

Human Action Recognition via Spatio-temporal Dual Network Flow and Visual Attention Fusion
-
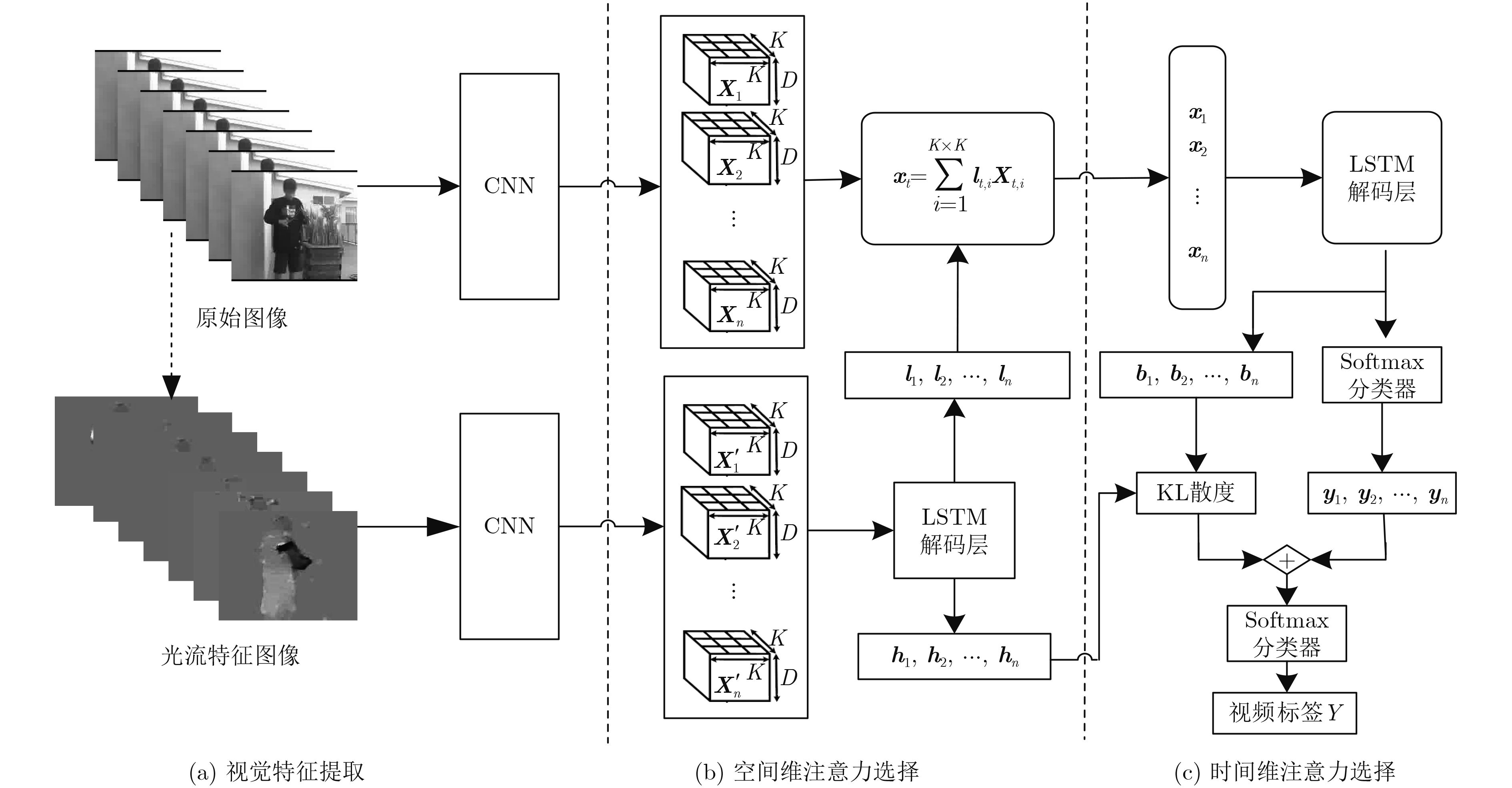
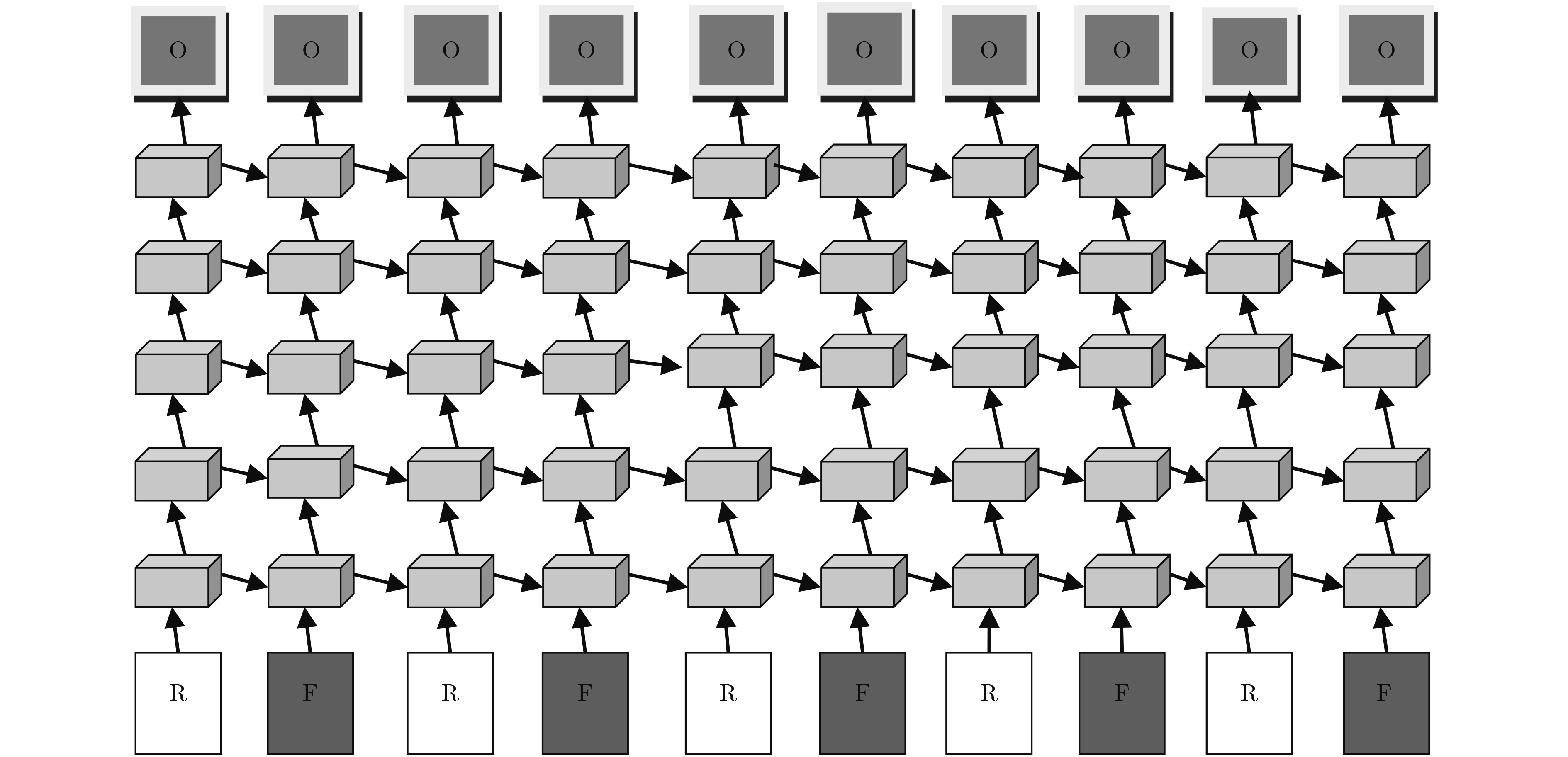
摘要: 该文受人脑视觉感知机理启发,在深度学习框架下提出融合时空双网络流和视觉注意的行为识别方法。首先,采用由粗到细Lucas-Kanade估计法逐帧提取视频中人体运动的光流特征。然后,利用预训练模型微调的GoogLeNet神经网络分别逐层卷积并聚合给定时间窗口视频中外观图像和相应光流特征。接着,利用长短时记忆多层递归网络交叉感知即得含高层显著结构的时空流语义特征序列;解码时间窗口内互相依赖的隐状态;输出空间流视觉特征描述和视频窗口中每帧标签概率分布。其次,利用相对熵计算时间维每帧注意力置信度,并融合空间网络流感知序列标签概率分布。最后,利用softmax分类视频中行为类别。实验结果表明,与其他现有方法相比,该文行为识别方法在分类准确度上具有显著优势。Abstract: Inspired by the mechanism of human brain visual perception, an action recognition approach integrating dual spatio-temporal network flow and visual attention is proposed in a deep learning framework. First, the optical flow features with body motion are extracted frame-by-frame from video with coarse-to-fine Lucas-Kanade flow estimation. Then, the GoogLeNet neural network with fine-tuned pre-trained model is applied to convoluting layer-by-layer and aggregate respectively appearance images and the related optical flow features in the selected time window. Next, the multi-layered Long Short-Term Memory (LSTM) neural networks are exploited to cross-recursively perceive the spatio-temporal semantic feature sequences with high level and significant structure. Meanwhile, the inter-dependent implicit states are decoded in the given time window, and the attention salient feature sequence is obtained from temporal stream with the visual feature descriptor in spatial stream and the label probability of each frame. Then, the temporal attention confidence for each frame with respect to human actions is calculated with the relative entropy measure and fused with the probability distributions with respect to the action categories from the given spatial perception network stream in the video sequence. Finally, the softmax classifier is exploited to identify the category of human action in the given video sequence. Experimental results show that this presented approach has significant advantages in classification accuracy compared with other methods.
-
表 1 本文方法在不同子模型组合下平均准确度和模型测试用时性能比较
子模型
组合1+3 2+3 1+2+3 1+2+3
+41+2+3
+51+2+3
+4+5平均准确度(%) 76.1 72.9 82.0 83.2 85.5 87.5 测试时间(s) 129 130 130 132 132 133 注:数字含义:1为原始图像,2为光流特征,3为CNN+LSTM模型,4为空间注意力,5为时间注意力  下载: 导出CSV
下载: 导出CSV
-
IKIZLER-CINBIS N and SCLAROFF S, Object, scene and actions: Combining multiple features for human action recognition[C]. European Conference on Computer Vision, Heraklion, Crete, Greece, 2010, 6311: 494–507. WANG Heng, KLASER A, and SCHMID C. Action recognition by dense trajectories[C]. IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2011: 3169–3176. 张良, 鲁梦梦, 姜华. 局部分布信息增强的视觉单词描述与动作识别[J]. 电子与信息学报, 2016, 38(3): 549–556 doi: 10.11999/JEIT150410ZHANG Liang, LU Mengmeng, and JIANG Hua. An improved scheme of visual words description and action recognition using local enhanced distribution information[J]. Journal of Electronics&Information Technology, 2016, 38(3): 549–556 doi: 10.11999/JEIT150410 SHARMA S, KIROS R and SALAKHUTDINOV R. Action recognition using visual attention[C]. International Conference on Neural Information Processing Systems Times Series Workshop, Montreal, Canada, 2015: 1–11. SCHMIDHUBER J. Deep learning in neural networks: An overview[J]. Neural Networks, 2015, 61: 85–1117 doi: 10.1016/j.neunet.2014.09.003 RENSINK R A. The dynamic representation of scenes[J]. Visual Cognition, 2000, 1(1/3): 17–42. XU Kelvin, BA Jimmy, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]. Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 2015, 14: 77–81. BAHDANAU D, CHO K, and BENGIO Y. Neural machine translation by jointly learning to align and translate[C]. International Conference on Learning Representation, San Diego, USA, 2015: 1–15. MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2204–2212. BA Jimmy Lei, GROSSE R, SALAKHUTDINOV R, et al. Learning wake-sleep recurrent attention models[C]. International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 2593–2601. AND J S P. Horn-Schunck optical flow with a multi-scale strategy[J]. Image Processing on Line, 2013, 20: 151–172 doi: 10.5201/ipol.2013.20 RUSSAKOVSKY O, DENG Jia, SU Hao, et al. ImageNet: Large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211–252. SZEGEDY Christian, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]. IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. ANDREJ K, JUSTIN J, and LI Feifei. Visualizing and understanding recurrent networks[C]. International Conference on Learning Representation Workshop, Caribe Hilton, USA, 2016: 1–11. GOLDBERGER J, GORDON S, and GREENSPAN H. An efficient image similarity measure based on approximations of KL-divergence between two gaussian mixtures[C]. IEEE International Conference on Computer Vision, Nice, France, 2003: 487–493. SRIVASTAVA N, HINTON G E, KRIZHEVSKY A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15: 1929–1958. KINGMA D P and BA J. Adam: A method for stochastic optimization[C]. International Conference on Learning Representation, San Diego, USA, 2015: 1–15. -

 下载:
下载:



图(3) / 表(2)
计量
- 文章访问数: 2574
- HTML全文浏览量: 1283
- PDF下载量: 103
- 被引次数: 0
