

Design and Hardware Implementation of Image Recognition System Based on Improved Neural Network
-
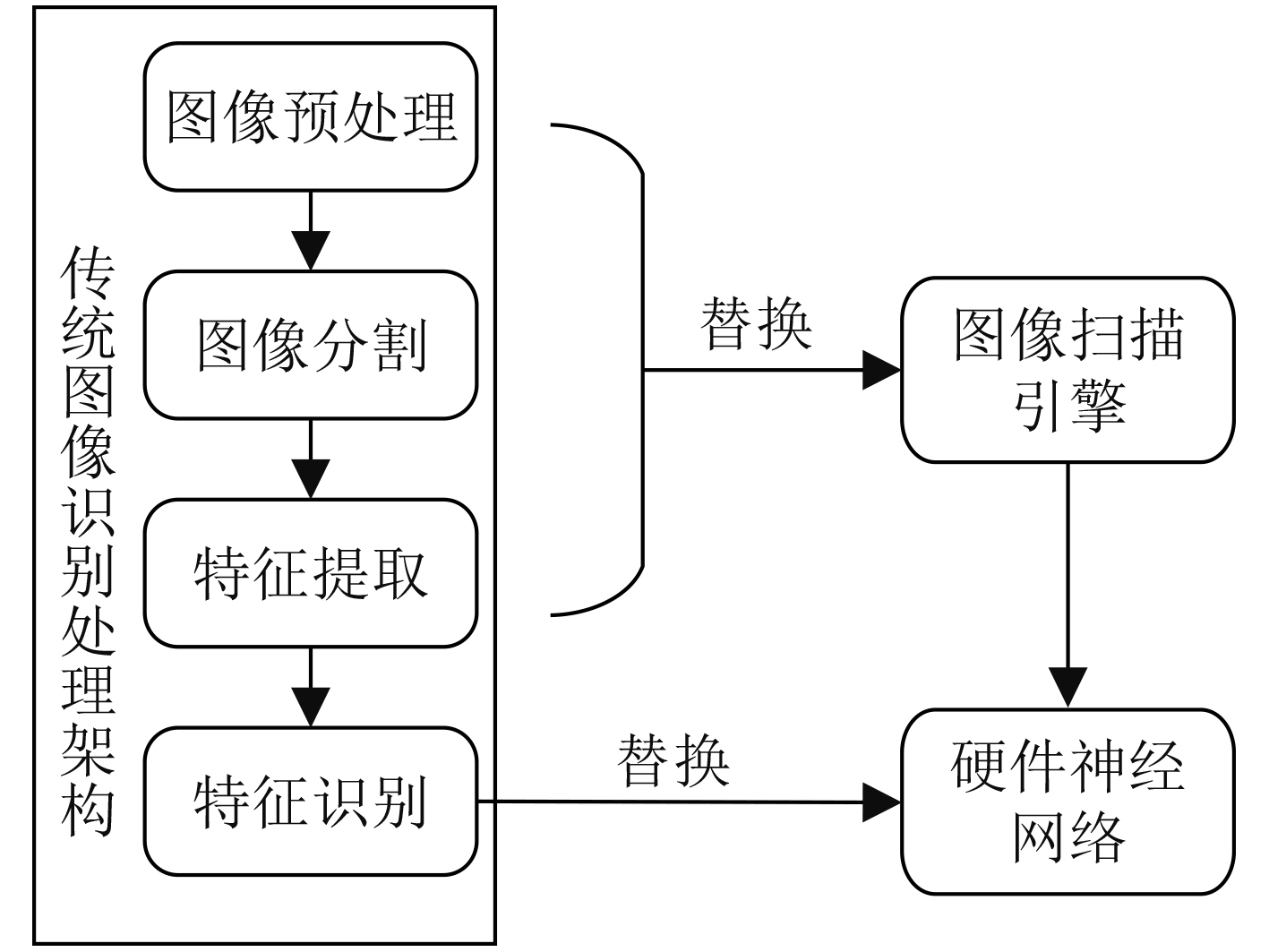
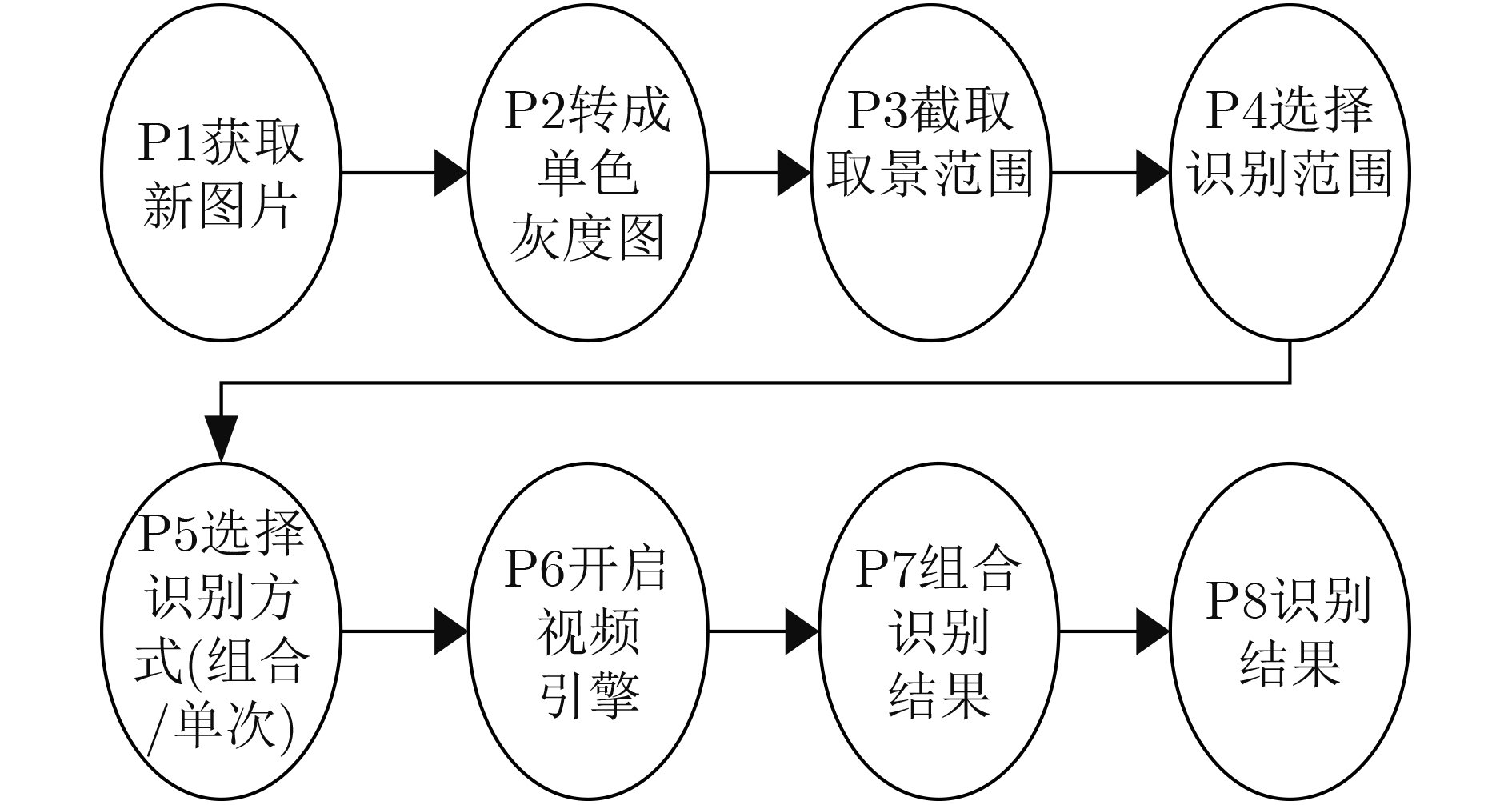
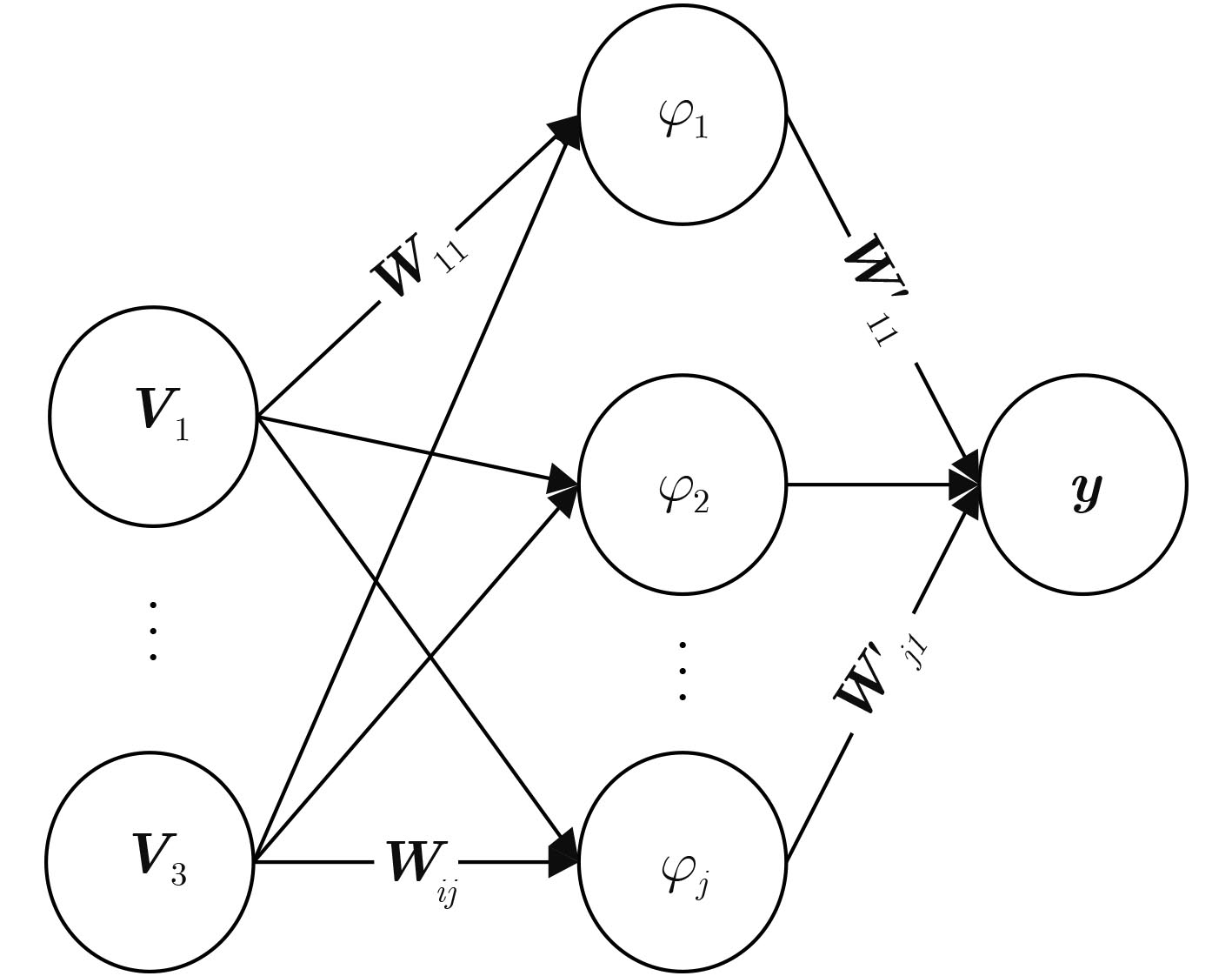
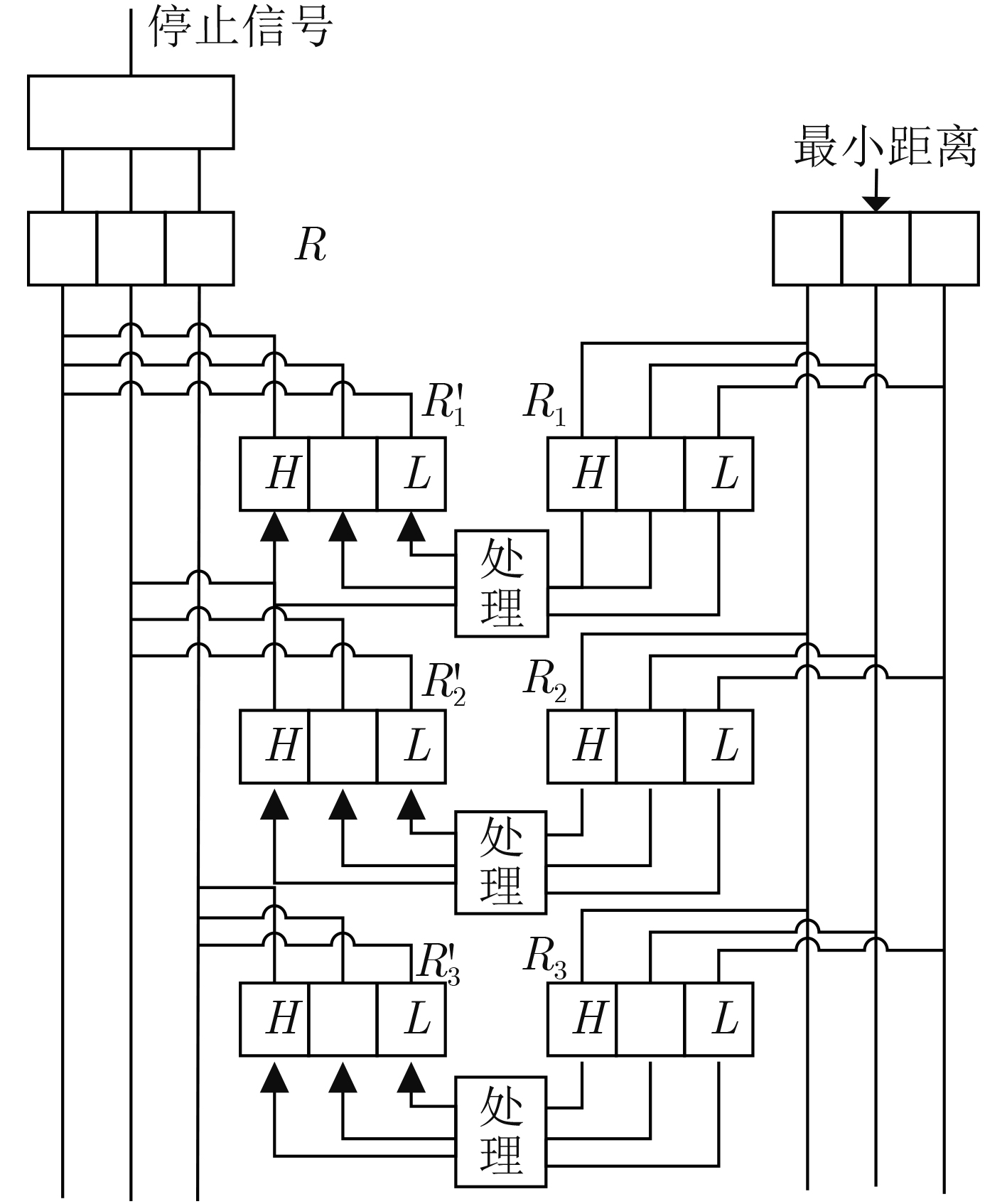
摘要: 针对现有图像识别系统大多采用软件实现,无法利用神经网络并行计算能力的问题。该文提出一套基于FPGA的改进RBF神经网络硬件化图像识别系统,将乘法运算改为加法运算解决了神经网络计算复杂不便于硬件化的问题,并且提出一种基于位比较的排序电路解决了大量数据的快速排序问题,以此为基础开发了多目标图像识别应用系统。系统特征提取部分采用FPGA实现,图像识别部分采用ASIC电路实现。实验结果表明,该文所提出的改进RBF神经网络算法平均识别时间较LeNet-5, AlexNet和VGG16缩短50%;所开发的硬件系统完成对10000张样本图片识别的时间为165 μs,对比于DSP芯片系统所需426.6 μs,减少了60%左右。Abstract: To solve the problem that most existing image recognition systems are implemented in software which can not utilize the parallel computing power of neural networks, this paper proposes a FPGA image recognition system based on improved RBF neural network hardware. The multiplication operation in the neural networks is complex and inconvenient for hardware implementation. Furthermore, a sort circuit based on bit comparison is designed to solve the problem of fast sorting of a large number of data. Then, a multi-target image recognition application system is developed. The feature extraction part in the developed system is implemented by FPGA, and the image recognition part is implemented by ASIC circuit. The experimental results show that the average recognition time of the improved RBF neural network algorithm proposed is 50% shorter than that of LeNet-5, AlexNet and VGG16, and the time for the developed hardware system to recognize 10000 sample pictures is 165μs, which is reduced by about 60% compared with 426.6μs required by a DSP chip system.
-
Key words:
- FPGA /
- ASIC circuit /
- RBF neural networks /
- Image recognition system
-
表 1 测试数据集为MNIST时不同网络模型对比实验
网络模型 准确率 平均识别时间(s) LeNet-5 0.989 1.2 AlexNet 0.991 1.5 VGG16 0.997 2.3 改进RBF神经网络 0.996 0.9  下载: 导出CSV
下载: 导出CSV
表 2 测试数据集为CIFAR-10时不同网络模型对比实验
网络模型 准确率 平均识别时间(s) LeNet-5 0.787 2.4 AlexNet 0.810 3.3 VGG16 0.832 5.5 改进RBF神经网络 0.828 1.3
下载: 导出CSV
表 3 测试数据集为VOC2012时不同网络模型对比实验
网络模型 准确率 平均识别时间(s) LeNet-5 0.757 2.7 AlexNet 0.783 3.5 VGG16 0.813 6.7 改进RBF神经网络 0.808 2.6
下载: 导出CSV
表 4 基于DSP图像识别系统与本文提出图像识别系统性能比较
计算量 DSP芯片 本文系统 时钟频率(MHz) 500 15 ALU数量 6 1024 运算位宽(bit) 32 8 单个样本大小(Byte) 256 256 每个周期能进行加法次数 6 1024×2=2048 每次加法处理数据(Byte) (32/8)×6=24 (8/8)×2048=2048 完成两个样本的比较
需要周期数(2×256/24)=21.33 (2×256/2048)=0.25 完成两个样本比较的
时间(ns)21.33×2=42.66 0.25×66=16.5 和所有样本比较
所需时间(μs)426.6 165
下载: 导出CSV
-
[1] 李国良, 周煊赫, 孙佶, 等. 基于机器学习的数据库技术综述[J]. 计算机学报, 2020, 43(11): 2019–2049.LI Guoliang, ZHOU Xuanhe, SUN Ji, et al. A survey of machine learning based database techniques[J]. Chinese Journal of Computers, 2020, 43(11): 2019–2049. [2] 刘方园, 王水花, 张煜东. 深度置信网络模型及应用研究综述[J]. 计算机工程与应用, 2018, 54(1): 11–18, 47. doi: 10.3778/j.issn.1002-8331.1711-0028LIU Fangyuan, WANG Shuihua, and ZHANG Yudong. Review of deep confidence network model and application research[J]. Computer Engineering and Applications, 2018, 54(1): 11–18, 47. doi: 10.3778/j.issn.1002-8331.1711-0028 [3] LIANG Tian and AFZEL N. Software reliability prediction using recurrent neural network with Bayesian regularization[J]. International Journal of Neural Systems, 2004, 14(3): 165–174. doi: 10.1142/S0129065704001966 [4] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. [5] SABOUR S, FROSST N, and HINTON G E. Dynamic routing between capsules[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 3856–3866. [6] 任源, 潘俊, 刘京京, 等. 人工智能芯片的研究进展[J]. 微纳电子与智能制造, 2019, 1(2): 20–34.REN Yuan, PAN Jun, LIU Jingjing, et al. Overview of artificial intelligence chip development[J]. Micro/Nano Electronics and Intelligent Manufacturing, 2019, 1(2): 20–34. [7] 秦华标, 曹钦平. 基于FPGA的卷积神经网络硬件加速器设计[J]. 电子与信息学报, 2019, 41(11): 2599–2605. doi: 10.11999/JEIT190058QIN Huabiao and CAO Qinping. Design of convolutional neural networks hardware acceleration based on FPGA[J]. Journal of Electronics &Information Technology, 2019, 41(11): 2599–2605. doi: 10.11999/JEIT190058 [8] 韩栋, 周聖元, 支天, 等. 智能芯片的评述和展望[J]. 计算机研究与发展, 2019, 56(1): 7–22. doi: 10.7544/issn1000-1239.2019.20180693HAN Dong, ZHOU Shengyuan, ZHI Tian, et al. A survey of artificial intelligence chip[J]. Journal of Computer Research and Development, 2019, 56(1): 7–22. doi: 10.7544/issn1000-1239.2019.20180693 [9] 王巍, 周凯利, 王伊昌, 等. 基于快速滤波算法的卷积神经网络加速器设计[J]. 电子与信息学报, 2019, 41(11): 2578–2584. doi: 10.11999/JEIT190037WANG Wei, ZHOU Kaili, WANG Yichang, et al. Design of convolutional neural networks accelerator based on fast filter algorithm[J]. Journal of Electronics &Information Technology, 2019, 41(11): 2578–2584. doi: 10.11999/JEIT190037 [10] 伍家松, 达臻, 魏黎明, 等. 基于分裂基-2/(2a)FFT算法的卷积神经网络加速性能的研究[J]. 电子与信息学报, 2017, 39(2): 285–292. doi: 10.11999/JEIT160357WU Jiasong, DA Zhen, WEI Liming, et al. Acceleration performance study of convolutional neural network based on split-radix-2/(2a) FFT algorithms[J]. Journal of Electronics &Information Technology, 2017, 39(2): 285–292. doi: 10.11999/JEIT160357 [11] 张烨, 许艇, 冯定忠, 等. 基于难分样本挖掘的快速区域卷积神经网络目标检测研究[J]. 电子与信息学报, 2019, 41(6): 1496–1502. doi: 10.11999/JEIT180702ZHANG Ye, XU Ting, FENG Dingzhong, et al. Research on faster RCNN object detection based on hard example mining[J]. Journal of Electronics &Information Technology, 2019, 41(6): 1496–1502. doi: 10.11999/JEIT180702 -

 下载:
下载:




图(6) / 表(4)
计量
- 文章访问数: 1611
- HTML全文浏览量: 911
- PDF下载量: 178
- 被引次数: 0
