

Blind Recognition of Self-synchronous Scramblers Based on Cosine Conformity
-
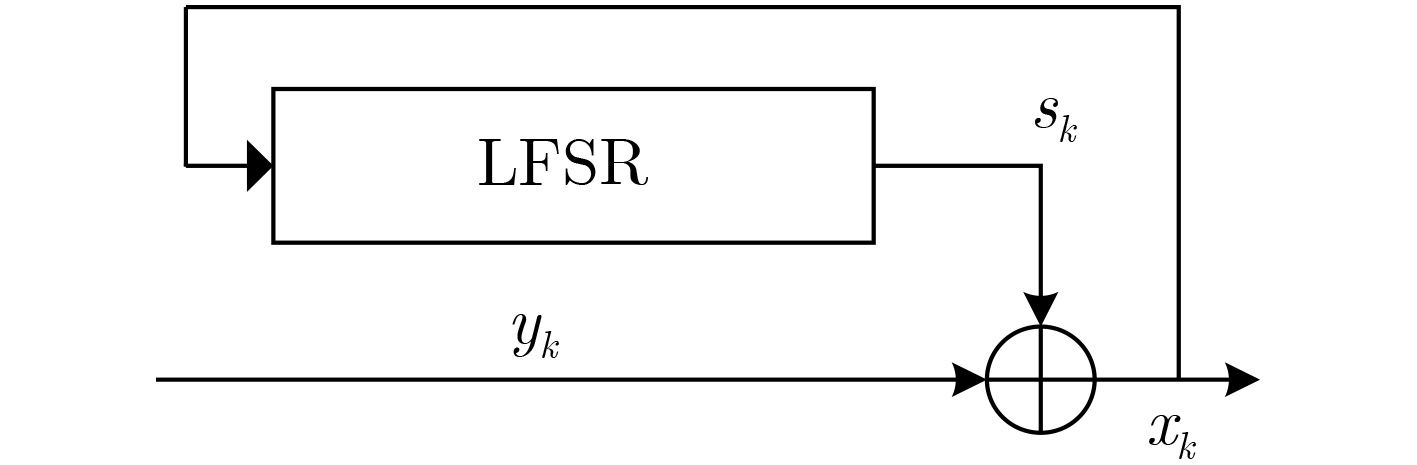
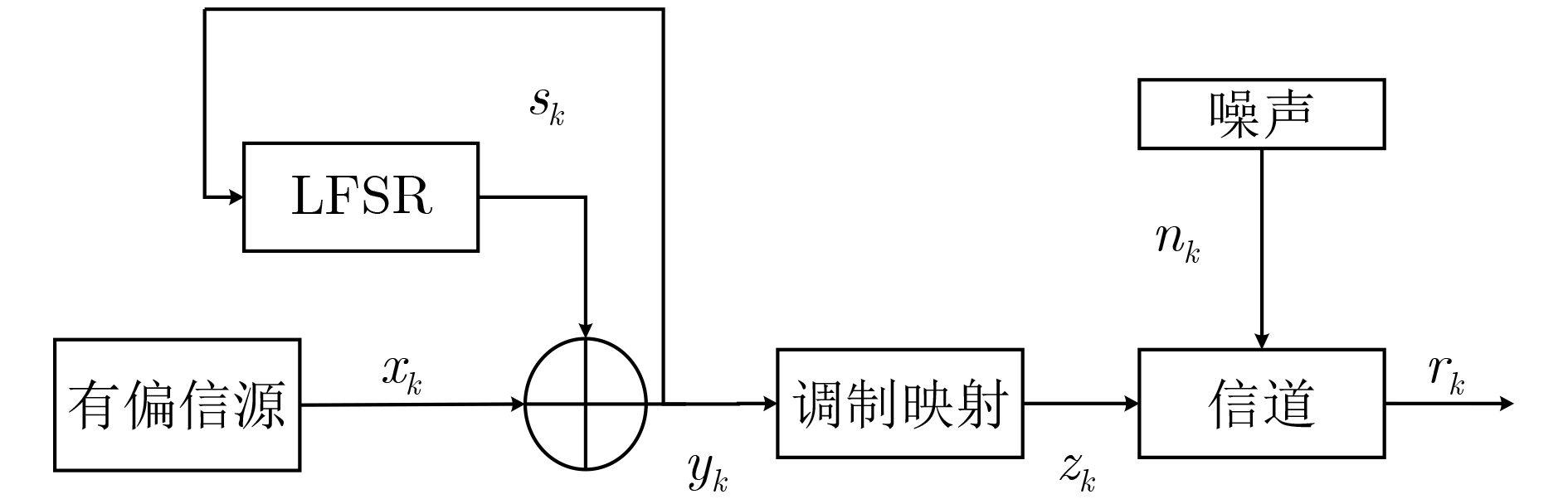
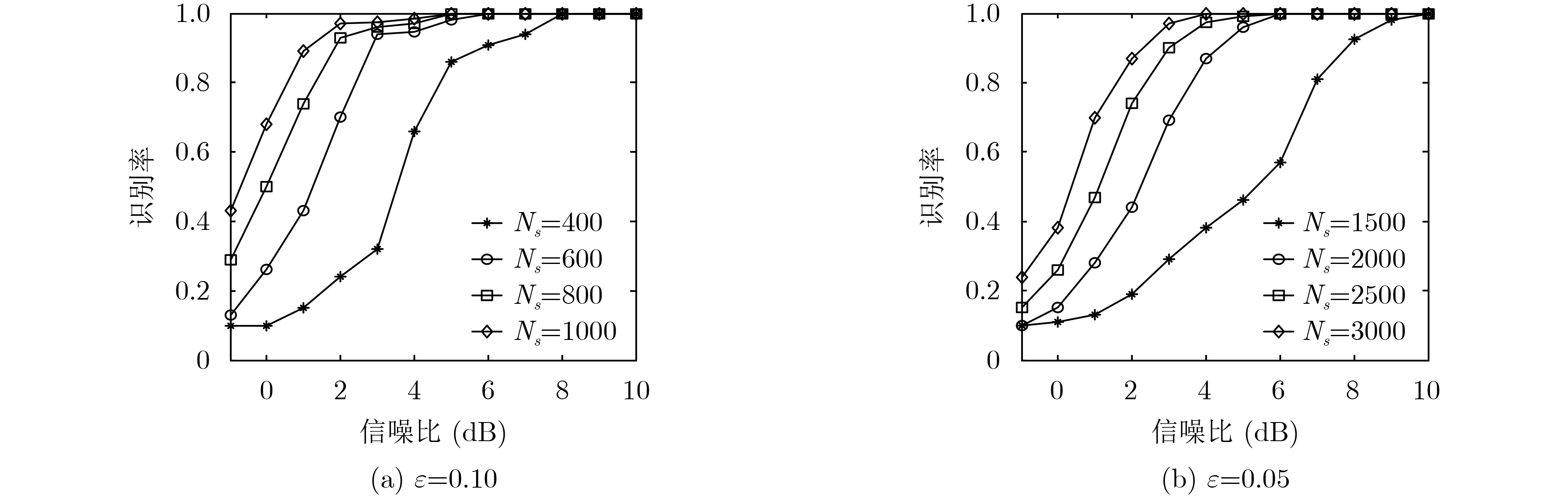
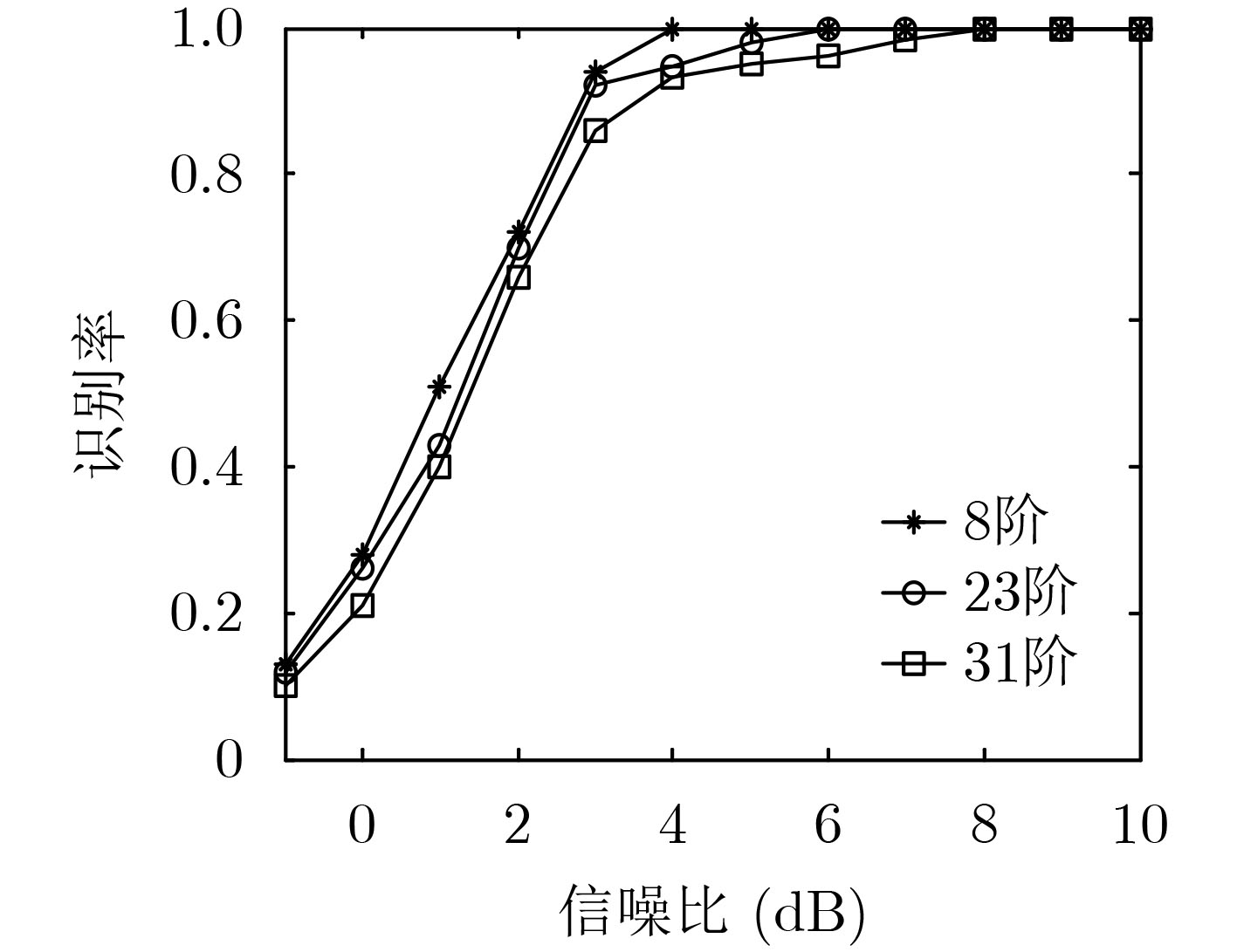
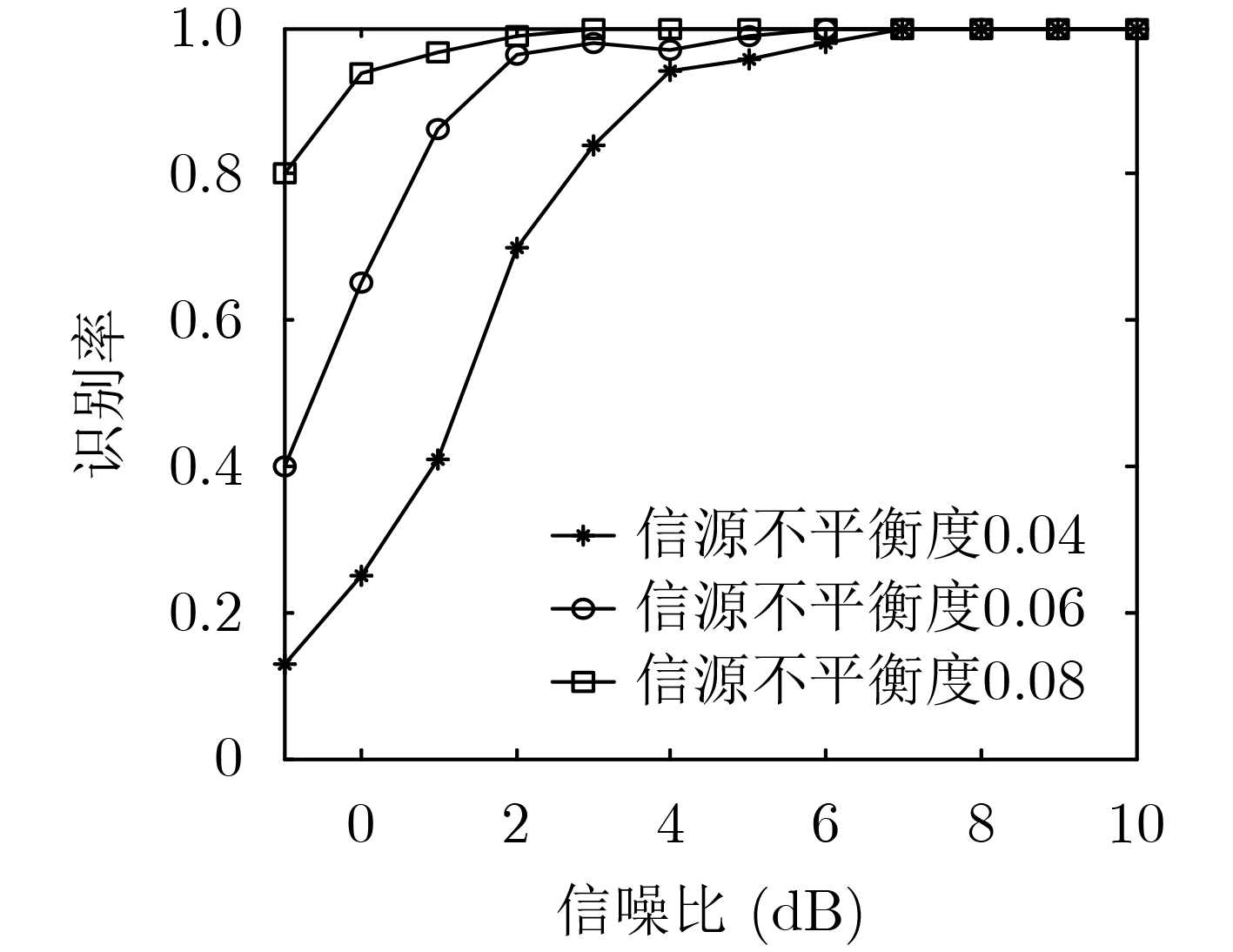
摘要: 为克服现有非合作自同步扰码识别算法在低信噪比下识别率低、适应性差的缺点,该文提出一种基于余弦符合度的自同步扰码盲识别方法。首先基于信源不平衡性和自同步扰码解扰原理建立自同步扰码的含错校验方程,然后将接收到的软判决序列转化为信息码元的后验概率序列,遍历可能的生成多项式,在遍历的过程中引入余弦符合度作为统计量,通过分析符合度的统计特性求解出最优的判别门限,根据统计量和判别门限的关系完成自同步扰码生成多项式的识别。仿真结果表明:该算法能有效识别出生成多项式,且在低信噪比下识别率优于现有算法,具有较好的低信噪比适应能力,在信源不平衡度ε为0.1,截获扰码序列长度为800 bit和ε为0.05,截获扰码序列长度为3000 bit时,能够有效完成生成多项式的识别,与目前算法相比,该文算法识别性能优于现有的硬判决算法,且比硬判决算法性能提升1~2 dB。Abstract: In order to overcome the shortcomings of the existing non-cooperative self-synchronous scramblers recognition algorithms with low recognition rate and poor adaptability under low signal-to-noise ratio, a blind recognition method of self-synchronous scramblers based on cosine conformity is proposed. Firstly, based on the source imbalance and self-synchronous scramblers descrambling principle, the error-containing check equation of the self-synchronous scramblers is established, and then the received soft decision sequence is converted into the posterior probability sequence of the information symbol. The possible generating polynomials are traversed. The cosine conformity is introduced as a statistic in the traversal process, and the optimal discrimination threshold is solved by analyzing the statistical characteristics of the cosine conformity. The self-synchronous scramblers generating polynomial is identified according to the relationship between the statistics and the discrimination threshold. The simulation results show that the algorithm can effectively identify the generating polynomial, and the recognition rate is better than the existing algorithm under low signal-to-noise ratio, and it has good low signal-to-noise ratio adaptability. When the source imbalance is 0.1, the length of the intercepted scrambling code sequence is 800 bit and 0.05, and the length of the intercepted scrambling code sequence is 3000 bit, the identification of the generating polynomial can be effectively completed. Compared with the current algorithm, the recognition performance of this algorithm is better than the existing hard decision. The performance of the algorithm is improved by 1~2 dB compared with the hard decision algorithm.
-
[1] 马钰, 张立民. 基于实时检测的扰码重建算法[J]. 电子与信息学报, 2016, 38(007): 1794–1799.MA Yu, ZHANG Limin. Scrambling code reconstruction algorithm based on real-time detection[J]. Journal of Electronics and Information Technology, 2016, 38(007): 1794–1799. [2] KIM D, SONG J, and YOON D. On the estimation of synchronous scramblers in direct sequence spread spectrum systems[J]. IEEE Access, 2020, 8: 166450–166459. doi: 10.1109/ACCESS.2020.3023425 [3] 邱钊洋, 李天昀, 查雄. 非周期长码直扩信号同步及伪码序列盲估计[J]. 电子与信息学报, 2021, 43(8): 2171–2180. doi: 10.11999/JEIT201096QIU Zhaoyang, LI Tianyun, and CHA Xiong. Aperiodic Long Code DSSS Signal Synchronization and Blind Estimation of Pseudo Code Sequence[J]. Journal of Electronics and Information Technology, 2021, 43(8): 2171–2180. doi: 10.11999/JEIT201096 [4] 钟兆根, 孙雪丽, 马钰. 线性扰码重建算法性能分析[J]. 系统工程与电子技术, 2019, 41(2): 205–210.ZHONG Zhaogen, SUN Xueli, and MA Yu. Performance analysis of linear scrambling code reconstruction algorithm[J]. Systems Engineering and Electronics, 2019, 41(2): 205–210. [5] 解辉, 韩壮志, 丁爽. 基于传播算子算法的扰码序列估计方法[J]. 系统工程与电子技术, 2017, 39(10): 2327–2332.XIE Hui, HAN Zhuangzhi, and DING Shuang. Scrambling sequence estimation method based on propagation operator algorithm[J]. Systems Engineering and Electronics, 2017, 39(10): 2327–2332. [6] HAN Shunan, ZHANG Min, and LI Xinhao. Reconstruction of Feedback Polynomial of Synchronous Scrambler Based on Triple Correlation Characteristics of M-sequences[J]. IEICE Transactions on Communications, 2018, ElO1.B(7): 1723–1732. [7] 韩树楠, 张旻, 李歆昊. 基于m序列三阶相关性的同步扰码反馈多项式重构[J]. 电子学报, 2019, 47(3): 552–559.HAN Shunan, ZHANG Min, and LI Xinhao. Synchronous scrambling feedback polynomial reconstruction based on the third-order correlation of m-sequences[J]. Acta Electronica Sinica, 2019, 47(3): 552–559. [8] CLUZEAU M. Reconstruction of a linear scrambler[J]. IEEE Transactions on Computers, 2007, 56(9): 1283–1291. doi: 10.1109/TC.2007.1055 [9] 吕喜在, 苏绍璟, 黄芝平. 一种新的自同步扰码多项式盲恢复方法[J]. 兵工学报, 2011, 32(6): 680–685.LV Xizai, SU Shaojin, and HUANG Zhiping. A new blind recovery method of self-synchronizing scrambling polynomial[J]. Acta Armamentarius, 2011, 32(6): 680–685. [10] 黄芝平, 周靖, 苏绍璟, 等. 基于游程统计的自同步扰码多项式阶数估计[J]. 电子科技大学学报, 2013(4): 541–545.HUANG Zhiping, ZHOU Jing, SU Shaojing, et al. Self-synchronizing scrambling polynomial order estimation based on run-length statistics[J]. Journal of University of Electronic Science and Technology of China, 2013(4): 541–545. [11] 廖红舒, 袁叶, 甘露. 自同步扰码的盲识别方法[J]. 通信学报, 2013, 34(1): 136–143.LIAO Hongshu, YUAN Ye, and GAN Lu. Blind recognition method of self-synchronizing scrambling code[J]. Journal on Communications, 2013, 34(1): 136–143. [12] HAN S, and ZHANG M. A method for blind identification of a scrambler based on matrix analysis[J]. Communications Letters, IEEE, 2018, 22(11): 2198–2201. doi: 10.1109/LCOMM.2018.2868681 [13] 尹瑾, 王建新. RS码的自同步扰码盲识别方法[J]. 计算机工程与应用, 2017, 53(22): 77–81.YIN Jin, and WANG Jianxin. Self-synchronizing scrambling code blind recognition method of RS code[J]. Computer Engineering and Applications, 2017, 53(22): 77–81. [14] WU Zhaojun, ZHANG Limin, and ZHONG Zhaogen. A maximum cosinoidal cost function method for parameter estimation of RSC Turbo codes[J]. IEEE Communications Letters, 2019, 23(3): 390–393. doi: 10.1109/LCOMM.2018.2890224 [15] 吴昭军, 张立民, 钟兆根, 等. 一种软判决下的RS码识别算法[J]. 电子与信息学报, 2020, 42(9): 2150–2157. doi: 10.11999/JEIT190592WU Zhaojun, ZHANG Limin, ZHONG Zhaogen, et al. A RS code recognition algorithm under soft decision[J]. Journal of Electronics and Information, 2020, 42(9): 2150–2157. doi: 10.11999/JEIT190592 [16] 欧世峰, 赵艳磊, 宋鹏,等. 基于概率耦合的双直接判决先验信噪比估计算法[J]. 电子学报, 2020, 48(8): 151–160.OU Shifeng, ZHAO Yanlei, SONG Peng, et al. Dual direct decision prior signal-to-noise ratio estimation algorithm based on probabilistic coupling[J]. Acta Electronica Sinica, , 2020, 48(8): 151–160. [17] 尹瑾, 王建新. 基于软判决求解含错方程的自同步扰码盲识别[J]. 探测与控制学报, 2017(2): 46–50, 55.YIN Jin and WANG Jianxin. Self-synchronizing scrambling code blind recognition based on soft decision to solve error equations[J]. Journal of Detection and Control, 2017(2): 46–50, 55. [18] MA Yu, ZHANG Limin, and WANG Haotong. Reconstructing synchronous scrambler with robust detection capability in the presence of noise[J]. IEEE Transactions on Information Forensics and Security, 2015, 10(2): 397–408. doi: 10.1109/TIFS.2014.2378143 -


 下载:
下载:




图(8)
计量
- 文章访问数: 1177
- HTML全文浏览量: 841
- PDF下载量: 63
- 被引次数: 0
