

Fusion Bias Dynamic Expert Trust Recommendation Algorithm
-
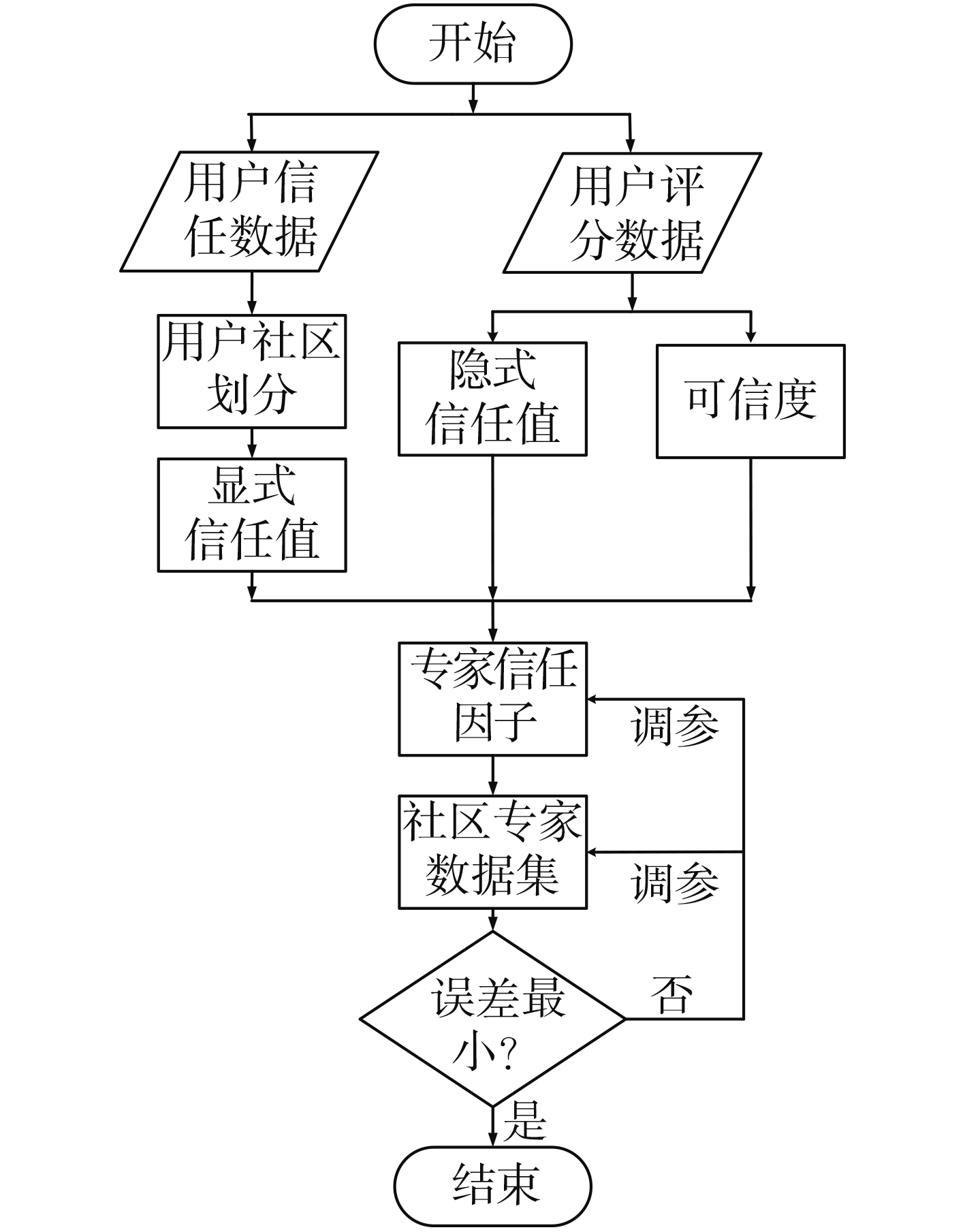
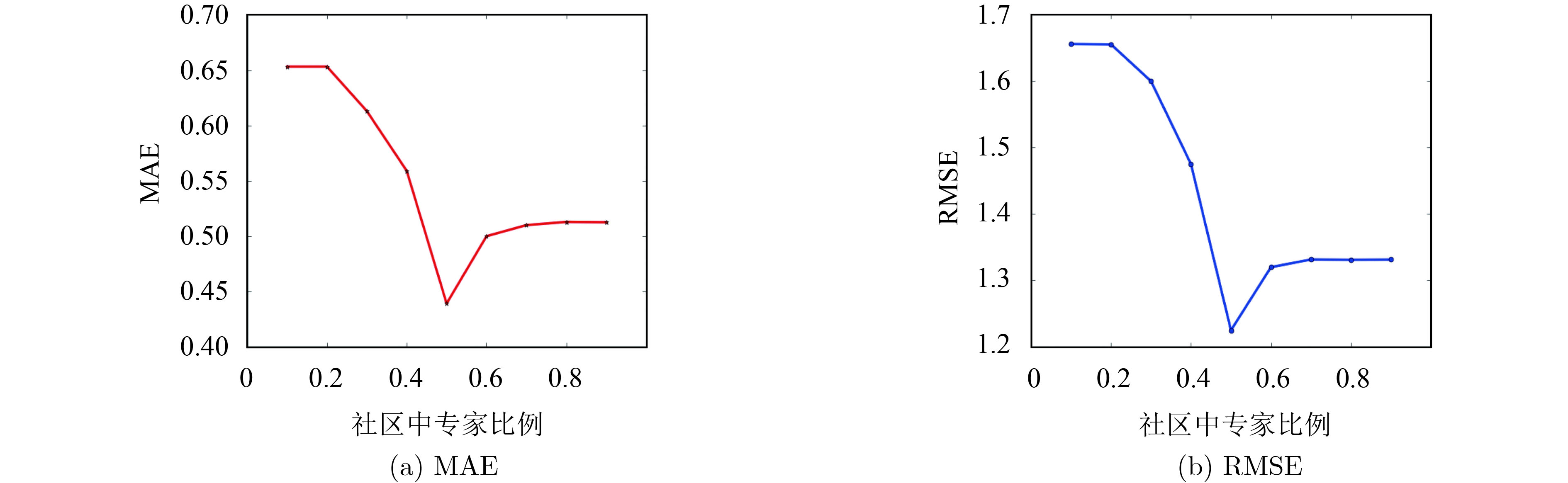
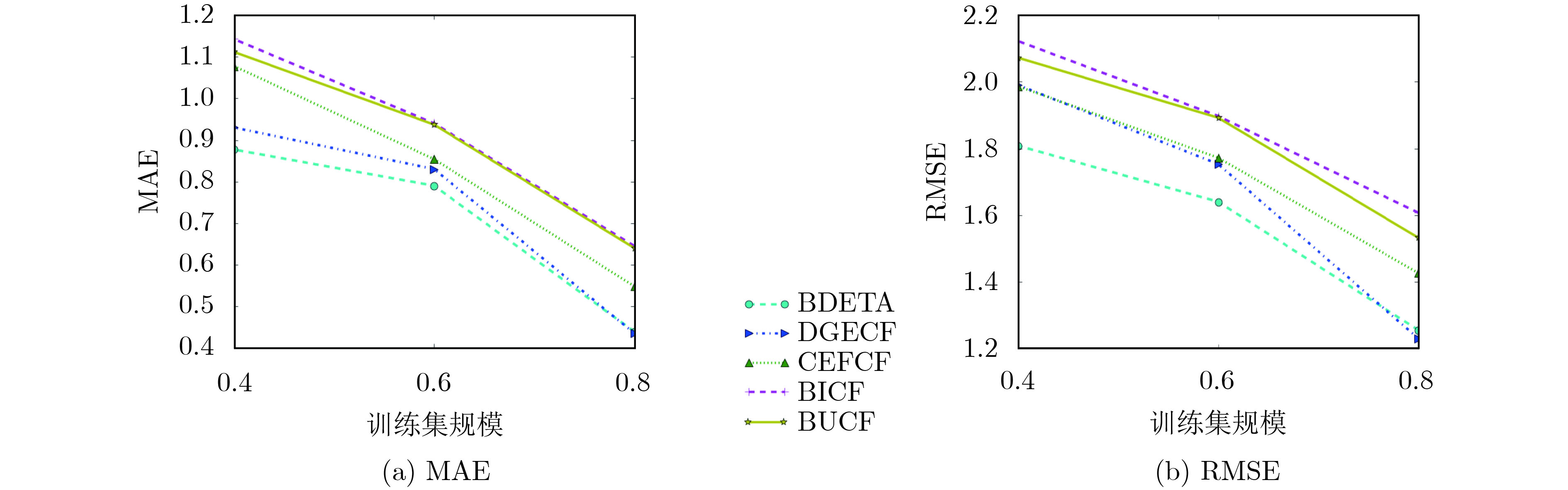
摘要: 针对协同过滤推荐算法中数据稀疏、冷启动与噪声用户对推荐质量的严重影响,该文将用户-项目评分数据与用户信任关系数据相结合;提出一种融合偏置的动态专家信任推荐算法(BDETA),首先根据用户信任关系数据进行社区划分,获取用户间显式信任值;其次从社区中用户-项目评分数据获取可信度、隐式信任值;通过结合用户间可信度、显式信任值、隐式信任值动态确定专家信任因子,根据用户的推荐能力为每个社区确定专家数据集;最后结合用户不同评分标准进行评分预测。在真实数据集FilmTrust的实验结果中,能够有效地解决协同过滤中冷启动与数据稀疏问题,可更好地满足用户的个性化推荐需求,并且在推荐系统常用评价指标MAE与RMSE中有着不错的表现。Abstract: In view of the severe influence of sparse data, cold start and irrelevant noise users on recommendation quality in collaborative filtering recommendation algorithm, this paper combines user-project score data with user trust relationship data. A Biased Dynamic Expert Trust Recommendation Algorithm (BDETA) based on fusion bias is proposed. Firstly, the community is divided according to the user trust relationship data and explicit trust values are obtained.Secondly, the credibility and implicit trust values are obtained from the user-project score data in the community. The expert trust factor is dynamically determined by combining the trust between users, explicit trust value and implicit trust value, and the expert data set is determined for each community according to the recommendation ability of the user.Finally, the different scoring criteria of users in the community data set are combined to predict the scoring for the target users. In the experimental results of real data set FilmTrust, it can effectively solve the problem of collaborative filtering cold startup and data sparseness, better meet the personalized recommendation requirements of users, and has a good performance in the commonly used evaluation index MAE and RMSE of the recommendation system.
-
表 2 参数
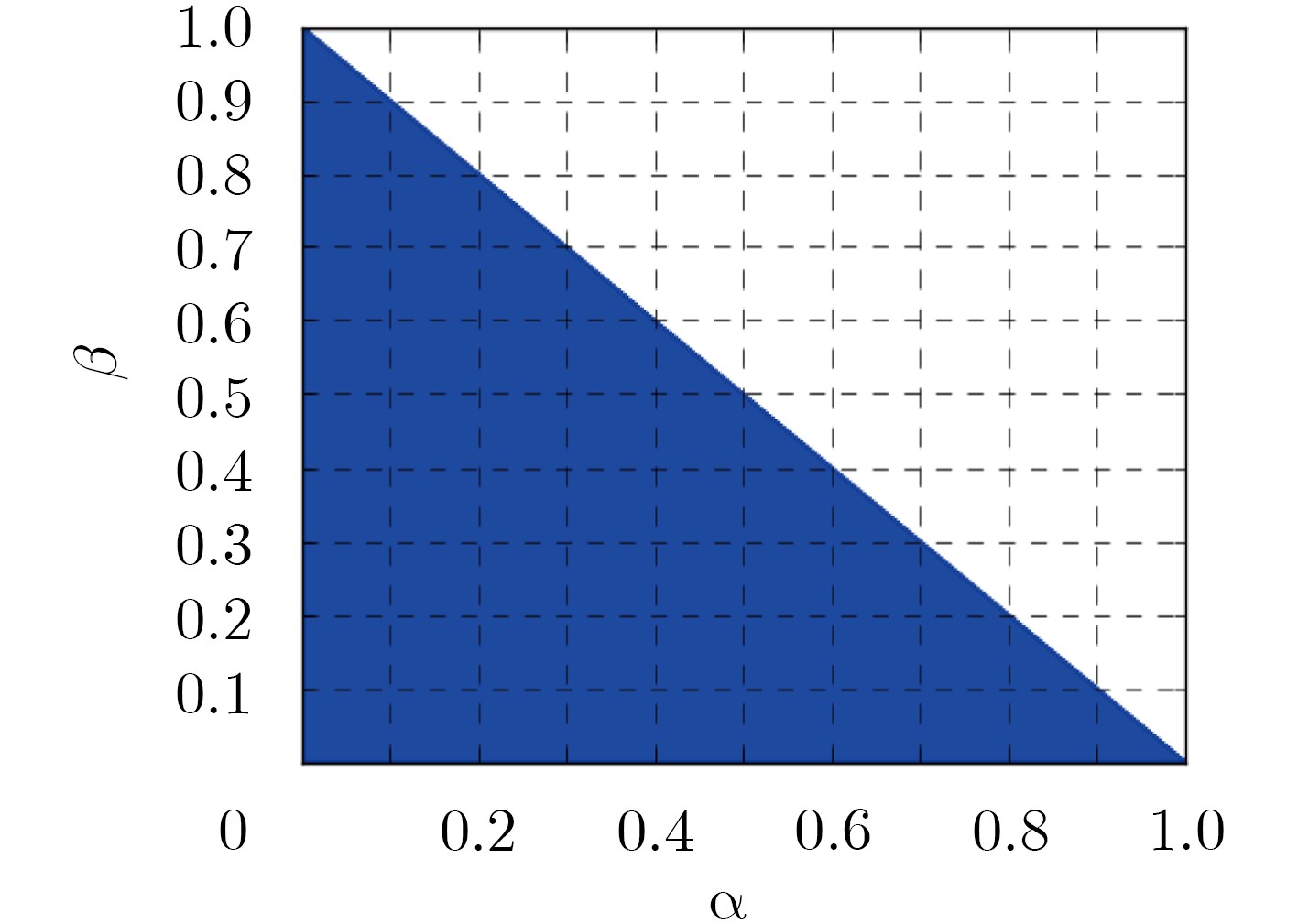
$\alpha $ 和$\beta $ 对MAE的影响$\alpha \backslash \beta $ 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 0 0.5219 0.5354 0.5312 0.5243 0.5164 0.5154 0.5162 0.5167 0.5169 0.5173 0.5178 0.1 0.5183 0.5307 0.5354 0.5238 0.5151 0.5156 0.5163 0.5167 0.5170 0.5174 0 0.2 0.5494 0.5390 0.5294 0.5269 0.5138 0.5152 0.5160 0.5165 0.5168 0 0 0.3 0.5506 0.5463 0.5220 0.5213 0.5221 0.5150 0.5158 0.5164 0 0 0 0.4 0.5430 0.5284 0.4697 0.4969 0.5223 0.5164 0.5158 0 0 0 0 0.5 0.5611 0.5245 0.5220 0.4392 0.5100 0.4860 0 0 0 0 0 0.6 0.5644 0.5566 0.5482 0.4532 0.4640 0 0 0 0 0 0 0.7 0.5510 0.5436 0.5574 0.5304 0 0 0 0 0 0 0 0.8 0.5832 0.5580 0.5436 0 0 0 0 0 0 0 0 0.9 0.5831 0.5831 0 0 0 0 0 0 0 0 0 1.0 0.6127 0 0 0 0 0 0 0 0 0 0  下载: 导出CSV
下载: 导出CSV
-
[1] ADOMAVICIUS G and TUZHILIN A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6): 734–749. doi: 10.1109/TKDE.2005.99 [2] KOENIGSTEIN N and PAQUET U. Xbox movies recommendations: Variational Bayes matrix factorization with embedded feature selection[C]. Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 2013. doi: 10.1145/2507157.2507168. [3] KIM T H, PARK S I, and YANG S B. Improving prediction quality in collaborative filtering based on clustering[C]. Proceedings of 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Sydney, Australia, 2008: 704–710. doi: 10.1109/WIIAT.2008.319. [4] KOOHI H and KIANI K. User based collaborative filtering using fuzzy C-means[J]. Measurement, 2016, 91: 134–139. doi: 10.1016/j.measurement.2016.05.058 [5] 龚敏, 邓珍荣, 黄文明. 基于用户聚类与Slope One填充的协同推荐算法[J]. 计算机工程与应用, 2018, 54(22): 139–143. doi: 10.3778/j.issn.1002-8331.1707-0336GONG Min, DENG Zhenrong, and HUANG Wenming. Collaborative recommendation algorithm based on user clustering and Slope One filling[J]. Computer Engineering and Applications, 2018, 54(22): 139–143. doi: 10.3778/j.issn.1002-8331.1707-0336 [6] MASSA P and AVESANI P. Trust-aware recommender systems[C]. Proceedings of the 2007 ACM conference on Recommender Systems, Minneapolis, USA, 2007: 17–24. [7] YUAN W, SHU L, CHAO H C, et al. ITARS: Trust-aware recommender system using implicit trust networks[J]. IET Communications, 2010, 4(14): 1709–1721. doi: 10.1049/iet-com.2009.0733 [8] LIU Fengkun and LEE H J. Use of social network information to enhance collaborative filtering performance[J]. Expert Systems with Applications, 2010, 37(7): 4772–4778. doi: 10.1016/j.eswa.2009.12.061 [9] 郭弘毅, 刘功申, 苏波, 等. 融合社区结构和兴趣聚类的协同过滤推荐算法[J]. 计算机研究与发展, 2016, 53(8): 1664–1672. doi: 10.7544/issn1000-1239.2016.20160175GUO Hongyi, LIU Gongshen, SU Bo, et al. Collaborative filtering recommendation algorithm combining community structure and interest clusters[J]. Journal of Computer Research and Development, 2016, 53(8): 1664–1672. doi: 10.7544/issn1000-1239.2016.20160175 [10] 张凯涵, 梁吉业, 赵兴旺, 等. 一种基于社区专家信息的协同过滤推荐算法[J]. 计算机研究与发展, 2018, 55(5): 968–976. doi: 10.7544/issn1000-1239.2018.20170253ZHANG Kaihan, LINAG Jiye, ZHAO Xingwang, et al. A collaborative filtering recommendation algorithm based on information of community experts[J]. Journal of Computer Research and Development, 2018, 55(5): 968–976. doi: 10.7544/issn1000-1239.2018.20170253 [11] GHAVIPOUR M and MEYBODI M R. An adaptive fuzzy recommender system based on learning automata[J]. Electronic Commerce Research and Applications, 2016, 20: 105–115. doi: 10.1016/j.elerap.2016.10.002 [12] BEDI P and VASHISTH P. Empowering recommender systems using trust and argumentation[J]. Information Sciences, 2014, 279: 569–586. doi: 10.1016/j.ins.2014.04.012 [13] AMATRIAIN X, LATHIA N, PUJOL J M, et al. The wisdom of the few: A collaborative filtering approach based on expert opinions from the web[C]. The 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, USA, 2009: 532–539. doi: 10.1145/1571941.1572033. [14] BREESE J S, HECKERMAN D, and KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[C]. The 14th Conference on Uncertainty in Artificial Intelligence, San Francisco, USA, 1998. [15] 贾彭慧, 刘鑫一, 孔亚斌, 等. 基于专家动态生成的协同过滤推荐算法[J]. 计算机技术与发展, 2020, 30(3): 19–23. doi: 10.3969/j.issn.1673-629X.2020.03.004JIA Penghui, LIU Xinyi, KONG Yabin, et al. A dynamically generated experts-based collaborative filtering recommendation algorithm[J]. Computer Technology and Development, 2020, 30(3): 19–23. doi: 10.3969/j.issn.1673-629X.2020.03.004 [16] 高发展, 黄梦醒, 张婷婷. 综合用户特征及专家信任的协作过滤推荐算法[J]. 计算机科学, 2017, 44(2): 103–106. doi: 10.11896/j.issn.1002-137X.2017.02.014GAO Fazhan, HUANG Mengxing, and ZHANG Tingting. Collaborative filtering recommendation algorithm based on user characteristics and expert opinions[J]. Computer Science, 2017, 44(2): 103–106. doi: 10.11896/j.issn.1002-137X.2017.02.014 [17] 赵明, 闫寒, 曹高峰, 等. 融合用户信任度和相似度的基于核心用户抽取的鲁棒性推荐算法[J]. 电子与信息学报, 2019, 41(1): 180–186. doi: 10.11999/JEIT180142ZHAO Ming, YAN Han, CAO Gaofeng, et al. Robust recommendation algorithm based on core user extraction with user trust and similarity[J]. Journal of Electronics &Information Technology, 2019, 41(1): 180–186. doi: 10.11999/JEIT180142 [18] 王建芳, 刘冉东, 刘永利. 一种带偏置的专家信任推荐算法[J]. 小型微型计算机系统, 2018, 39(2): 287–291. doi: 10.3969/j.issn.1000-1220.2018.02.019WANG Jianfang, LIU Randong, and LIU Yongli. Expert trust recommendation algorithm with bias[J]. Journal of Chinese Computer Systems, 2018, 39(2): 287–291. doi: 10.3969/j.issn.1000-1220.2018.02.019 [19] WALTMAN L and VAN ECK N J. A smart local moving algorithm for large-scale modularity-based community detection[J]. The European Physical Journal B, 2013, 86(11): 471. doi: 10.1140/epjb/e2013-40829-0 [20] GUO Guibing, ZHANG Jie, and THALMANN D. Merging trust in collaborative filtering to alleviate data sparsity and cold start[J]. Knowledge-Based Systems, 2014, 57: 57–68. doi: 10.1016/j.knosys.2013.12.007 [21] LATHIA N, HAILES S, and CAPRA L. Trust-based Collaborative Filtering[M]. KARABULUT Y, MITCHELL J, HERRMANN P, et al. Trust Management II. Boston: Springer, 2008: 119–134. [22] SHEUGH L and ALIZADEH S H. A novel 2D-Graph clustering method based on trust and similarity measures to enhance accuracy and coverage in recommender systems[J]. Information Sciences, 2018, 432: 210–230. doi: 10.1016/j.ins.2017.12.007 [23] 刘国丽, 白晓霞, 廉孟杰, 等. 基于专家信任的协同过滤推荐算法改进研究[J]. 计算机工程与科学, 2019, 41(10): 1846–1853. doi: 10.3969/j.issn.1007-130X.2019.10.018LIU Guoli, BAI Xiaoxia, LIAN Mengjie, et al. An improved collaborative filtering recommendation algorithm based on expert trust[J]. Computer Engineering &Science, 2019, 41(10): 1846–1853. doi: 10.3969/j.issn.1007-130X.2019.10.018 [24] NIKZAD–KHASMAKHI N, BALAFAR M A, and FEIZI-DERAKHSHI M R. The state-of-the-art in expert recommendation systems[J]. Engineering Applications of Artificial Intelligence, 2019, 82: 126–147. doi: 10.1016/j.engappai.2019.03.020 [25] GOLDBERG D, NICHOLS D, OKI B M, et al. Using collaborative filtering to weave an information tapestry[J]. Communications of the ACM, 1992, 35(12): 61–70. doi: 10.1145/138859.138867 [26] DESHPANDE M and KARYPIS G. Item-based top-N recommendation algorithms[J]. ACM Transactions on Information Systems, 2004, 22(1): 143–177. doi: 10.1145/963770.963776 -

 下载:
下载:





图(4) / 表(2)
计量
- 文章访问数: 1018
- HTML全文浏览量: 447
- PDF下载量: 64
- 被引次数: 0
