

Research on Concurrent Transmission Control of Heterogeneous Wireless Links Based on Adaptive Network Coding
-
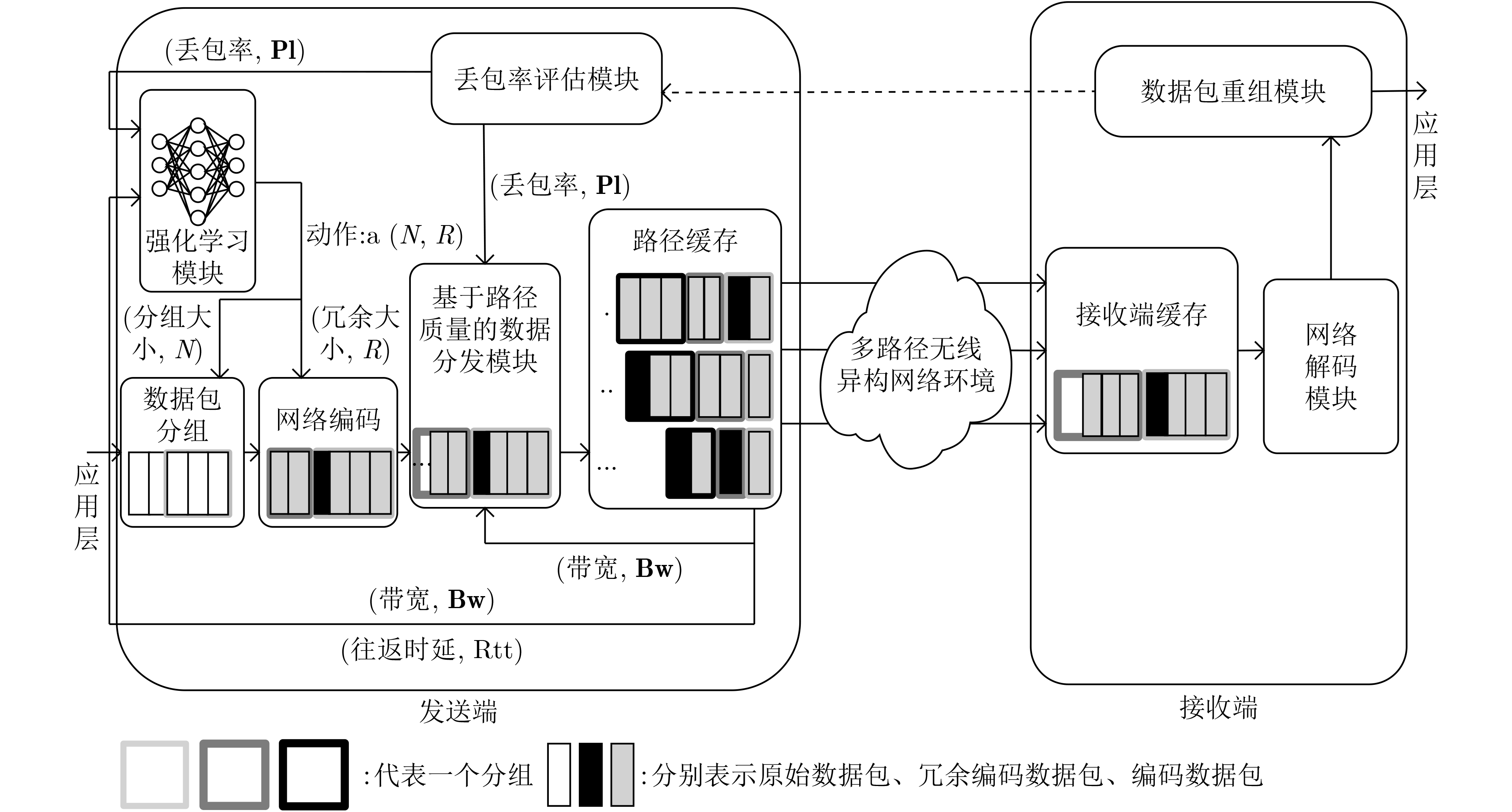
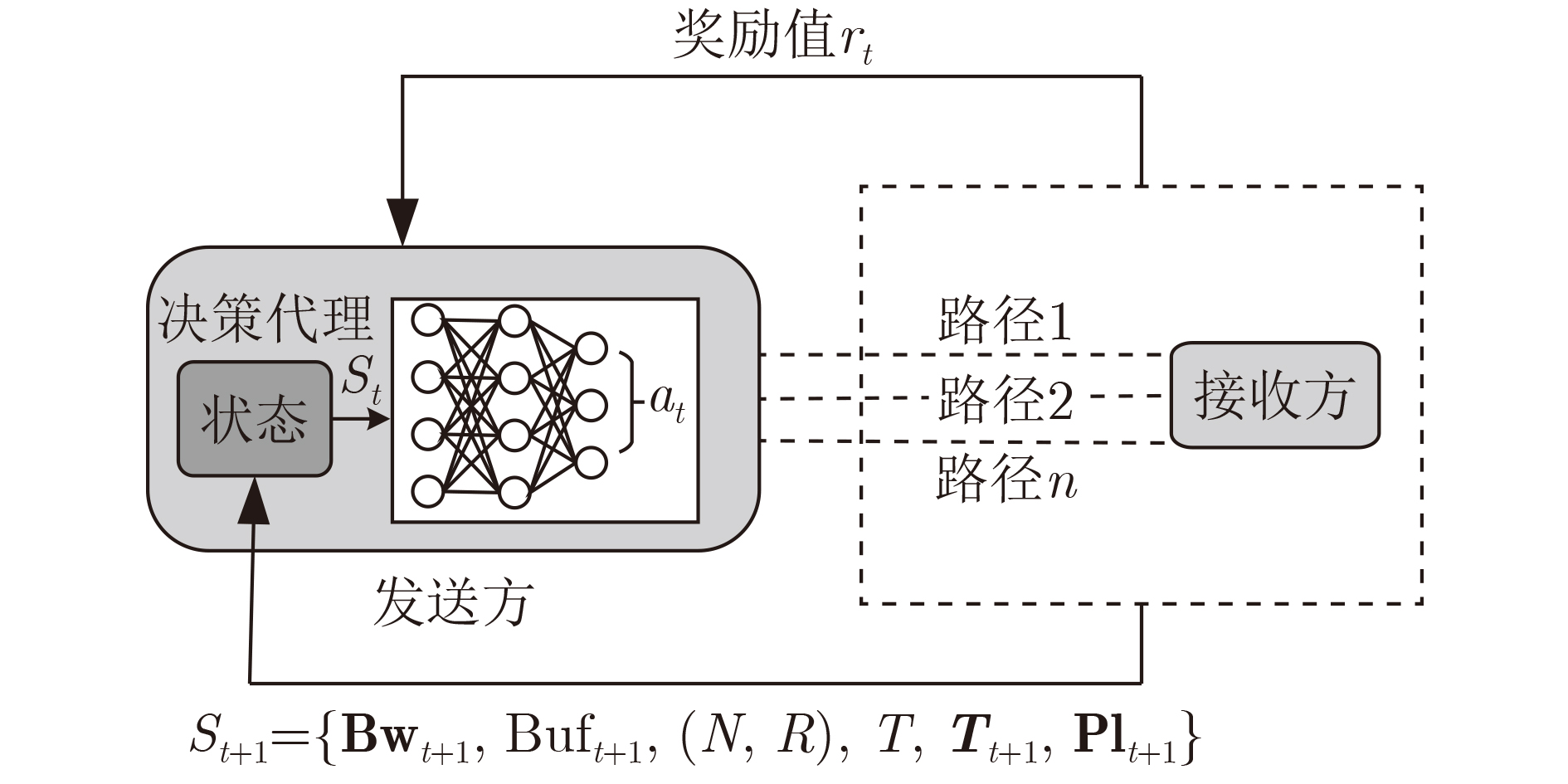
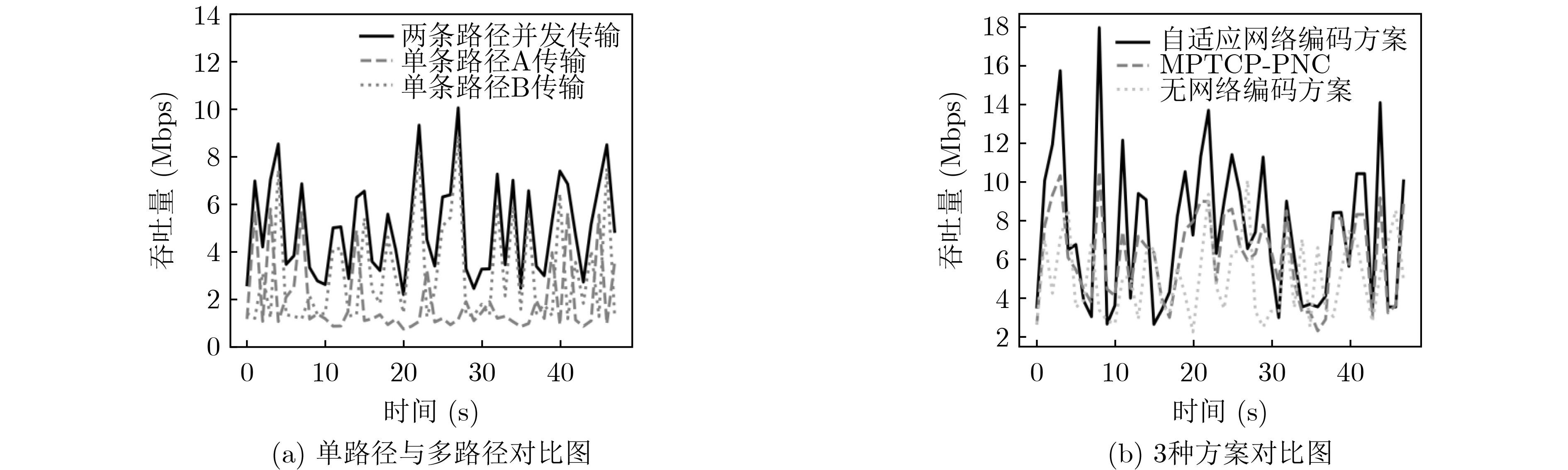
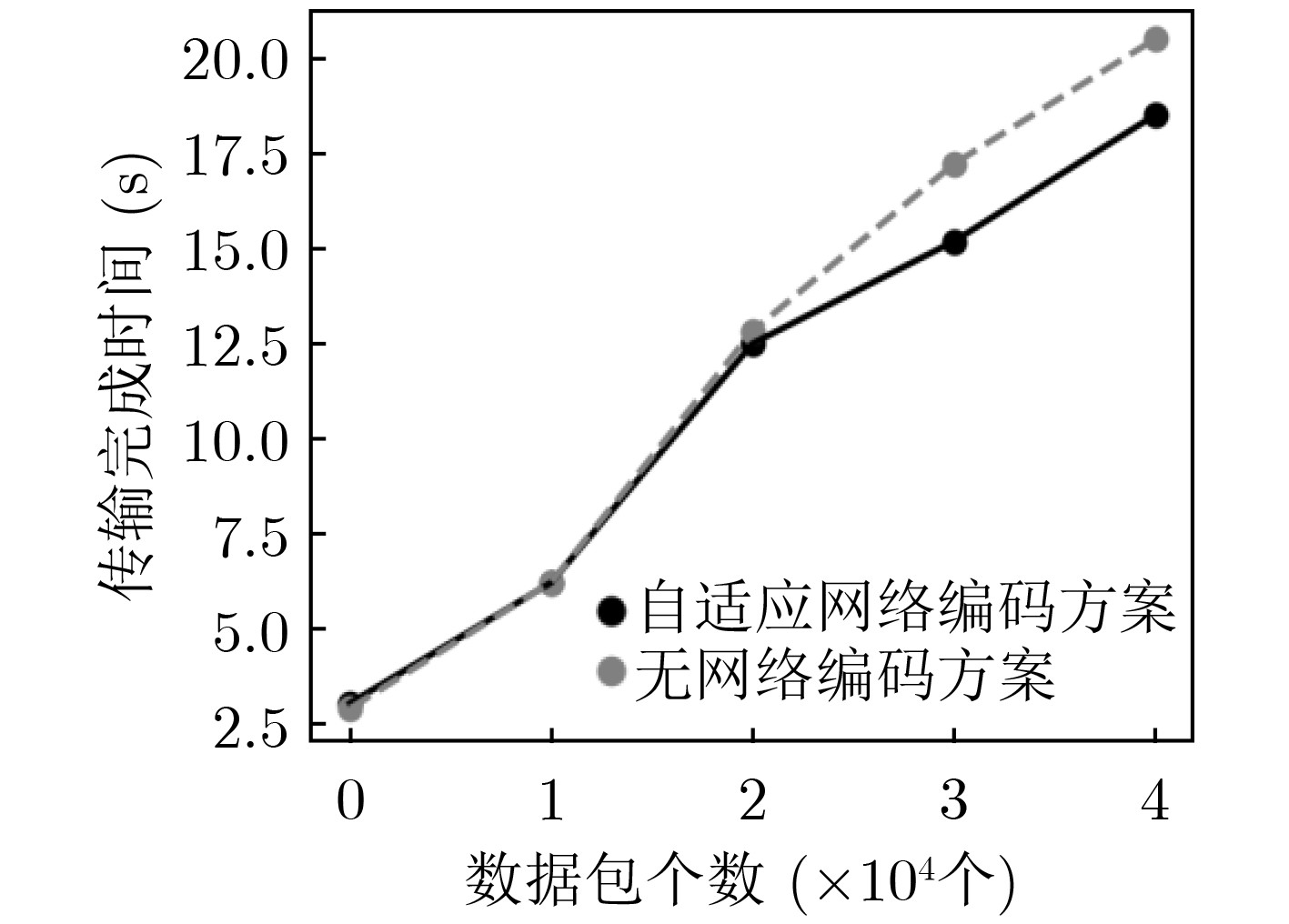
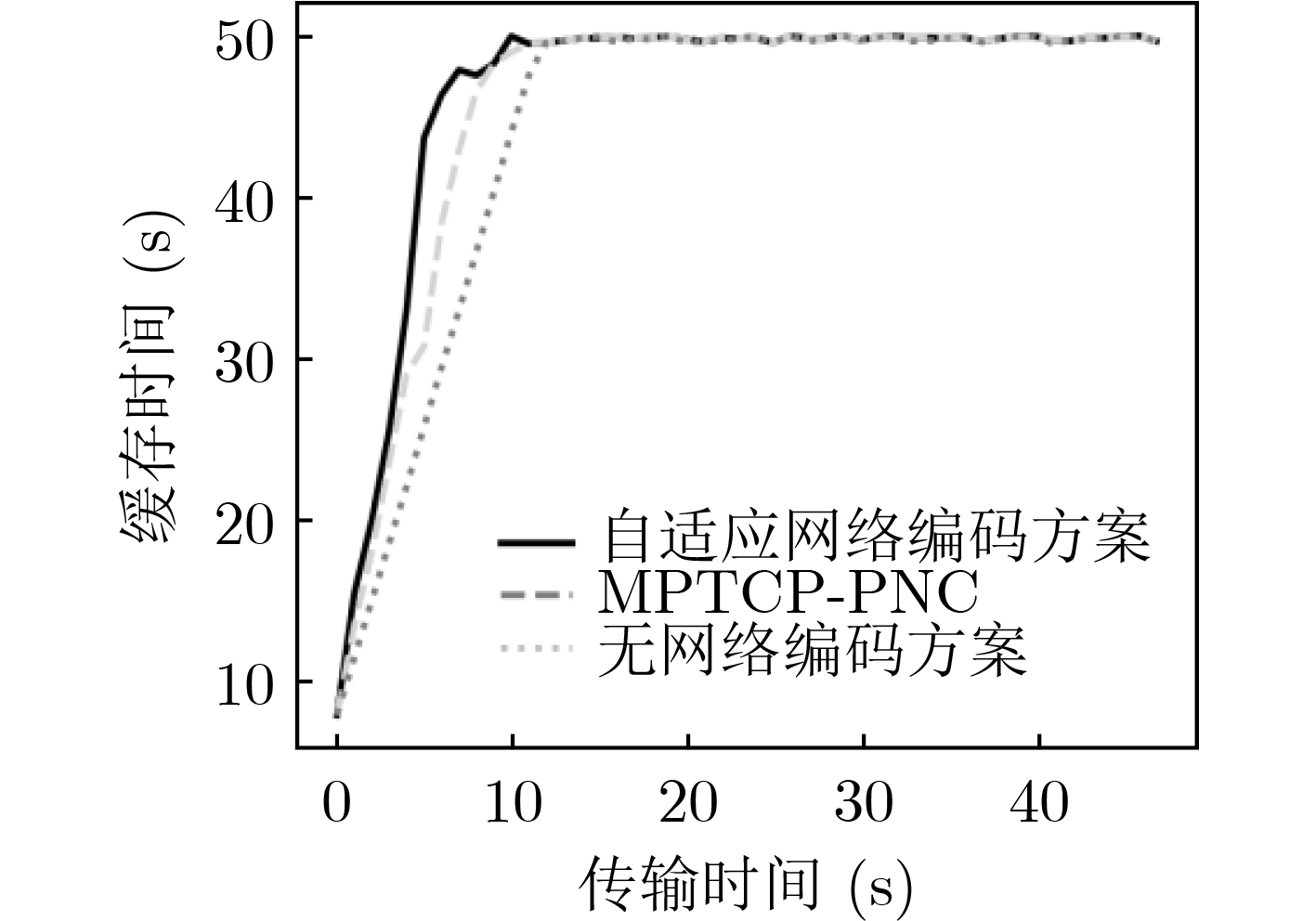
摘要: 随着高清视频直播、虚拟现实等高速率业务不断兴起,单一的网络很难满足用户的业务需求。利用多种异构链路实现并发传输,可以有效聚合带宽资源,提高服务质量。但是,在异构无线网络中,由于链路状况复杂多变,多条链路质量不一,现有的多路径并发传输算法并不能自适应地根据复杂的网络状况做出最优的决策。该文提出了一种自适应网络编码的多路径并发传输控制算法,引入Asynchronous Advantage Actor-Critic(A3C)强化学习,通过自适应的网络编码,根据当前网络状况智能地选择编码分组大小和冗余大小,从而解决数据包的乱序问题。仿真结果表明,该算法能够提高10%左右的传输速率,提升了用户体验。Abstract: With the continuous rise of high-speed services such as high-definition video live broadcast and virtual reality, it is difficult for a single network to meet the business needs of users. Using a variety of heterogeneous links to achieve concurrent transmission can effectively aggregate bandwidth resources and improve the quality of service. However, in heterogeneous wireless networks, due to the complex link conditions and the different quality of multiple links, the existing multi-path concurrent transmission algorithms can not make the optimal decision adaptively according to the complex network conditions. In this paper, a multi-path concurrent transmission control algorithm based on adaptive network coding is proposed. The Asynchronous Advanced Actor Critical (A3C) reinforcement learning is introduced. Through adaptive network coding, the coding packet size and redundancy size can be intelligently selected according to the current network conditions, so as to solve the problem of disordered packet. Simulation results show that the algorithm can improve the transmission rate by about 10% and improve the user experience.
-
Key words:
- Wireless network /
- Concurrent transmission /
- Network coding /
- Reinforcement learning
-
表 1 基于A3C的自适应编码决策算法(算法1)
输入:全局代理的网络参数${\theta _c}$和${\theta _a}$,全局迭代次数$m$,全局最大
的迭代次数$M$输出:迭代后的网络参数${\theta _c}$和${\theta _a}$ 1:初始化时间$t = 0$ 2:repeat 3: (1) 初始化起始状态${S_t} = {S_0}$ 4: (2) 初始化网络参数增量${\rm{d}}{\theta _c} = 0$,${\rm{d}}{\theta _a} = 0$ 5: (3) 将全局代理的网络参数赋值给局部代理$\theta _c' = {\theta _c}$,$\theta _a' = {\theta _a}$ 6: (4) for $t = 1,2, \cdots ,T$ $do$ 7: (a) 基于策略$ \pi ({a}_{t}|{S}_{t};{\theta }_{a}^{\text{'}}) $,执行动作${a_t}$ 8: (b) 从视频播放环境中获得奖励值${r_t}$和新的状态${S_{t + 1}}$ 9: (c)$ t\leftarrow t+1,m\leftarrow m+1 $ 10: end for 11: (5) 计算状态${S_T}$的值函数$V_\gamma ^{\pi (\theta _a^,)}({S_T};\theta _c')$ 12: (6) for $ i=T,T-1,\cdots ,1 $ do 13: (a)更新$ {\theta }_{a} $的增量 14: ${\rm{d}}{\theta }_{a}\leftarrow {\rm{d}}{\theta }_{a}+{\nabla }_{ {\theta }_{a}^{,} }{\mathrm{log} }_{ {}_{2} }\pi ({a}_{i}|{S}_{i};{\theta }_{a}^{\text{'} }){A}^{\pi ({\theta }_{c}^{\text{'} })}$
$+\varphi {\nabla }_{{\theta }_{a}^{\text{'}}}H(\pi ({a}_{i}|{S}_{i};{\theta }_{a}^{\text{'}})) $15: (b)更新${\theta _c}$的增量 16: ${\rm{d}}{\theta _c} \leftarrow {\rm{d}}{\theta _c} + {\nabla _{\theta _c'} }{({r_i} + \gamma V_\gamma ^{\pi (\theta _a')}({S_{i + 1} };\theta _c')}$
$- V_\gamma ^{\pi (\theta _a')}({S_i};\theta _c'))^2$17: end for 18: (7) 更新全局代理的网络参数 19:until $m > {{M} }$  下载: 导出CSV
下载: 导出CSV
表 2 自适应编码算法(算法2)
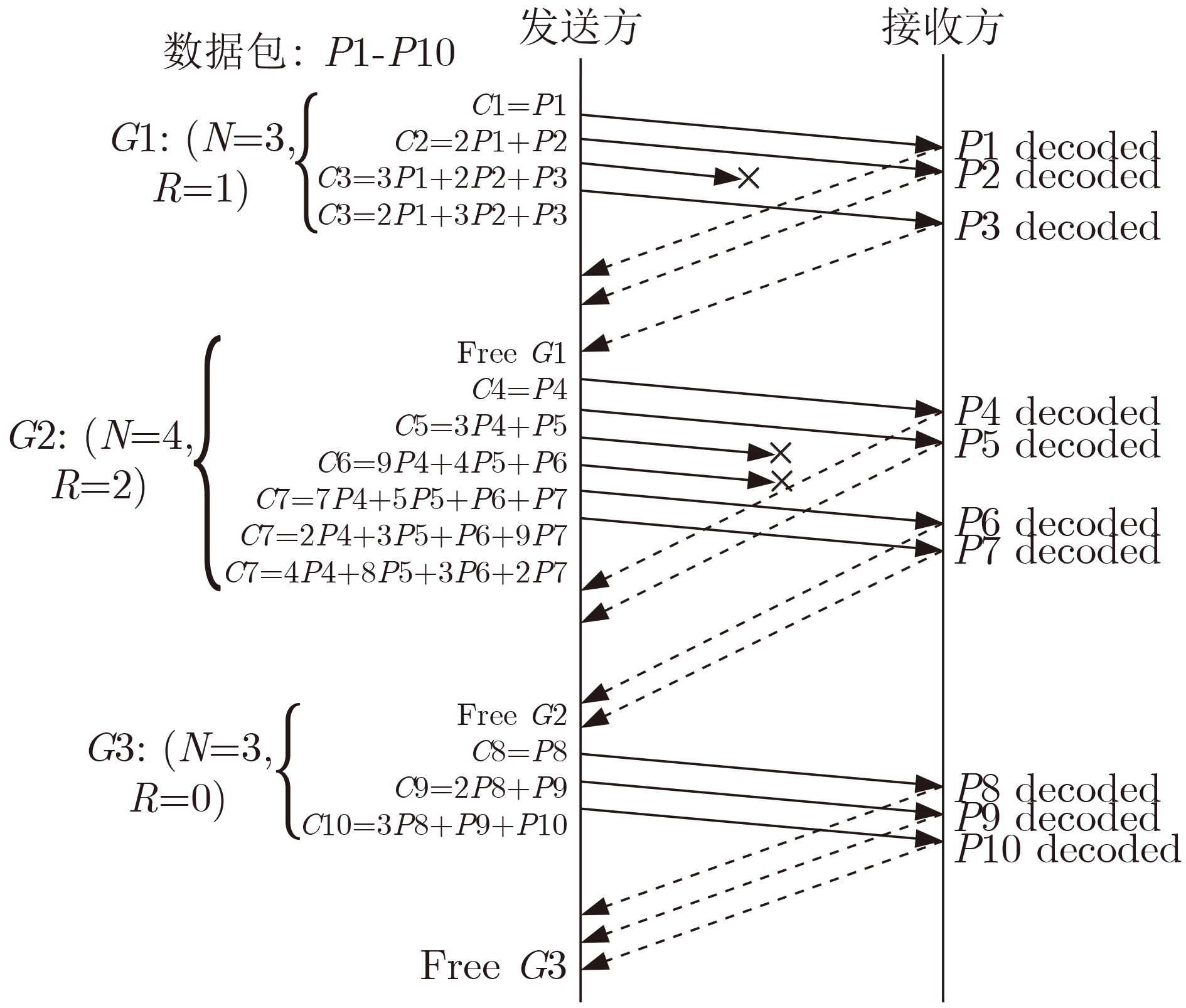
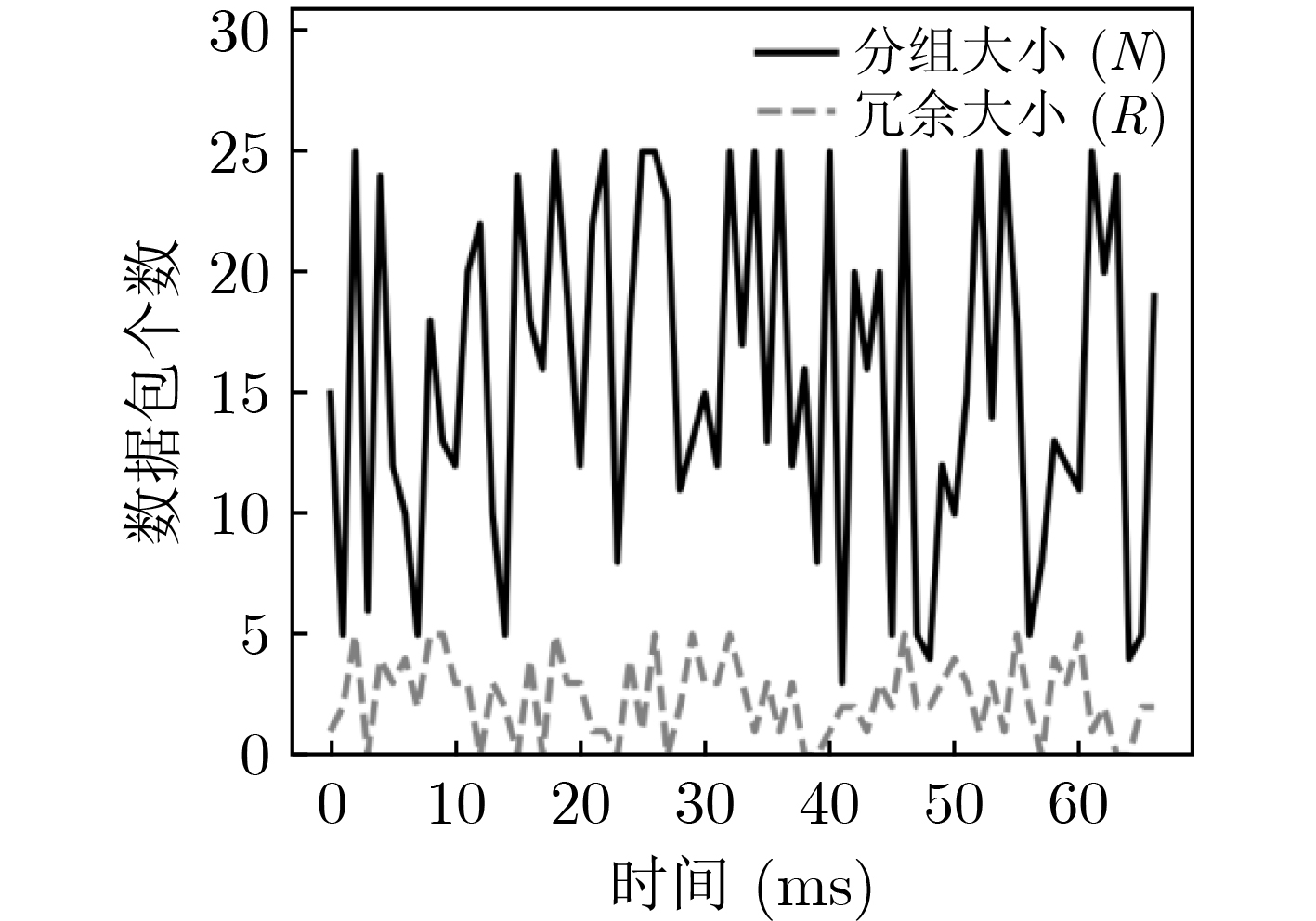
1: int $N = 0$; 2: int $R = 0$; 3: while(!isEnd){ 4: //从强化模块获取$N$和$R$ 5: $N,R = $ReinforcementLearning(); 6: //从编码矩阵${C_P}$中选取编码系数,编码原始数据包 7: 获取编码系数${a_1},{a_2}, \cdots ,{a_N}$ 8: //从冗余编码矩阵${C_r}$中选取编码系数,编码冗余数据包 9: 获取编码系数${b_1},{b_2}, \cdots ,{b_N}$ 10: NetworkCoding$(N,R)$; 11: $\} $
下载: 导出CSV
表 3 基于路径质量的数据包分发算法(算法3)
1:j=null; 2: ${Q_{\max }} = 0$; 3: for (每一条路径)$\{ $ 4: ${Q_i} = ({{\rm{effwnd}}_i} - {{\rm{unAck}}_i}) \times (1 - {{\rm{Pl}}_i})$; 5: ${\rm{if}}({Q_i} > {Q_{\max } })\{$ 6: $j = i$; 7: ${Q_{\max }} = {Q_i}$; 8: $\} {\rm{else}}$ ${\rm{if}}({Q_{\max } } = {Q_i}\& \& i.{\rm{Bw}} > j.{\rm{Bw}})\{$ 9: $j = i$; 10: $\} $ 11: $\} $ 12: ${\rm{if}}(j! = {\rm{null}})\{$ 13: 将编码数据包发送到路径$j$; 14: $\} $
下载: 导出CSV
表 5 多流并发环境参数
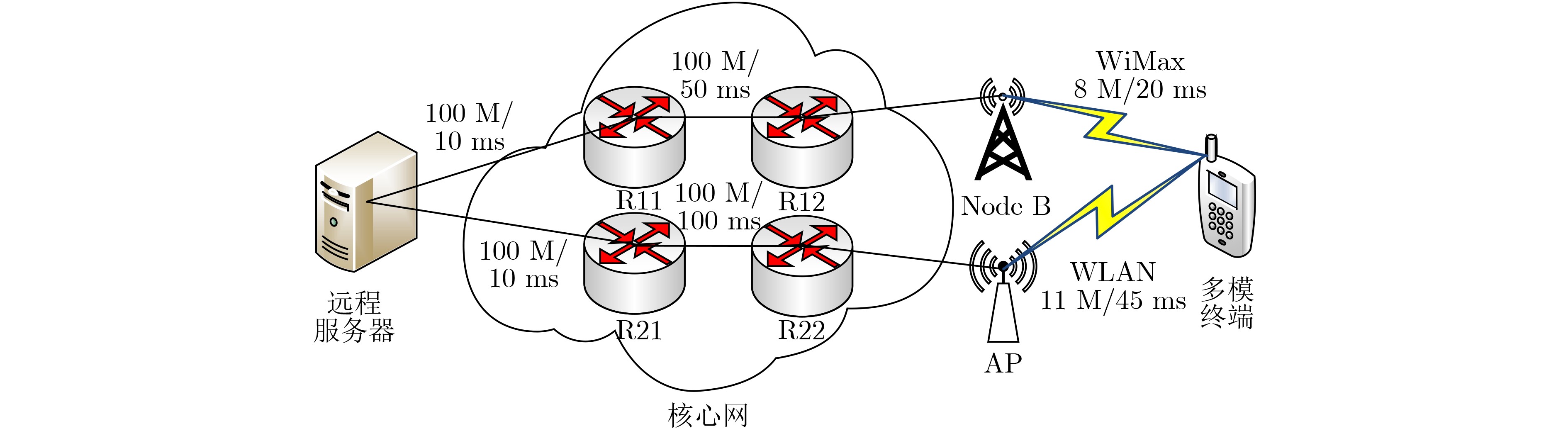
参数 参数值 参数 参数值 视频块个数 48 缓冲区起始长度(s) 4 视频块长度(s) 4 异构链路个数 2 缓冲区容量(s) 50 缓冲区上溢等待时间(s) 0.5 分组大小范围$N$ 1-25 分组内冗余大小范围$R$ 0-5 时延惩罚因子$\beta $ 0.5 重新缓冲惩罚因子$\alpha $ 0.3 缓冲区惩罚因子$\lambda $ 0.2 缓冲区长度下限${B_1}$(s) 15 缓冲区长度上限${B_2}$(s) 50 数据包大小(bytes) 1500
下载: 导出CSV
表 6 A3C算法参数
参数 参数值 参数 参数值 折扣因子$\gamma $ 0.99 Critic 网络的更新步长$a$ 0.001 视频信息数量 8 Actor 网络的更新步长$w$ 0.01 局部代理个数$l$ 16 熵的系数$\varphi $ 0.2
下载: 导出CSV
-
[1] XU Yongjun, GUI Guan, GACANIN H, et al. A survey on resource allocation for 5G heterogeneous networks: Current research, future trends, and challenges[J]. IEEE Communications Surveys & Tutorials, 2021, 23(2): 668–695. doi: 10.1109/COMST.2021.3059896 [2] WU Jiyan, YUEN C, WANG Ming, et al. Content-aware concurrent multipath transfer for high-definition video streaming over heterogeneous wireless networks[J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(3): 710–723. doi: 10.1109/TPDS.2015.2416736 [3] XU Changqiao, LIU Tianjiao, GUAN Jianfeng, et al. CMT-QA: Quality-aware adaptive concurrent multipath data transfer in heterogeneous wireless networks[J]. IEEE Transactions on Mobile Computing, 2013, 12(11): 2193–2205. doi: 10.1109/TMC.2012.189 [4] ZHANG Wei, LEI Weimin, and ZHANG Songyang. A multipath transport scheme for real-time multimedia services based on software-defined networking and segment routing[J]. IEEE Access, 2020, 8: 93962–93977. doi: 10.1109/ACCESS.2020.2994346 [5] 刘杰民, 白雪松, 王兴伟. 多路径并行传输中传输路径选择策略[J]. 电子与信息学报, 2012, 34(6): 1521–1524. doi: 10.3724/SP.J.1146.2011.01221LIU Jiemin, BAI Xuesong, and WANG Xingwei. The strategy for transmission path selection in concurrent multipath transfer[J]. Journal of Electronics &Information Technology, 2012, 34(6): 1521–1524. doi: 10.3724/SP.J.1146.2011.01221 [6] ZHANG Yuyang, DONG Ping, DU Xiaojiang, et al. BNNC: Improving performance of multipath transmission in heterogeneous vehicular networks[J]. IEEE Access, 2019, 7: 158113–158125. doi: 10.1109/ACCESS.2019.2948954 [7] HAN Chen, YIN Jun, YE Lei, et al. NCAnt: A network coding-based multipath data transmission scheme for multi-UAV formation flying networks[J]. IEEE Communications Letters, 2021, 25(3): 1041–1044. doi: 10.1109/LCOMM.2020.3039846 [8] XU Changqiao, LI Zhuofeng, ZHONG Lujie, et al. CMT-NC: Improving the concurrent multipath transfer performance using network coding in wireless networks[J]. IEEE Transactions on Vehicular Technology, 2016, 65(3): 1735–1751. doi: 10.1109/TVT.2015.2409556 [9] XU Changqiao, WANG Peng, XIONG Chunshan, et al. Pipeline network coding-based multipath data transfer in heterogeneous wireless networks[J]. IEEE Transactions on Broadcasting, 2017, 63(2): 376–390. doi: 10.1109/TBC.2016.2590819 [10] LI Wenzhong, ZHANG Han, GAO Shaohua, et al. SmartCC: A reinforcement learning approach for multipath TCP congestion control in heterogeneous networks[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(11): 2621–2633. doi: 10.1109/JSAC.2019.2933761 [11] STEWART R. RFC 4960 Stream control transmission protocol[S]. Fremont: IETF, 2007. [12] HSIEH H Y and SIVAKUMAR R. pTCP: An end-to-end transport layer protocol for striped connections[C]. Proceedings of the 10th IEEE International Conference on Network Protocols, Paris, France, 2002: 24–33. [13] ZHANG Ming, LAI Junwen, KRISHNAMURTHY A, et al. A transport layer approach for improving end-to-end performance and robustness using redundant paths[C]. Proceedings of USENIX 2004 Annual Technical Conference, Boston, USA, 2004: 99–112. [14] PAASCH C and BONAVENTURE O. Multipath TCP[J]. Communications of the ACM, 2014, 57(4): 51–57. doi: 10.1145/2578901 [15] MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]. Proceedings of the 33rd International Conference on Machine Learning, New York, USA, 2016: 1928–1937. -



图(8) / 表(6)
计量
- 文章访问数: 1187
- HTML全文浏览量: 768
- PDF下载量: 76
- 被引次数: 0
 下载:
下载:
