

Blind Estimation of the Pseudo Noise Sequence and Information Sequence for Long Code Asynchronous DS-CDMA Signal in Multipath Environment
-
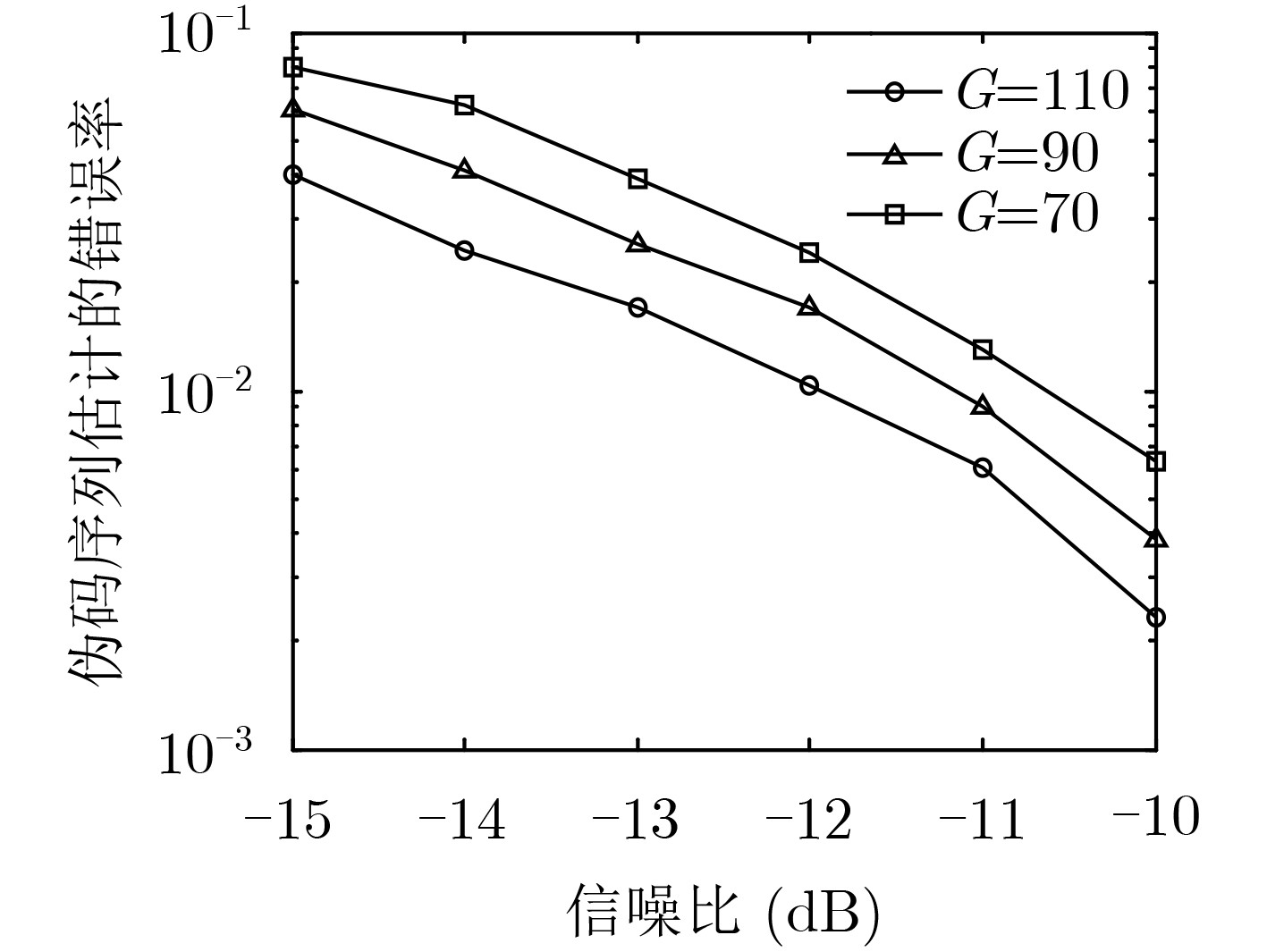
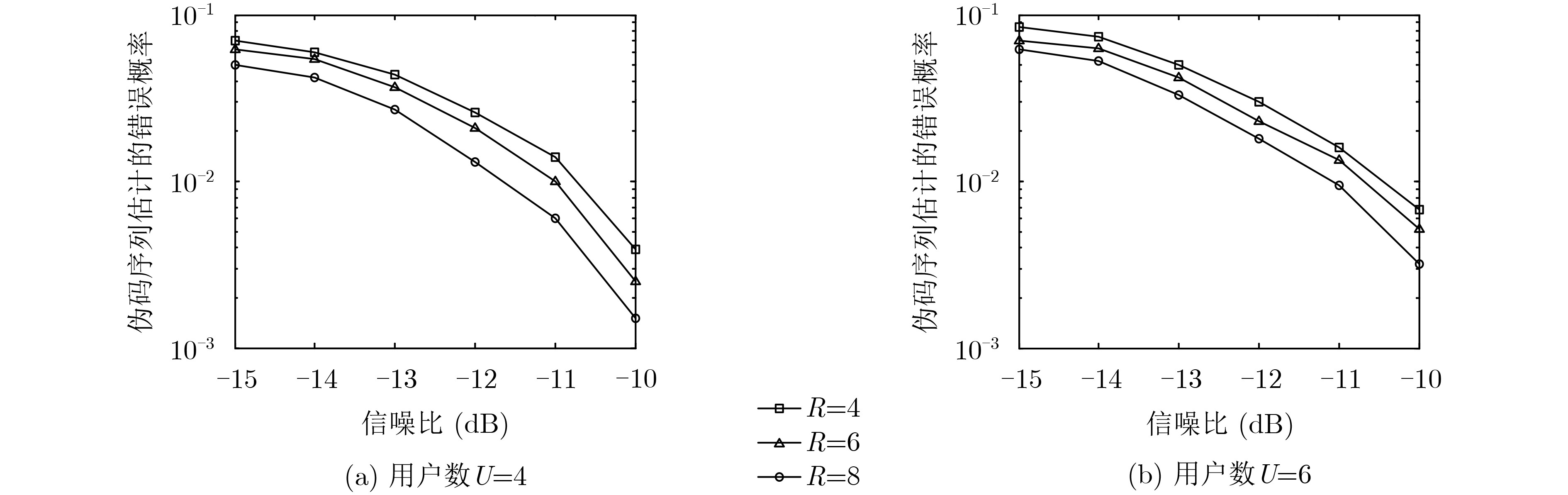
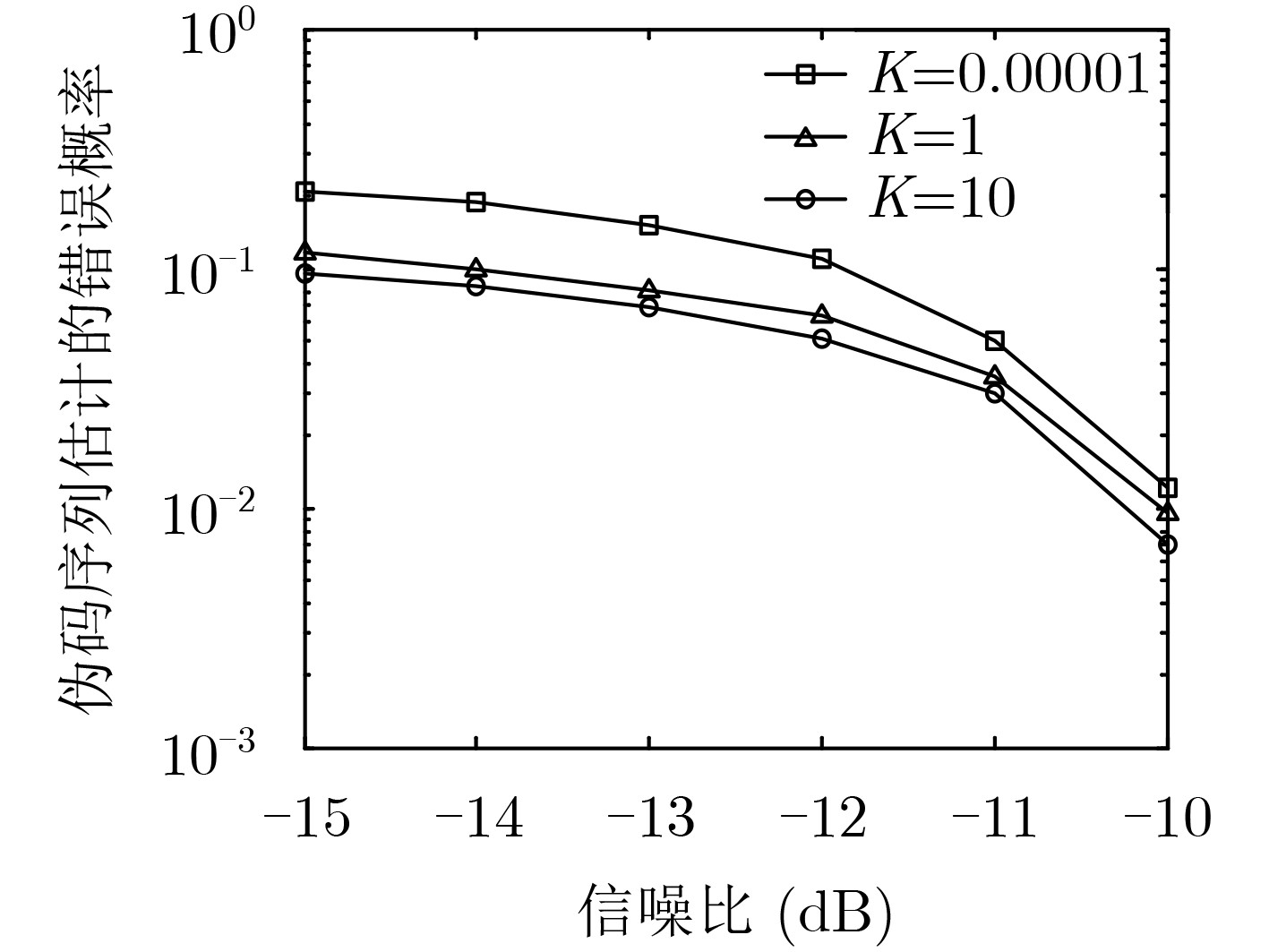
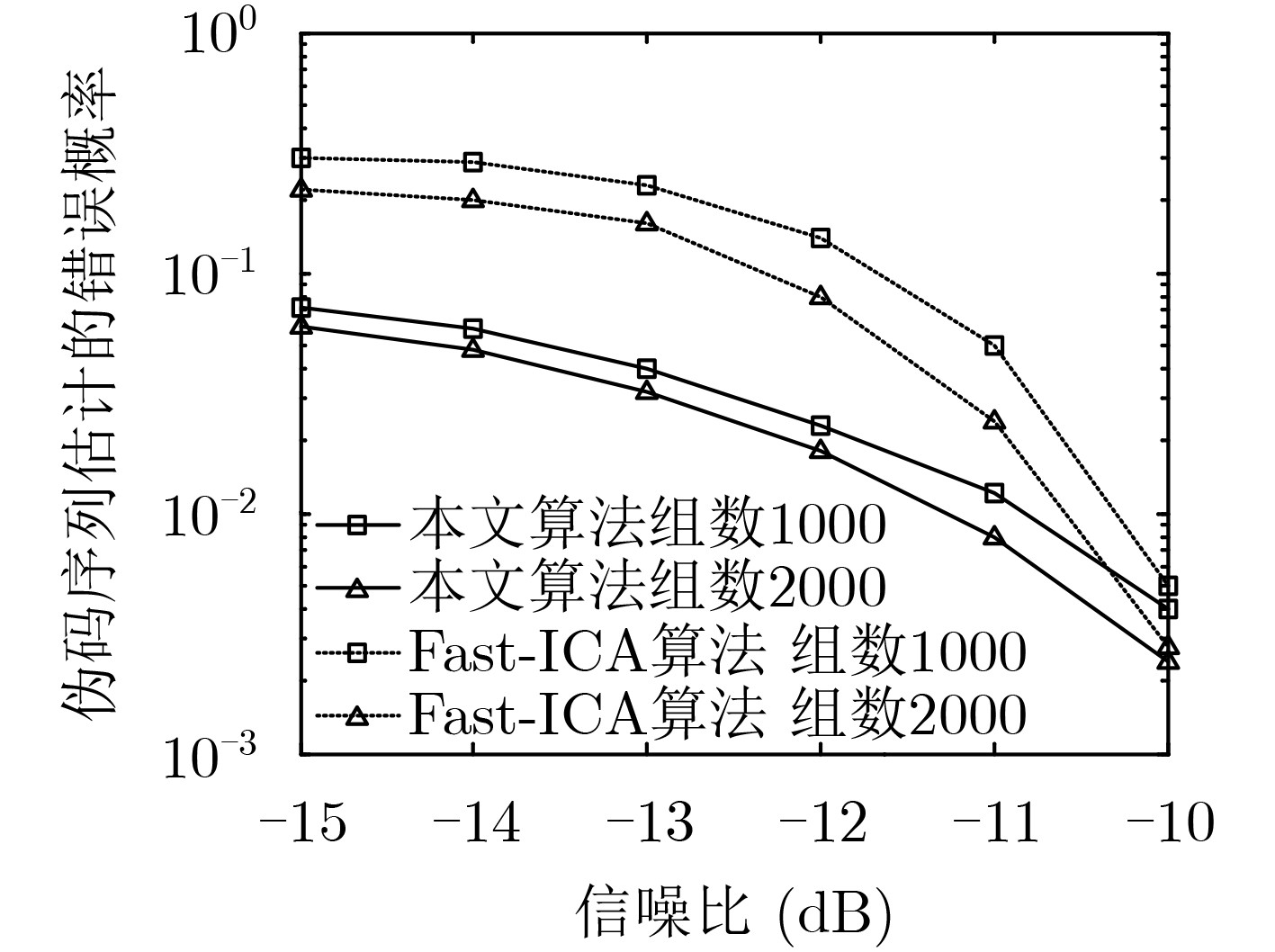
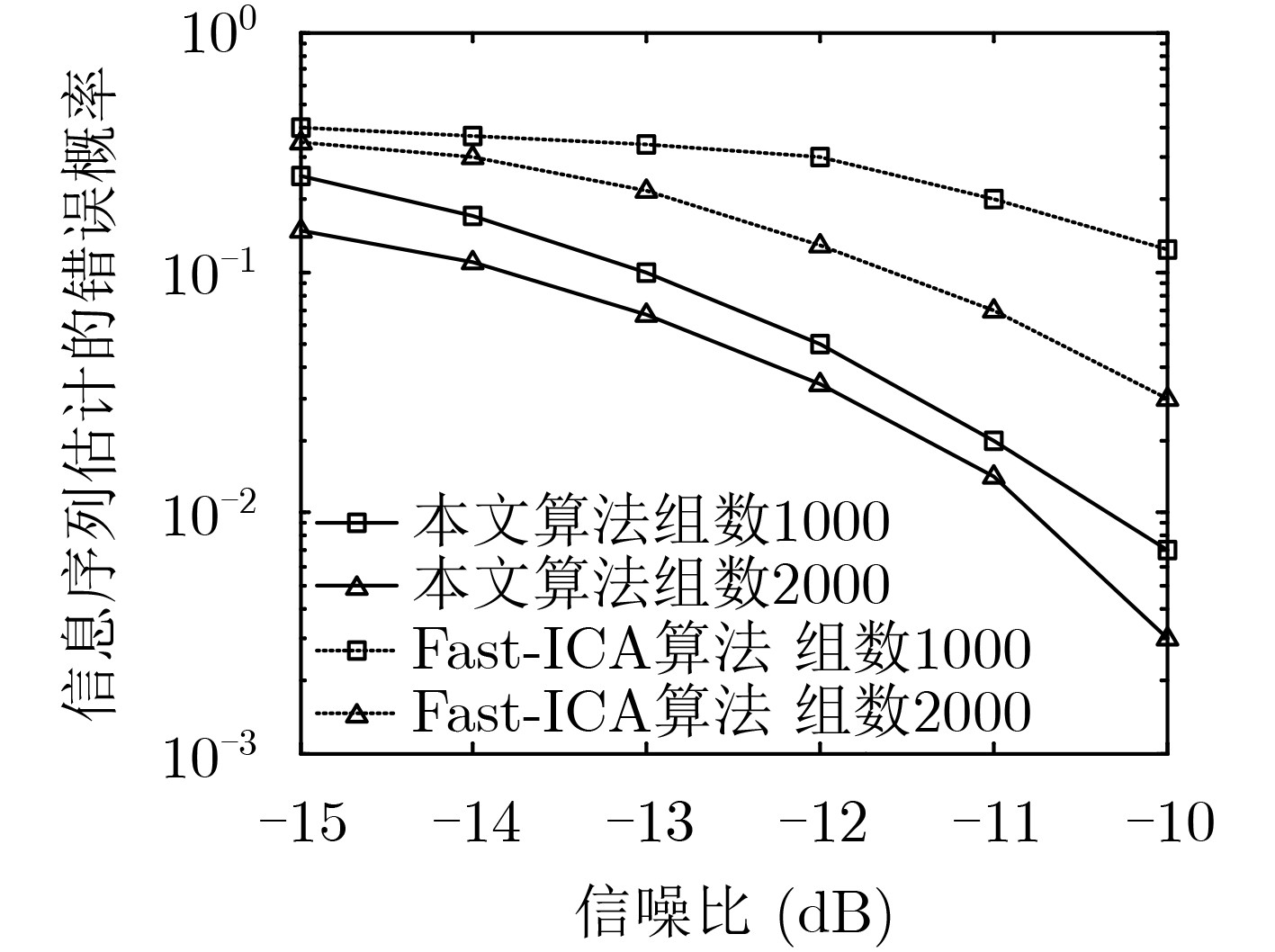
摘要: 针对低信噪比 (SNR)下存在多径效应的传统单通道异步长码直接序列码分多址(DS-CDMA)信号伪码序列(PN)及信息序列难估计问题,该文提出一种基于平行因子的多通道盲估计方法。该方法先将接收到的多径信号建模为多通道模型,然后将长码DS-CDMA信号建模成短码DS-CDMA信号的缺失数据模型,形成观测缺失数据矩阵,并将其等效为缺失平行因子模型,最后利用正则交替最小二乘法(ALS)对缺失平行因子进行低秩分解,实现多径环境下长码DS-CDMA信号各用户伪码序列及信息序列的盲估计。仿真结果表明,序列的估计性能与多径环境密切相关,且在莱斯因子为10,多径路数为3,通道数为4,用户数为6,信噪比大于–10 dB的条件下,伪码序列及信息序列的估计错误率均低于1%。
-
关键词:
- 长码直接序列码分多址信号 /
- 缺失数据模型 /
- 多径环境 /
- 伪码序列 /
- 信息序列
Abstract: For the problem of long code Direct Sequence-Code Division Multiple Access (DS-CDMA) signal in traditional asynchronous single-channel with multipath effect under low Signal-to-Noise Ratio (SNR), including blind estimation of the Pseudo-Noise (PN) sequence and information sequence, a method using multi-channel synchronous and asynchronous based on parallel factor is proposed. Firstly, the received signal in multipath environment is modeled as a multi-channel receiving model. And then the long code DS-CDMA signal is modeled as the short code DS-CDMA signal with missing data to form the observation missing-data matrix, which is equivalent to a parallel factor model with missing data. Finally, the regularized Alternating Least Squares (ALS) algorithm is applied to decompose the parallel factor, and the PN sequence and information sequence of long code DS-CDMA signals in multipath environment can be further estimated. Simulation results show that the performance of sequences estimation closely relates with the multipath environment, and the estimation error rate of 6 user PN sequences and information sequence is less than 1% under the condition that the Rician factor is equal to 10 and the number of path and channel are 3 and 4 respectively when the SNR is higher than -10 dB. -
田日才, 迟永钢. 扩频通信[M]. 2版. 北京: 清华大学出版社, 2014: 1–5.TIAN Richai and CHI Yonggang. Spread Spectrum Communication[M]. 2nd ed. Beijing: Tsinghua University Press, 2014: 1–5. 周杨, 张天骐. 同/异步短码DS-CDMA信号伪码序列及信息序列盲估计[J]. 电子与信息学报, 2019, 41(7): 1540–1547. doi: 10.11999/JEIT180812ZHOU Yang and ZHANG Tianqi. Blind estimation of the pseudo noise sequence and information sequence for short code synchronous and asynchronous DS-CDMA signal[J]. Journal of Electronics &Information Technology, 2019, 41(7): 1540–1547. doi: 10.11999/JEIT180812 张天骐, 强幸子, 马宝泽, 等. 基于最小二乘的同步多用户非周期长码直扩信号扩频序列估计[J]. 电波科学学报, 2016, 31(6): 1113–1123. doi: 10.13443/j.cjors.2016030201ZHANG Tianqi, QIANG Xingzi, MA Baoze, et al. Estimation of the spread spectrum sequence for synchronous multi-user aperiodic long-code DSSS signals based on least squares[J]. Chinese Journal of Radio Science, 2016, 31(6): 1113–1123. doi: 10.13443/j.cjors.2016030201 GU Xiaowei, ZHAO Zhijin, and SHEN Lei. Blind estimation of pseudo-random codes in periodic long code direct sequence spread spectrum signals[J]. IET Communications, 2016, 10(11): 1273–1281. doi: 10.1049/iet-com.2015.0374 赵知劲, 李淼, 尚俊娜. 基于矩阵填充和三阶相关的长短码DS-CDMA信号多伪码盲估计[J]. 电子与信息学报, 2016, 38(7): 1788–1793. doi: 10.11999/JEIT151087ZHAO Zhijin, LI Miao, and SHANG Junna. Blind estimation of LSC-DS-CDMA signal based on matrix completion and triple correlation[J]. Journal of Electronics &Information Technology, 2016, 38(7): 1788–1793. doi: 10.11999/JEIT151087 SHEN Lei and ZHAO Zhijing. Blind estimation of the pseudo-random sequences of direct sequence spread spectrum signals in multi-path using fast ICA[C]. 2009 Pacific-Asia Conference on Circuits, Communications and Systems, Chengdu, China, 2009: 531–535. doi: 10.1109/PACCS.2009.75. LUO Zhongqiang and ZHU Lidong. A charrelation matrix-based blind adaptive detector for DS-CDMA Systems[J]. Sensors, 2015, 15(8): 20152–20168. doi: 10.3390/s150820152 张天骐, 杨强, 宋玉龙, 等. 基于相似度的直扩信号盲解扩方法[J]. 系统工程与电子技术, 2017, 39(7): 1451–1456. doi: 10.3969/j.issn.1001-506X.2017.07.04ZHANG Tianqi, YANG Qiang, SONG Yulong, et al. Similarity based blind despread method of DS-SS signal[J]. Systems Engineering and Electronics, 2017, 39(7): 1451–1456. doi: 10.3969/j.issn.1001-506X.2017.07.04 LIANG Jianghai, WANG Xiang, WANG Fenghua, et al. Blind spreading sequence estimation algorithm for long-code DS-CDMA signals in asynchronous multi-user systems[J]. IET Signal Processing, 2017, 11(6): 704–710. doi: 10.1049/iet-spr.2016.0506 MEHBOODI S, FARHANG M, and JAMSHIDI A. Maximum likelihood estimation of pseudo-noise sequences in non-cooperative direct-sequence spread-spectrum communication systems[C]. 2016 24th Iranian Conference on Electrical Engineering, Shiraz, Iran, 2016: 119–123. doi: 10.1109/IranianCEE.2016.7585501. QIU Piyou, HUANG Zhitao, JIANG Wangliang, et al. Blind multiuser spreading sequences estimation algorithm for the direct-sequence code division multiple access signals[J]. IET Signal Processing, 2010, 4(5): 465–478. doi: 10.1049/iet-spr.2008.0254 任啸天, 徐晖, 黄知涛, 等. 基于Fast-ICA同、异步系统短码CDMA信号扩频序列与信息序列盲估计[J]. 电子学报, 2011, 39(12): 2726–2732.REN Xiaotian, XU Hui, HUANG Zhitao, et al. Fast-ICA based blind estimation of spreading and information sequences of short-code CDMA signals in synchronous and asynchronous systems[J]. Acta Electronica Sinica, 2011, 39(12): 2726–2732. 周义明, 李英顺, 田小平. 基于瑞利多径衰落信道的信号包络频谱感知[J]. 电子与信息学报, 2020, 42(5): 1231–1236. doi: 10.11999/JEIT190065ZHOU Yiming, LI Yingshun, and TIAN Xiaoping. Spectrum sensing based on signal envelope of Rayleigh multi-path fading channels[J]. Journal of Electronics &Information Technology, 2020, 42(5): 1231–1236. doi: 10.11999/JEIT190065 陈根华, 陈伯孝. 复杂多径信号下基于空域变换的米波雷达稳健测高算法[J]. 电子与信息学报, 2020, 42(5): 1297–1302. doi: 10.11999/JEIT190554CHEN Genhua and CHEN Baixiao. Robust altitude estimation based on spatial sign transform in the presence of diffuse multipath for very high frequency radar[J]. Journal of Electronics &Information Technology, 2020, 42(5): 1297–1302. doi: 10.11999/JEIT190554 牟青, 魏平. 基于缺失数据模型的长码直扩信号的伪码估计[J]. 电子学报, 2010, 38(10): 2365–2369.MOU Qing and WEI Ping. Spreading waveform estimation of long-code DS-SS signals based on missing-data model[J]. Acta Electronica Sinica, 2010, 38(10): 2365–2369. HARSHMAN R A, HONG S, and LUNDY M E. Shifted factor analysis—Part I: Models and properties[J]. Journal of Chemometrics, 2003, 17(7): 363–378. doi: 10.1002/cem.808 韩曦. 基于多维矩阵的移动通信信号检测及参数估计技术研究[D]. [博士论文], 北京邮电大学, 2013: 18–22.HAN Xi. Research on signal detection and parameter estimation in mobile communications based on multi-way arrays[D]. [Ph. D. dissertation], Beijing University of Posts and Telecommunications, 2013: 18–22. SIDIROPOULOS N D, GIANNAKIS G B, and BRO R. Blind PARAFAC receivers for DS-CDMA systems[J]. IEEE Transactions on Signal Processing, 2000, 48(3): 810–823. doi: 10.1109/78.824675 张贤达. 矩阵分析与应用[M]. 2版. 北京: 清华大学出版社, 2013: 604–608.ZHANG Xianda. Matrix Analysis and Applications[M]. 2nd ed. Beijing: Tsinghua University Press, 2013: 604–608. -


 下载:
下载:











图(9)
计量
- 文章访问数: 1645
- HTML全文浏览量: 988
- PDF下载量: 44
- 被引次数: 0
