

Impossible Differential Cryptanalysis of LiCi Block Cipher
-
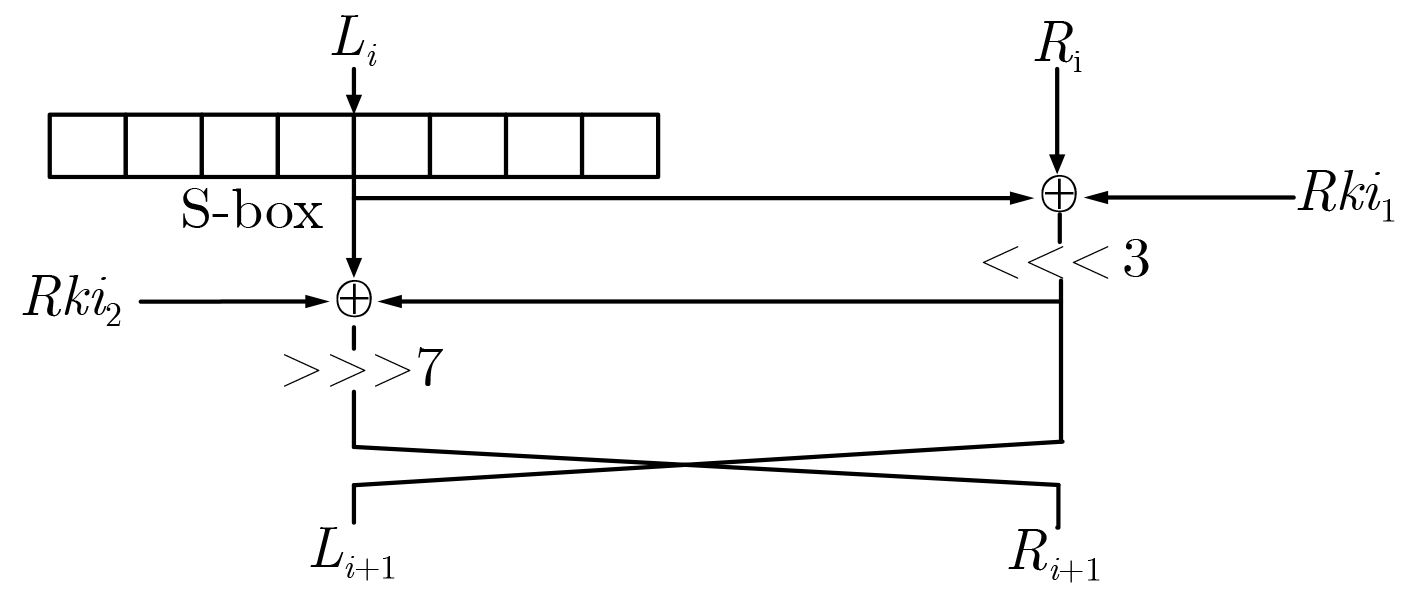
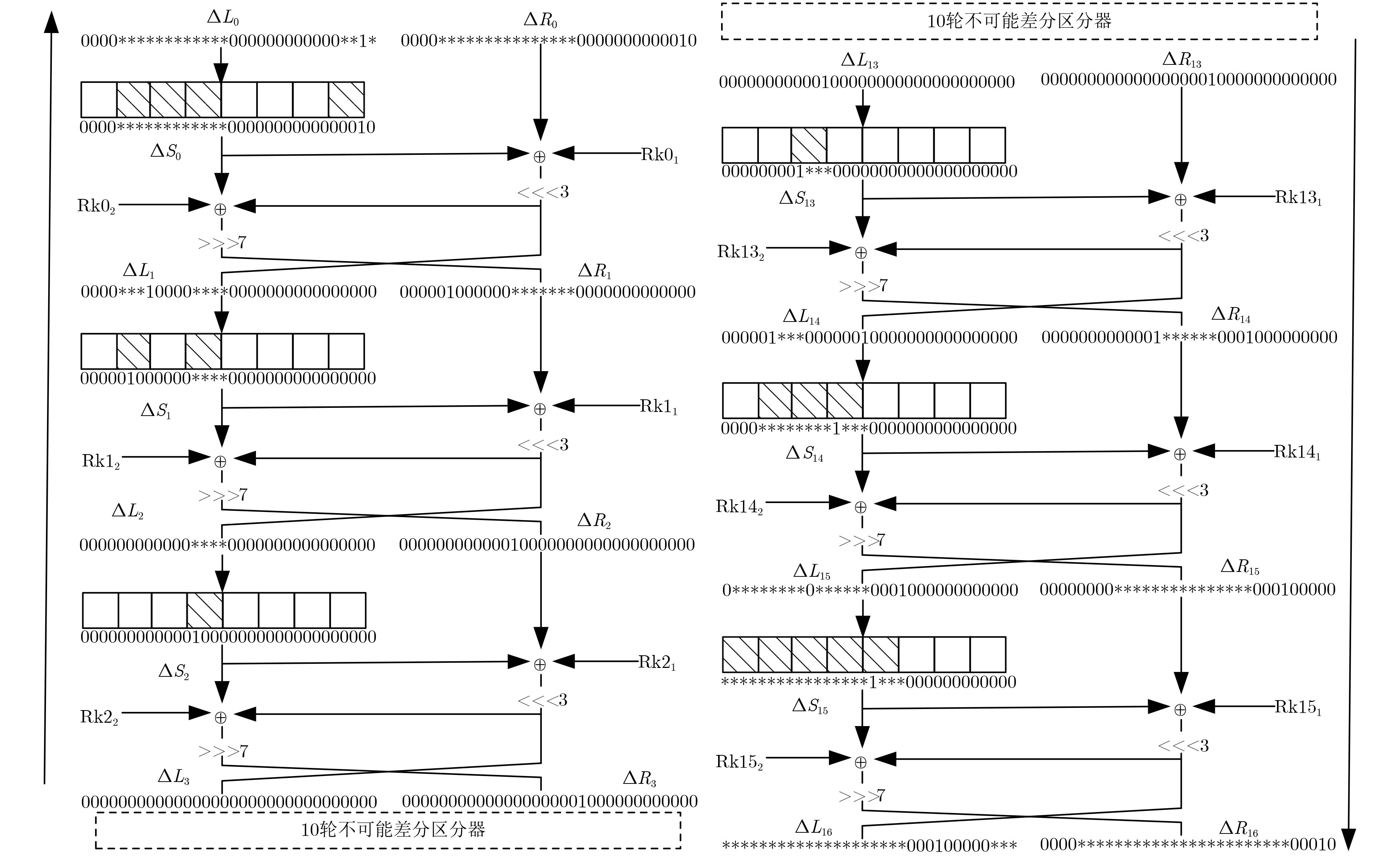
摘要: LiCi是由Patil等人(2017)提出的轻量级分组密码算法。由于采用新型的设计理念,该算法具有结构紧凑、能耗低、占用芯片面积小等优点,特别适用于资源受限的环境。目前该算法的安全性备受关注,Patil等人声称:16轮简化算法足以抵抗经典的差分攻击及线性攻击。该文基于S盒的差分特征,结合中间相遇思想,构造了一个10轮的不可能差分区分器。基于此区分器,向前后各扩展3轮,并利用密钥编排方案,给出了LiCi的一个16轮的不可能差分分析方法。该攻击需要时间复杂度约为283.08次16轮加密,数据复杂度约为259.76选择明文,存储复杂度约为276.76数据块,这说明16轮简化的LiCi算法无法抵抗不可能差分攻击。Abstract: LiCi algorithm is a newly lightweight block cipher. Due to its new design idea adopted by Patil et al, it has the advantages of compact design, low energy consumption and less chip area, thus is is especially suitable for resource-constrained environments. Currently, its security receives extensively attention, and Patil et al. claimed that the 16-round reduced LiCi can sufficiently resist both differential attack and linear attack. In this paper, a new 10-round impossible differential distinguisher is constructed based on the differential characteristics of the S-box and the meet-in-the-middle technique. Moreover, on the basis of this distinguisher, a 16-round impossible differential attack on LiCi is proposed by respectively extending 3-round forward and backward via the key scheduling scheme. This attack requires a time complexity of about 283.08 16-round encryptions, a data complexity of about 259.76 chosen plaintexts, and a memory complexity of 276.76 data blocks, which illustrates that the 16-round LiCi cipher can not resist impossible differential attack.
-
表 1 S盒输入/输出差分特征
输入差分 0001 0100 1000 1100 1101 **11 **1* **0* ***1 ***0 输出差分 1*** ***1 ***1 1**0 0*** 0001 0010 0011 0100 0101  下载: 导出CSV
下载: 导出CSV
表 2 S盒输入/输出差分特征概率
输入差分 **11 **1* ***1 **** 0001 0*** *0** 01** *000 输出差分 0001 0010 0100 1000 1*** **** **** **** **** 概率 1/4 1/8 1/8 1/16 1/8 1/2 1/2 1/4 1/8
下载: 导出CSV
表 3 不可能差分分析16轮LiCi算法的密钥恢复各步骤的时间复杂度
步骤 恢复的密钥比特 猜测比特数目 时间复杂度(单位:次16轮加密所用的时间) (1) – 0 ${2^{m + 49}} \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 42}}$ (2) ${\rm{Rk}}{0_1}\left[ {24 \sim 21} \right]$ 4 ${2^{m + 21}} \times {2^4} \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 18}}$ (3) ${\rm{Rk}}{15_2}\left[ {15 \sim 12} \right]$ 4 ${2^{m + 18}} \times {2^4} \times {2^4} \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 19}}$ (4) ${\rm{Rk}}{15_2}\left[ {31 \sim 28} \right]$ 4 ${2^{m + 15}} \times {2^4} \times {2^4} \times {2^4} \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 20}}$ (5) ${\rm{Rk}}{15_2}\left[ {23 \sim 20} \right]$ 4 ${2^{m + 14}} \times {2^4} \times {2^4} \times {2^4} \times {2^4} \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 23}}$ (6) ${\rm{Rk}}{15_1}\left[ {16 \sim 13} \right]$, ${\rm{Rk}}{14_2}\left[ {23 \sim 20} \right]$ 8 ${2^{m + 13}} \times {2^4} \times {2^4} \times {2^4} \times {2^4} \times {2^8} \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 30}}$ (7) ${\rm{Rk}}{15_2}\left[ {19 \sim 16,11 \sim 9} \right]$, ${\rm{Rk}}{15_1}\left[ {12 \sim 9} \right]$, ${\rm{Rk}}{14_2}\left[ {19 \sim 16} \right]$ 12 ${2^{m + 10}} \times {2^{16}} \times {2^8} \times {2^{12}} \times 2 \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 40}}$ (8) ${\rm{Rk}}{15_2}\left[ {27 \sim 24} \right]$, ${\rm{Rk}}{15_1}\left[ {20 \sim 17} \right]$, ${\rm{Rk}}{14_2}\left[ {27 \sim 24} \right]$ 12 ${2^{m + 7}} \times {2^{24}} \times {2^{12}} \times {2^{12}} \times 2 \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 49}}$ (9) ${\rm{Rk}}{15_2}\left[ {8 \sim 6} \right]$, ${\rm{Rk}}{15_1}\left[ {8 \sim 6} \right]$, ${\rm{Rk}}{15_2}\left[ {15 \sim 13} \right]$, ${\rm{Rk}}{14_1}\left[ {16 \sim 13} \right]$ 10 ${2^{m + 5}} \times {2^{24}} \times {2^{12}} \times {2^{12}} \times {2^{10}} \times 2 \times \frac{1}{{8 \times 16}} = {2^{{{m}} + 56}}$ (10) ${\rm{Rk}}{0_1}\left[ {20 \sim 9} \right]$, ${\rm{Rk}}{0_2}\left[ {23 \sim 20} \right]$, ${\rm{Rk}}{1_1}\left[ {16 \sim 13} \right]$ 20 ${2^{m{\rm{ - }}16}} \times {2^{58}} \times {2^{20}} \times 3 \times \frac{1}{{8 \times 16}} + {2^{74}} = {2^{{{m}} + 56.58}} + {2^{74}}$
下载: 导出CSV
-
BIRYUKOV A and PERRIN L. State of the art in lightweight symmetric cryptography[R]. Cryptology ePrint Archive: Report 2017/511, 2017: 1–11. GUO Jian, PEYRIN T, POSCHMANN A, et al. The LED block cipher[C]. Proceedings of the 13th International Workshop on Cryptographic Hardware and Embedded Systems, Nara, Japan, 2011: 326–341. BOGDANOV A, KNUDSEN L R, LEANDER G, et al. PRESENT: An ultra-lightweight block cipher[C]. Proceedings of 9th International Workshop on Cryptographic Hardware and Embedded Systems, Vienna, Austria, 2007: 450–466. BANIK S, PANDEY S K, PEYRIN T, et al. GIFT: A small present[C]. Proceedings of the 19th International Conference on Cryptographic Hardware and Embedded Systems, Taipei, China, 2017: 321–345. BANIK S, BOGDANOV A, ISOBE T, et al. Midori: A block cipher for low energy[C]. Proceedings of the 21st International Conference on the Theory and Application of Cryptology and Information Security, Auckland, New Zealand, 2015: 411–436. WU Wenling and ZHANG Lei. LBlock: A lightweight block cipher[C]. Proceedings of the 9th International Conference on Applied Cryptography and Network Security, Nerja, Spain, 2011: 327–344. 国家商用密码管理办公室. 无线局域网产品使用的SMS4密码算法[EB/OL]. http://www.oscca.gov.cn/sca/c100061/201611/1002423/files/330480f731f64e1ea75138211ea0dc27.pdf, 2018.Office of State Commercial Cipher Administration. Block cipher for WLAN products-SMS4[EB/OL]. http://www.oscca.gov.cn/sca/c100061/201611/1002423/files/330480f731f64e1ea75138211ea0dc27.pdf, 2018. BEAULIEU R, TREATMAN-CLARK S, SHORS D, et al. The SIMON and SPECK lightweight block ciphers[C]. Proceedings of the 52nd ACM/EDAC/IEEE Design Automation Conference, San Francisco, USA, 2015: 1–6. AOKI K, ICHIKAWA T, KANDA M, et al. Camellia: A 128-bit block cipher suitable for multiple platforms-design and analysis[C]. Proceedings of the 7th Annual International Workshop on Selected Areas in Cryptography, Ontario, Canada, 2000: 39–56. PATIL J, BANSOD G, and KANT K S. LiCi: A new ultra-lightweight block cipher[C]. Proceedings of 2017 International Conference on Emerging Trends & Innovation in ICT, Pune, India, 2017: 40–45. KNUDSEN L R. DEAL-a 128-bit block cipher[R]. Technical Report, 1998. BIHAM E, BIRYUKOV A, and SHAMIR A. Cryptanalysis of Skipjack Reduced to 31 Rounds Using Impossible Differentials[M]. Berlin, Germany, 1999: 12–23. BIHAM E and SHAMIR A. Differential cryptanalysis of DES-like cryptosystems[C]. Proceedings of the 10th Annual International Cryptology Conference on Advances in Cryptology, 1991: 2–21. TJUAWINATA I, HUANG Tao, and WU Hongjun. Improved differential cryptanalysis on generalized feistel schemes[C]. Proceedings of the 18th International Conference on Cryptology in India, Chennai, India, 2017: 302–324. LIU Ya, GU Dawu, LIU Zhiqiang, et al. Impossible differential attacks on reduced-round LBlock[C]. Proceedings of the 8th International Conference on Information Security Practice and Experience, Hangzhou, China, 2012: 97–108. KONDO K, SASAKI Y, TODO Y, et al. Analyzing key schedule of SIMON: Iterative key differences and application to related-key impossible differentials[C]. Proceedings of the 12th International Workshop on Security, Hiroshima, Japan, 2017: 141–158. MEHRDAD A, MOAZAMI F, and SOLEIMANY H. Impossible differential cryptanalysis on Deoxys-BC-256[R]. Cryptology ePrint Archive: Report 2018/048, 2018. SHAHMIRZADI A R, AZIMI S A, SALMASIZADEH M, et al. Impossible differential cryptanalysis of reduced-round Midori64 block cipher[J]. ISeCure, 2018, 10(1): 3–14. TEZCAN C. Improbable differential attacks on Present using undisturbed bits[J]. Journal of Computational and Applied Mathematics, 2014, 259: 503–511. doi: 10.1016/j.cam.2013.06.023 -




图(3) / 表(4)
计量
- 文章访问数: 4105
- HTML全文浏览量: 1781
- PDF下载量: 129
- 被引次数: 0
 下载:
下载:
