

Full-sea Depth Sound Speed Profiles Prediction Using RNN and Attention Mechanism
-
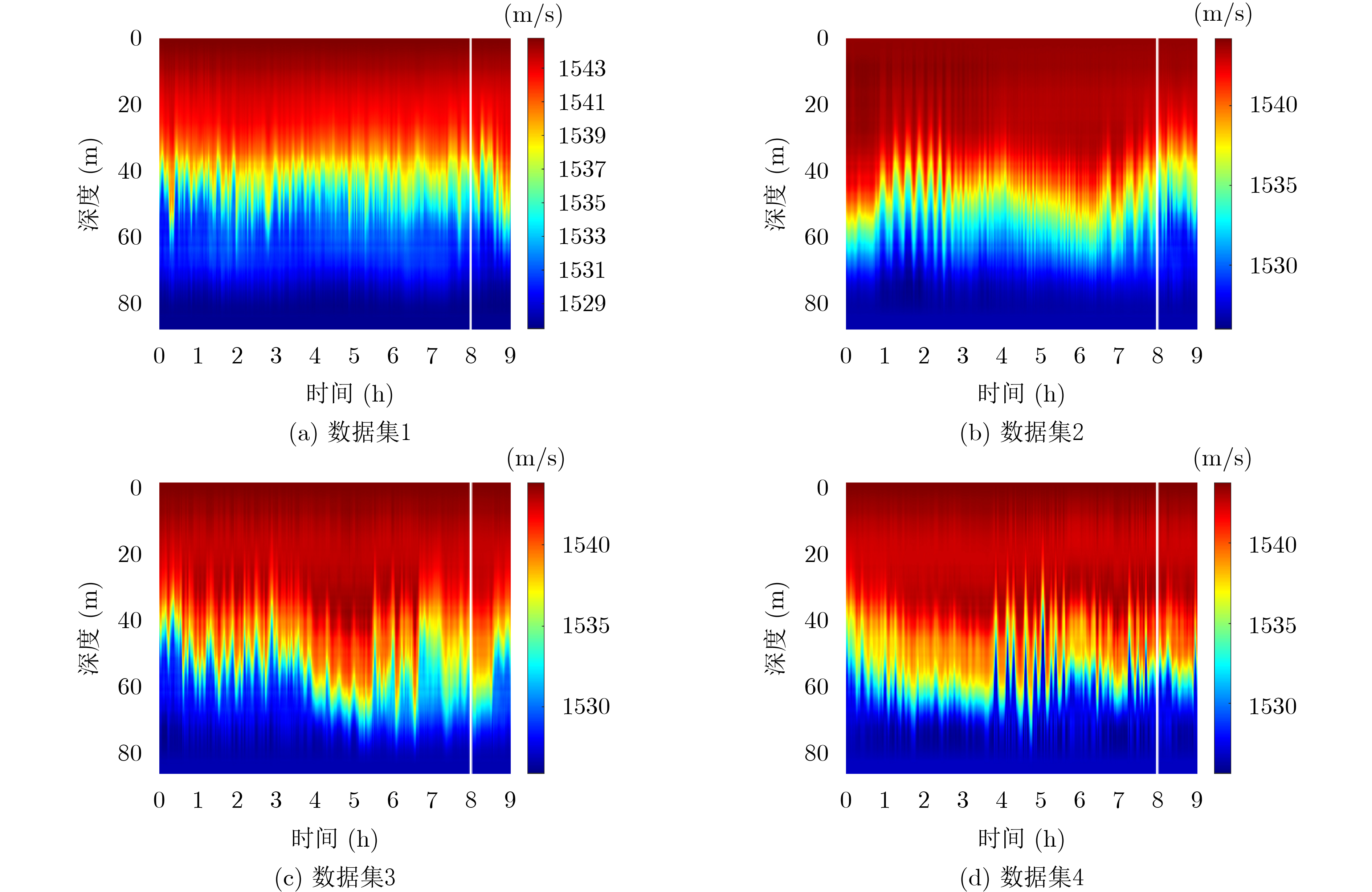
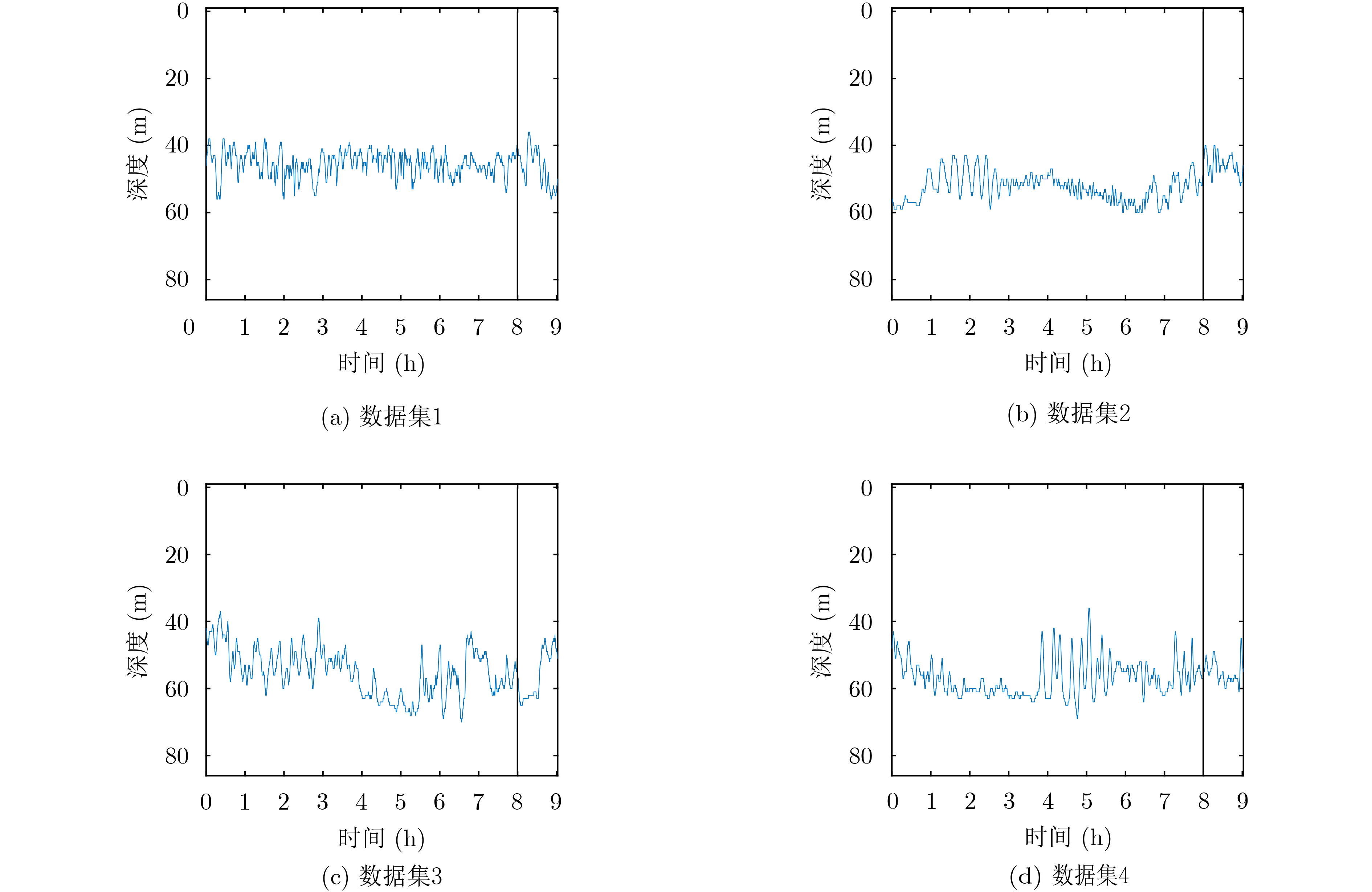
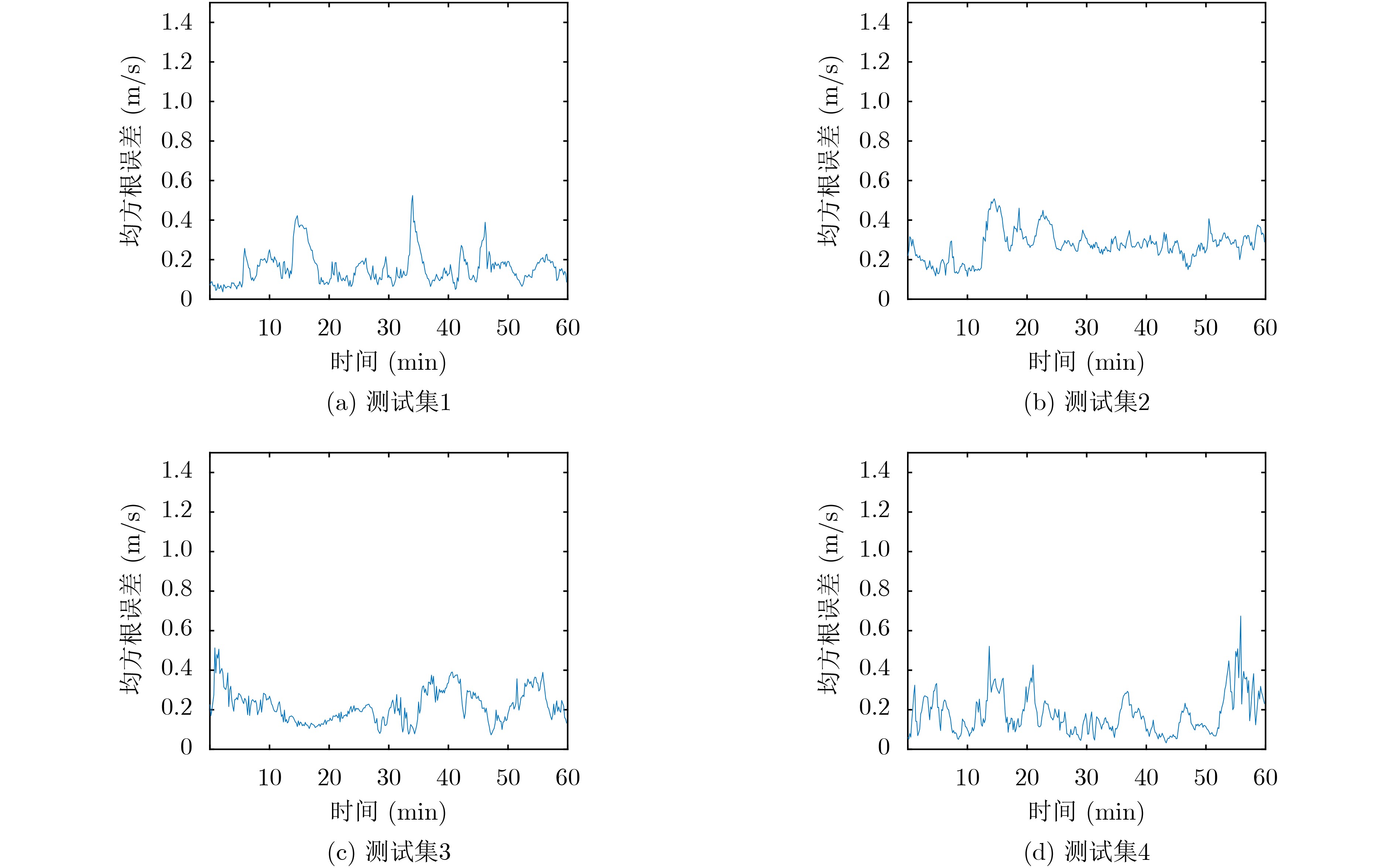
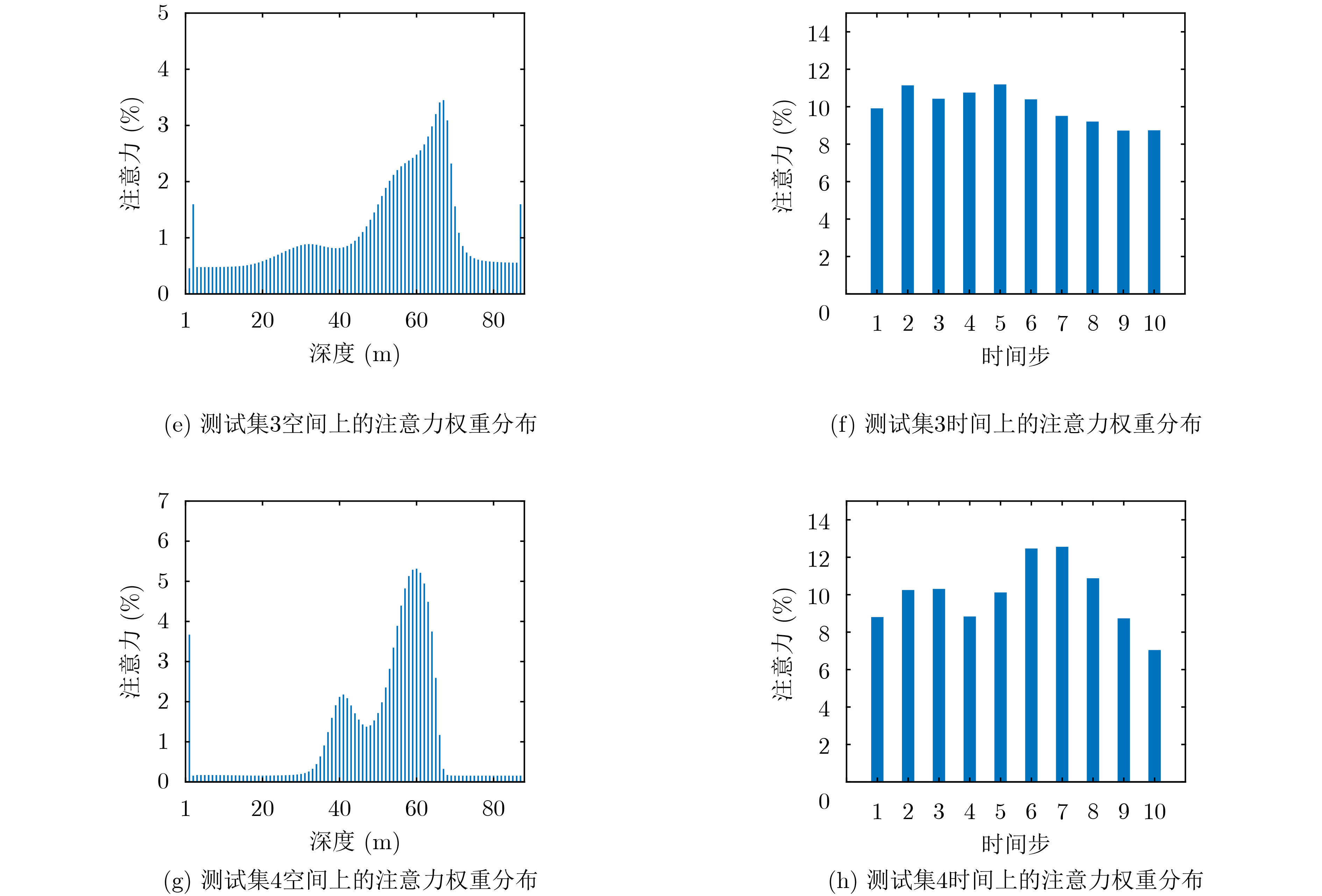
摘要: 海水中的声速剖面具有明显的时间演化特性,其预测问题可以看作一个非线性的时间序列预测问题。解决此类问题的常用方法大多使用预定义的非线性形式,无法捕捉真正潜在的非线性关系。循环神经网络作为一种为序列建模特别设计的深度神经网络,在捕捉非线性关系上具有极大的灵活性,在非线性自回归的时间序列预测这一问题上展现了它的有效性;注意力机制能够从众多信息中选择出对当前任务目标最关键的信息,对多变量时间序列在时空维度上的非线性关系进行捕捉。该文利用深度学习中的循环神经网络,添加双层注意力机制构建多变量时间序列预测模型,对浅海环境下时变的全海深声速剖面进行预测。多个模型的预测结果表明,该模型相对于单纯的编码-解码模型有着明显的预测性能提升,并且注意力权重的分布能够与实际物理现象相关联,为水声学中物理模型与机器学习的结合提供了新的思路。Abstract: The Sound Speed Profiles (SSPs) in sea water have obvious time evolution characteristics, and their prediction can be regarded as a nonlinear time series prediction. Recurrent Neural Networks (RNN), a type of deep neural network designed for sequence modeling, can capture nonlinear relationships flexibly. Attention Mechanism (AM), which selects the most critical information for the current task, can describe the nonlinear relationships in space and temporal dimensions. In this paper, RNN and AM are used to construct a multivariate time series prediction model to learn the historical SSPs and predict the time-varying full-sea SSPs in shallow sea environment. Experiments on real sound speed data show that the proposed method is effective and outperforms other methods, and provides a new idea for the combination of physical model and machine learning in underwater acoustics.
-
表 1 不同模型对全海深声速剖面的预测性能
模型 数据集1 数据集2 数据集3 数据集4 $ \bar E $ $E_{ {\rm{best} } }$ $ \bar E $ ${E_{{\rm{best}}} }$ $ \bar E $ ${E_{{\rm{best}}} }$ $ \bar E $ ${E_{{\rm{best}}} }$ Encoder-Decoder (32) 0.3319 0.2370 0.5521 0.3818 0.3802 0.2264 0.2831 0.1763 Encoder-Decoder (64) 0.2899 0.2224 0.4395 0.3144 0.2590 0.2109 0.2225 0.1744 Encoder-Decoder (128) 0.2332 0.1802 0.3360 0.2631 0.2438 0.1362 0.1702 0.0925 Encoder-Decoder (256) 0.1953 0.1604 0.2732 0.1678 0.1593 0.0923 0.1399 0.0885 Encoder-Attn-LSTM (32) 0.2467 0.1308 0.3564 0.2232 0.2178 0.1028 0.1375 0.0987 Encoder-Attn-LSTM (64) 0.2263 0.1210 0.3128 0.2216 0.1884 0.1132 0.1197 0.0842 Encoder-Attn-LSTM (128) 0.2001 0.1201 0.2835 0.1881 0.1525 0.0956 0.1055 0.0691 Encoder-Attn-LSTM (256) 0.1776 0.0931 0.2595 0.2022 0.0942 0.0563 0.0919 0.0541 Decoder-Attn-LSTM (32) 0.2245 0.1672 0.3769 0.2592 0.2103 0.1076 0.1293 0.0976 Decoder-Attn-LSTM (64) 0.2091 0.1635 0.3384 0.2150 0.1879 0.1101 0.1172 0.0807 Decoder-Attn-LSTM (128) 0.2061 0.1250 0.3129 0.2427 0.1508 0.0939 0.1029 0.0667 Decoder-Attn-LSTM (256) 0.1591 0.1111 0.2658 0.1628 0.1023 0.0597 0.0911 0.0620 DA-LSTM(32) 0.1072 0.0515 0.1794 0.1005 0.1287 0.0711 0.1245 0.1010 DA-LSTM (64) 0.0975 0.0456 0.1477 0.0948 0.1068 0.0512 0.1019 0.0532 DA-LSTM (128) 0.0802 0.0428 0.1264 0.0878 0.0806 0.0459 0.0893 0.0708 DA-LSTM (256) 0.0609 0.0312 0.1116 0.0811 0.0604 0.0341 0.0768 0.0414  下载: 导出CSV
下载: 导出CSV
-
[1] 李启虎. 水声学研究进展[J]. 声学学报, 2001, 26(4): 295–301. doi: 10.3321/j.issn:0371-0025.2001.04.002LI Qihu. Advances of research work in underwater acoustics[J]. Acta Acustica, 2001, 26(4): 295–301. doi: 10.3321/j.issn:0371-0025.2001.04.002 [2] 汪德昭, 尚尔昌. 水声学[M]. 2版. 北京: 科学出版社, 2013: 9. [3] 张建华. 海温预报知识讲座 第一讲 海水温度预报概况[J]. 海洋预报, 2003, 20(4): 81–85. doi: 10.3969/j.issn.1003-0239.2003.04.013ZHANG Jianhua. Lectures on sea surface temperature prediction[J]. Marine Forecasts, 2003, 20(4): 81–85. doi: 10.3969/j.issn.1003-0239.2003.04.013 [4] KURAPOV A L, EGBERT G D, MILLER R N, et al. Data assimilation in a Baroclinic coastal ocean model: Ensemble statistics and comparison of methods[J]. Monthly Weather Review, 2002, 130(4): 1009–1025. doi: 10.1175/1520-0493(2002)130<1009:DAIABC>2.0.CO;2 [5] MUNK W, WORCESTER P, and CWUNSCH C. Ocean Acoustic Tomography[M]. Cambridge: Cambridge University Press, 1995. [6] LEBLANC L R and MIDDLETON F H. An underwater acoustic sound velocity data model[J]. The Journal of the Acoustical Society of America, 1980, 67(6): 2055–2062. doi: 10.1121/1.384448 [7] DAUGHERTY J R and LYNCH J F. Surface wave, internal wave, and source motion effects on matched field processing in a shallow water waveguide[J]. The Journal of the Acoustical Society of America, 1990, 87(6): 2503–2526. doi: 10.1121/1.399098 [8] TOLSTOY A, DIACHOK O, and FRAZER L N. Acoustic tomography via matched field processing[J]. The Journal of the Acoustical Society of America, 1991, 89(3): 1119–1127. doi: 10.1121/1.400647 [9] ZHU Guolei, WANG Yingmin, and WANG Qi. Matched field processing based on Bayesian estimation[J]. Sensors, 2020, 20(5): 1374. doi: 10.3390/s20051374 [10] SHEN Yining, PAN Xiang, ZHENG Zheng, et al. Matched-field geoacoustic inversion based on radial basis function neural network[J]. The Journal of the Acoustical Society of America, 2020, 148(5): 3279–3290. doi: 10.1121/10.0002656 [11] 崔宝龙, 徐国军, 笪良龙, 等. 采用小生境遗传算法反演浅海声速剖面研究[J]. 应用声学, 2021, 40(2): 279–286. doi: 10.11684/j.issn.1000-310X.2021.02.016CUI Baolong, XU Guojun, DA Lianglong, et al. Shallow sea sound speed profile inversion based on niche genetic algorithm[J]. Applied Acoustics, 2021, 40(2): 279–286. doi: 10.11684/j.issn.1000-310X.2021.02.016 [12] TAROUDAKIS M I and PAPADAKIS J S. A modal inversion scheme for ocean acoustic tomography[J]. Journal of Computational Acoustics, 1993, 1(4): 395–421. doi: 10.1142/S0218396X93000214 [13] SKARSOULIS E K, ATHANASSOULIS G A, and SEND U. Ocean acoustic tomography based on peak arrivals[J]. The Journal of the Acoustical Society of America, 1996, 100(2): 797–813. doi: 10.1121/1.416212 [14] YARDIM C, GERSTOFT P, and HODGKISS W S. Tracking of geoacoustic parameters using Kalman and particle filters[J]. The Journal of the Acoustical Society of America, 2009, 125(2): 746–760. doi: 10.1121/1.3050280 [15] CARRIÈRE O, HERMAND J P, LE GAC J C, et al. Full-field tomography and Kalman tracking of the range-dependent sound speed field in a coastal water environment[J]. Journal of Marine Systems, 2009, 78 Suppl: S382-S392. [16] CARRIERE O, HERMAND J P, and CANDY J V. Inversion for time-evolving sound-speed field in a shallow ocean by ensemble Kalman filtering[J]. IEEE Journal of Oceanic Engineering, 2009, 34(4): 586–602. doi: 10.1109/JOE.2009.2033954 [17] 金丽玲, 李建龙, 徐文. 自回归状态空间模型下时变声速剖面跟踪方法[J]. 声学学报, 2016, 41(6): 813–819.JIN Liling, LI Jianlong, and XU Wen. Tracking of time-evolving sound speed profiles with the auto-regressive state-space model[J]. Acta Acustica, 2016, 41(6): 813–819. [18] 苏林, 任群言, 庞立臣, 等. 强非线性时间演化声速剖面的序贯反演[J]. 声学学报, 2019, 44(4): 452–462.SU Lin, REN Qunyan, PANG Lichen, et al. Sequential inversion of highly nonlinear time-evolving sound speed profiles[J]. Acta Acustica, 2019, 44(4): 452–462. [19] 庞立臣, 胡涛, 傅德龙, 等. 集合卡尔曼滤波在时变声速剖面追踪中的性能分析[J]. 声学学报, 2020, 45(2): 176–188.PANG Lichen, HU Tao, FU Delong, et al. Performances of the ensemble Kalman filter on the tracking of time-evolving sound speed profiles[J]. Acta Acustica, 2020, 45(2): 176–188. [20] LINS I D, DAS CHAGAS MOURA M, SILVA M A, et al. Sea surface temperature prediction via support vector machines combined with particle swarm optimization[C]. International Probabilistic Safety Assessment & Management Conference, Seattle, USA, 2010: 16–29. [21] TANGANG F T, HSIEH W W, and TANG B. Forecasting the equatorial Pacific sea surface temperatures by neural network models[J]. Climate Dynamics, 1997, 13(2): 135–147. doi: 10.1007/s003820050156 [22] NOWRUZI H and GHASSEMI H. Using artificial neural network to predict velocity of sound in liquid water as a function of ambient temperature, electrical and magnetic fields[J]. Journal of Ocean Engineering and Science, 2016, 1(3): 203–211. doi: 10.1016/j.joes.2016.07.001 [23] JAIN S and ALI M M. Estimation of sound speed profiles using artificial neural networks[J]. IEEE Geoscience and Remote Sensing Letters, 2006, 3(4): 467–470. doi: 10.1109/LGRS.2006.876221 [24] SUN Sijia and ZHAO Hangfang. Sparse representation of sound speed profiles based on dictionary learning[C]. 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 2020: 484–488. [25] ZHANG Qin, WANG Hui, DONG Junyu, et al. Prediction of sea surface temperature using long short-term memory[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(10): 1745–1749. doi: 10.1109/LGRS.2017.2733548 [26] SARKAR P, JANARDHAN P, and ROY P. Applicability of a long short-term memory deep learning network in sea surface temperature predictions[C]. Earth 1st International Conference on Water Security and Sustainability, Rangpo, Indin, 2019. [27] SARKAR P P, JANARDHAN P, and ROY P. Prediction of sea surface temperatures using deep learning neural networks[J]. SN Applied Sciences, 2020, 2(8): 1458. doi: 10.1007/s42452-020-03239-3 [28] QIN Yao, SONG Dongjin, CHENG Haifeng, et al. A dual-stage attention-based recurrent neural network for time series prediction[C]. Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 2017: 2627–2633. [29] HUANG Siteng, WANG Donglin, WU Xuehan, et al. DSANet: Dual self-attention network for multivariate time series forecasting[C]. Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 2019: 2129–2132. [30] MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2204–2212. -

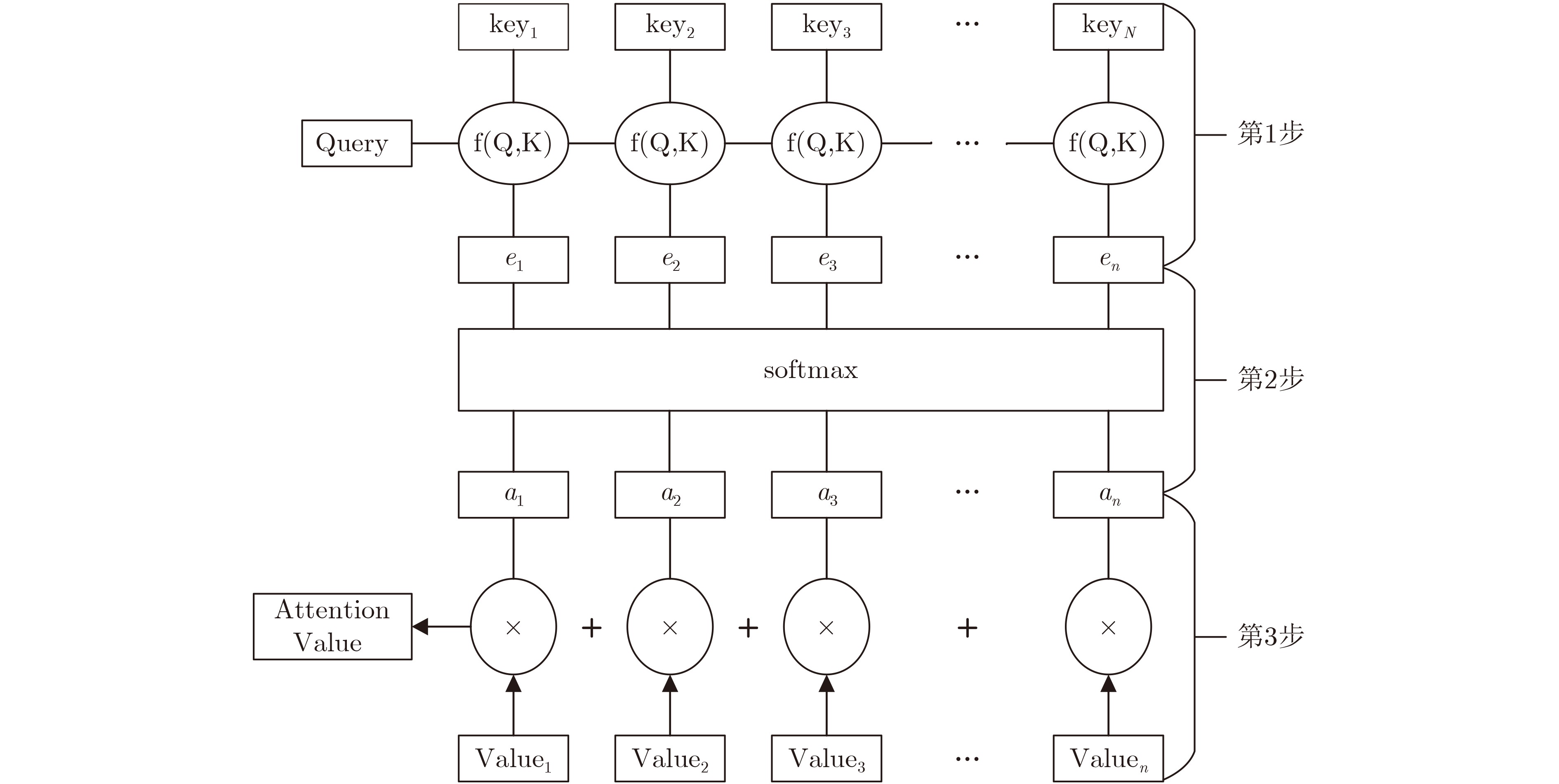
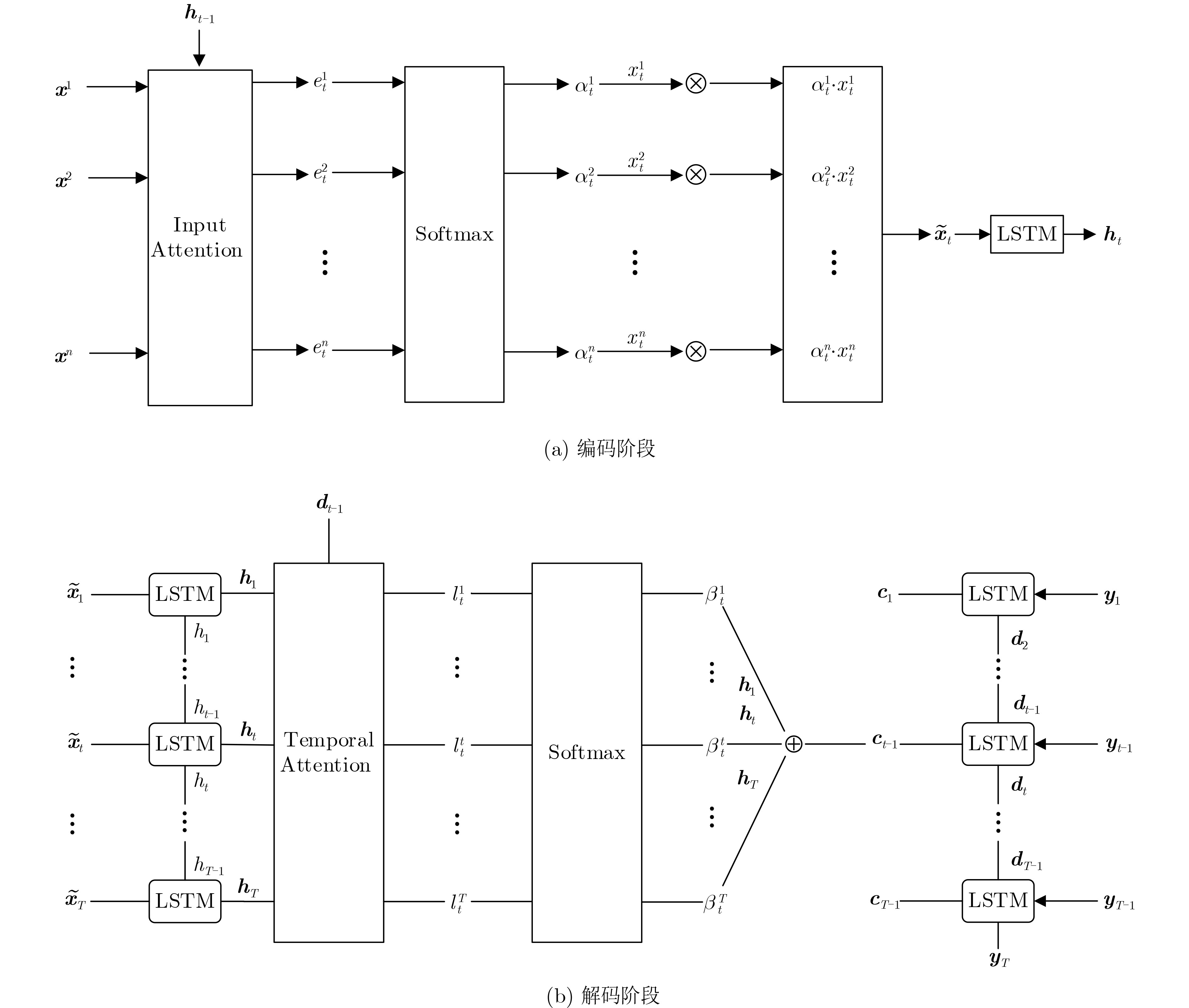
 下载:
下载:

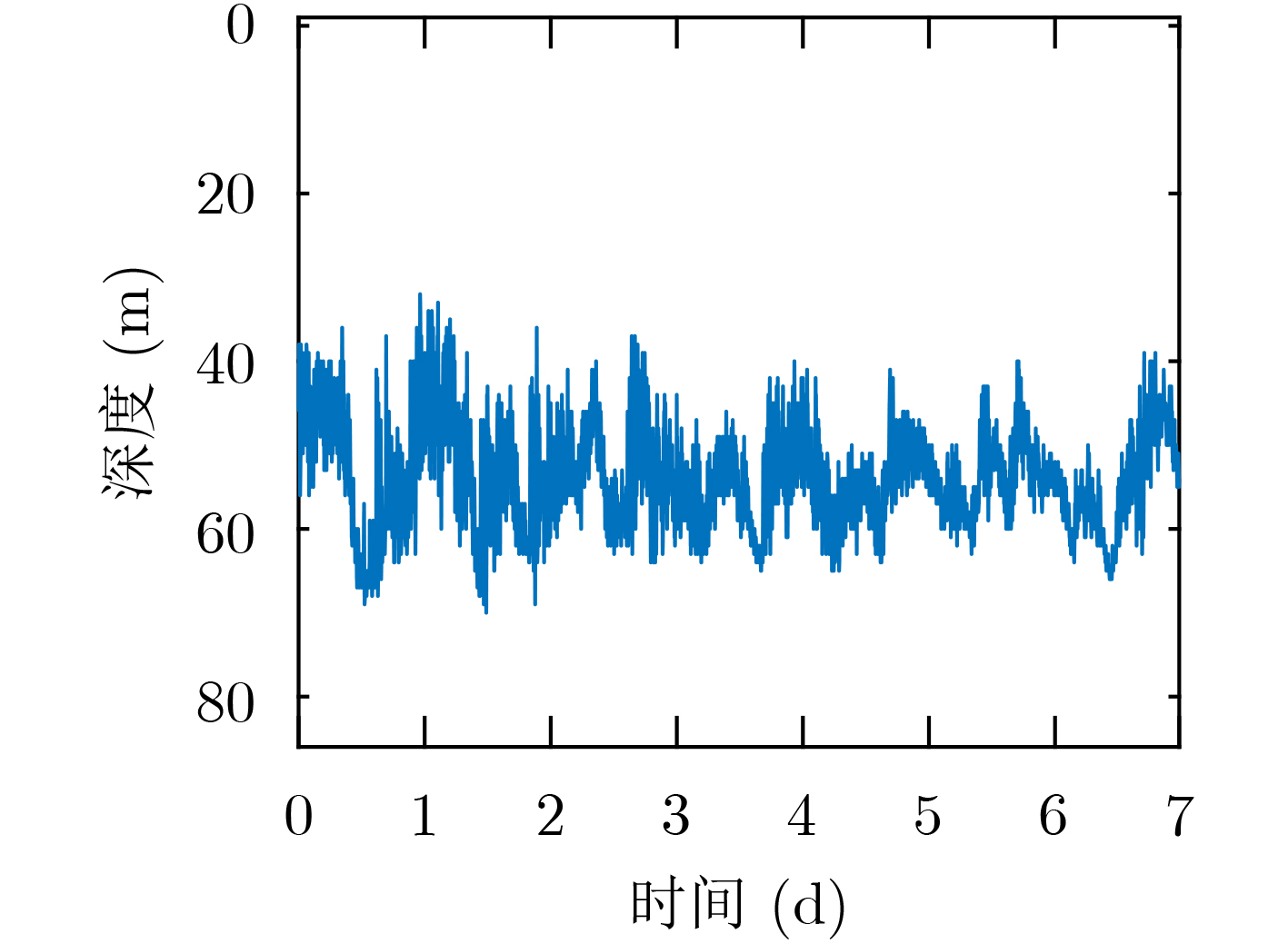

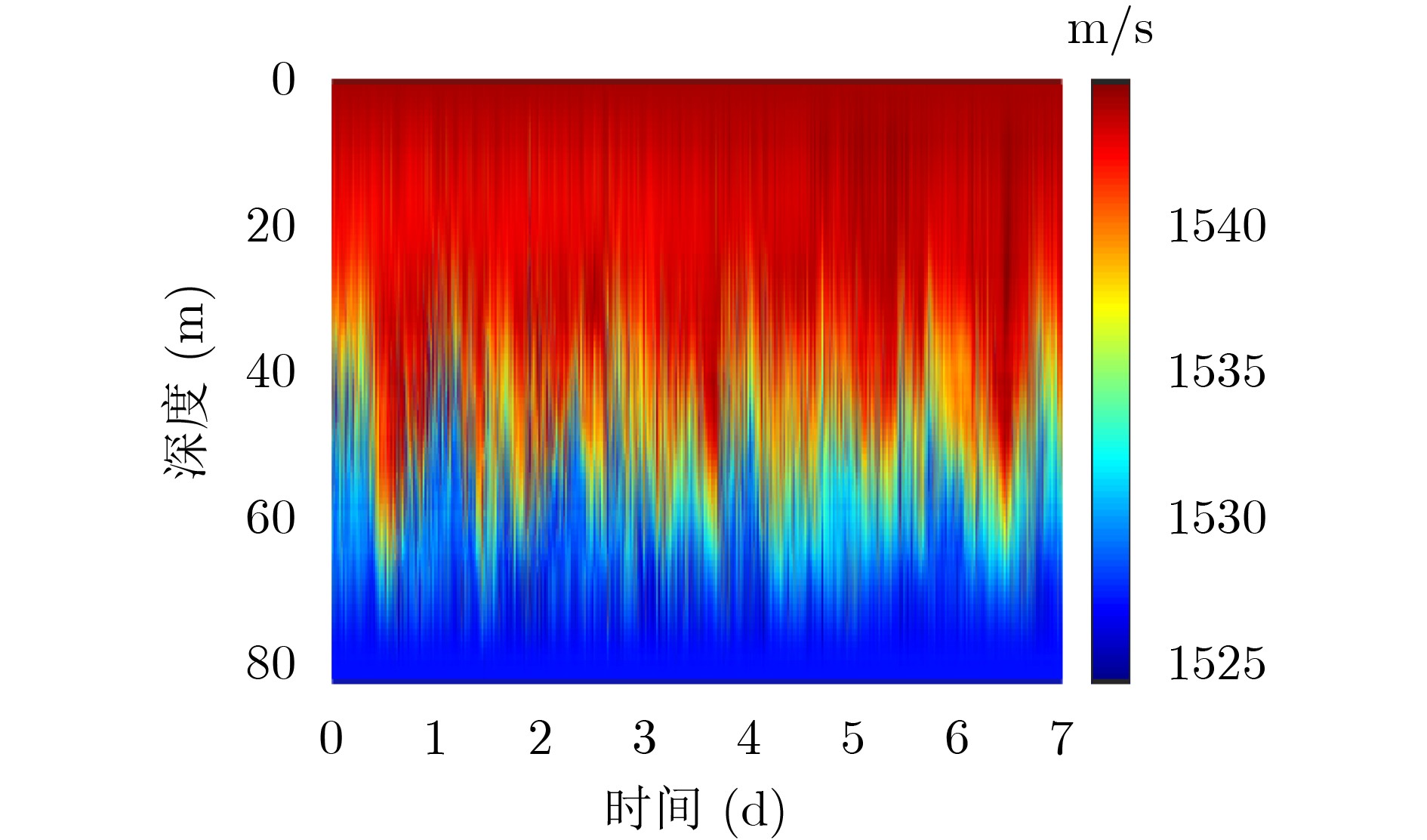




图(11) / 表(1)
计量
- 文章访问数: 1896
- HTML全文浏览量: 1012
- PDF下载量: 170
- 被引次数: 0
