

Co-saliency Detection Based on Convolutional Neural Network and Global Optimization
-
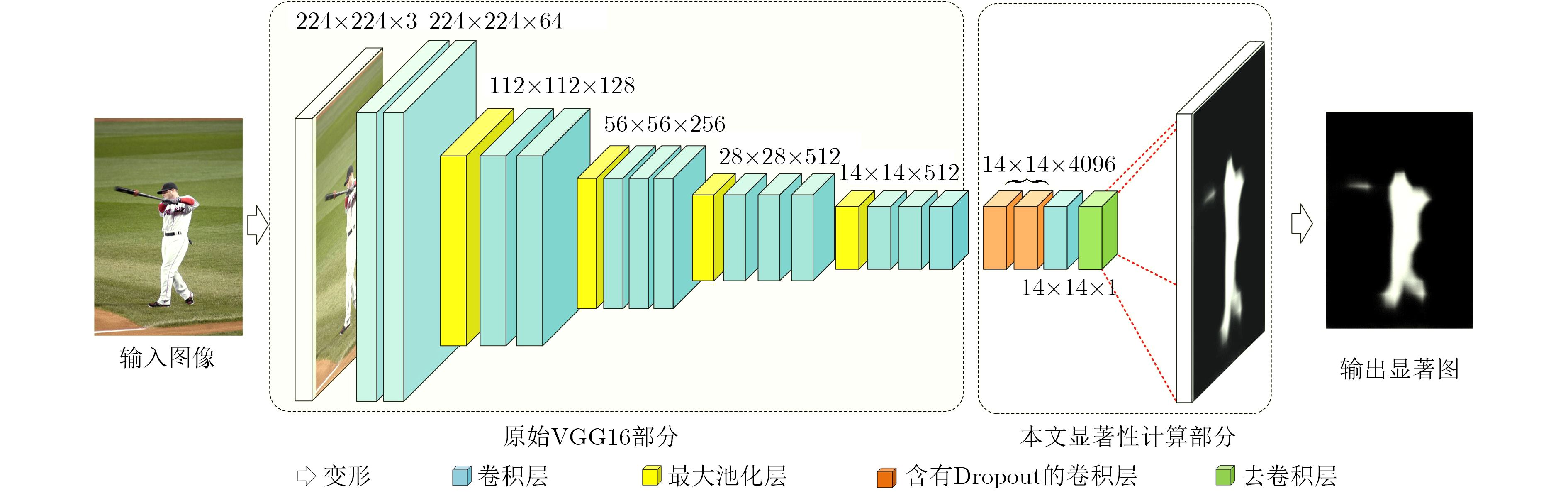
摘要: 针对目前协同显著性检测问题中存在的协同性较差、误匹配和复杂场景下检测效果不佳等问题,该文提出一种基于卷积神经网络与全局优化的协同显著性检测算法。首先基于VGG16Net构建了全卷积结构的显著性检测网络,该网络能够模拟人类视觉注意机制,从高级语义层次提取一幅图像中的显著性区域;然后在传统单幅图像显著性优化模型的基础上构造了全局协同显著性优化模型。该模型通过超像素匹配机制,实现当前超像素块显著值在图像内与图像间的传播与共享,使得优化后的显著图相对于初始显著图具有更好的协同性与一致性。最后,该文创新性地引入图像间显著性传播约束因子来克服超像素误匹配带来的影响。在公开测试数据集上的实验结果表明,所提算法在检测精度和检测效率上优于目前的主流算法,并具有较强的鲁棒性。Abstract: To solve the problems in current co-saliency detection algorithms, a novel co-saliency detection algorithm is proposed which applies fully convolution neural network and global optimization model. First, a fully convolution saliency detection network is built based on VGG16Net. The network can simulate the human visual attention mechanism and extract the saliency region in an image from the semantic level. Second, based on the traditional saliency optimization model, the global co-saliency optimization model is constructed, which realizes the transmission and sharing of the current superpixel saliency value in inter-images and intra-image through superpixel matching, making the final saliency map has better co-saliency value. Third, the inter-image saliency value propagation constraint parameter is innovatively introduced to overcome the disadvantages of superpixel mismatching. Experimental results on public test datasets show that the proposed algorithm is superior over current state-of-the-art methods in terms of detection accuracy and detection efficiency, and has strong robustness.
-
Key words:
- Co-saliency /
- Deep Learning /
- Convolutional Neural Network /
- Global Optimization
-
表 1 不同算法在两大数据库上的测试结果对比
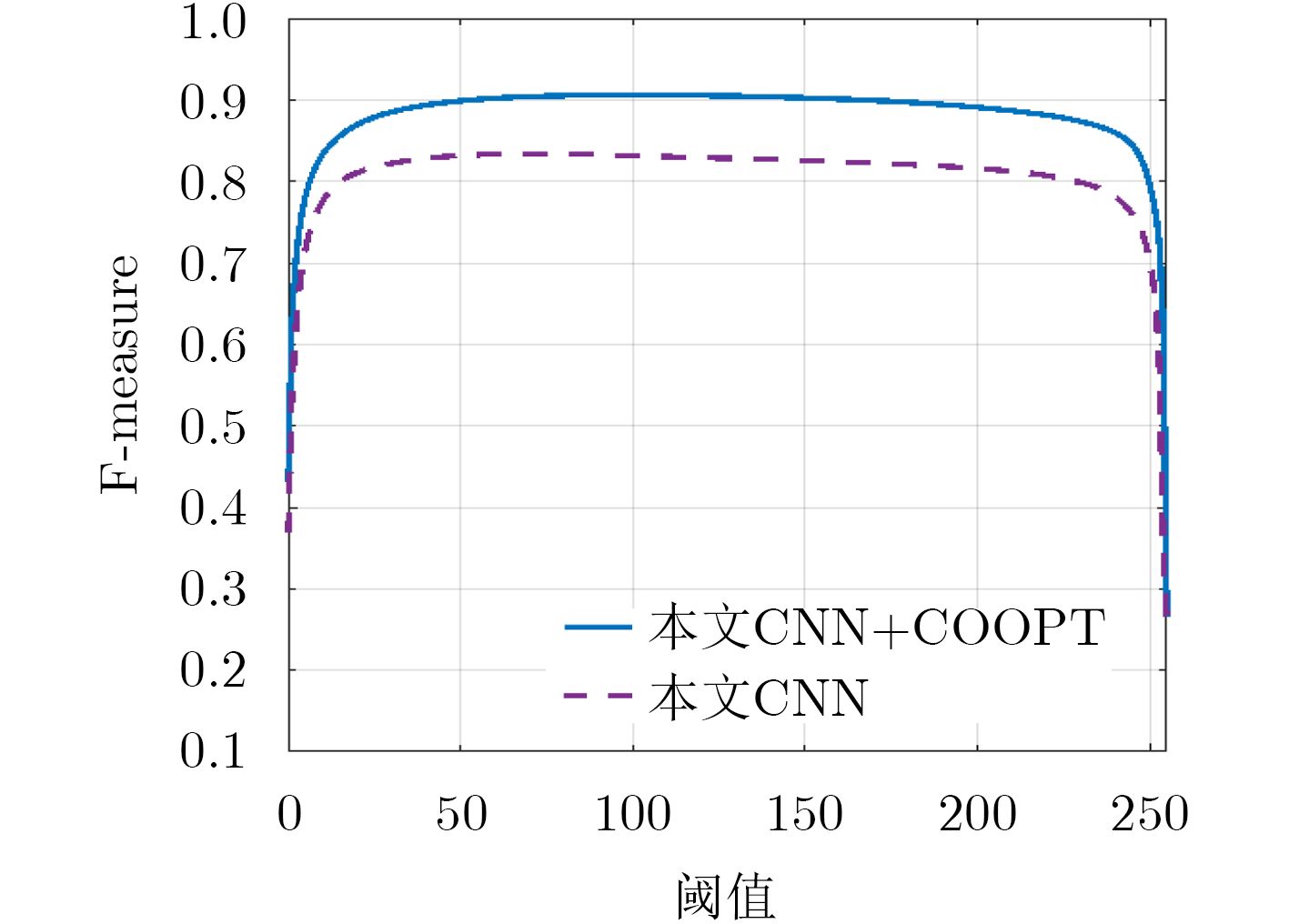
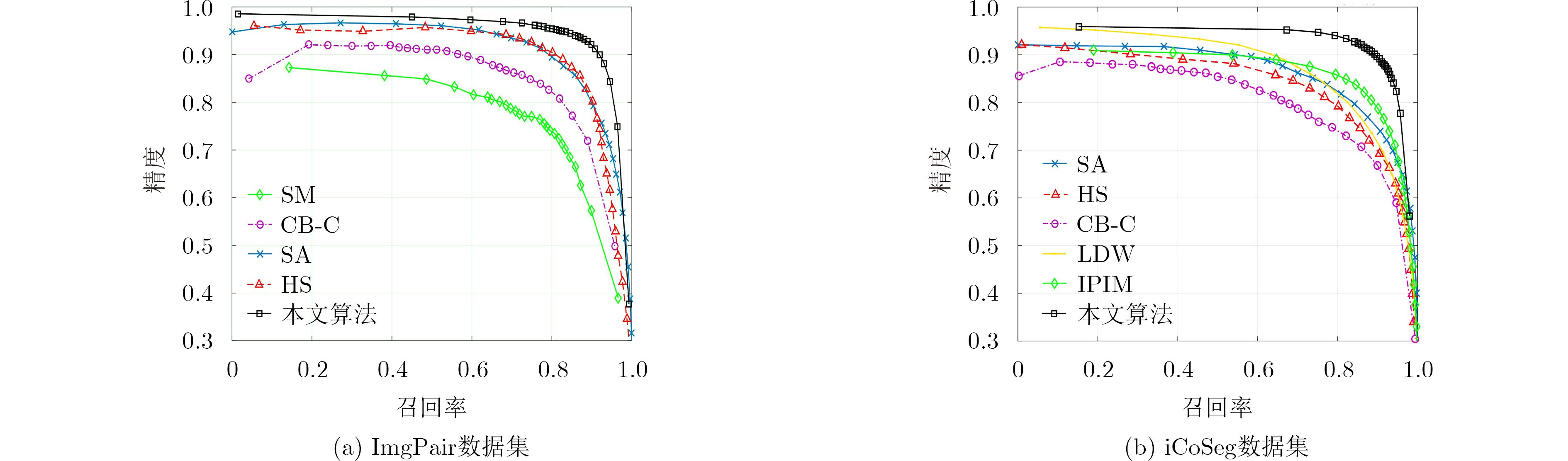
算法 ImgPair iCoSeg AUC AF MAE AUC AF MAE SA 0.967 0.826 0.160 0.965 0.720 0.160 HS 0.954 0.821 0.147 0.954 0.640 0.180 CB-C 0.931 0.782 0.178 0.913 0.647 0.198 CB-S 0.927 0.749 0.181 0.935 0.688 0.173 ACM 0.880 0.719 0.197 – – – SM 0.879 0.724 0.166 0.621 0.580 0.234 LDW – – – 0.957 0.699 0.178 IPIM – – – 0.964 0.703 0.159 本文CNN 0.958 0.811 0.098 0.932 0.761 0.081 本文CNN+COOPT 0.981 0.904 0.075 0.962 0.848 0.056  下载: 导出CSV
下载: 导出CSV
表 2 不同协同显著性算法平均运算时间比较
算法 CB-C SA SM 本文CNN 本文CNN+COOPT 时间(s) 5.40 2.10 6.60 0.12 2.70 处理器 CPU CPU CPU GPU CPU+GPU
下载: 导出CSV
-
CHANG Kaiyueh, LIU Tyngluh, and LAI Shanghong. From co-saliency to co-segmentation: An efficient and fully unsupervised energy minimization model[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado, USA, 2011: 2129–2136. JACOBS D E, DAN B G, and SHECHTMAN E. Co-saliency: Where people look when comparing images[C]. ACM Symposium on User Interface Software and Technology, New York, USA, 2010: 219–228. YE Linwei, LIU Zhi, ZHOU Xiaofeng, et al. Saliency detection via similar image retrieval[J]. IEEE Signal Processing Letters, 2016, 23(6): 838–842 doi: 10.1109/LSP.2016.2558489 YE Linwei, LIU Zhi, LI Junhao, et al. Co-saliency detection via co-salient object discovery and recovery[J]. IEEE Signal Processing Letters, 2015, 22(11): 2073–2077 doi: 10.1109/LSP.2015.2458434 LIU Zhi, ZOU Wenbin, and OLIVIER L M. Saliency tree: A novel saliency detection framework[J]. IEEE Transactions on Image Processing, 2014, 23(5): 1937–1952 doi: 10.1109/TIP.2014.2307434 REN Jingru, ZHOU Xiaofei, LIU Zhi, et al. Saliency integration driven by similar images[J]. Journal of Visual Communication and Image Representation, 2018, 50: 227–236 doi: 10.1016/j.jvcir.2017.12.002 LI Yijun, FU Keren, LIU Zhi, et al. Efficient saliency-model-guided visual co-saliency detection[J]. IEEE Signal Processing Letters, 2015, 22(5): 588–592 doi: 10.1109/LSP.2014.2364896 FU Huazhu, CAO Xiaochun, and TU Zhuowen. Cluster-based co-saliency detection[J]. IEEE Transactions on Image Processing, 2013, 22(10): 3766–3778 doi: 10.1109/TIP.2013.2260166 LIU Zhi, ZOU Wenbin, LI Lina, et al. Co-saliency detection based on hierarchical segmentation[J]. IEEE Signal Processing Letters, 2014, 21(1): 88–92 doi: 10.1109/LSP.2013.2292873 ZHANG Zhaofeng, WU Zemin, JIANG Qingzhu, et al. Co-saliency detection based on superpixel matching and cellular automata[J]. KSII Transactions on Internet and Information Systems, 2017, 11(5): 2576–2589 doi: 10.3837/tiis.2017.05.015 YANG Chuan, ZHANG Lihe, LU Huchuan, et al. Saliency detection via graph-based manifold ranking[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, USA, 2013: 3166–3173. QIN Yao, LU Huchuan, XU Yiqun, et al. Saliency detection via cellular automata[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 110–119. ZHANG Dingwen, HAN Junwei, LI Chao, et al. Co-saliency detection via looking deep and wide[C]. IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 2994–3002. ZHANG Dingwen, MENG Deyu, HAN Junwei, et al. Co-saliency detection via a self-paced multiple-instance learning framework[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(5): 865–878 doi: 10.1109/TPAMI.2016.2567393 WEI Lina, ZHAO Shanshan, BOURAHLA O E F, et al. Group-wise deep co-saliency detection[C]. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 2017: 3041–3047. SIMONYAN K, and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[OL]. Computer Science, 2014. arXiv: 1409.1556. LI Xi, ZHAO Liming, WEI Lina, et al. Deepsaliency: Multi-task deep neural network model for salient object detection[J]. IEEE Transactions on Image Processing, 2016, 25(8): 3919–3930 doi: 10.1109/TIP.2016.2579306 JIA Yangqing, SHELHAMER E, DONAHUE J, et al. Caffe: Convolutional architecture for fast feature embedding [C]. Proceedings of the ACM International Conference on Multimedia, 2014: 675–678. CHENG Mingming, ZHANG Guoxin, NILOY J, et al. Global contrast based salient region detection[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Spring, USA, 2011: 409–416. ACHANTA R, SHAJI A, SMITH K, et al. Slic superpixels compared to state-of-the-art superpixel methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2274–2282 doi: 10.1109/TPAMI.2012.120 LU Song, MAHADEVAN V, and VASCONCELOS N. Learning optimal seeds for diffusion-based salient object detection[C]. IEEE Computer Vision and Pattern Recognition (CVPR), Columbus, USA, 2014: 2790–2797. LI Hongliang and NGAN K N. A co-saliency model of image pairs[J]. IEEE Transactions on Image Processing, 2011, 20(12): 3365–3375 doi: 10.1109/TIP.2011.2156803 BATRA D, KOWDLE A, PARIKH D, et al. Interactively co-segmentating topically related images with intelligent scribble guidance[J]. International Journal of Computer Vision, 2011, 93(3): 273–292 doi: 10.1007/s11263-010-0415-x CAO Xiaochun, TAO Zhiqiang, ZHANG Bao, et al. Self-adaptively weighted co-saliency detection via rank constraint[J]. IEEE Transactions on Image Processing, 2014, 23(9): 4175–4186 doi: 10.1109/TIP.2014.2332399 ZHANG Dingwen, HAN Junwei, HAN Jungong, et al. Co-saliency detection based on intra-saliency prior transfer and deep inter-saliency mining[J]. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(6): 1163–1176 doi: 10.1109/TNNLS.2015.2495161 -

 下载:
下载:







图(8) / 表(2)
计量
- 文章访问数: 2847
- HTML全文浏览量: 993
- PDF下载量: 100
- 被引次数: 0
