

Online Service Function Chain Deployment Method Based on Deep Q Network
-
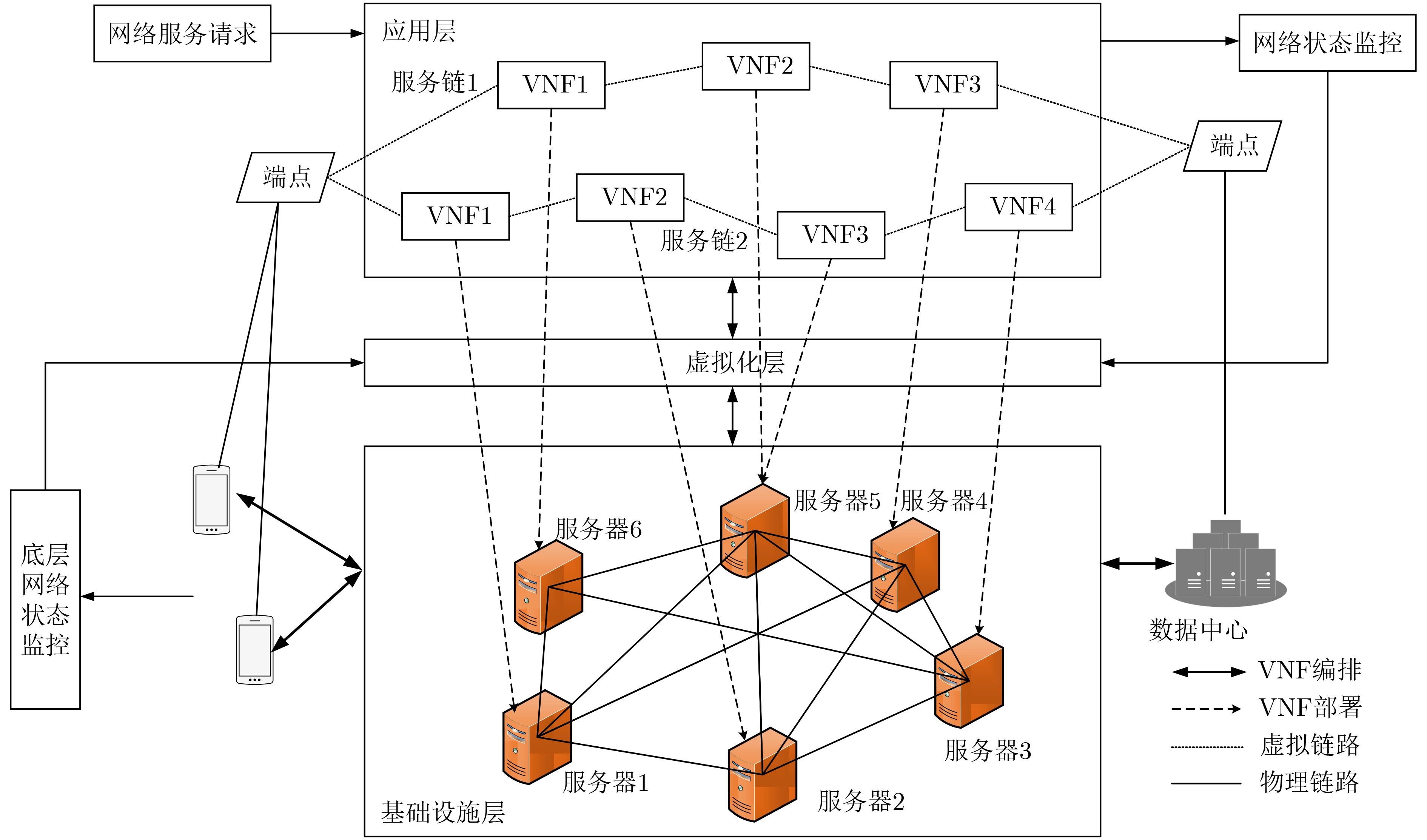
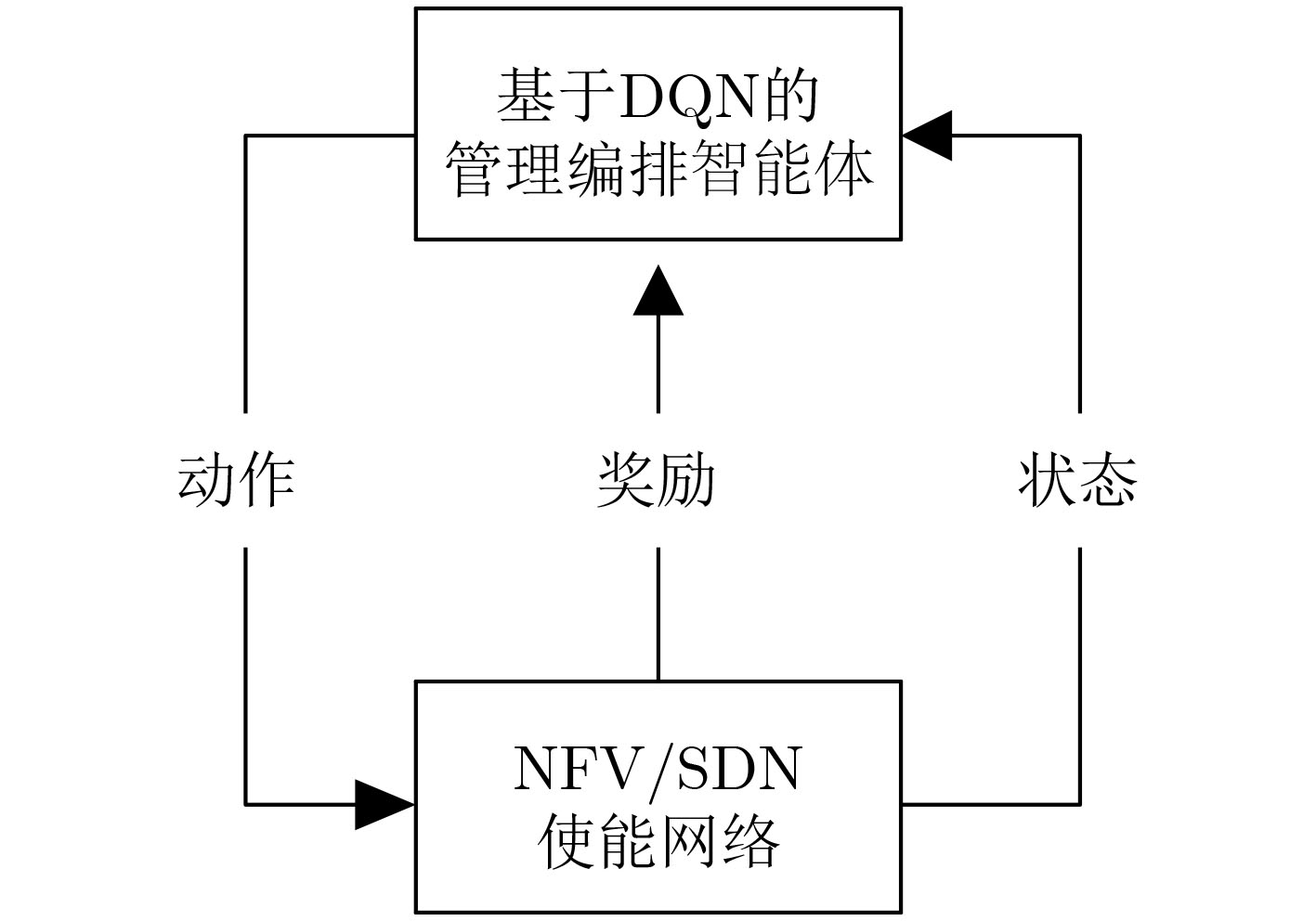
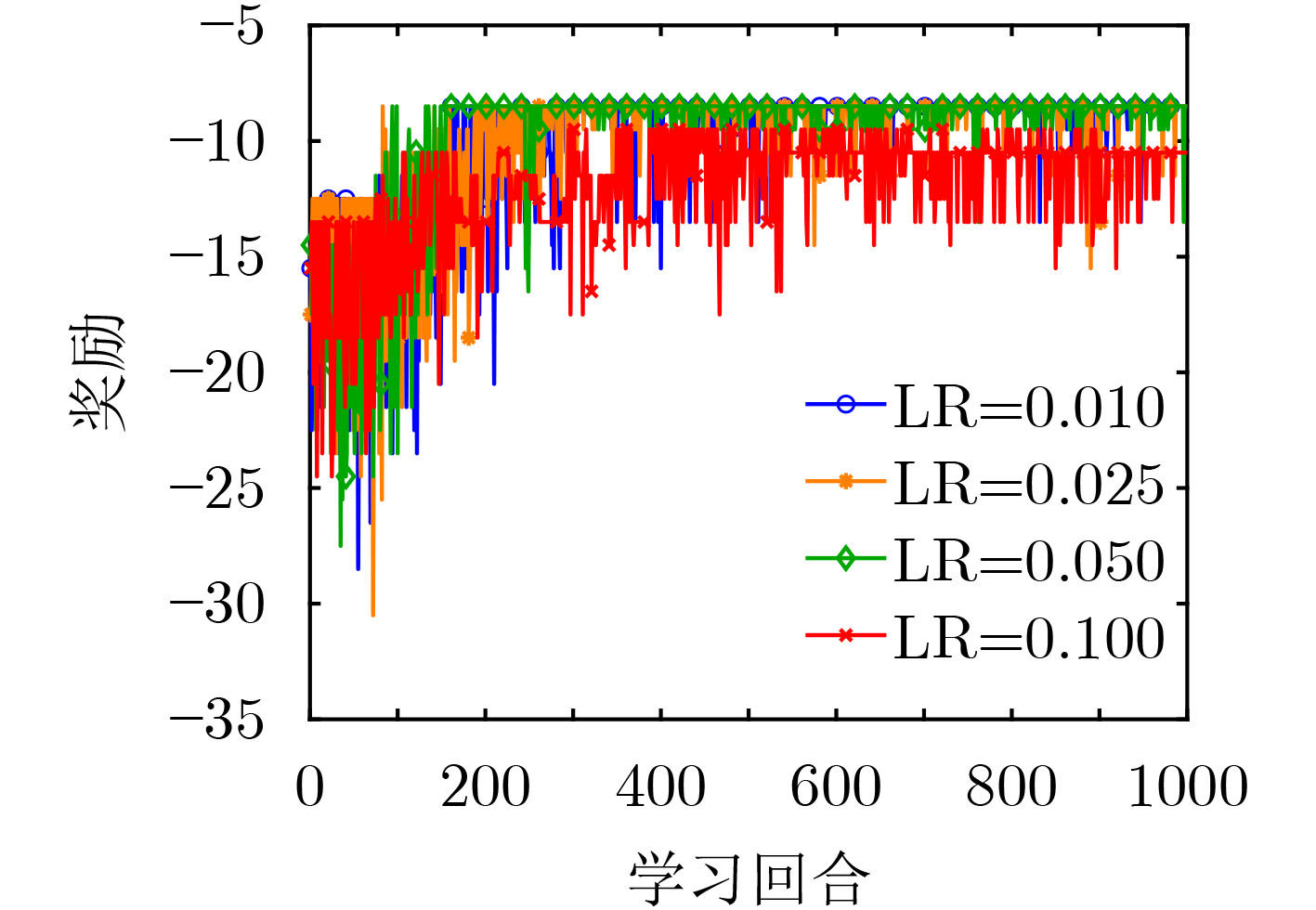
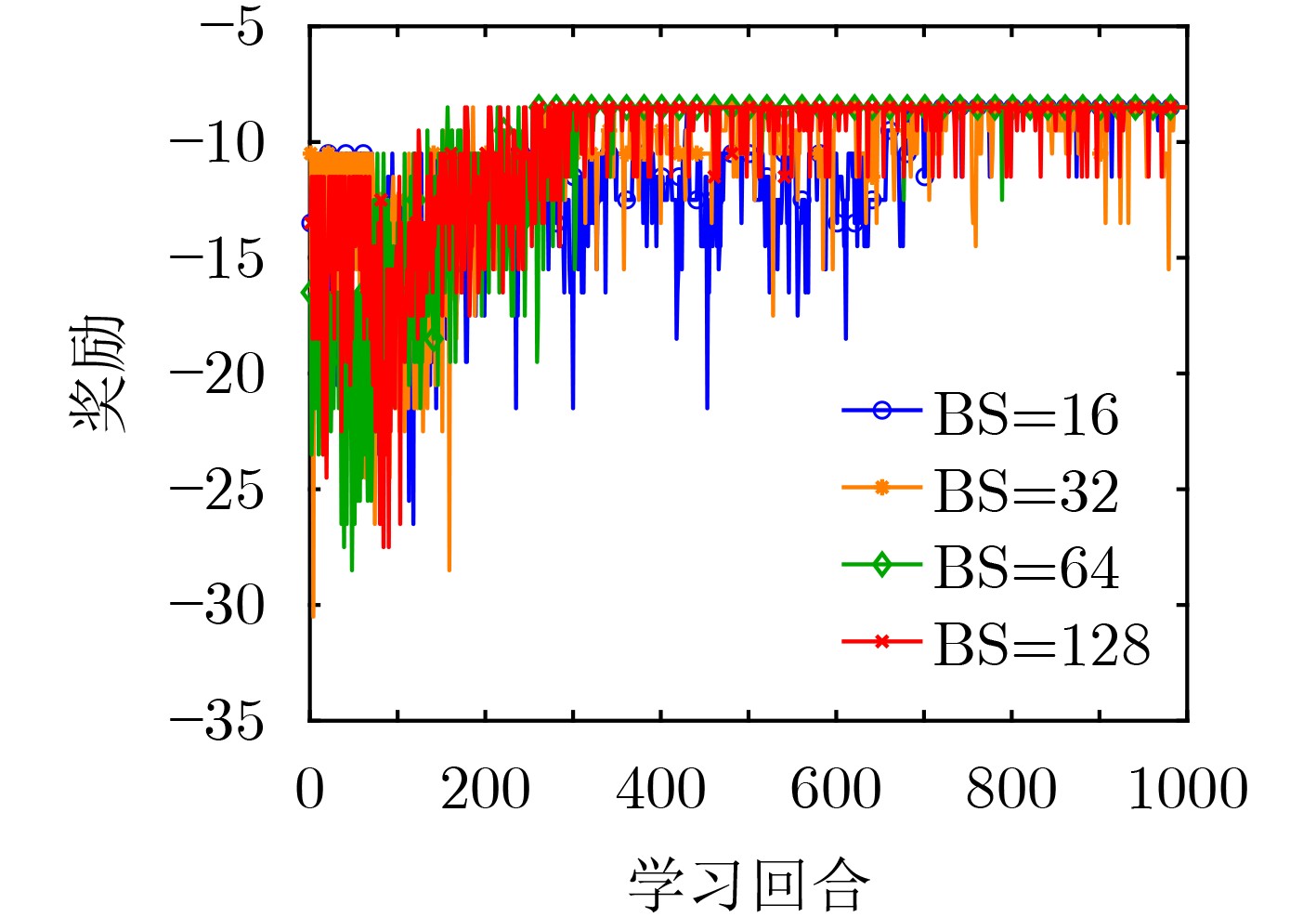
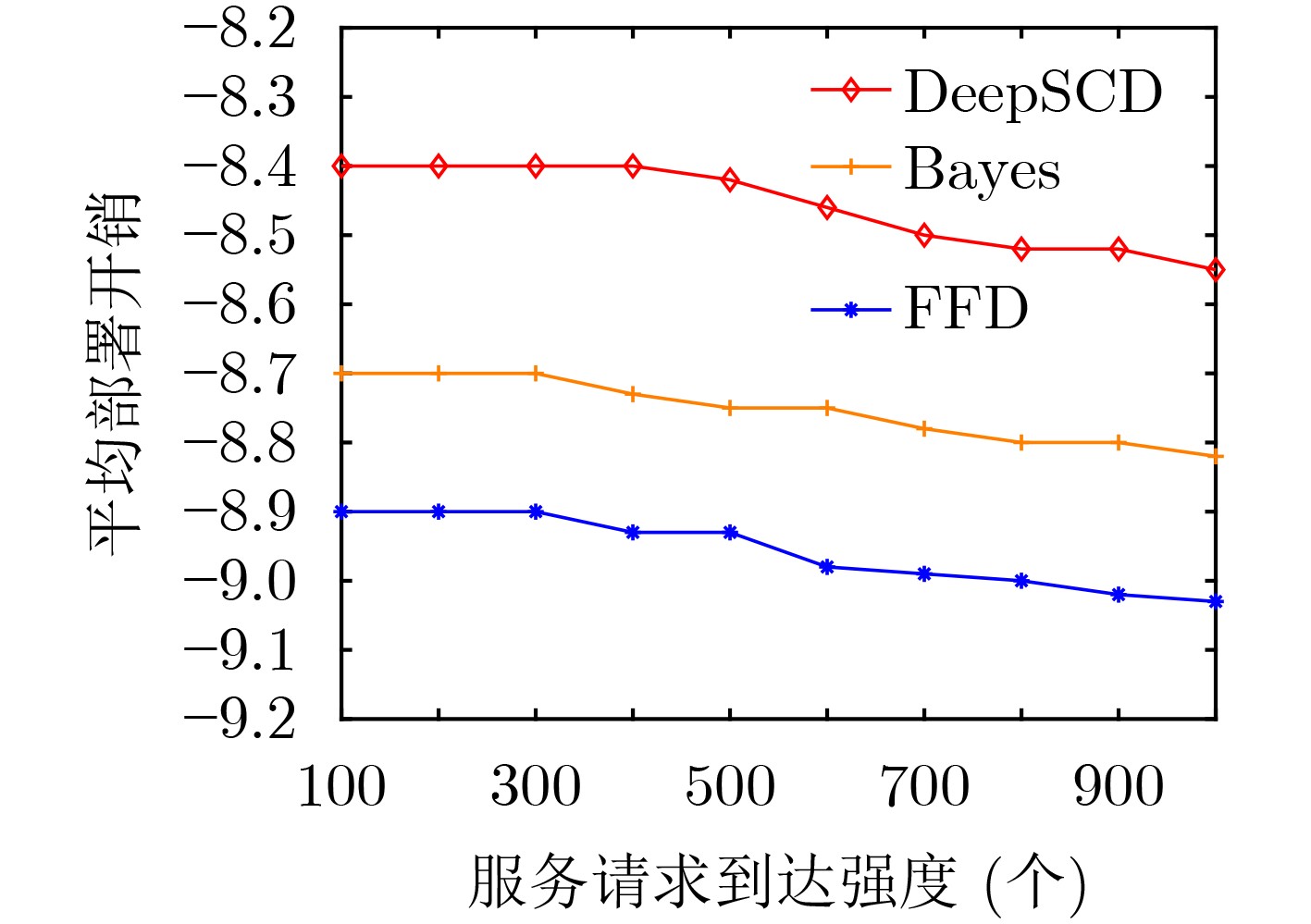
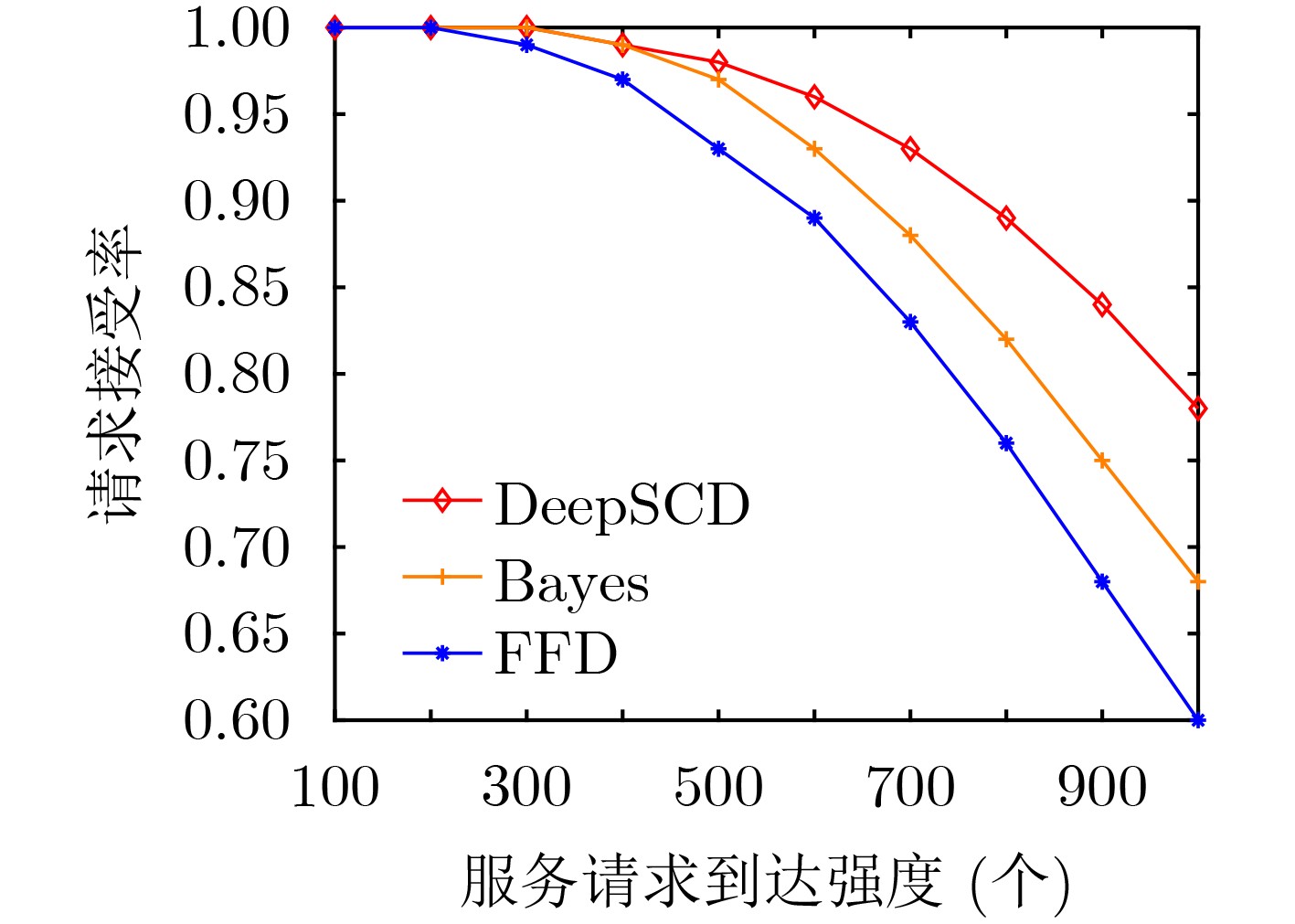
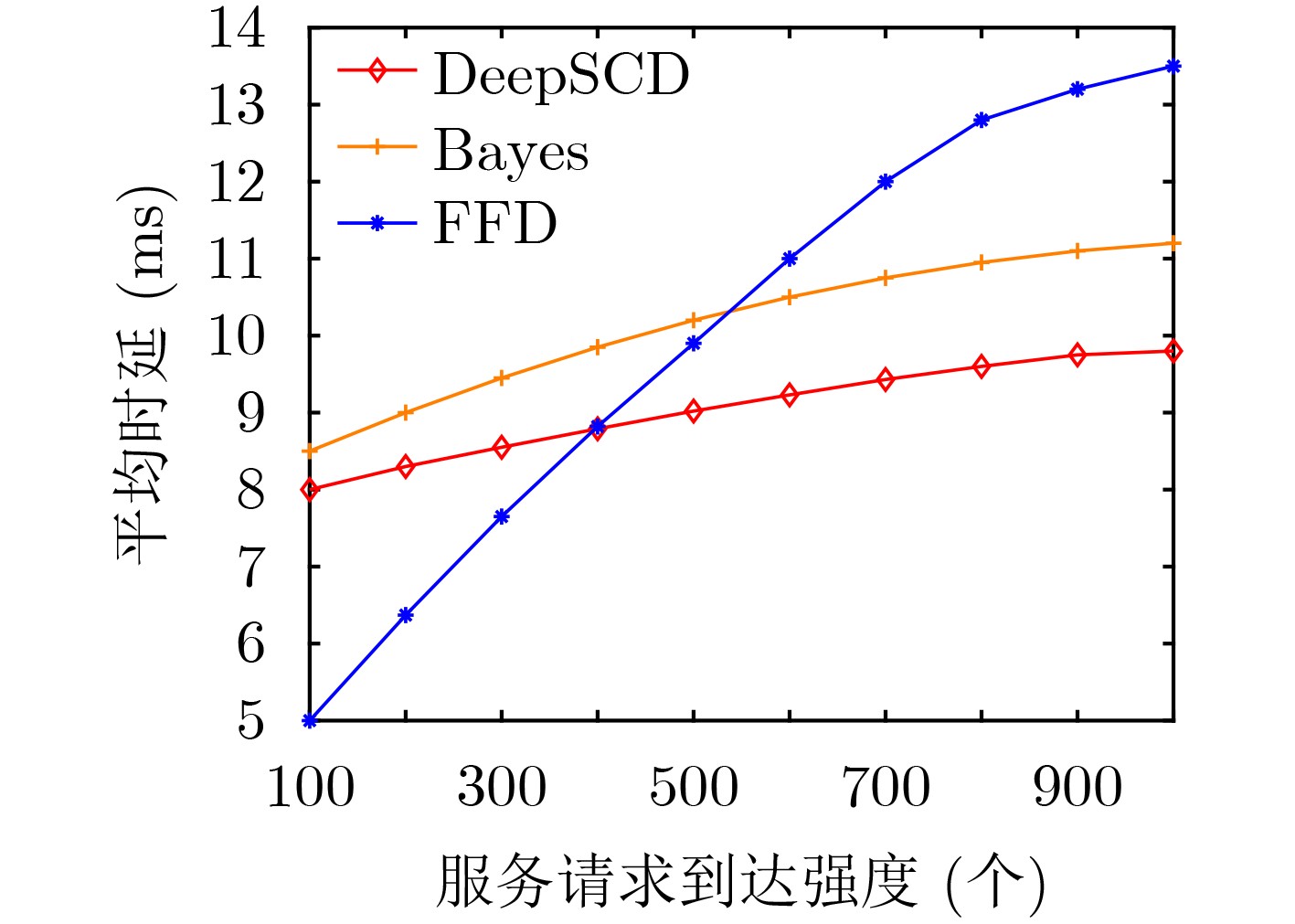
摘要: 针对5G网络资源状态动态变化和网络模型高维度下服务功能链部署的复杂性问题,该文提出一种基于深度Q网络的在线服务功能链部署方法(DeePSCD)。首先,为描述网络资源动态变化的特征,将服务功能链部署建模成马尔可夫决策过程,然后,针对系统资源模型的高维度问题采用深度Q网络的方法进行在线服务功能链部署策略求解。该方法可以有效描述网络资源状态的动态变化,特别是深度Q网络能有效克服求解复杂度,优化服务功能链的部署开销。仿真结果表明,所提方法在满足服务时延约束条件下降低了服务功能链的部署开销,提高了运营商网络的服务请求接受率。Abstract: To deal with the dynamic nature of 5G network resource state and the difficulty of service function chain deployment under the high-dimensional network state model, an online Service function Chain Deployment method based on Deep Q network (DeePSCD) is proposed. First, to describe the dynamic nature of network resource state, the service function chain deployment is modeled as a Markov decision process. Then, the deep Q network is used to solve the online service function chain deployment problem in the high-dimensional system resource model. This method can effectively describe the dynamic changes of network resource state. Specifically, deep Q network handles the complexity of problem and determines the optimal deployment solution of service function chain. Simulation results show that the proposed method can reduce the deployment cost of the service function chain and increase the acceptance rate while meeting the service delay constraint.
-
表 1 算法1 基于DQN的在线服务链部署算法
输入:服务链信息${G_r} = \left( {N_r^{'},L_r^{'}} \right)$和当前网络状态${s_t}$ 输出:服务链部署策略$\pi _Q^*$ (1) 初始化经验复用池${{D} }$的容量${{M} }$ (2) 初始化动作对应的$Q$值为随机值 (3) 初始化选择策略$\pi $ (4) for episode in range(EPISODES): (5) 初始化状态$s$ (6) for step in range(STEPS): (7) 检查底层网络资源状态,生成满足条件服务器节点集合$\varPhi$ (8) 以$\varepsilon $的概率随机选择一个动作${a_t}$ (9) 否则选择${a_t} = {\max _a}{Q^*}\left( {{s_t},a;\theta } \right)$ (10) 在服务链部署模拟器中执行动作${a_t}$并观察对应的奖励
${r_t}$和下一个状态${s_{t + 1}}$(11) 在经验复用池中存储样本${e_t} = \left( {{s_t},{a_t},{r_t},{s_{t + 1}}} \right)$ (12) 从经验复用池中随机抽取小批量的样本$\left( {s_j},{a_j},{r_j},\right. $
$ \left.{s_{j + 1}} \right)$(13) 令${y_j} = \left\{ {\begin{array}{*{20}{c} } { {r_j} },& { {r_j} = {\rm{end} } } \\ { {r_j} + \gamma { {\max }_{a'} }Q\left( { {s_{j + 1} },a';\theta } \right)},& { {r_j} \ne {\rm{end} } } \end{array} } \right.$ (14) 在${\left( {{y_j} - Q\left( {{s_{j + 1}},a;\theta } \right)} \right)^2}$上执行梯度下降 (15) 每L步更新目标网络参数${\theta ^ - }$ (16) end (17) end (18) 根据${Q^*}\left( {{s_t},a;\theta } \right)$计算服务链部署方案${\pi ^*}$及其开销R  下载: 导出CSV
下载: 导出CSV
-
[1] ETSI. Network Functions Virtualisation (NFV)[EB/OL]. https://www.etsi.org/technologies/nfv, 2020. [2] YI Bo, WANG Xingwei, LI Keqin, et al. A comprehensive survey of network function virtualization[J]. Computer Networks, 2018, 133: 212–262. doi: 10.1016/j.comnet.2018.01.021 [3] ERAMO V, MIUCCI E, AMMAR M, et al. An approach for service function chain routing and virtual function network instance migration in network function virtualization architectures[J]. IEEE/ACM Transactions on Networking, 2017, 25(4): 2008–2025. doi: 10.1109/TNET.2017.2668470 [4] KARAKUS M and DURRESI A. A survey: Control plane scalability issues and approaches in Software-Defined Networking (SDN)[J]. Computer Networks, 2017, 112: 279–293. doi: 10.1016/j.comnet.2016.11.017 [5] BHAMARE D, JAIN R, SAMAKA M, et al. A survey on service function chaining[J]. Journal of Network and Computer Applications, 2016, 75: 138–155. doi: 10.1016/j.jnca.2016.09.001 [6] MIJUMBI R, SERRAT J, GORRICHO J L, et al. Network function virtualization: State-of-the-art and research challenges[J]. IEEE Communications Surveys & Tutorials, 2016, 18(1): 236–262. doi: 10.1109/COMST.2015.2477041 [7] BARI M F, CHOWDHURY S R, AHMED R, et al. Orchestrating virtualized network functions[J]. IEEE Transactions on Network and Service Management, 2016, 13(4): 725–739. doi: 10.1109/TNSM.2016.2569020 [8] LIU Jiaqiang, LI Yong, ZHANG Ying, et al. Improve service chaining performance with optimized middlebox placement[J]. IEEE Transactions on Services Computing, 2017, 10(4): 560–573. doi: 10.1109/TSC.2015.2502252 [9] KUO T W, LIOU B H, LIN K C J, et al. Deploying chains of virtual network functions: On the relation between link and server usage[C]. IEEE INFOCOM 2016 - the 35th Annual IEEE International Conference on Computer Communications, San Francisco, USA, 2016: 1–9. doi: 10.1109/INFOCOM.2016.7524565. [10] SUN Quanying, LU Ping, LU Wei, et al. Forecast-assisted NFV service chain deployment based on affiliation-aware vNF placement[C]. 2016 IEEE Global Communications Conference (GLOBECOM), Washington, USA, 2016: 1–6. doi: 10.1109/GLOCOM.2016.7841846. [11] LI Defang, HONG Peilin, XUE Kaiping, et al. Virtual network function placement considering resource optimization and SFC requests in cloud datacenter[J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 29(7): 1664–1677. doi: 10.1109/TPDS.2018.2802518 [12] HAWILO H, JAMMAL M, and SHAMI A. Network function virtualization-aware orchestrator for service function chaining placement in the cloud[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(3): 643–655. doi: 10.1109/JSAC.2019.2895226 [13] TANG Hong, ZHOU D, and CHEN Duan. Dynamic network function instance scaling based on traffic forecasting and VNF placement in operator data centers[J]. IEEE Transactions on Parallel and Distributed Systems, 2019, 30(3): 530–543. doi: 10.1109/TPDS.2018.2867587 [14] QI Dandan, SHEN Subin, and WANG Guanghui. Towards an efficient VNF placement in network function virtualization[J]. Computer Communications, 2019, 138: 81–89. doi: 10.1016/j.comcom.2019.03.005 [15] SINGH S, OKUN A, and JACKSON A. Learning to play Go from scratch[J]. Nature, 2017, 550(7676): 336–337. doi: 10.1038/550336a [16] 袁泉, 汤红波, 黄开枝, 等. 基于Q-learning算法的vEPC虚拟网络功能部署方法[J]. 通信学报, 2017, 38(8): 172–182. doi: 10.11959/j.issn.1000-436x.2017173YUAN Quan, TANG Hongbo, HUANG Kaizhi, et al. Deployment method for vEPC virtualized network function via Q-learning[J]. Journal on Communications, 2017, 38(8): 172–182. doi: 10.11959/j.issn.1000-436x.2017173 [17] XIAO Yikai, ZHANG Qixia, LIU Fangming, et al. NFVdeep: Adaptive online service function chain deployment with deep reinforcement learning[C]. Proceedings of the International Symposium on Quality of Service, Arizona, USA, 2019: 1–10. doi: 10.1145/3326285.3329056. [18] QUANG P T A, HADJADJ-AOUL Y, and OUTTAGARTS A. A deep reinforcement learning approach for VNF forwarding graph embedding[J]. IEEE Transactions on Network and Service Management, 2019, 16(4): 1318–1331. doi: 10.1109/TNSM.2019.2947905 [19] KINGMAN J F C. Poisson Processes[M]. ARMITAGE P and COLTON T. Encyclopedia of Biostatistics. Chichester: John Wiley & Sons, 2005. doi: 10.1002/0470011815.b2a07042. [20] HOWARD R A. Dynamic programming and Markov processes[J]. Technometrics, 1961, 3(1): 120–121. doi: 10.2307/1266484 [21] The University of Adelaide. The internet topology zoo[EB/OL]. http://www.topology-zoo.org/dataset.html, 2012. [22] Networkx. Network analysis in python: Important structures and bipartite graphs[EB/OL]. https://coderzcolumn.com/tutorials/data-science/network-analysis-in-python-important-structures-and-bipartite-graphs-networkx, 2020. [23] YALA L, FRANGOUDIS P A, LUCARELLI G, et al. Cost and availability aware resource allocation and virtual function placement for CDNaaS provision[J]. IEEE Transactions on Network and Service Management, 2018, 15(4): 1334–1348. doi: 10.1109/TNSM.2018.2874524 [24] OCHOA-ADAY L, CERVELLÓ-PASTOR C, FERNÁNDEZ-FERNÁNDEZ A, et al. An online algorithm for dynamic NFV placement in cloud-based autonomous response networks[J]. Symmetry, 2018, 10(5): 163. doi: 10.3390/sym10050163 [25] MAROTTA A, ZOLA E, D’ANDREAGIOVANNI F, et al. A fast robust optimization-based heuristic for the deployment of green virtual network functions[J]. Journal of Network and Computer Applications, 2017, 95: 42–53. doi: 10.1016/j.jnca.2017.07.014 [26] SHI Runyu, ZHANG Jia, CHU Wenjing, et al. MDP and machine learning-based cost-optimization of dynamic resource allocation for network function virtualization[C]. 2015 IEEE International Conference on Services Computing, New York, USA, 2015: 65–73. doi: 10.1109/SCC.2015.19. -

 下载:
下载:



图(8) / 表(1)
计量
- 文章访问数: 1451
- HTML全文浏览量: 1146
- PDF下载量: 118
- 被引次数: 0
