

Research on Long Short-Term Memory Networks Speech Separation Algorithm Based on Beamforming
-
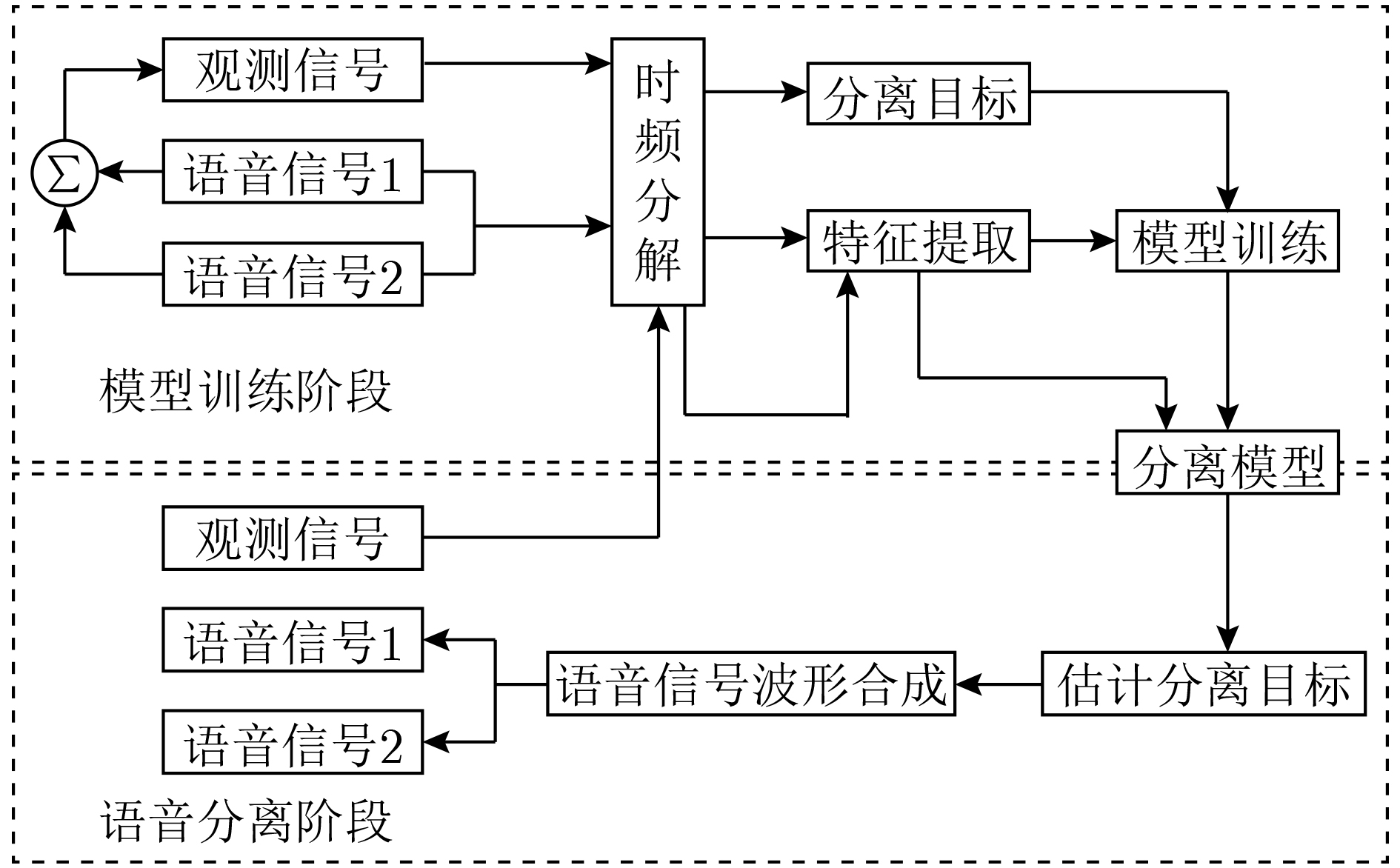
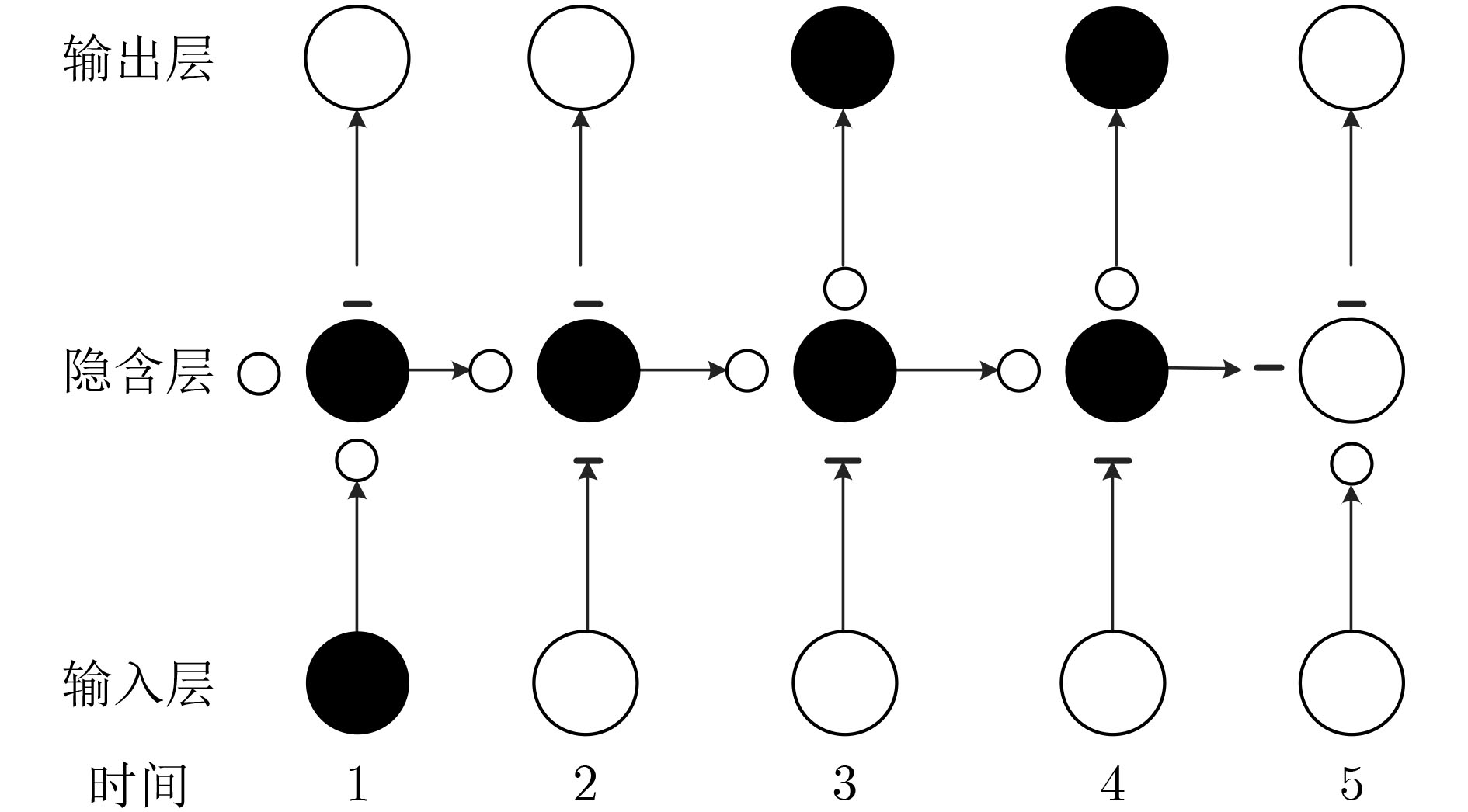
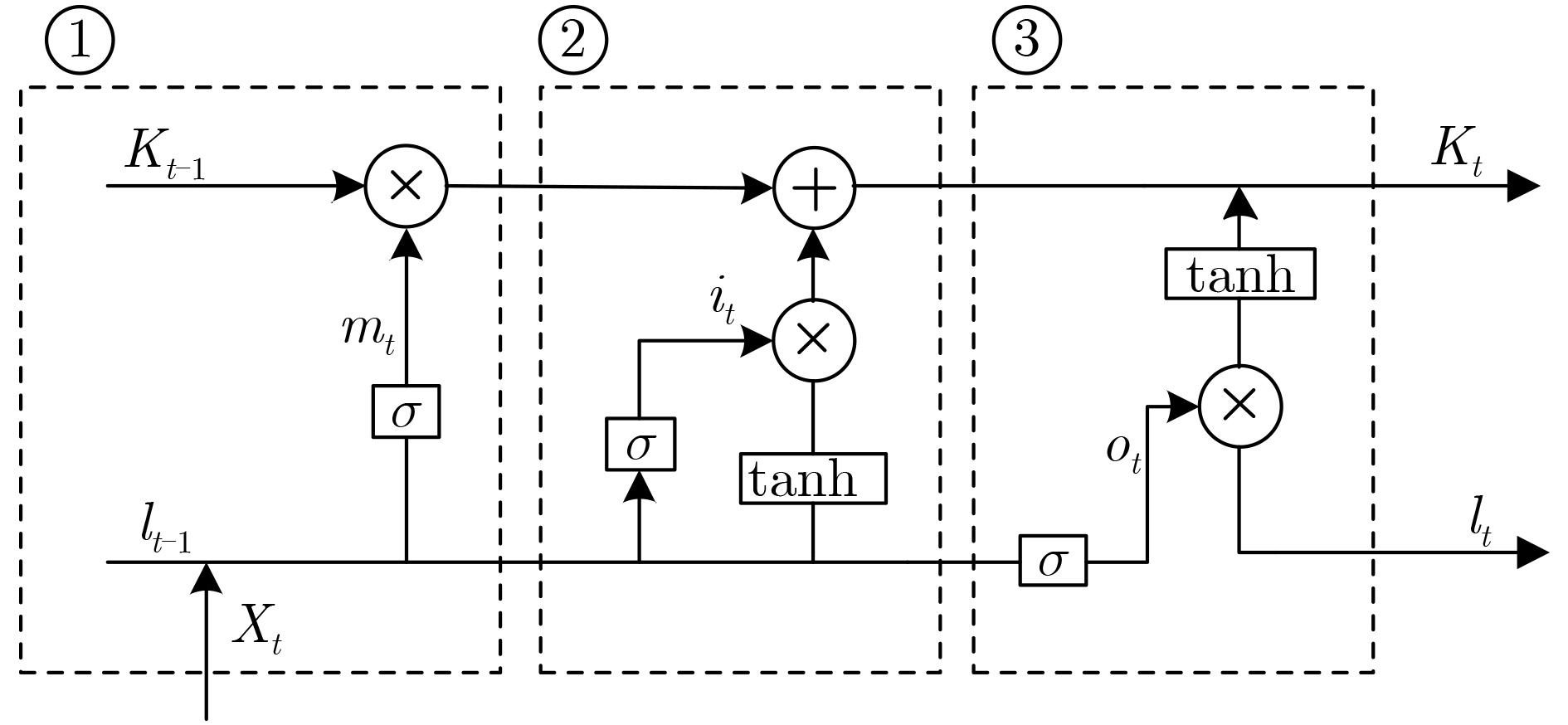
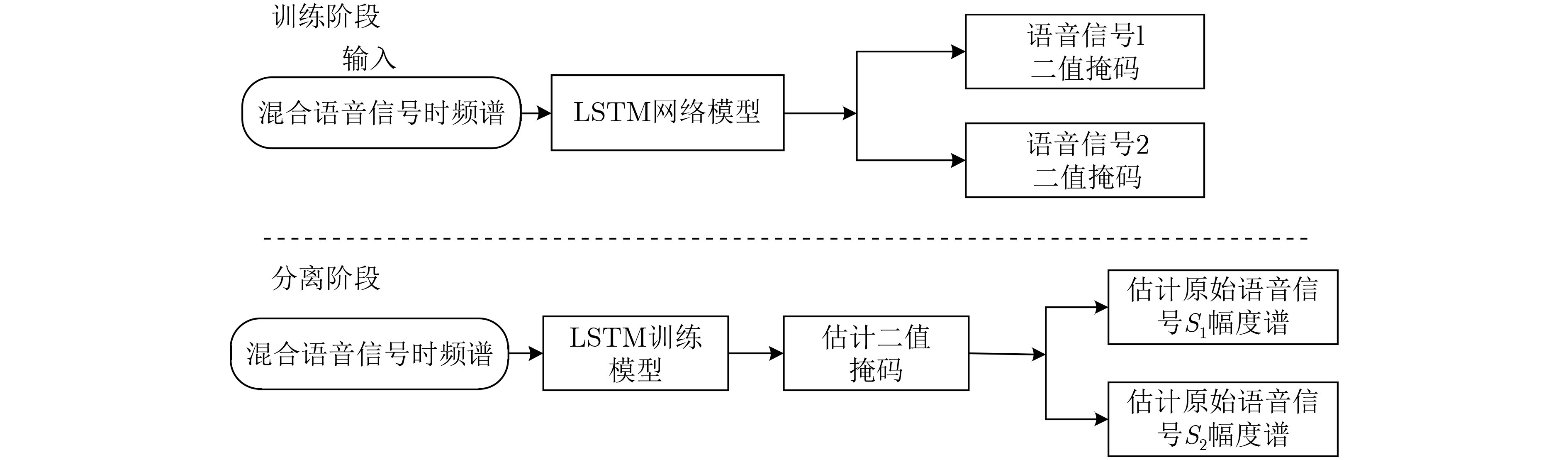
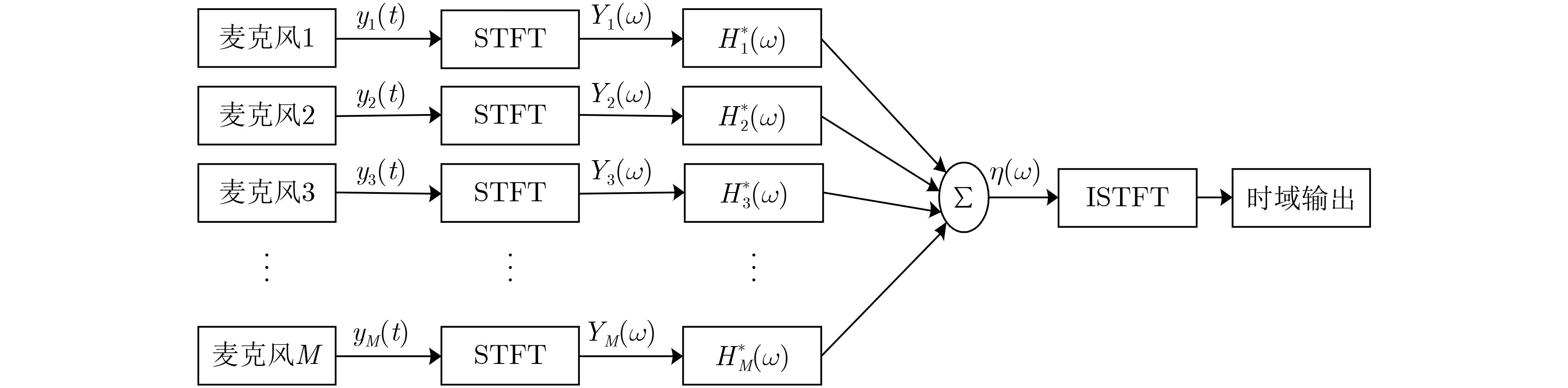
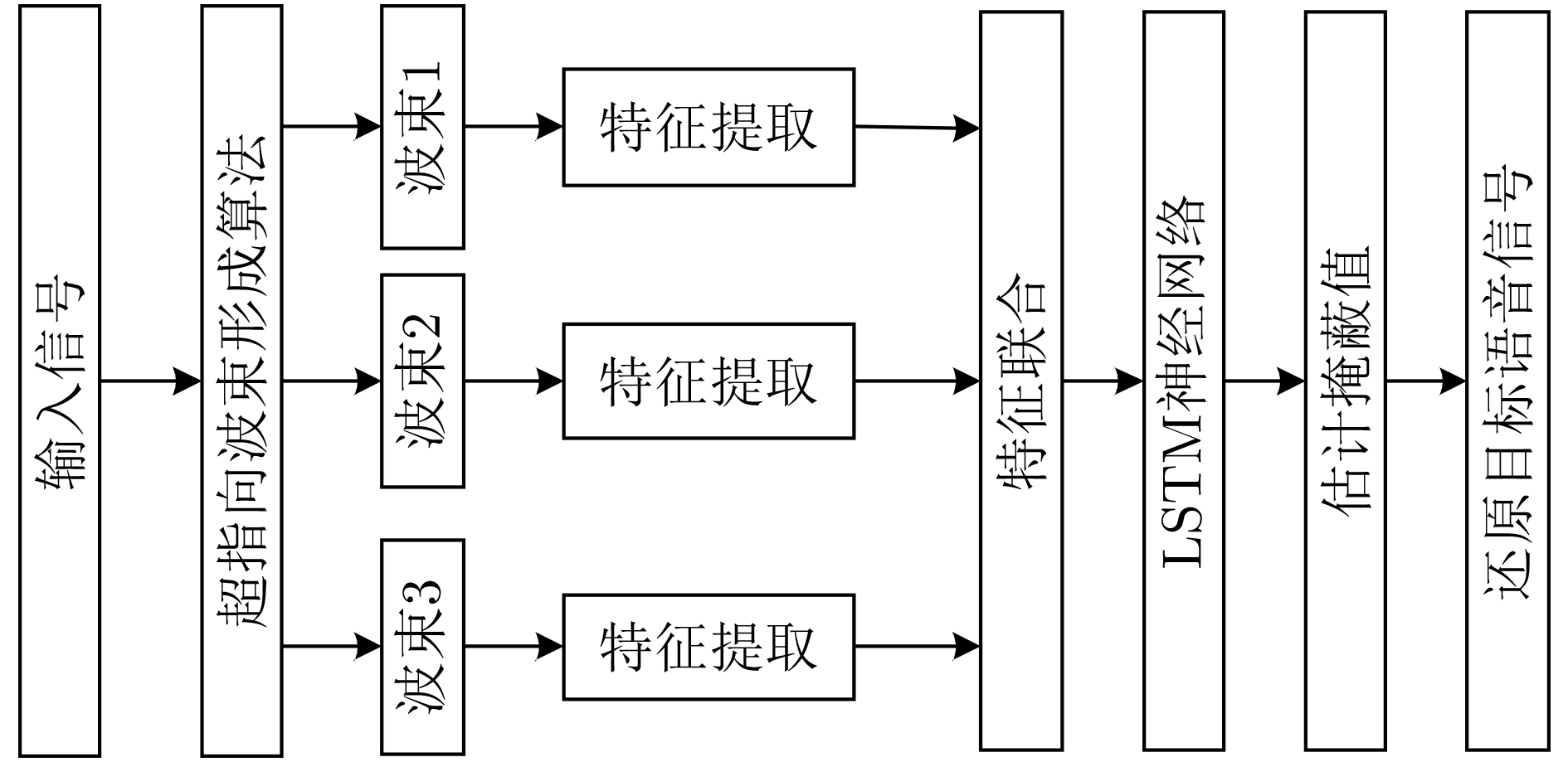
摘要: 在利用深度学习方式进行语音分离的领域,常用卷积神经网络(RNN)循环神经网络进行语音分离,但是该网络模型在分离过程中存在梯度下降问题,分离结果不理想。针对该问题,该文利用长短时记忆网络(LSTM)进行信号分离探索,弥补了RNN网络的不足。多路人声信号分离较为复杂,现阶段所使用的分离方式多是基于频谱映射方式,没有有效利用语音信号空间信息。针对此问题,该文结合波束形成算法和LSTM网络提出了一种波束形成LSTM算法,在TIMIT语音库中随机选取3个说话人的声音文件,利用超指向波束形成算法得到3个不同方向上的波束,提取每一波束中频谱幅度特征,并构建神经网络预测掩蔽值,得到待分离语音信号频谱并重构时域信号,进而实现语音分离。该算法充分利用了语音信号空间特征和信号频域特征。通过实验验证了不同方向语音分离效果,在60°方向该算法与IBM-LSTM网络相比,客观语音质量评估(PESQ)提高了0.59,短时客观可懂(STOI)指标提高了0.06,信噪比(SNR)提高了1.13 dB,另外两个方向上,实验结果同样证明了该算法较IBM-LSTM算法和RNN算法具有更好的分离性能。Abstract: In the field of speech separation using deep learning, the Recurrent Neural Network (RNN) is commonly used for speech separation, but the network model has a gradient descent problem in the separation process, and the separation result is not ideal. Considering this problem, this paper uses Long Short-Term Memory (LSTM) network to explore the signal separation, which makes up for the deficiency of RNN network. The separation of multi-channel vocal signals is more complicated, and most of the separation methods used at this stage are based on the spectrum mapping method, and the spatial information of the voice signal is not effectively used. In response to this problem, this paper combines the beamforming algorithm and the LSTM network to propose a beamforming LSTM algorithm. The voice files of three speakers are randomly selected from the TIMIT voice library, and the super-pointing beamforming algorithm is used to obtain beams in three different directions. The spectral amplitude characteristics in each beam are extracted, and a neural network is constructed to predict the masking value. The to-be-separated speech signal spectrum is obtained. and the time-domain signal is constructed, and the speech separation is realized. The algorithm makes full use of the spatial characteristics of the speech signal and the signal frequency domain characteristics. The effect of speech separation in different directions is verified through experiments. Compared with the IBM-LSTM network, at 60-degree direction, this algorithm improves Perceptual Evaluation of Speech Quality (PESQ) by 0.59, Short-Time Objective Intelligibility (STOI) index by 0.06, and Signal to Noise Ratio (SNR) by 1.13 dB. At the other two reverse directions, the experimental results also prove that the algorithm has better separation performance than the IBM-LSTM algorithm and the RNN algorithm.
-
表 1 不同网络结构分离人声信号结果
评价指标
网络结构观测信号角度(°) PESQ STOI SNR (dB) 波束形成LSTM 60 3.34 0.91 6.75 IBM-LSTM 2.75 0.85 5.62 RNN 2.58 0.82 4.59 波束形成LSTM 120 3.28 0.89 6.74 IBM-LSTM 2.72 0.84 5.61 RNN 2.52 0.80 4.56 波束形成LSTM 240 3.32 0.91 6.74 IBM-LSTM 2.76 0.84 5.60 RNN 2.54 0.81 4.54  下载: 导出CSV
下载: 导出CSV
-
[1] EPHRAT A, MOSSERI I, LANG O, et al. Looking to listen at the cocktail party: A speaker–independent audio–visual model for speech separation[J]. ACM Transactions on Graphics, 2008, 37(4): 109:1–109:11. [2] JONES G L and LITOVSKY R Y. A cocktail party model of spatial release from masking by both noise and speech interferers[J]. The Journal of the Acoustical Society of America, 2011, 130(3): 1463–1474. doi: 10.1121/1.3613928 [3] XU Jiaming, SHI Jing, LIU Guangcan, et al. Modeling attention and memory for auditory selection in a cocktail party environment[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018. [4] 黄雅婷, 石晶, 许家铭, 等. 鸡尾酒会问题与相关听觉模型的研究现状与展望[J]. 自动化学报, 2019, 45(2): 234–251.HUANG Yating, SHI Jing, XU Jiaming, et al. Research advances and perspectives on the cocktail party problem and related auditory models[J]. Acta Automatica Sinica, 2019, 45(2): 234–251. [5] 李娟. 基于ICA和波束形成的快速收敛的BSS算法[J]. 山西师范大学学报: 自然科学版, 2018, 32(4): 52–56.LI Juan. A fast-convergence algorithm combining ICA and beamforming[J]. Journal of Shanxi Normal University:Natural Science Edition, 2018, 32(4): 52–56. [6] 陈国良, 黄晓琴, 卢可凡. 改进的快速独立分量分析在语音分离系统中的应用[J]. 计算机应用, 2019, 39(S1): 206–209.CHEN Guoliang, HUANG Xiaoqin, and LU Kefan. Application of improved fast independent component analysis in speech separation system[J]. Journal of Computer Applications, 2019, 39(S1): 206–209. [7] 王昕, 蒋志翔, 张杨, 等. 基于时间卷积网络的深度聚类说话人语音分离[J]. 计算机工程与设计, 2020, 41(9): 2630–2635.WANG Xin, JIANG Zhixiang, ZHANG Yang, et al. Deep clustering speaker speech separation based on temporal convolutional network[J]. Computer Engineering and Design, 2020, 41(9): 2630–2635. [8] 崔建峰, 邓泽平, 申飞, 等. 基于非负矩阵分解和长短时记忆网络的单通道语音分离[J]. 科学技术与工程, 2019, 19(12): 206–210. doi: 10.3969/j.issn.1671-1815.2019.12.029CUI Jianfeng, DENG Zeping, SHEN Fei, et al. Single channel speech separation based on non–negative matrix factorization and long short–term memory network[J]. Science Technology and Engineering, 2019, 19(12): 206–210. doi: 10.3969/j.issn.1671-1815.2019.12.029 [9] 陈修凯, 陆志华, 周宇. 基于卷积编解码器和门控循环单元的语音分离算法[J]. 计算机应用, 2020, 40(7): 2137–2141.CHEN Xiukai, LU Zhihua, and ZHOU Yu. Speech separation algorithm based on convolutional encoder decoder and gated recurrent unit[J]. Journal of Computer Applications, 2020, 40(7): 2137–2141. [10] WANG Deliang and CHEN Jitong. Supervised speech separation based on deep learning: An overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1702–1726. doi: 10.1109/TASLP.2018.2842159 [11] 刘文举, 聂帅, 梁山, 等. 基于深度学习语音分离技术的研究现状与进展[J]. 自动化学报, 2016, 42(6): 819–833.LIU Wenju, NIE Shuai, LIANG Shan, et al. Deep learning based speech separation technology and its developments[J]. Acta Automatica Sinica, 2016, 42(6): 819–833. [12] WANG Yuxuan, NARAYANAN A, and WANG Deliang. On training targets for supervised speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12): 1849–1858. doi: 10.1109/TASLP.2014.2352935 [13] HUANG P S, KIM M, HASEGAWA–JOHNSON M, et al. Deep learning for monaural speech separation[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 2014: 1562–1566. [14] HUI Like, CAI Meng, GUO Cong, et al. Convolutional maxout neural networks for speech separation[C]. 2015 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Abu Dhabi, United Arab Emirates. 2015: 24–27. [15] CHANDNA P, MIRON M, JANER J, et al. Monoaural audio source separation using deep convolutional neural networks[C]. The 13th International Conference, Grenoble, France, 2017: 258–266. [16] NIE Shuai, ZHANG Hui, ZHANG Xueliang, et al. Deep stacking networks with time series for speech separation[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 2014: 6667–6671. [17] GERS F A, SCHMIDHUBER J, and CUMMINS F. Learning to forget: Continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451–2471. doi: 10.1162/089976600300015015 [18] 梁尧, 朱杰, 马志贤. 基于深度神经网络的单通道语音分离算法[J]. 信息技术, 2018, 42(7): 24–27.LIANG Yao, ZHU Jie, and MA Zhixian. A monaural speech separation algorithm based on deep neural networks[J]. Information Technology, 2018, 42(7): 24–27. [19] 李文杰, 罗文俊, 李艺文, 等. 基于可分离卷积与LSTM的语音情感识别研究[J]. 信息技术, 2020, 44(10): 61–66.LI Wenjie, LUO Wenjun, LI Yiwen, et al. Speech emotion recognition based on separable convolution and LSTM[J]. Information Technology, 2020, 44(10): 61–66. [20] WESTHAUSEN N L and MEYER B T. Dual–signal transformation LSTM network for real–time noise suppression[EB/OL]. https://arxiv.org/abs/2005.07551,2020. [21] GREZES F, NI Zhaoheng, TRINH V A, et al. Combining spatial clustering with LSTM speech models for multichannel speech enhancement[EB/OL]. https://arxiv.org/abs/2012.03388,2020. [22] LI Xiaofei and HORAUD R. Online monaural speech enhancement using delayed subband LSTM[EB/OL]. https://arxiv.org/abs/2005.05037, 2020. [23] 潘超, 黄公平, 陈景东. 面向语音通信与交互的麦克风阵列波束形成方法[J]. 信号处理, 2020, 36(6): 804–815.PAN Chao, HUANG Gongping, and CHEN Jingdong. Microphone array beamforming: An overview[J]. Journal of Signal Processing, 2020, 36(6): 804–815. [24] 朱训谕, 潘翔. 基于麦克风线阵的语音增强算法研究[J]. 杭州电子科技大学学报: 自然科学版, 2020, 40(5): 30–33, 72.ZHU Xunyu and PAN Xiang. Research on speech enhancement algorithm based on microphone linear array[J]. Journal of Hangzhou Dianzi University:Natural Science, 2020, 40(5): 30–33, 72. [25] KIM H S, KO H, BEH J, et al. Sound source separation method and system using beamforming technique[P]. USA Patent. 008577677B2, 2013. [26] ARAKI S, SAWADA H, and MAKINO S. Blind speech separation in a meeting situation with maximum SNR beamformers[C]. 2007 IEEE International Conference on Acoustics, Speech and Signal Processing–ICASSP’07, Honolulu, USA, 2007, 1: I–41–I–44. [27] SARUWATARI H, KURITA S, TAKEDA K, et al. Blind source separation combining independent component analysis and beamforming[J]. EURASIP Journal on Advances in Signal Processing, 2003, 2003: 569270. doi: 10.1155/S1110865703305104 [28] WANG Lin, DING Heping, and YIN Fuliang. Speech separation and extraction by combining superdirective beamforming and blind source separation[M]. NAIK G and WANG Wenwu. Blind Source Separation. Heidelberg: Springer, 2014: 323–348. [29] XENAKI A, BOLDT J B, and CHRISTENSEN M G. Sound source localization and speech enhancement with sparse Bayesian learning beamforming[J]. The Journal of the Acoustical Society of America, 2018, 143(6): 3912–3921. doi: 10.1121/1.5042222 [30] QIAN Kaizhi, ZHANG Yang, CHANG Shiyu, et al. Deep learning based speech beamforming[C]. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 2018: 5389–5393. [31] HIMAWAN I, MCCOWAN I, and LINCOLN M. Microphone array beamforming approach to blind speech separation[C]. The 4th International Workshop, Brno, The Czech Republic, 2007: 295–305. -

 下载:
下载:




图(8) / 表(1)
计量
- 文章访问数: 1292
- HTML全文浏览量: 1122
- PDF下载量: 165
- 被引次数: 0
