

A Novel Joint ISAR Cross-range Scaling and Phase Autofocus Algorithm Based on Image Contrast Maximization
-
摘要:
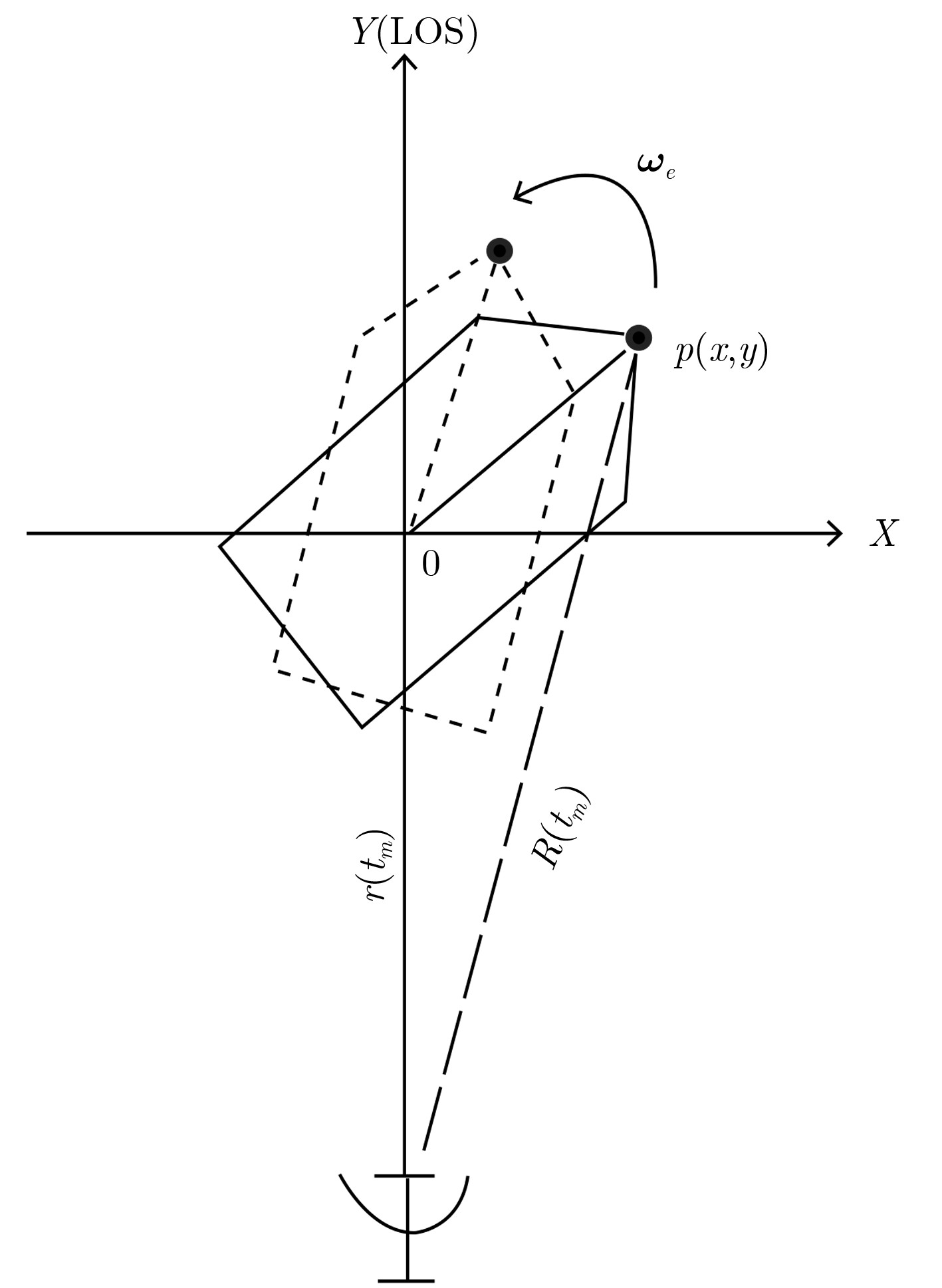
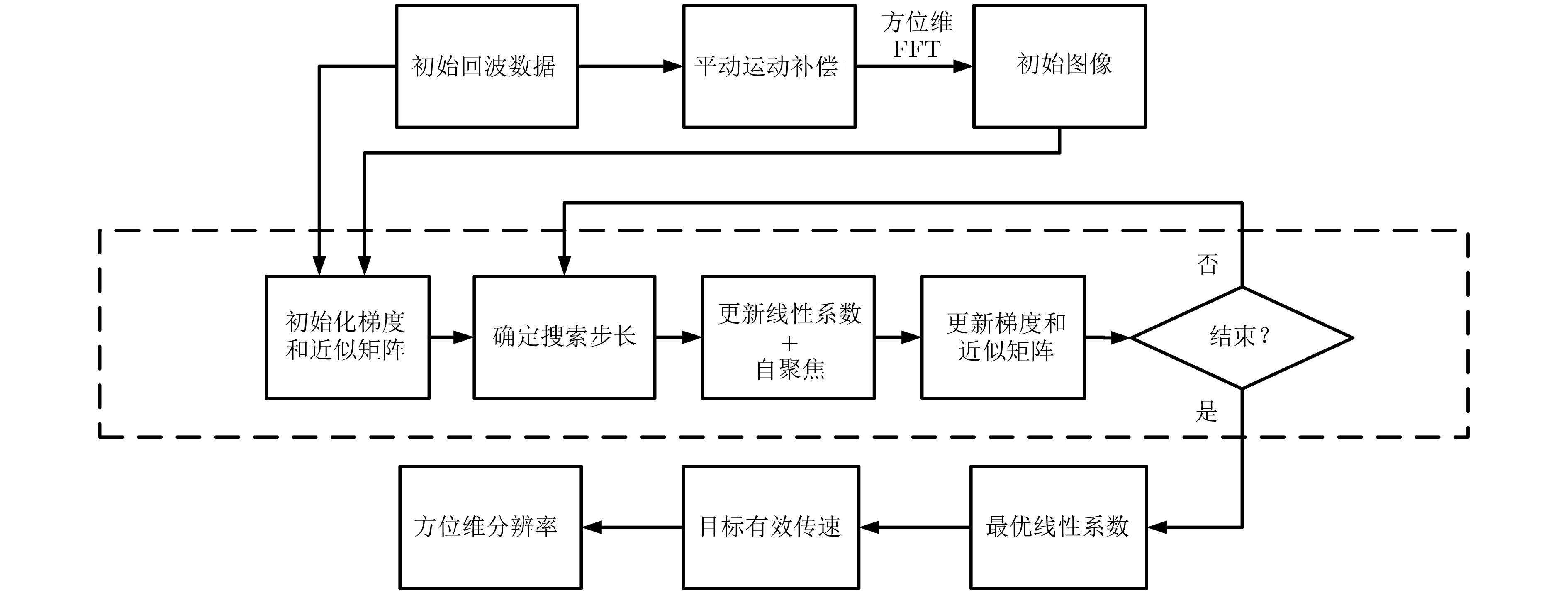
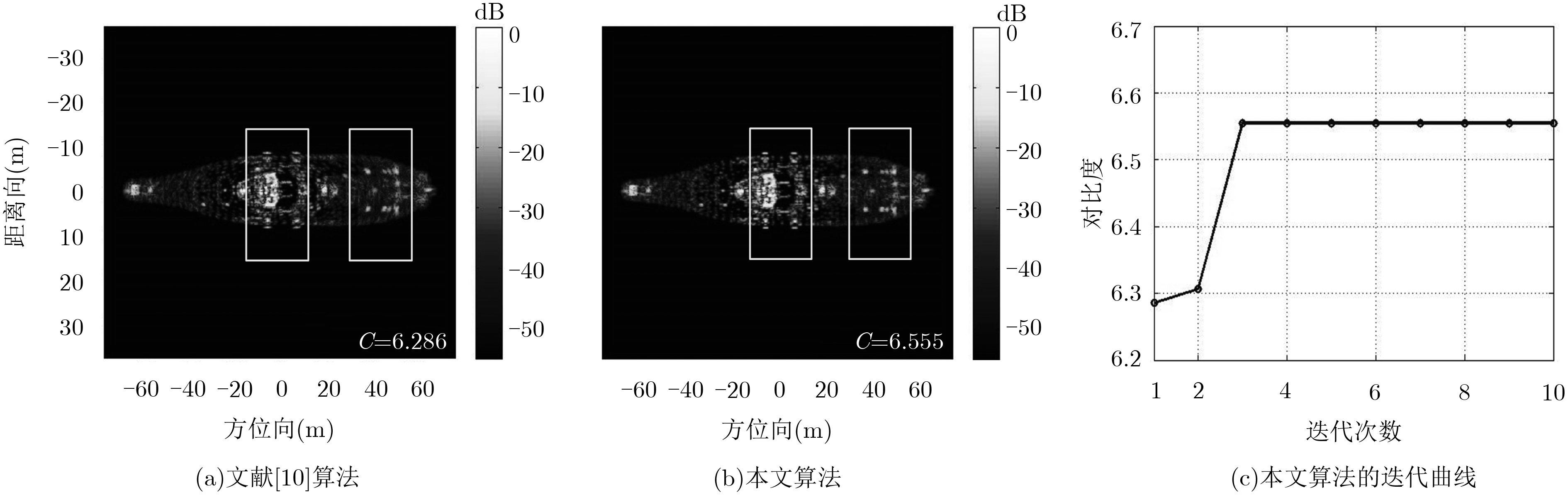
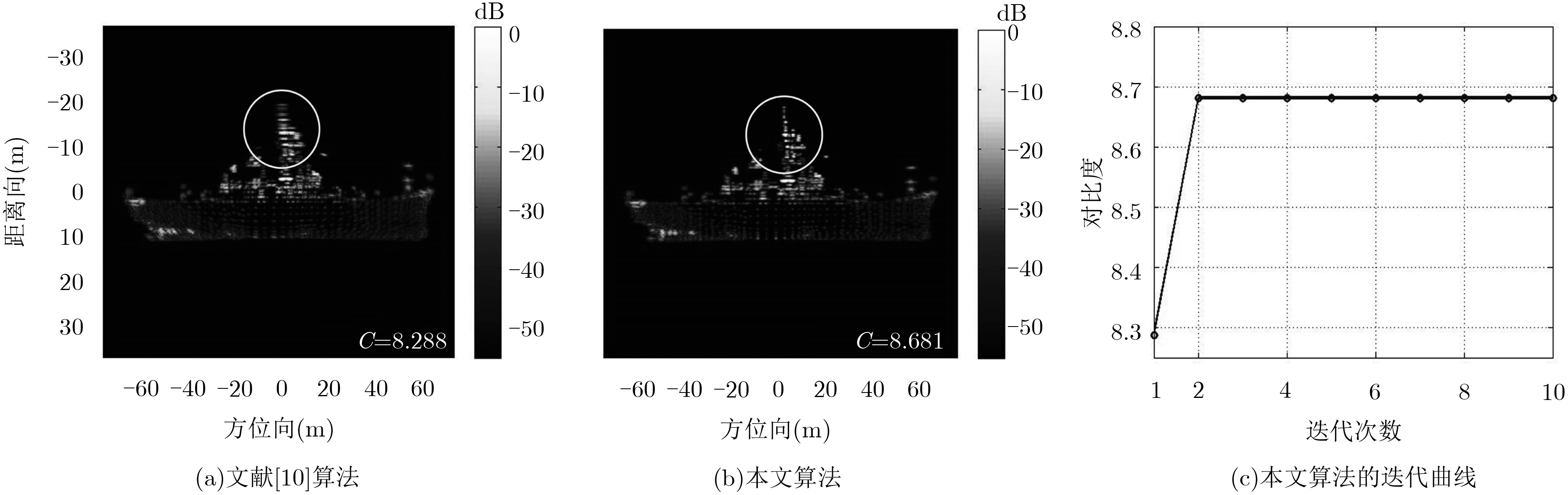
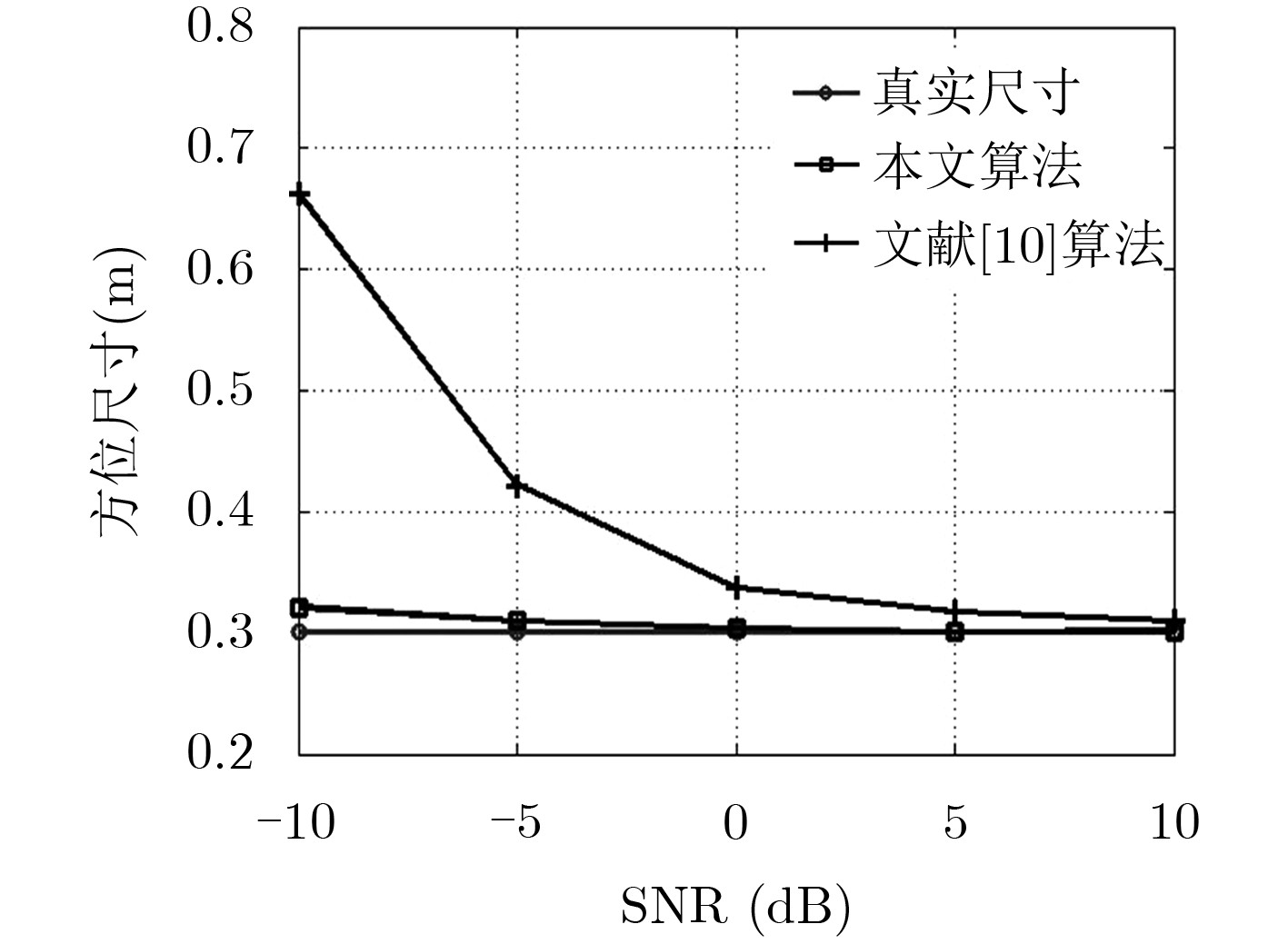
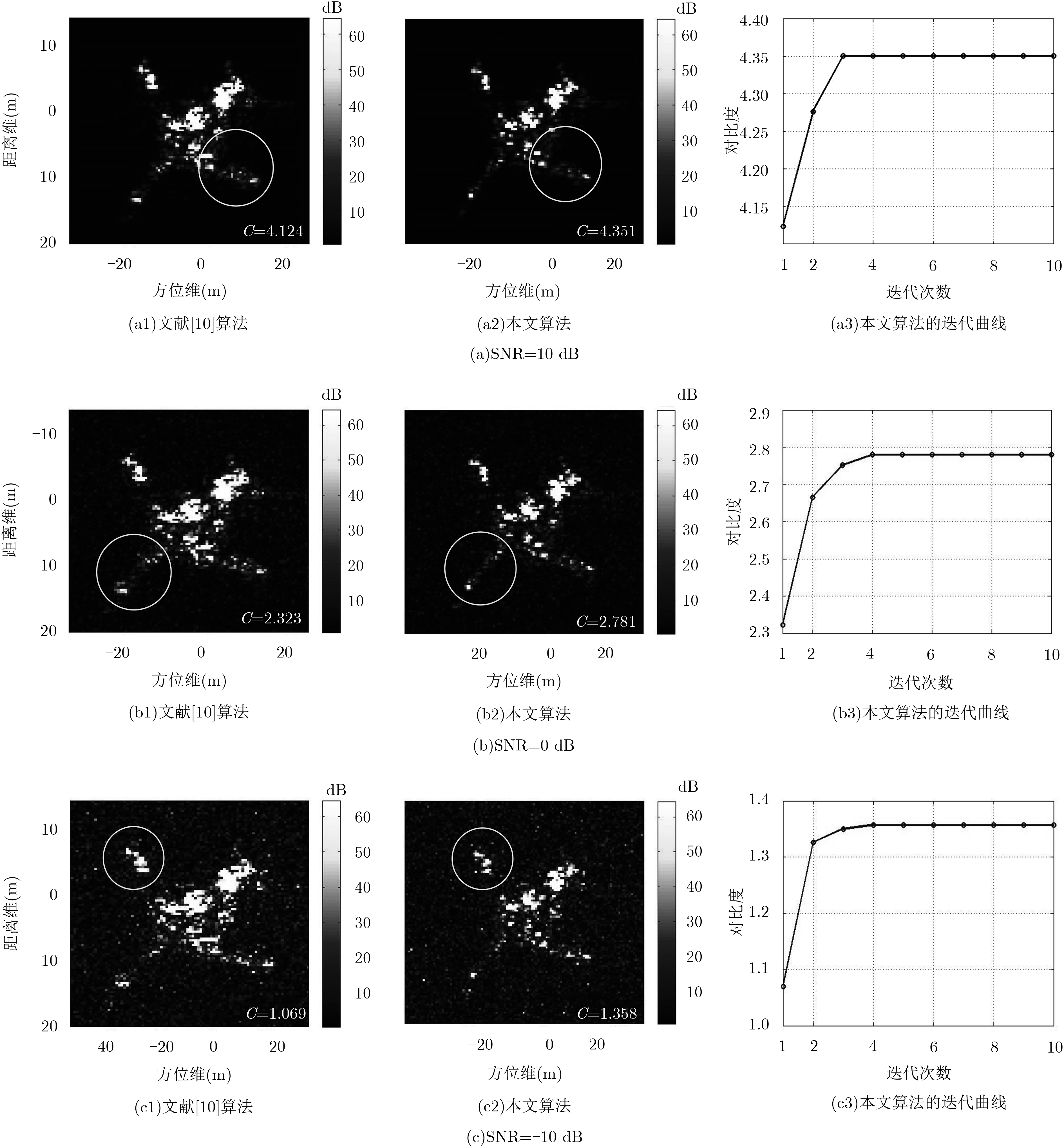
针对特显点选取易受噪声影响这一问题,该文提出一种基于全局图像最大对比度的逆合成孔径雷达(ISAR)方位定标算法,并在实现方位定标的同时完成距离空变相位补偿自聚焦。该方法以图像对比度作为代价函数,利用BFGS算法实现代价函数的最大化高效求解,获得目标信号的距离空变调频率,进而计算目标有效转动角速度,实现方位定标和距离空变相位自聚焦。仿真和实测数据实验对比验证了该算法的有效性和稳健性。
Abstract:Due to the selection of dominant scatterers is easy to be affected by noise, a novel Inverse Synthetic Aperture Radar (ISAR) cross-range scaling algorithm based on image contrast maximization is proposed, which can realize the cross-range scaling while achieving the range spatial-variant phase autofocus. With the image contrast as cost function, the cross-range chirp rate of received signal can be estimated accurately using Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm. Based on the estimated results, the cross-range scaling of ISAR image and precise phase autofocus can be implemented. Both simulated and real data experiments confirm the effectiveness and robustness of the proposed algorithm.
-
表 1 仿真参数
参数 数值 载频fc (GHz) 10 带宽B (GHz) 1 脉冲持续间隔Tp (μs) 200 脉冲重复频率PRF (Hz) 512 dechirp采样率fs (MHz) 2.56 距离维采样点数 512 方位维采样点数 512 距离维像素值(m) 0.150 方位维像素值(m) 0.3006  下载: 导出CSV
下载: 导出CSV
-
马凯莉. 基于压缩感知技术的ISAR成像方法研究[D]. [硕士论文], 南京航空航天大学, 2017.MA Kaili. Study on compressive-sensing-based ISAR imaging methods[D]. [Master dissertation], Nanjing University of Aeronautics and Astronautics, 2017. WANG Yong and ZHU Pengkai. Novel and comprehensive approach for the feature extraction and recognition method based on ISAR images of ship target[J]. Journal of Harbin Institute of Technology, 2017, 24(5): 12–19 doi: 10.11916/j.issn.1005-9113.17038 JACK L. WALKER Range-Doppler imaging of rotating objects[J]. IEEE Transactions on Aerospace and Electronic Systems, 1980, 16(1): 23–52 doi: 10.1109/TAES.1980.308875 WANG Yong, KANG Jian, and JIANG Yicheng. ISAR imaging of maneuvering target based on the local polynomial wigner distribution and integrated high-order ambiguity function for cubic phase signal model[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(7): 2971–2991 doi: 10.1109/JSTARS.2014.2301158 吕少霞. ISAR成像的横向定标算法研究[D]. [硕士论文], 哈尔滨工业大学, 2007.LÜ Shaoxia. Cross-range scaling algorithm based on ISAR imaging[D]. [Master dissertation], Harbin Institute of Technology, 2007. 张华. ISAR成像横向定标问题研究[D]. [硕士论文], 哈尔滨工业大学, 2010.ZHANG Hua. Research on cross-range scaling in ISAR imaging[D]. [Master dissertation], Harbin Institute of Technology, 2010. PASTINA D and SPINA C. Slope-based frame selection and scaling technique for ship ISAR imaging[J]. IET Signal Processing, 2008, 2(3): 265–276 doi: 10.1049/iet-spr:20070122 汪玲. 逆合成孔径雷达成像关键技术研究[D]. [博士论文], 南京航空航天大学, 2006.WANG Ling. Research on key technology of inverse synthetic aperture radar imaging[D]. [Ph.D. dissertation], Nanjing University of Aeronautics and Astronautics, 2006. WANG Ling, ZHU Daiyin, and ZHU Zhaoda. Cross-range scaling for aircraft ISAR images based on axis slope measurements[C]. IEEE Radar Conference, Rome, Italy, 2008: 1–6. doi: 10.1109/RADAR.2008.4721024. 李宁, 汪玲. 一种改进的ISAR图像方位向定标方法[J]. 雷达科学与技术, 2012, 10(1): 74–81 doi: 10.3969/j.issn.1672-2337.2012.01.014LI Ning and WANG Ling. An improved cross-range scaling method for ISAR[J]. Radar Science and Technology, 2012, 10(1): 74–81 doi: 10.3969/j.issn.1672-2337.2012.01.014 MARTORELLA M. Novel approach for ISAR image cross-range scaling[J]. IEEE Transactions on Aerospace and Electronic Systems, 2008, 44(1): 281–294 doi: 10.1109/TAES.2008.4517004 RAN Lei, LIU Zheng, ZHANG Lei, et al. An autofocus algorithm for estimating residual trajectory deviations in synthetic aperture radar[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(6): 3408–3425 doi: 10.1109/TGRS.2017.2670785 ALAGOZ B B, ALISOY H Z, KOSEOGLU M, et al. Modeling and analysis of dielectric materials by using gradient-descent optimization method[J]. International Journal of Modeling Simulation & Scientific Computing, 2017, 8(1): 3–45 doi: 10.1142/S1793962317500143 ZHANG Shuanghui, LIU Yongxiang, LI Xiang, et al. Fast ISAR cross-range scaling using modified Newton method[J]. IEEE Transactions on Aerospace and Electronic Systems, 2018, 54(3): 1355–1367 doi: 10.1109/TAES.2017.2785560 邱毅, 刘峥, 刘钦. 基于变步长搜索黄金分割优化的自聚焦算法[J]. 现代雷达, 2012, 34(4): 48–52 doi: 10.3969/j.issn.1004-7859.2012.04.011QIU Yi, LIU Zheng, and LIU Qin. A novel autofocus algorithm based on variable step searching and golden section method[J]. Modern Radar, 2012, 34(4): 48–52 doi: 10.3969/j.issn.1004-7859.2012.04.011 -



计量
- 文章访问数: 2718
- HTML全文浏览量: 1126
- PDF下载量: 122
- 被引次数: 0
 下载:
下载:
