

Tiny Face Hallucination via Relativistic Adversarial Learning
-
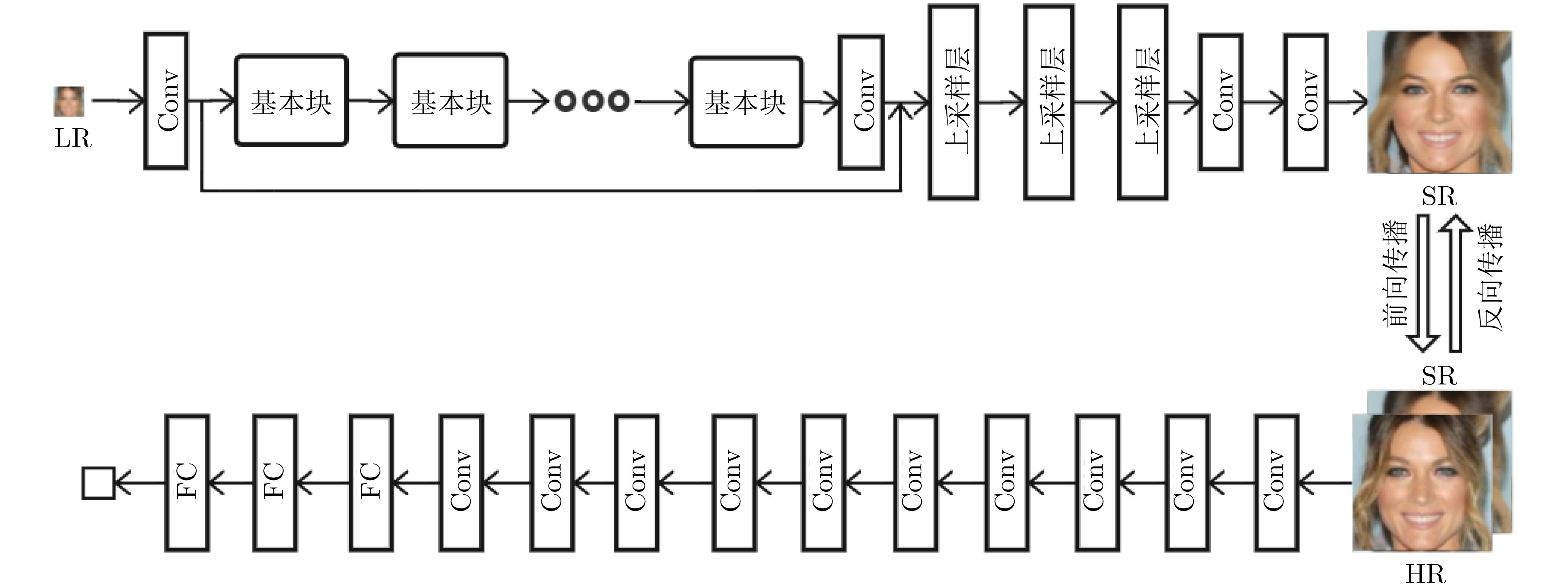
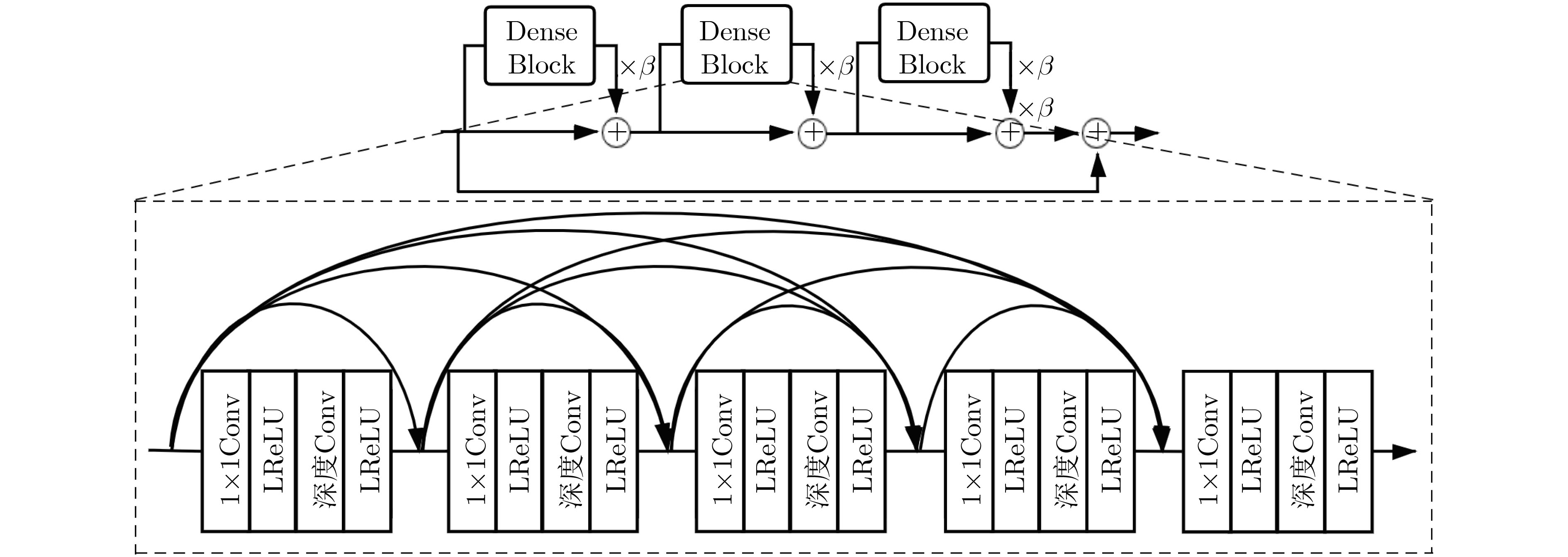
摘要: 针对当前代表性低清小脸幻构方法存在的视觉真实感弱、网络结构复杂等问题,提出了一种基于相对生成对抗网络的低清小脸幻构方法(tfh-RGAN)。该文方法的网络架构包括幻构生成器和判别器两个部分,通过像素损失函数和相对生成对抗损失函数的联合最小化,实现生成器和判别器的交替迭代训练。其中,幻构生成器结合了残差块、稠密块以及深度可分离卷积算子,保证幻构效果和网络深度的同时降低生成器的参数量;判别器采用图像分类问题中的全卷积网络,通过先后去除批归一化层、添加全连接层,充分挖掘相对生成对抗网络在低清小脸幻构问题上的能力极限。实验结果表明,在不额外显式引入任何人脸结构先验的条件下,该文方法能够以更简练的网络架构输出清晰度更高、真实感更强的幻构人脸。从定量角度看,该文方法的峰值信噪比相较之前的若干代表性方法可提高0.25~1.51 dB。Abstract: Considering that previous tiny face hallucination methods either produced visually less pleasant faces or required architecturally more complex networks, this paper advocates a new deep model for tiny face hallucination by borrowing the idea of Relativistic Generative Adversarial Network (tfh-RGAN). Specifically, a hallucination generator and a relativistic discriminator are jointly learned in an alternately iterative training fashion by minimizing the combined pixel loss and relativistic generative adversarial loss. As for the generator, it is mainly structured as concatenation of a few basic modules followed by three 2×up-sampling layers, and each basic module is formulated by coupling the residual blocks, dense blocks, and depthwise separable convolution operators. As such, the generator can be made lightweight while with a considerable depth so as to achieve high quality face hallucination. As for the discriminator, it makes use of VGG128 while removing all its batch normalization layers and embedding a fully connected layer additionally so as to fulfill the capacity limit of relativistic adversarial learning. Experimental results reveal that, the proposed method, though simpler in the network architecture without a need of explicitly imposing any face structural prior, is able to produce better hallucination faces with higher definition and stronger reality. In terms of the quantitative assessment, the peak signal-to-noise ratio of the proposed method can be improved up to 0.25~1.51 dB compared against several previous approaches.
-

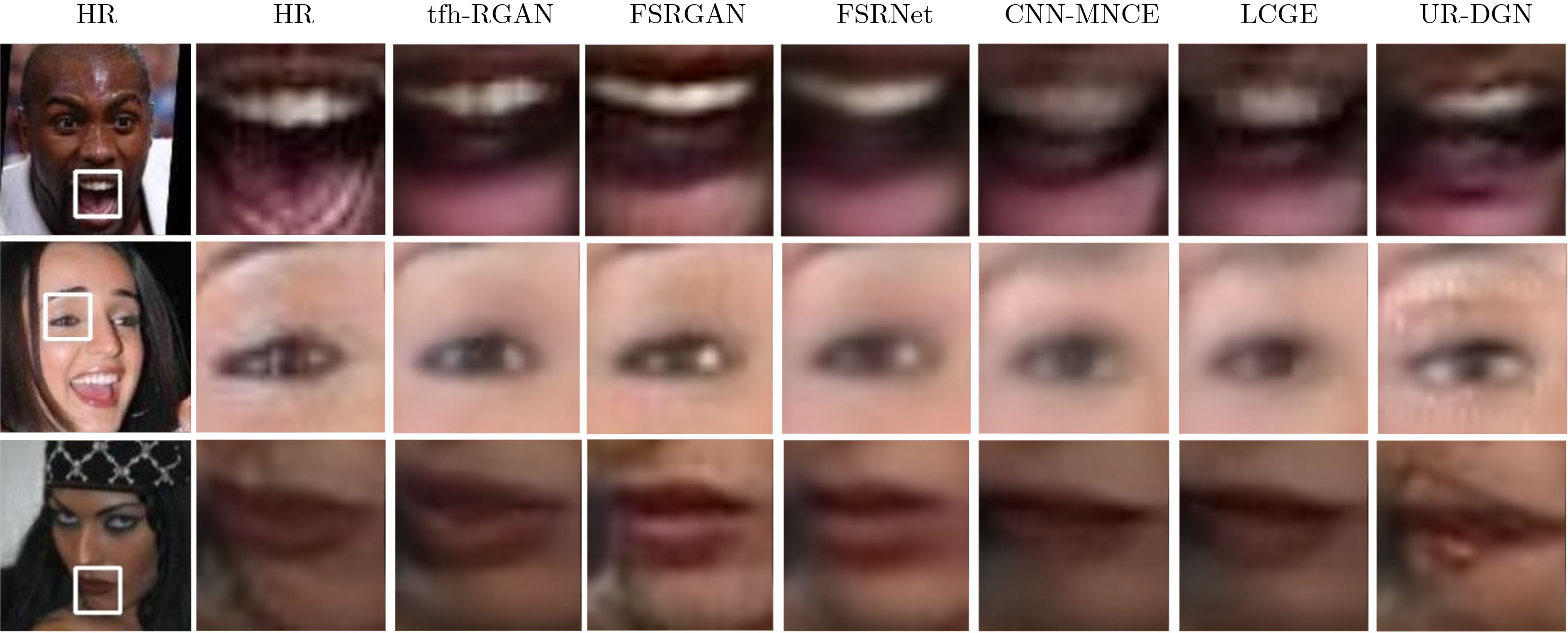
图 3 tfh-RGAN消融实验的定性分析. 1~4行分别对应tfh-GeneratorRRDB, tfh-GeneratorL-RRDB, tfh-RGANVGG128以及tfh-RGAN的幻构人脸;第5行为原始HR人脸
表 1 tfh-RGAN消融实验的定量分析
模型 PSNR SSIM 参数量 tfh-GeneratorRRDB 25.06 0.7313 16734915 tfh-GeneratorL-RRDB 25.00 0.7295 7138947 tfh-RGANVGG128 24.89 0.7299 7138947 tfh-RGAN 24.73 0.7172 7138947  下载: 导出CSV
下载: 导出CSV
-
[1] DONG Chao, LOY C C, HE Kaiming, et al. Learning a deep convolutional network for image super-resolution[C]. Proceedings of the 13th European Conference on Computer Vision, Zurich, 2014: 184–199. doi: 10.1007/978-3-319-10593-2_13. [2] 赵小强, 宋昭漾. 多级跳线连接的深度残差网络超分辨率重建[J]. 电子与信息学报, 2019, 41(10): 2501–2508. doi: 10.11999/JEIT190036ZHAO Xiaoqiang and SONG Zhaoyang. Super-resolution reconstruction of deep residual network with multi-level skip connections[J]. Journal of Electronics &Information Technology, 2019, 41(10): 2501–2508. doi: 10.11999/JEIT190036 [3] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Cambridge, UK, 2014: 2672–2680. [4] YU Xin and PORIKLI F. Ultra-resolving face images by discriminative generative networks[C]. Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 318–333. doi: 10.1007/978-3-319-46454-1_20. [5] LUCIC M, KURACH K, MICHALSKI M, et al. Are GANs created equal? a large-scale study[EB/OL]. https://arxiv.org/abs/1711.10337, 2018. [6] SHAO Wenze, XU Jingjing, CHEN Long, et al. On potentials of regularized Wasserstein generative adversarial networks for realistic hallucination of tiny faces[J]. Neurocomputing, 2019, 364: 1–15. doi: 10.1016/j.neucom.2019.07.046 [7] GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANS[EB/OL]. https://arxiv.org/abs/1704.00028, 2017. [8] CHEN Yu, TAI Ying, LIU Xiaoming, et al. FSRNet: End-to-end learning face super-resolution with facial priors[C]. Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 2492–2501. doi: 10.1109/CVPR.2018.00264. [9] JOLICOEUR-MARTINEAU A. The relativistic discriminator: A key element missing from standard GAN[EB/OL]. https://arxiv.org/abs/1807.00734, 2018. [10] HE Kaiming, ZHANG Xiangyu, and REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [11] HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2261–2269. doi: 10.1109/CVPR.2017.243. [12] HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. http://arxiv.org/abs/1704.04861, 2017. [13] WANG Xintao, YU Ke, WU Shixiang, et al. ESRGAN: Enhanced super-resolution generative adversarial networks[C]. Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 2018: 63–79. doi: 10.1007/978-3-030-11021-5_5. [14] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. Proceedings of the 3rd International Conference on Learning Representations, San Diego, USA, 2015: 1–14. [15] LIU Ziwei, LUO Ping, WANG Xiaogang, et al. Deep learning face attributes in the wild[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 3730–3738. doi: 10.1109/ICCV.2015.425. [16] KINGMA D P and BA J. Adam: A method for stochastic optimization[EB/OL]. https://arxiv.org/abs/1412.6980, 2017. [17] SONG Yibing, ZHANG Jiawei, HE Shengfeng, et al. Learning to hallucinate face images via component generation and enhancement[C]. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 2017: 4537–4543. [18] JIANG Junjun, HU Yi, HU Jinhui, et al. Deep CNN denoiser and multi-layer neighbor component embedding for face hallucination[C]. Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 2018: 771–778. -

 下载:
下载:




图(5) / 表(2)
计量
- 文章访问数: 1180
- HTML全文浏览量: 681
- PDF下载量: 69
- 被引次数: 0
