

Image Steganography Detection Based on Multilayer Perceptual Convolution and Channel Weighting
-
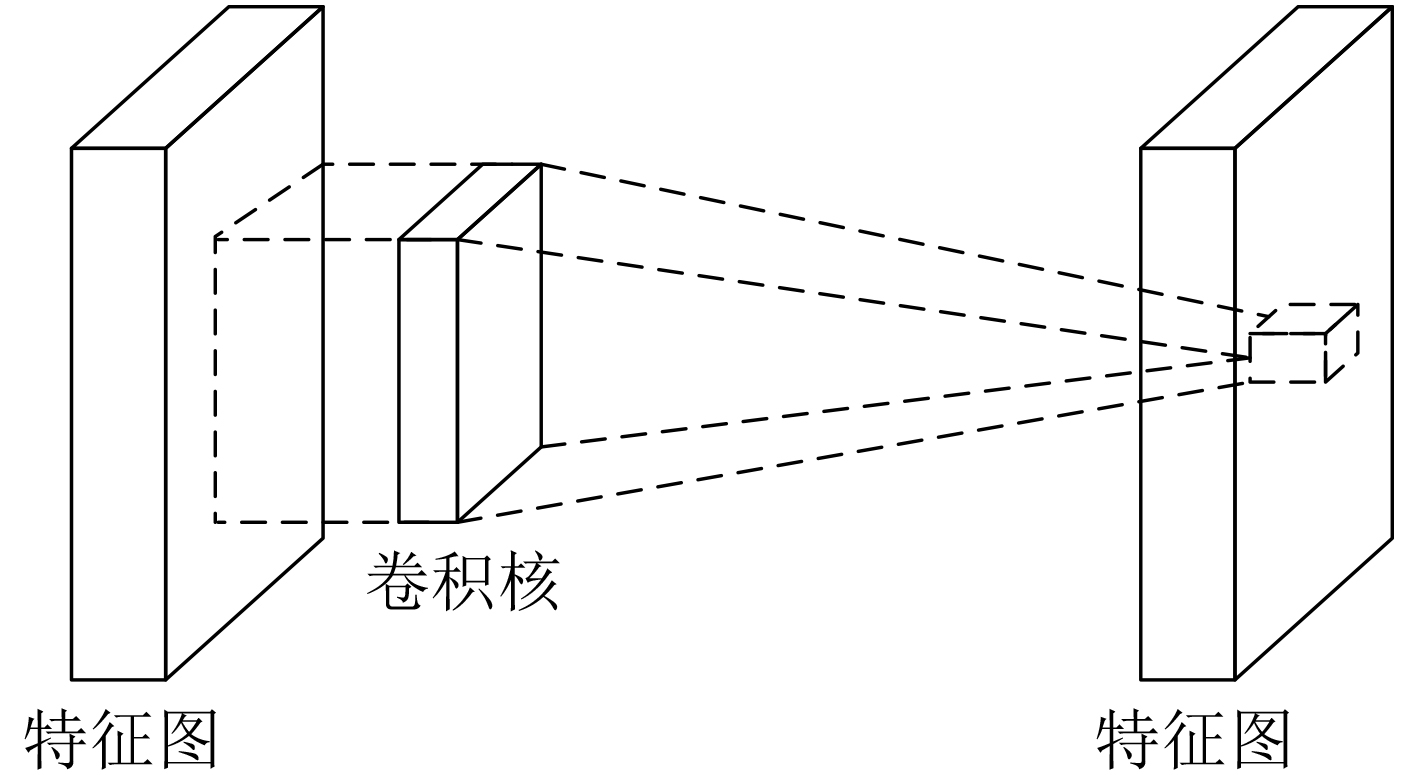
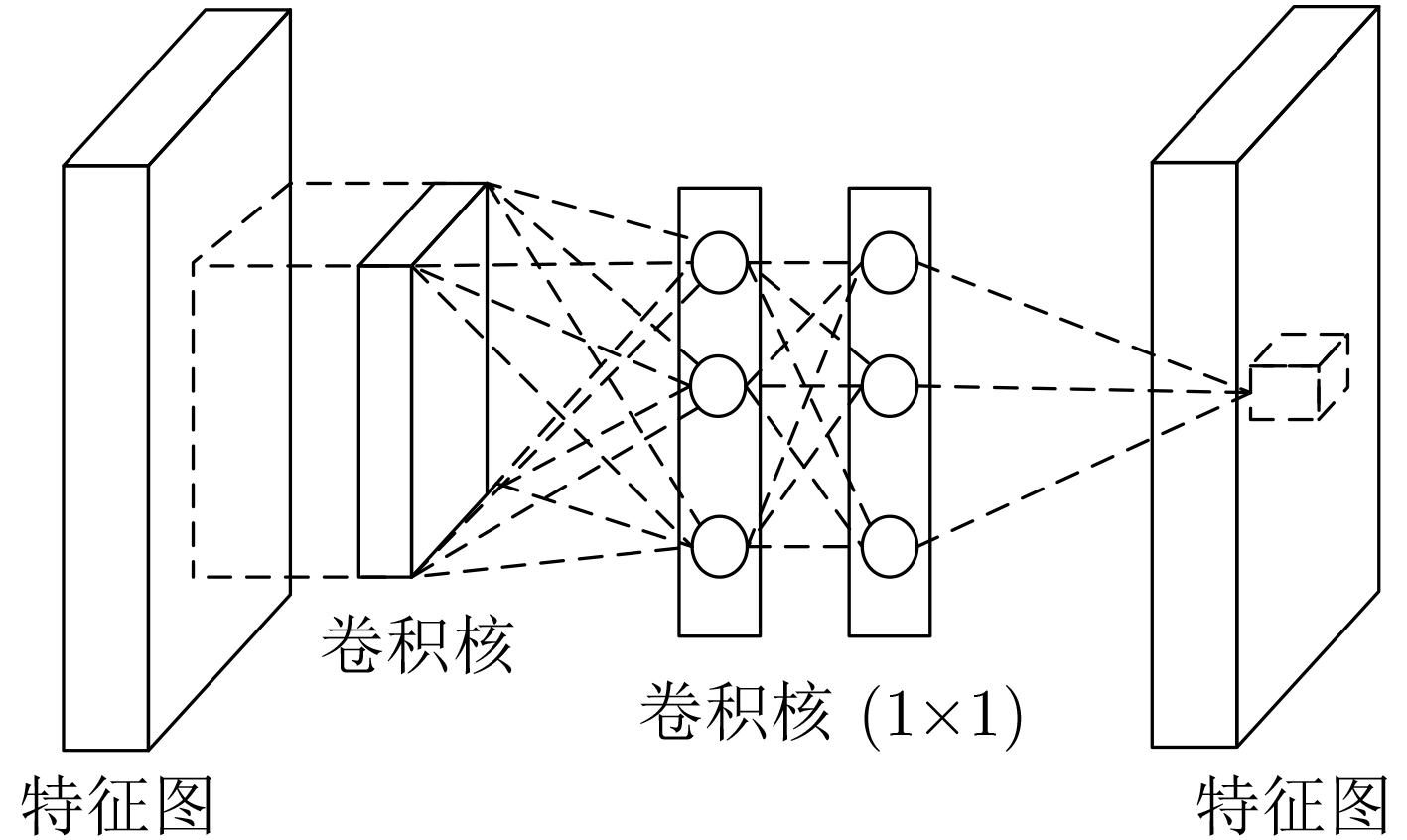
摘要: 针对目前图像隐写检测模型中线性卷积层对高阶特征表达能力有限,以及各通道特征图没有区分的问题,该文构建了一个基于多层感知卷积和通道加权的卷积神经网络(CNN)隐写检测模型。该模型使用多层感知卷积(Mlpconv)代替传统的线性卷积,增强隐写检测模型对高阶特征的表达能力;同时引入通道加权模块,实现根据全局信息对每个卷积通道赋予不同的权重,增强有用特征并抑制无用特征,增强模型提取检测特征的质量。实验结果表明,该检测模型针对不同典型隐写算法及不同嵌入率,相比Xu-Net, Yedroudj-Net, Zhang-Net均有更高的检测准确率,与最优的Zhu-Net相比,准确率提高1.95%~6.15%。Abstract: For steganalysis, many studies have shown that convolutional neural networks have better performance than traditional artificially designed features. However, the ability of linear convolution layer to express higher-order features is limited and the feature map of each channel is not distinguished in the existing detection model which based on Convolutional Neural Networks (CNN). To solve these problems, an image steganography detection model based on Multi-layer perceptual convolution and channel weighting is constructed in this paper. The Multi-layer perceptual convolution layer (Mlpconv)is used to replace the traditional linear convolution layer to enhance the expressiveness ability of high-order features of the detection model. The channel weighting module is added to the model, which assigns different weights to each convolution channel based on global information, so that the useful features can be enhanced and the useless features can be suppressed, and the detection features extracted from the quality model can be improved. The experimental results show that the detection accuracy of proposed detection model is higher than that of Xu-Net, Yedroudj-Net, and Zhang-Net for different typical steganography algorithms and different embedding rates. And compared with the optimal Zhu-Net, the accuracy rate is increased by 1.95~6.15%.
-
表 1 Yedroudj-Net[12]修改预处理层前后准确率(%)
检测模型 WOW S-UNIWARD 0.2 bpp 0.4 bpp 0.2 bpp 0.4 bpp Yedroudj-Net[12] 72.20 85.90 63.30 77.20 改进预处理层的Yedroudj-Net 77.21 87.54 68.81 81.91  下载: 导出CSV
下载: 导出CSV
表 3 通道加权前后模型的检测准确率(%)
本文模型 WOW S-UNIWARD 0.2bpp 0.4bpp 0.2bpp 0.4bpp 通道加权前 80.72 89.59 76.94 87.66 通道加权后 81.25 90.15 77.65 88.10
下载: 导出CSV
-
[1] LIU Jia, KE Yan, ZHANG Zhuo, et al. Recent advances of image steganography with generative adversarial networks[J]. IEEE Access, 2020, 8: 60575–60597. doi: 10.1109/ACCESS.2020.2983175 [2] PEVNY T, BAS P, and FRIDRICH J. Steganalysis by subtractive pixel adjacency matrix[J]. IEEE Transactions on information Forensics and Security, 2010, 5(2): 215–224. doi: 10.1109/TIFS.2010.2045842 [3] FRIDRICH J and KODOVSKY J. Rich models for steganalysis of digital images[J]. IEEE Transactions on Information Forensics and Security, 2012, 7(3): 868–882. doi: 10.1109/tifs.2012.2190402 [4] 付章杰, 李恩露, 程旭, 等. 基于深度学习的图像隐写研究进展[J]. 计算机研究与发展, 2021, 58(3): 548–568. doi: 10.7544/issn1000-1239.2021.20200360FU Zhangjie, LI Enlu, CHENG Xu, et al. Recent advances in image steganography based on deep learning[J]. Computer Research and Development, 2021, 58(3): 548–568. doi: 10.7544/issn1000-1239.2021.20200360 [5] SHARIFZADEH M, ALORAINI M, and SCHONFELD D. Adaptive batch size image merging steganography and quantized Gaussian image steganography[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 867–879. doi: 10.1109/TIFS.2019.2929441 [6] LAISHRAM D and TUITHUNG T. A novel minimal distortion-based edge adaptive image steganography scheme using local complexity[J]. Multimedia Tools and Applications, 2021, 80(1): 831–854. doi: 10.1007/S11042-020-09519-9 [7] 陈君夫, 付章杰, 张卫明, 等. 基于深度学习的图像隐写分析综述[J]. 软件学报, 2021, 32(2): 551–578. doi: 10.13328/j.cnki.jos.006135CHEN Junfu, FU Zhangjie, ZHANG Weiming, et al. Review of image steganalysis based on deep learning[J]. Journal of Software, 2021, 32(2): 551–578. doi: 10.13328/j.cnki.jos.006135 [8] TAN Shunquan and LI Bin. Stacked convolutional auto-encoders for steganalysis of digital images[C]. Signal and Information Processing Association Annual Summit and Conference (APSIPA), 2014 Asia-Pacific, Siem Reap, Cambodia, 2014: 1–4. [9] QIAN Yinlong, DONG Jing, WANG Wei, et al. Deep learning for steganalysis via convolutional neural networks[J]. SPIE, 2015, 9409. [10] XU Guanshuo, WU Hanzhou, and SHI Yunqing. Structural design of convolutional neural networks for steganalysis[J]. IEEE Signal Processing Letters, 2016, 23(5): 708–712. doi: 10.1109/LSP.2016.2548421 [11] YE Jian, NI Jiangqun, and YI Yang. Deep learning hierarchical representations for image steganalysis[J]. IEEE Transactions on Information Forensics and Security, 2017, 12(11): 2545–2557. doi: 10.1109/TIFS.2017.2710946 [12] YEDROUDJ M, COMBY F, and CHAUMONT M. Yedrouj-Net: An efficient CNN for spatial steganalysis[C]. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 2018: 2092–2096. [13] ZHANG Ru, ZHU Feng, LIU Jianyi, et al. Depth-wise separable convolutions and multi-level pooling for an efficient spatial CNN-based steganalysis[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 1138–1150. doi: 10.1109/TIFS.2019.2936913 [14] HOLUB V and FRIDRICH J. Designing steganographic distortion using directional filters[C]. 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Costa Adeje, Spain, 2012: 234–239. [15] HOLUB V, FRIDRICH J, and DENEMARK T. Universal distortion function for steganography in an arbitrary domain[J]. EURASIP Journal on Information Security, 2014, 2014: 1. doi: 10.1186/1687-417X-2014-1 [16] MEMISEVIC R, ZACH C, HINTON G E, et al. Gated softmax classification[C]. The 23rd International Conference on Neural Information Processing Systems, Red Hook, USA, 2010: 1603–1611. [17] LIN Min, CHEN Qiang, and YAN Shuicheng. Network in network[Z]. ArXiv: 1312.4400, 2013. [18] HU JIE, SHEN Li, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011–2023. doi: 10.1109/TPAMI.2019.2913372 [19] BAS P, FILLER T, and TOMÁS PEVNÝ T. “Break Our Steganographic System”: The ins and outs of organizing BOSS[C]. Information Hiding 13th International Conference, Prague, Czech Republic, 2011: 59–70. [20] GLOROT X and BENGIO Y. Understanding the difficulty of training deep feedforward neural networks[J]. Journal of Machine Learning Research, 2010, 9: 249–256. -


 下载:
下载:






图(7) / 表(3)
计量
- 文章访问数: 1497
- HTML全文浏览量: 1132
- PDF下载量: 97
- 被引次数: 0
