

High Resolution Wireless Channel Simulation and Localization Technique for 6G Network
-
摘要: 为了应对6G无线信道中的小数时延和同步误差给定位系统带来的挑战,该文提出基于频域等效的高分辨率信道方法仿真以及基于到达角(AOA)信息的高分辨率定位技术。前者通过将信道抽头时延转换到频域处理,在降低时域方法带来的高复杂度的同时实现了高分辨率仿真,为时延定位信息的实现提供基础;后者则通过将迭代信道估计、基于首到达径检测的AOA估计算法与基于AOA信息的位置估计算法结合起来,在同步误差下实现高精度定位。数值仿真结果表明,二者均在相应的实际场景下实现了高分辨率特性。Abstract: In order to cope with the challenges brought by the fractional delay and synchronization error in 6G wireless channel of positioning systems, this paper proposes a high resolution channel simulation method based on frequency domain equivalent and a high resolution positioning technology exploiting Angle Of Arrival (AOA) information. The former achieves high resolution while reducing the high complexity brought by time domain method due to converting channel tap delays to frequency domain to process, providing solid foundation for accurate simulation of delay information in localization; the later achieves high positioning resolution under synchronization error by combining iterative channel estimation, AOA estimation algorithm based on first arrival path detection and position estimation algorithm with AOA information input. The numerical simulation results show that they both achieve optimized performance in corresponding practical scenarios.
-
Key words:
- Channel simulation /
- Localization /
- 6G /
- Synchronization error /
- Angle Of Arrival (AOA)
-
SAAD W, BENNIS M, and CHEN Mingzhe. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems[J]. IEEE Network, 2020, 34(3): 134–142. doi: 10.1109/MNET.001.1900287 KATZ M, MATINMIKKO-BLUE M, and LATVA-AHO M. 6Genesis flagship program: Building the bridges towards 6G-enabled wireless smart society and ecosystem[C]. The 10th IEEE Latin-American Conference on Communications, Guadalajara, Mexico, 2018: 1–9. doi: 10.1109/LATINCOM.2018.8613209. ELMEADAWY S and SHUBAIR R M. 6G wireless communications: Future technologies and research challenges[C]. 2019 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 2019: 1–5, doi: 10.1109/ICECTA48151.2019.8959607. LATVA-AHO M and LEPPÄNEN K. 6G research vision 1: Key drivers and research challenges for 6G ubiquitous wireless intelligence[EB/OL]. https://www.oulu.fi/6gflagship/6gresearchvision, 2020. OPPENHEIM A V and SCHAFER R W. Discrete-Time Signal Processing[M]. United States: Prentice Hall, 1999: 33–65. HERMANOWICZ E and ROJEWSKI M. A Nyquist filter of fractional delay[C]. 2013 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 2013: 124–128. ADITYA S, MOLISCH A F, and BEHAIRY H M. A survey on the impact of multipath on wideband time-of-arrival based localization[J]. Proceedings of the IEEE, 2018, 106(7): 1183–1203. doi: 10.1109/JPROC.2018.2819638 RAPPAPORT T S, XING Yunchou, KANHERE O, et al. Wireless communications and applications above 100 GHz: Opportunities and challenges for 6G and beyond[J]. IEEE Access, 2019, 7: 78729–78757. doi: 10.1109/ACCESS.2019.2921522 郝本建, 王林林, 李赞, 等. 面向TDOA被动定位的定位节点选择方法[J]. 电子与信息学报, 2019, 41(2): 462–468. doi: 10.11999/JEIT180293HAO Benjian, WANG Linlin, LI Zan, et al. Sensor selection method for TDOA passive localization[J]. Journal of Electronics &Information Technology, 2019, 41(2): 462–468. doi: 10.11999/JEIT180293 孙霆, 董春曦, 毛昱. 一种基于半定松弛技术的TDOA-FDOA无源定位算法[J]. 电子与信息学报, 2020, 42(7): 1599–1605. doi: 10.11999/JEIT190435SUN Ting, DONG Chunxi, and MAO Yu. A TDOA-FDOA passive positioning algorithm based on the semi-definite relaxation technique[J]. Journal of Electronics &Information Technology, 2020, 42(7): 1599–1605. doi: 10.11999/JEIT190435 ERICSSON. System level performance evaluation for RAT-dependent positioning techniques[R]. 3GPP TSG RAN WG1 Meeting #96. R1–1903142. XING Yunchou and RAPPAPORT T S. Propagation measurement system and approach at 140 GHz-moving to 6G and above 100 GHz[C]. 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 2018: 1–6, doi: 10.1109/GLOCOM.2018.8647921. KURTH R, SNYDER L, and HOVERSTEN V. Detection and estimation theory[R]. Massachusetts Institute of Technology, Research Laboratory of Electronics, Quarterly Progress Report, No. 93 (IX), 177. LI Yunxin and HUANG Xiaojing. The simulation of independent Rayleigh faders[J]. IEEE Transactions on Communications, 2002, 50(9): 1503–1514. doi: 10.1109/TCOMM.2002.802562 PATZOLD M, WANG Chengxiang, and HOGSTAD B O. Two new sum-of-sinusoids-based methods for the efficient generation of multiple uncorrelated Rayleigh fading waveforms[J]. IEEE Transactions on Wireless Communications, 2009, 8(6): 3122–3131. doi: 10.1109/TWC.2009.080769 PROAKIS J G and SALEHI M. Digital Communications[M]. 5th ed. New York: McGraw-Hill, 2008: 190–193. INSERRA D and TONELLO A M. A frequency-domain LOS angle-of-arrival estimation approach in multipath channels[J]. IEEE Transactions on Vehicular Technology, 2013, 62(6): 2812–2818. doi: 10.1109/TVT.2013.2245428 PAGES-ZAMORA A, VIDAL J, and BROOKS D H. Closed-form solution for positioning based on angle of arrival measurements[C]. The 13th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, Pavilhao Altantico, Lisboa, Portugal, 2002: 1522–1526, doi: 10.1109/PIMRC.2002.1045433. 3GPP. TR38.901 Study on channel model for frequencies from 0.5 to 100 GHz[S]. 2018. 3GPP. TR38.855 Study on NR positioning support[S]. 2018. 3GPP. TS38.211 NR Physical channels and modulation (Release 15)[S]. 2018. HUAWEI, HISILICON. Performance evaluation for NR positioning[R]. 3GPP TSG RAN WG1 Meeting #96. R1-1901577. -

 下载:
下载:


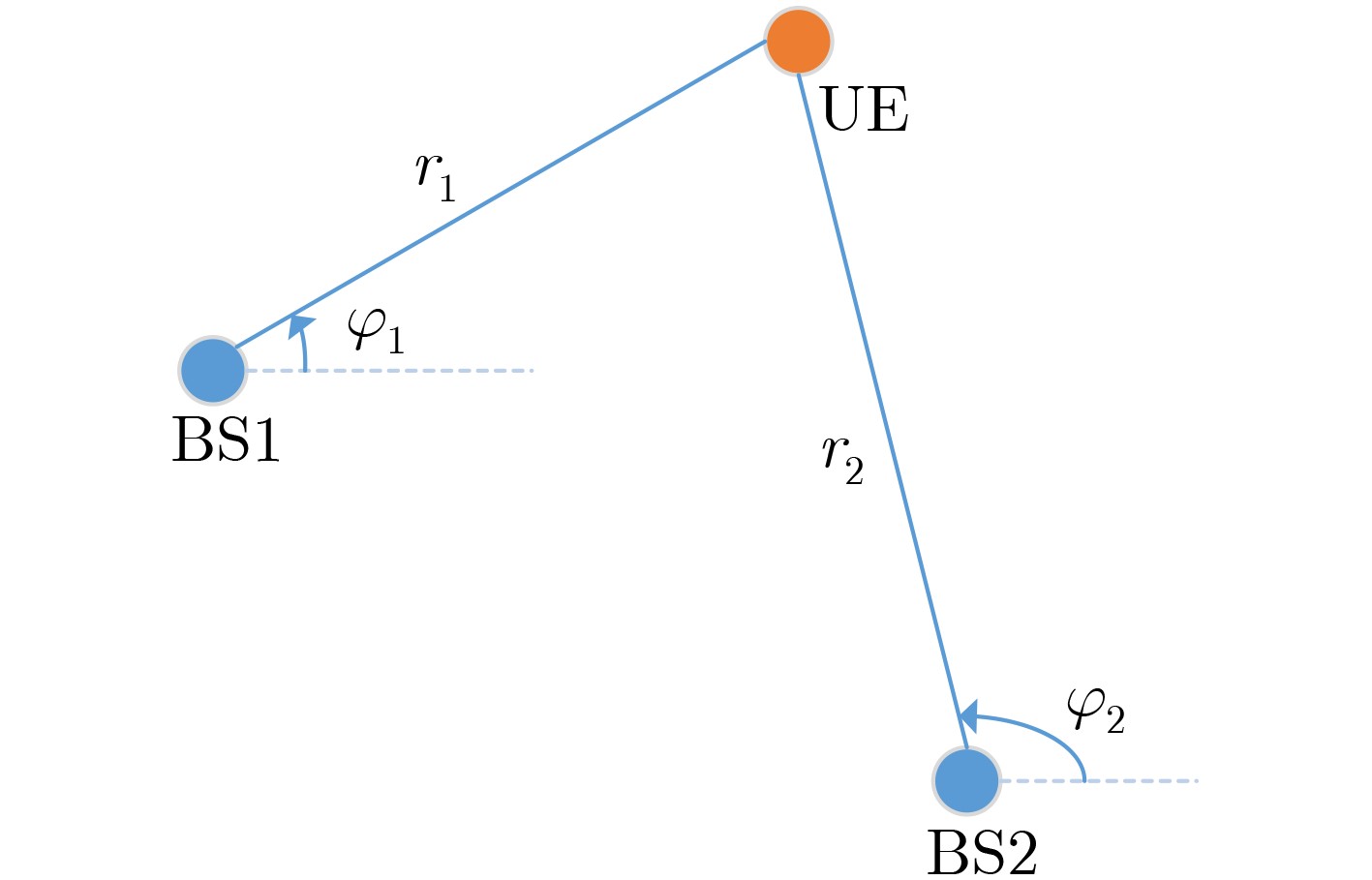




图(6)
计量
- 文章访问数: 1698
- HTML全文浏览量: 716
- PDF下载量: 149
- 被引次数: 0
