

Adaptive Incremental Kalman Filter Based on Innovation
-
摘要: 在一定环境条件下,当系统的量测方程没有进行验证或校准时,使用该量测方程往往会产生未知的系统误差,从而导致较大的滤波误差。增量方程的引入可以有效解决欠观测系统的状态估计问题。该文考虑带未知噪声统计的线性离散增量系统,首先提出一种基于新息的噪声统计估计算法。可以得到系统噪声统计的无偏估计。进而,提出一种新的增量系统自适应Kalman滤波算法。相比已有的自适应增量滤波算法,该文所提算法得到的状态估计精度更高。两个仿真实例证明了其有效性和可行性。
-
关键词:
- 自适应Kalman滤波 /
- 增量滤波器 /
- 欠观测系统 /
- 增量系统 /
- 滤波精度
Abstract: Under certain environmental conditions, the unknown system errors often occur and yield to larger filtering errors when the unverified or uncalibrated measurement equation is used. Incremental equation can be introduced, which can effectively solve the problem of state estimation for the systems under poor observation condition. In this paper, the linear discrete incremental system with unknown noise statistics is considered. Firstly, a noise statistics estimation algorithm is proposed based on innovation. The unbiased estimation of system noise statistics can be obtained. Furthermore, a new incremental system adaptive Kalman filtering algorithm is proposed. Compared with the existing adaptive incremental filtering algorithm, the state estimation accuracy of the proposed algorithm is higher. Two simulation examples prove its effectiveness and feasibility. -
SAGE A P and HUSA G W. Adaptive filtering with unknown prior statistics[C]. Joint Automatic Control Conference, Boulder, American, 1969: 760–769. KALMAN R E. A new approach to linear filtering and prediction problems[J]. Journal of Basic Engineering, 1960, 82(1): 35–45. doi: 10.1115/1.3662552 邓自立. 自校正滤波理论及其应用——现代时间序列分析方法[M]. 哈尔滨: 哈尔滨工业大学出版社, 2003: 6.1. 何丽, 汤莉. 基于Kalman滤波的云数据中心能耗和性能优化[J]. 计算机工程与科学, 2018, 40(7): 1165–1172. doi: 10.3969/j.issn.1007-130X.2018.07.003HE Li and TANG Li. Energy and performance optimization based on Kalman filtering in the cloud data center[J]. Computer Engineering &Science, 2018, 40(7): 1165–1172. doi: 10.3969/j.issn.1007-130X.2018.07.003 张宏伟, 谢维信. 平滑约束无迹卡尔曼滤波器[J]. 信号处理, 2019, 35(3): 466–471. doi: 10.16798/j.issn.1003-0530.2019.03.019ZHANG Hongwei and XIE Weixin. Smoothly constrained unscented Kalman filter[J]. Journal of Signal Processing, 2019, 35(3): 466–471. doi: 10.16798/j.issn.1003-0530.2019.03.019 耿友林, 解成博, 尹川, 等. 基于卡尔曼滤波的接收信号强度指示差值定位算法[J]. 电子与信息学报, 2019, 41(2): 455–461. doi: 10.11999/JEIT180268GENG Youlin, XIE Chengbo, YIN Chuan, et al. Received signal strength indication difference location algorithm based on Kalman filter[J]. Journal of Electronics &Information Technology, 2019, 41(2): 455–461. doi: 10.11999/JEIT180268 汪玲, 朱栋强, 马凯莉, 等. 空间目标卡尔曼滤波稀疏成像方法[J]. 电子与信息学报, 2018, 40(4): 846–852. doi: 10.11999/JEIT170319WANG Ling, ZHU Dongqiang, MA Kaili, et al. Sparse imaging of space targets using Kalman filter[J]. Journal of Electronics &Information Technology, 2018, 40(4): 846–852. doi: 10.11999/JEIT170319 SUN Xiaojun, GAO Yuan, DENG Zili, et al. Multi-model information fusion Kalman filtering and white noise deconvolution[J]. Information Fusion, 2010, 11: 163–173. doi: 10.1016/j.inffus.2009.06.004 刘利生, 吴斌, 杨萍. 航天器精确定轨与自校准技术[M]. 北京: 国防工业出版社, 2005: 9.2.LIU Lisheng, WU Bin, and YANG Ping. Orbit Precision Determination & Self-Calibration Technique of Spacecraft[M]. Beijing: National Defense Industry Press, 2005: 9.2. 傅惠民, 娄泰山, 吴云章. 欠观测条件下的扩展增量Kalman滤波方法[J]. 航空动力学报, 2012, 27(4): 777–781. doi: 10.13224/j.cnki.jasp.2012.04.004FU Huimin, LOU Taishan, and WU Yunzhang. Extended incremental Kalman filter method under poor observation condition[J]. Journal of Aerospace Power, 2012, 27(4): 777–781. doi: 10.13224/j.cnki.jasp.2012.04.004 傅惠民, 娄泰山, 吴云章. 增量粒子滤波方法[J]. 航空动力学报, 2013, 28(6): 1201–1207. doi: 10.13224/j.cnki.jasp.2013.06.005FU Huimin, LOU Taishan, and WU Yunzhang. Incremental particle filter method[J]. Journal of Aerospace Power, 2013, 28(6): 1201–1207. doi: 10.13224/j.cnki.jasp.2013.06.005 傅惠民, 吴云章, 娄泰山. 欠观测条件下的增量Kalman滤波方法[J]. 机械强度, 2012, 34(1): 43–47. doi: 10.16579/j.issn.1001.9669.2012.01.014FU Huimin, WU Yunzhang, and LOU Taishan. Incremental Kalman filter method under poor observation condition[J]. Journal of Mechanical Strength, 2012, 34(1): 43–47. doi: 10.16579/j.issn.1001.9669.2012.01.014 SUN Xiaojun, YAN Guangming, and ZHANG Bo. A Kind of incremental Kalman smoother under poor observation condition[C]. The 36th Chinese Control Conference, Dalian, China, 2017: 2524–2527. doi: 10.23919/ChiCC.2017.8027740. SUN Xiaojun and YAN Guangming. Multi-sensor optimal weighted fusion incremental Kalman smoother[J]. Journal of Systems Engineering and Electronics, 2018, 29(2): 262–268. doi: 10.21629/JSEE.2018.02.06 徐景硕, 秦永元, 彭蓉. 自适应卡尔曼滤波器渐消因子选取方法研究[J]. 系统工程与电子技术, 2004, 26(11): 1552–1554. doi: 10.3321/j.issn:1001-506X.2004.11.006XU Jingshuo, QIN Yongyuan, and PENG Rong. New method for selecting adaptive Kalman filter fading factor[J]. Systems Engineering and Electronics, 2004, 26(11): 1552–1554. doi: 10.3321/j.issn:1001-506X.2004.11.006 鲁平, 赵龙, 陈哲. 改进的Sage-Husa自适应滤波及其应用[J]. 系统仿真学报, 2007, 19(15): 3503–3505. doi: 10.3969/j.issn.1004-731X.2007.15.034LU Ping, ZHAO Long, and CHEN Zhe. Improved Sage-Husa adaptive filtering and its application[J]. Journal of System Simulation, 2007, 19(15): 3503–3505. doi: 10.3969/j.issn.1004-731X.2007.15.034 傅惠民, 吴云章, 娄泰山. 自适应增量Kalman滤波方法[J]. 航空动力学报, 2012, 27(6): 1125–1129.FU Huimin, WU Yunzhang, and LOU Taishan. Adaptive incremental Kalman filter method[J]. Journal of Aerospace Power, 2012, 27(6): 1125–1129. 徐英蛟. 一种改进自适应增量Kalman滤波的传递对准算法[J]. 指挥控制与仿真, 2018, 40(4): 33–37. doi: 10.3969/j.issn.1673-3819.2018.04.008XU Yingjiao. A improved adaptive incremental filtering algorithm of transfer alignment[J]. Command Control &Simulation, 2018, 40(4): 33–37. doi: 10.3969/j.issn.1673-3819.2018.04.008 傅惠民, 吴云章, 娄泰山. 自适应增量粒子滤波方法[J]. 航空动力学报, 2013, 28(8): 1764–1768.FU Huimin, WU Yunzhang, and LOU Taishan. Adaptive incremental particle filter method[J]. Journal of Aerospace Power, 2013, 28(8): 1764–1768. 傅惠民, 吴琼. 线性独立增量过程分析方法[J]. 航空动力学报, 2010, 25(4): 930–935.FU Huimin and WU Qiong. Analysis method for linear process with independent increments[J]. Journal of Aerospace Power, 2010, 25(4): 930–935. -


 下载:
下载:


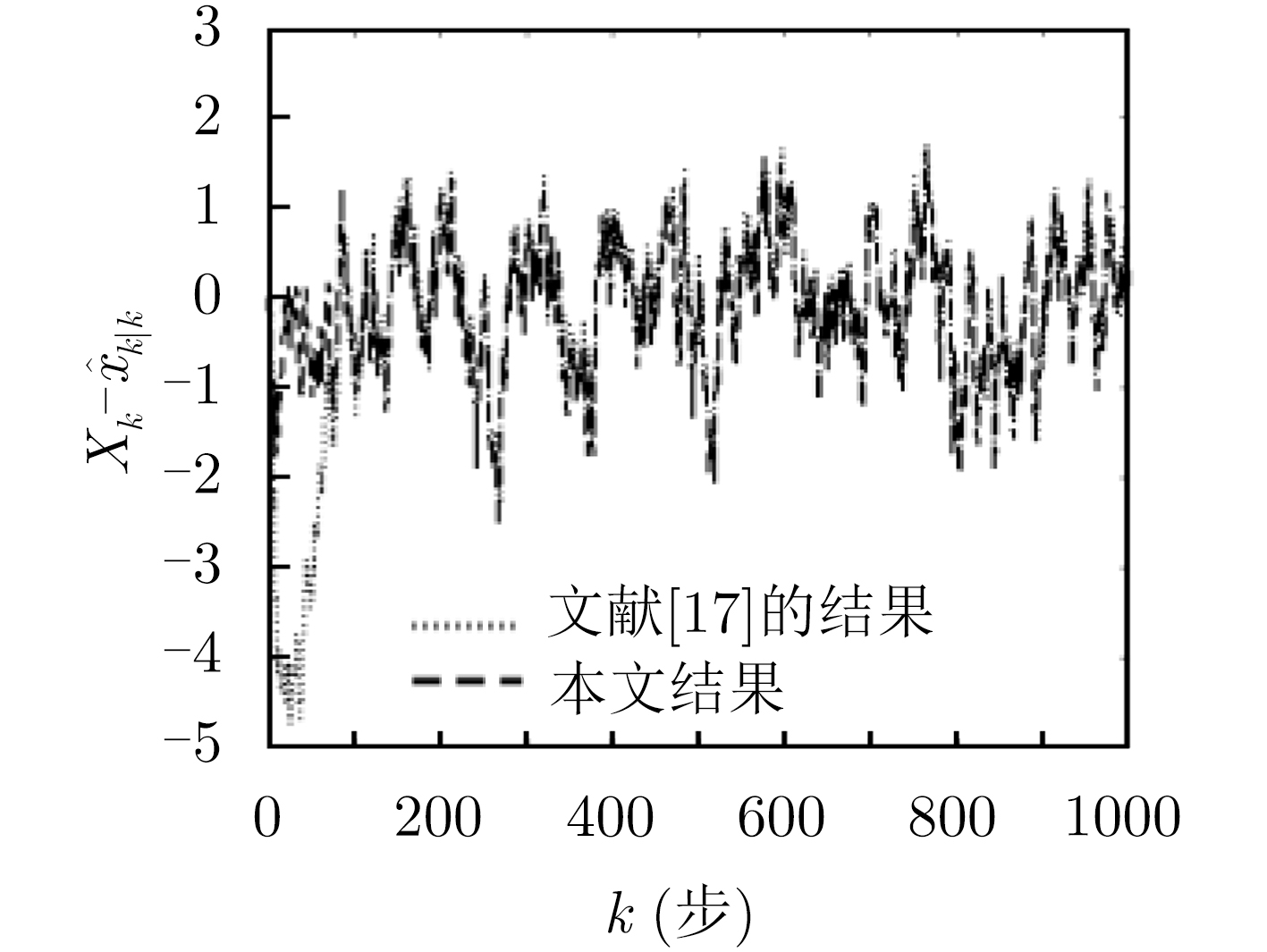

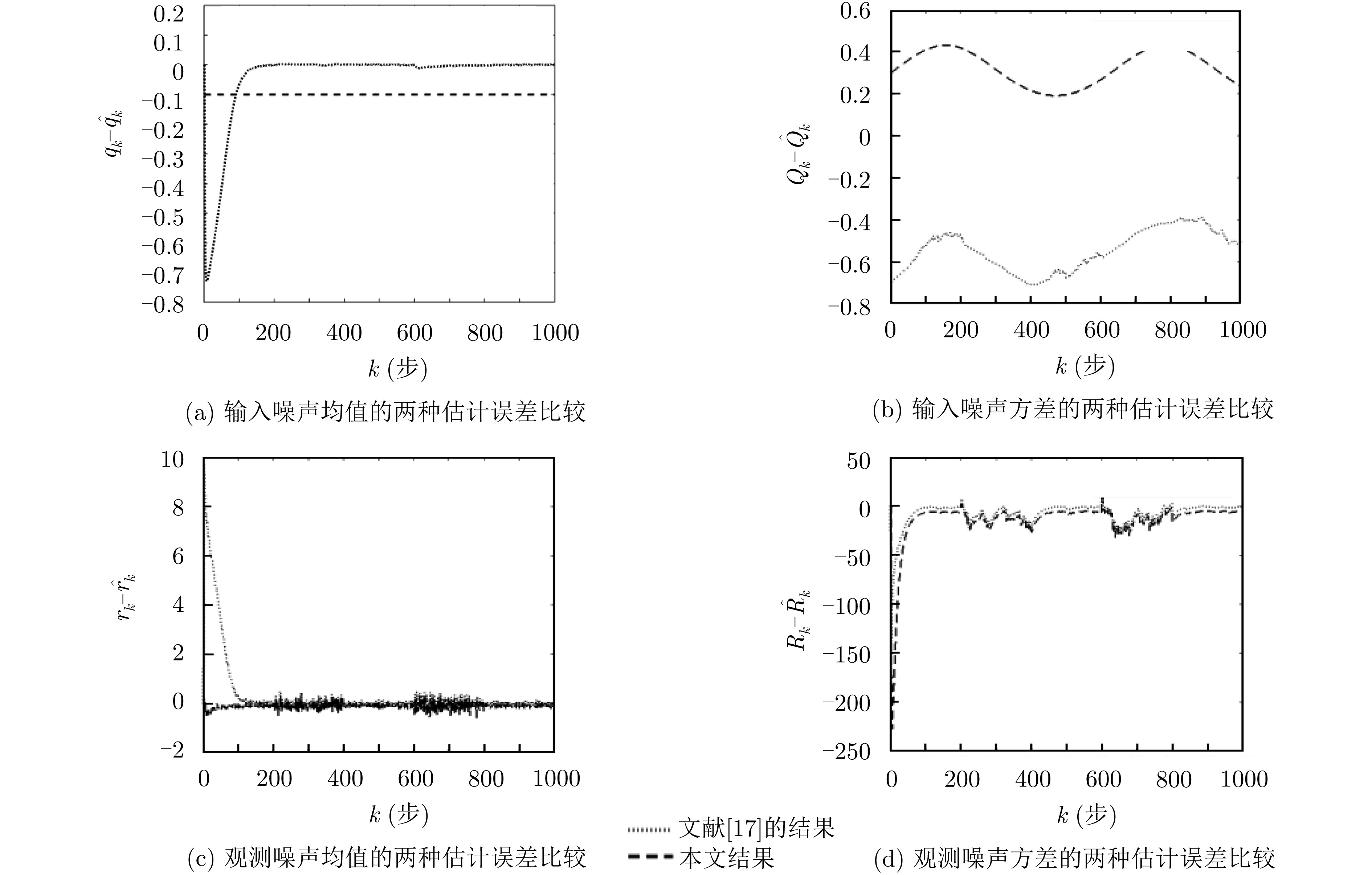




图(8)
计量
- 文章访问数: 3220
- HTML全文浏览量: 1336
- PDF下载量: 166
- 被引次数: 0
