Proximal policy optimization with mixed distributed training[C]. The 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, USA, 2019: 1452–1456. [16] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv: 1707.06347, 2017. [17] BEN YAHIA I G, BENDRISS J, SAMBA A, et al. CogNitive 5G networks: Comprehensive operator use cases with machine learning for management operations[C]. 2017 20th Conference on Innovations in Clouds, Internet and Networks (ICIN), Paris, France, 2017: 252–259. [18] BENDRISS J, BEN YAHIA I G, and ZEGHLACHE D. Forecasting and anticipating SLO breaches in programmable networks[C]. 2017 20th Conference on Innovations in Clouds, Internet and Networks (ICIN), Paris, France, 2017: 127–134. [19] BENDRISS J. Cognitive management of SLA in software-based networks[D]. [Ph. D. dissertation], Institut National des Télécommunications, 2018. -


 下载:
下载:




图(7) / 表(2)
计量
- 文章访问数: 1470
- HTML全文浏览量: 1148
- PDF下载量: 181
- 被引次数: 0
