

Multi-index Prediction Model of Wheat Quality Based on Long Short-Term Memory and Generative Adversarial Network
-
摘要:
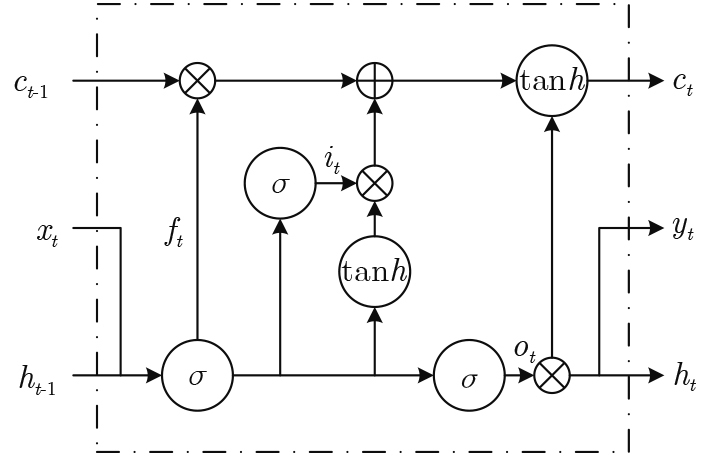
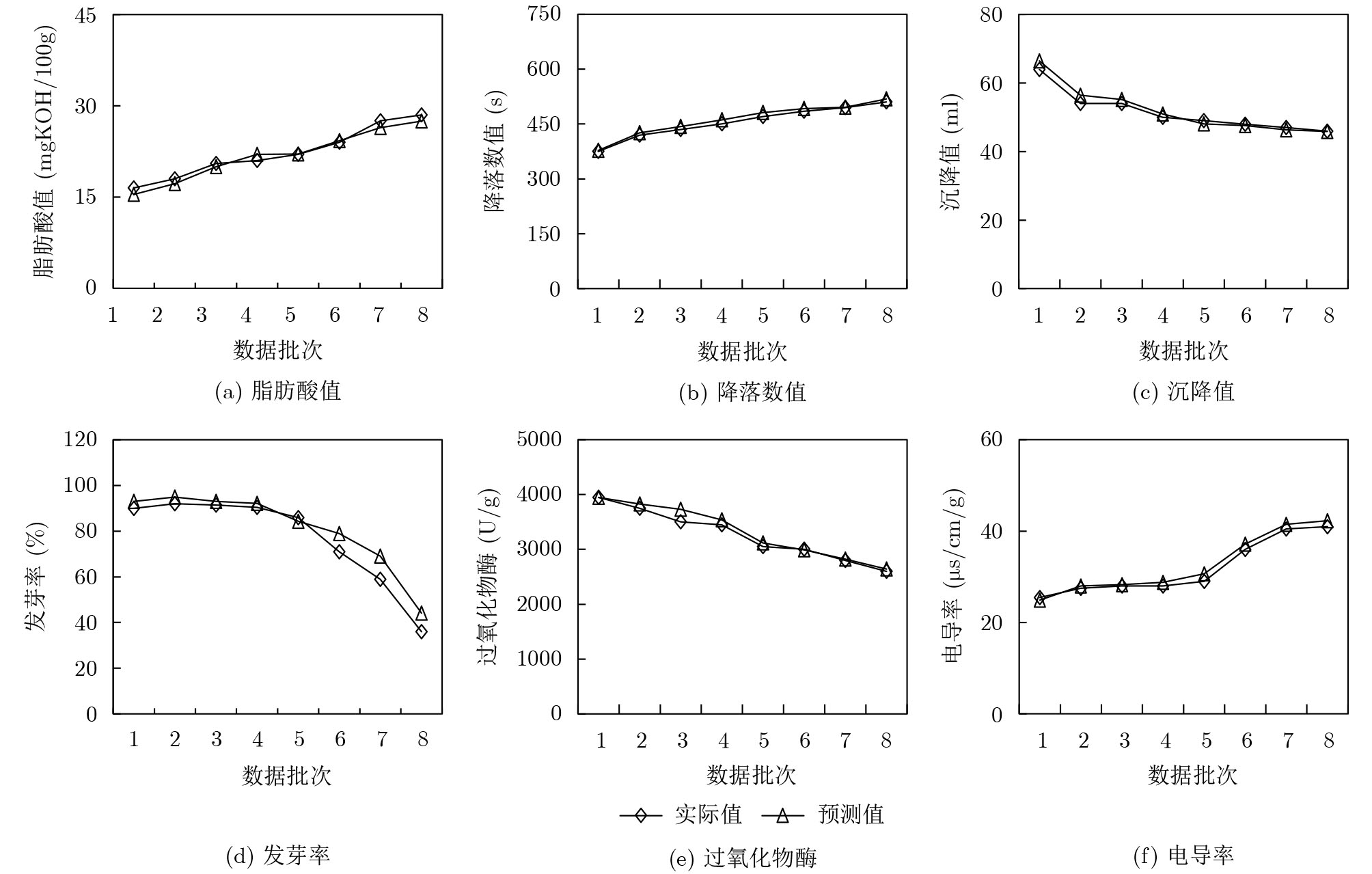
小麦多生理生化指标变化趋势反映了储藏品质的劣变状态,预测多指标时序数据会因关联性及相互作用而产生较大误差,为此该文基于长短期记忆网络(LSTM)和生成式对抗网络(GAN)提出一种改进拓扑结构的长短期记忆生成对抗网络(LSTM-GAN)模型。首先,由LSTM预测多指标不同时序数据的劣变趋势;其次,根据多指标的关联性并结合GAN的对抗学习方法来降低综合预测误差;最后通过优化目标函数及训练模型得出多指标预测结果。经实验分析发现:小麦多指标的长短期时序数据的变化趋势不同,进一步优化模型结构及训练时序长度可有效降低预测结果的误差;特定条件下小麦品质过快劣变会使多指标预测误差增大,因此应充分考虑储藏期环境变化对多指标数据的影响;LSTM-GAN模型的综合误差相对于仅使用LSTM预测降低了9.745%,并低于多种对比模型,这有助于提高小麦品质多指标预测及分析的准确性。
Abstract:The change trend of multi-index of wheat reflects the deterioration state of storage quality, while the predicted multi-index data will produce large errors due to its correlation and interaction. For this reason, an improved Long Short-Term Memory and Generative Adversarial Network(LSTM-GAN) model is proposed. The deterioration trend of different time series data of multi-index is predicted by Long Short-Term Memory(LSTM) network, and the improved model may reduce comprehensive prediction error by using Generative Adversarial Network(GAN) according to the correlation of multi-index. Finally, the prediction results obtained by optimizing the objective function and model structure. The experimental analysis shows that the training sequence length and structural parameters of the optimization model can effectively reduce the error of the prediction result. The deterioration of wheat quality under certain conditions will increase the prediction error of multi-index. Therefore, the influence of environmental changes during storage period on multi-index data should be fully considered. The comprehensive error of the LSTM-GAN model is reduced by 9.745% compared with the LSTM prediction and lower than multiple comparison models, which can improve the prediction of wheat quality indexes.
-
表 1 小麦多指标数据集统计信息
最小值 最大值 均值 标准差 脂肪酸值(mgKOH/100 g) 16.00 30.50 23.18 4.24 降落数值(s) 365.00 630.00 482.81 69.36 沉降值(ml) 19.50 62.00 40.11 13.94 发芽率(%) 0 97.00 71.29 28.96 过氧化物酶(U/g) 1400.00 4100.00 3171.35 667.93 电导率(μs/(cm·g)) 25.50 60.50 39.11 8.75  下载: 导出CSV
下载: 导出CSV
表 2 模型不同训练窗口长度误差对比
窗口长度 2 4 6 8 脂肪酸值 0.260 0.258 0.308 0.328 降落数值 0.325 0.263 0.228 0.277 沉降值 0.356 0.447 0.336 0.407 发芽率 0.652 0.530 0.483 0.511 过氧化物酶 0.424 0.455 0.402 0.415 电导率 0.412 0.324 0.329 0.374
下载: 导出CSV
表 3 LSTM-GAN模型不同结构参数训练误差
隐含层层数 2 3 5 神经元个数 6 8 10 12 6 8 10 12 6 8 10 12 脂肪酸值 0.285 0.245 0.275 0.281 0.265 0.290 0.260 0.285 0.255 0.355 0.345 0.335 降落数值 0.295 0.265 0.305 0.335 0.315 0.235 0.300 0.342 0.335 0.315 0.335 0.355 沉降值 0.400 0.405 0.410 0.427 0.405 0.425 0.435 0.533 0.445 0.540 0.315 0.493 发芽率 0.505 0.560 0.488 0.494 0.610 0.570 0.532 0.582 0.635 0.623 0.657 0.625 过氧化物酶 0.365 0.345 0.340 0.342 0.370 0.280 0.300 0.369 0.325 0.380 0.415 0.409 电导率 0.330 0.370 0.340 0.404 0.440 0.375 0.425 0.417 0.555 0.370 0.435 0.454 综合误差 2.180 2.190 2.158 2.284 2.405 2.175 2.252 2.528 2.550 2.583 2.502 2.671
下载: 导出CSV
表 4 不同筋力小麦多指标预测误差对比
强筋 中筋 弱筋 脂肪酸值 0.275 0.295 0.315 降落数值 0.305 0.290 0.255 沉降值 0.360 0.320 0.245 发芽率 0.422 0.419 0.428 过氧化物酶 0.390 0.350 0.365 电导率 0.290 0.300 0.335
下载: 导出CSV
表 5 不同模型预测误差对比
LSTM-GAN LSTM 线性回归 SVR ANN GM 脂肪酸值 0.275 0.285 0.290 0.303 0.326 0.386 降落数值 0.305 0.329 0.577 0.405 0.402 0.511 沉降值 0.410 0.482 0.563 0.366 0.459 0.498 发芽率 0.488 0.553 0.611 0.467 0.466 0.559 过氧化物酶 0.340 0.378 0.604 0.469 0.460 0.452 电导率 0.340 0.364 0.331 0.372 0.373 0.413 综合误差 2.158 2.391 2.976 2.381 2.484 2.817
下载: 导出CSV
-
KALSA K K, SUBRAMANYAM B, DEMISSIE G, et al. Evaluation of postharvest preservation strategies for stored wheat seed in Ethiopia[J]. Journal of Stored Products Research, 2019, 81: 53–61. doi: 10.1016/j.jspr.2019.01.001 ZHANG Shuaibing, LÜ Yangyong, WANG Yuli, et al. Physiochemical changes in wheat of different hardnesses during storage[J]. Journal of Stored Products Research, 2017, 72: 161–165. doi: 10.1016/j.jspr.2017.05.002 陈红松, 陈京九. 基于循环神经网络的无线网络入侵检测分类模型构建与优化研究[J]. 电子与信息学报, 2019, 41(6): 1427–1433. doi: 10.11999/JEIT180691CHEN Hongsong and CHEN Jingjiu. Recurrent neural networks based wireless network intrusion detection and classification model construction and optimization[J]. Journal of Electronics &Information Technology, 2019, 41(6): 1427–1433. doi: 10.11999/JEIT180691 XU Peng, DU Rui, ZHANG Zhongbao, et al. Predicting pipeline leakage in petrochemical system through GAN and LSTM[J]. Knowledge-Based Systems, 2019, 175: 50–61. doi: 10.1016/j.knosys.2019.03.013 MAHASSENI B, LAM M, and TODOROVIC S. Unsupervised video summarization with adversarial lstm networks[C]. 2017 IEEE conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2982–2991. doi: 10.1109/CVPR.2017.318. YANG Yang, ZHOU Jie, AI Jiangbo, et al. Video captioning by adversarial LSTM[J]. IEEE Transactions on Image Processing, 2018, 27(11): 5600–5611. doi: 10.1109/TIP.2018.2855422 GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. 曹志义, 牛少彰, 张继威. 基于半监督学习生成对抗网络的人脸还原算法研究[J]. 电子与信息学报, 2018, 40(2): 323–330. doi: 10.11999/JEIT170357CAO Zhiyi, NIU Shaozhang, and ZHANG Jiwei. Research on face reduction algorithm based on generative adversarial nets with semi-supervised learning[J]. Journal of Electronics &Information Technology, 2018, 40(2): 323–330. doi: 10.11999/JEIT170357 蒋华伟, 张磊, 周同星. 基于信息熵的小麦储藏品质多指标权重模型研究[J]. 中国粮油学报, 2020, 35(6): 105–113. doi: 10.3969/j.issn.1003-0174.2020.06.016JIANG Huawei, ZHANG Lei, and ZHOU Tongxing. Research on multi-index weight model of wheat storage quality based on information entropy[J]. Journal of the Chinese Cereals and Oils Association, 2020, 35(6): 105–113. doi: 10.3969/j.issn.1003-0174.2020.06.016 刘威, 刘尚, 白润才, 等. 互学习神经网络训练方法研究[J]. 计算机学报, 2017, 40(6): 1291–1308. doi: 10.11897/SP.J.1016.2017.01291LIU Wei, LIU Shang, BAI Runcai, et al. Research of mutual learning neural network training method[J]. Chinese Journal of Computers, 2017, 40(6): 1291–1308. doi: 10.11897/SP.J.1016.2017.01291 高艳娜. 小麦产后品质变化规律研究[D]. [硕士论文], 河南工业大学, 2010.GAO Yanna. Study on the changes of postpartum quality in wheat[D]. [Master dissertation], Henan University of Technology, 2010. FRIEDMAN L and KOMOGORTSEV O V. Assessment of the effectiveness of seven biometric feature normalization techniques[J]. IEEE Transactions on Information Forensics and Security, 2019, 14(10): 2528–2536. doi: 10.1109/TIFS.2019.2904844 GREFF K, SRIVASTAVA R K, KOUTNÍK J, et al. LSTM: A search space odyssey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(10): 2222–2232. doi: 10.1109/TNNLS.2016.2582924 FANG Tingting and LAHDELMA R. Evaluation of a multiple linear regression model and SARIMA model in forecasting heat demand for district heating system[J]. Applied Energy, 2016, 179: 544–552. doi: 10.1016/j.apenergy.2016.06.133 XU Jie, XU Chen, ZOU Bin, et al. New incremental learning algorithm with support vector machines[J]. IEEE Transactions on Systems, Man, and Cybernetics; Systems, 2019, 49(11): 2230–2241. doi: 10.1109/tsmc.2018.2791511 VILLARRUBIA G, DE PAZ J F, CHAMOSO P, et al. Artificial neural networks used in optimization problems[J]. Neurocomputing, 2018, 272: 10–16. doi: 10.1016/j.neucom.2017.04.075 DING Song, HIPEL K W, and DANG Yaoguo. Forecasting China’s electricity consumption using a new grey prediction model[J]. Energy, 2018, 149: 314–328. doi: 10.1016/j.energy.2018.01.169 -

 下载:
下载:



计量
- 文章访问数: 1747
- HTML全文浏览量: 841
- PDF下载量: 136
- 被引次数: 0
