

脏纸编码的多用户MIMO-OFDM系统中基于纳什公平的资源分配算法
doi: 10.3724/SP.J.1146.2007.00969
Nash Fairness Based Resource Allocation Algorithm for Dirty-Paper Coded Multi-user MIMO-OFDM Systems
-
摘要: MIMO-OFDM技术是实现大容量无线数据传输的一项关键技术。多用户系统中,在最大化系统资源利用率的同时保证用户间资源分配的公平性是系统设计的一个重要问题。该文首先分析了MIMO系统中最大化吞吐量的一种实现方式脏纸编码(DPC),然后基于纳什公平性准则提出了一种用于DPC的多用户MIMO-OFDM系统中的自适应资源分配算法。仿真结果表明,该算法在损失较小系统吞吐量的前提下,很好地保证了用户间资源分配的公平性。
-
关键词:
- 通信与信息系统 /
- 动态资源分配 /
- 纳什公平 /
- 多输入多输出/正交频分复用 /
- 脏纸编码
Abstract: MIMO-OFDM has been one of the most promising techniques for high data rate wireless transmission. In multi-user systems, how to guarantee the fairness among users while achieving large system throughput is an important issue for practical system design. In this paper, the Dirty-Paper Coding (DPC) as a new transmission technique is investigated to achieve the large throughput of MIMO systems, and a novel resource allocation algorithm based on Nash fairness is proposed for dirty-paper coded multi-user MIMO-OFDM systems. Simulation results show that the proposed algorithm can provide fair resource allocation among users, with less overall system rate loss. -
1. 引言
极光(aurora)是由太阳带电粒子流在极区电离层发生物理电离作用时呈现出的自然发光现象。极光形态特征变化与日地间电磁活动有着内在联系,这对太阳地球间的影响规律和太阳风暴等研究奠定了基础,因此极光图像的分类和检索成为日地物理学研究的重要途径。而面对这些海量极光数据,若通过手工选择或传统的基于SIFT的方法来进行极光图像的分类与检索效果不佳,所以如何有效合理利用这些重要数据已成为极光研究人员急需解决的问题。
一直以来研究人员都在进行着极光方面的研究,图像分类研究主要有文献[1]提出基于局部二值模式和分块化融合思想的极光图像分类方法;文献[2]提出基于融合显著性信息的文档主题生成模型对极光图像进行分类。检索研究主要有文献[3]提出利用极光的形状特征的极光图像检索方法;文献[4]将全局特征和局部特征融合实现极光图像检索;文献[5]利用CNN提取多尺度特征,并针对极光结构设计极区划分方案实现极光图像检索。以上方法大都采用传统的特征提取方法,对于极光图像特征的表征不够全面,存在性能不是很好、检索耗时长、存储开销大等问题。
近年来得益于深度学习在图像处理方面的应用[6],使得人们开始不断地对新的应用场景进行思考和尝试,深度哈希算法就是研究者们提出的一种新的探索。深度哈希算法利用CNN提取的高层语义特征代替传统哈希算法使用手工特征来进行哈希编码,不仅有效避免了“语义鸿沟”问题,还提高了检索性能。文献[7]提出通过构造相似矩阵的深度哈希算法CNNH;文献[8]提出基于图像标签对来设计损失函数的DPSH算法;文献[9]提出基于图像对间的相似度的DSH算法。上述算法对图像检索的性能都有一定程度上的改善,但CNNH算法的特征提取和哈希学习是分割开的,在训练过程中不能相互反馈;而DPSH和DSH算法都是基于图像对的相似信息来训练网络,标签信息没有全部发挥作用。
基于上述分析,本文结合CNN和哈希编码的优势,提出一种基于深度哈希算法的极光图像分类与检索方法,该算法的主要特点有:
(1) 在CNN之间加入哈希层实现了数据降维,还减少直接利用高维特征向量检索耗时、存储空间大的缺点,同时还将哈希学习和特征提取融合到同一个框架中,实现一种端到端的极光图像分类与检索算法;
(2) 多尺度特征融合,将空间金字塔池化(Spatial Pyramid Pooling, SPP)和幂均值变换(Power Mean Transformation, PMT)嵌入到CNN中,SPP不仅可以解决CNN结构对输入尺寸的限制而导致信息损耗的问题,还能对多个不同区域的特征信息融合,同时加入PMT,利用数学函数引入非线性变换,使得模型可以从数据中学习到更复杂的关系;
(3) 引入多任务学习机制,充分利用样本图像的标签信息和图像对之间的相似度信息来进行模型的训练,将哈希层的损失作为优化目标之一来保持二值哈希码之间良好的语义相似性。
2. 基于深度哈希算法的极光图像分类与检索
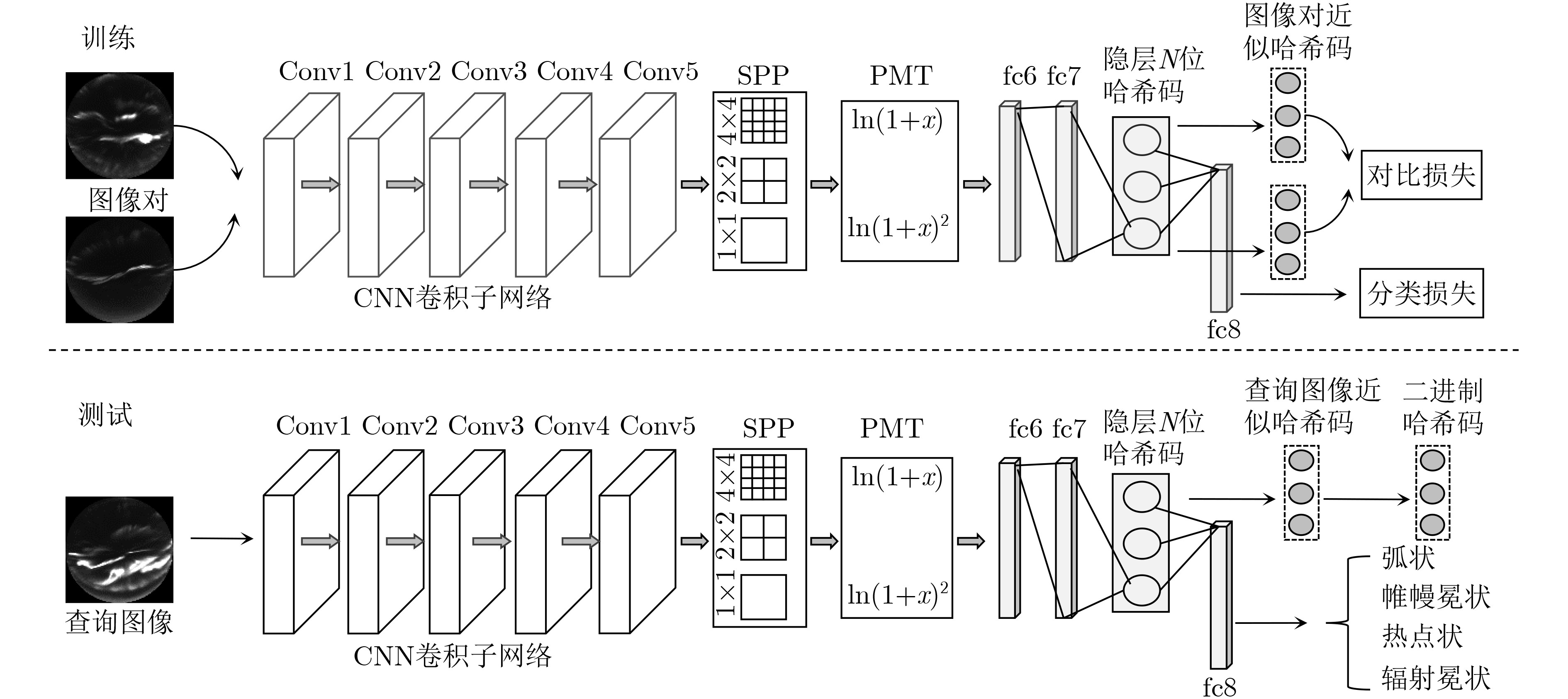
本文方法的框架如图1所示,上下两部分分别为训练网络和测试网络。
其中训练网络主要由3部分组成:(1)CNN卷积子网络;(2)空间金字塔池化(SPP)和幂均值变换(PMT); (3)损失函数。由于要用到图像之间的相似度信息,因此网络的输入层要求以图像对的形式输入。首先图像对经CNN卷积子网络提取局部特征;然后,最后一个卷积层输出若干特征图经过SPP和PMT融合图像多尺度的区域特征;接着将多尺度特征送入全连接层,哈希层中使用激活函数Sigmoid将输出的编码值映射到[0,1]区间,分别计算分类损失、对比损失,并反向传播进行模型训练。测试网络基本上与训练网络相同,只需去掉损失函数部分。
2.1 CNN卷积子网络
CNN卷积子网络用来提取图像的特征,本文采用AlexNet[10]作为基本网络结构,为了获得更有效的特征,将池化层pool3替换为SPP并加入PMT。其中Conv1-Conv5为AlexNet中结构,SPP的参数是金字塔的高度为3和池化方式为MaxPooling。
为了提高性能以及减少模型参数、加快训练速度,本文对AlexNet卷积子网络进行改进(用改进的 AlexNet表示,记为Im-AlexNet)。经过大量网络结构的调整实验,主要从以下几点改进:
(1) Conv1 的卷积核由 11×11 改为 5×5。采用较小的卷积核网络可以提取更加细致、深层次的图像特征,进而提高性能,同时可以减少网络参数;
(2) Conv2-Conv5 每层前加入1层 1×1 卷积,并且其后加 ReLU 激活函数。1×1 卷积为2次提取图像特征,可以更好地表征图像信息;加深网络的同时实现通道的信息整合,同时ReLU激活函数可以加快训练速度,增加网络的非线性特性,增强数据拟合准确性;
(3) 全连接层fc6和fc7节点数由4096改为1024,可以很大程度上减少网络参数,加快模型训练速度。经过对AlexNet网络结构进行改进,在泛化性、模型训练速度以及整体的鲁棒性等方面有所提高。
2.2 空间金字塔池化(SPP)和幂均值变换(PMT)
2.2.1 空间金字塔池化
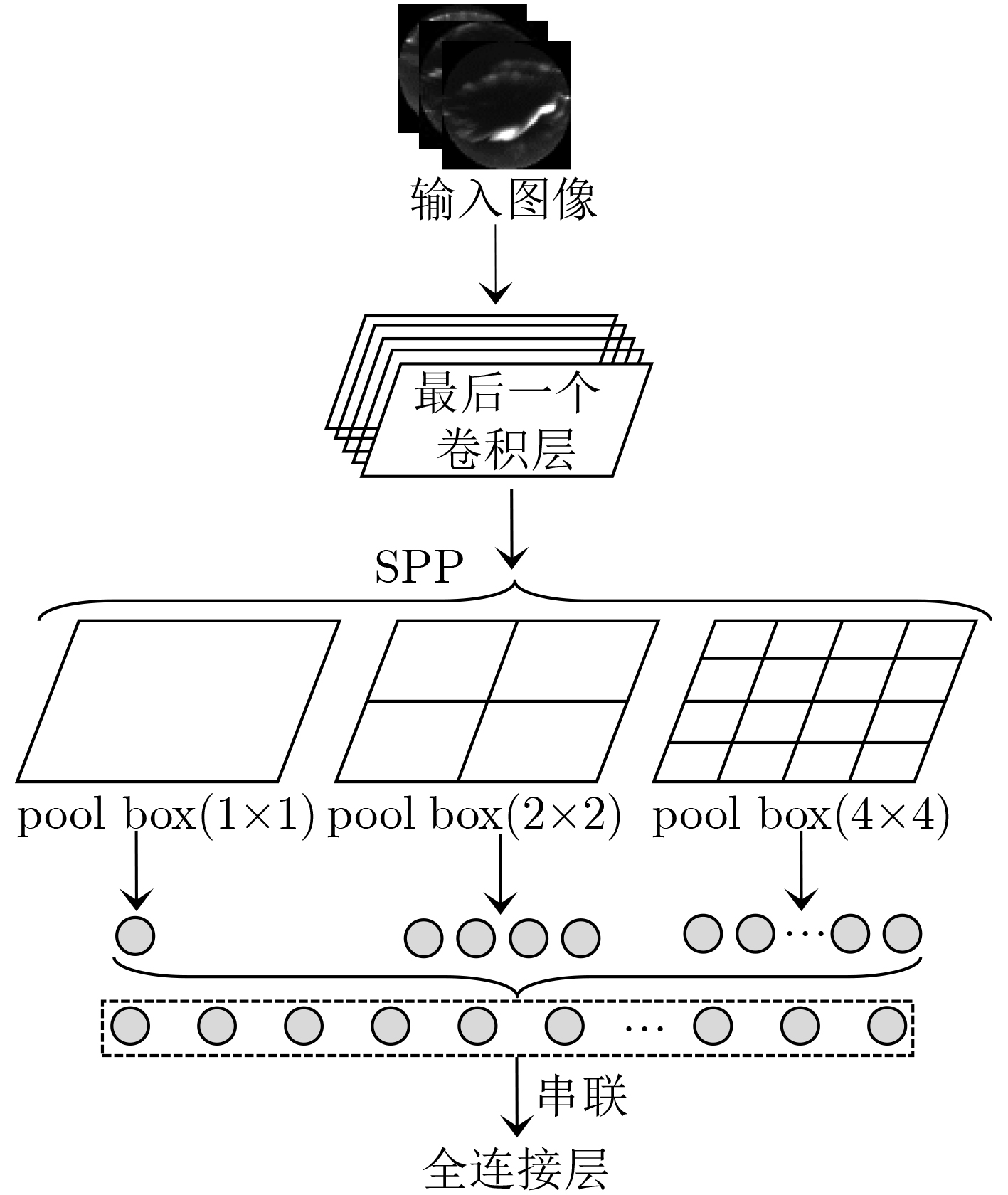
空间金字塔池化(SPP)[11]采用了多尺度分块的方法,通过使用多个不同大小的池化操作保证固定的特征向量输出,进而提升网络输入自适应能力,实现不同尺寸的输入,其中选择大小分别为 4×4, 2×2, 1×1的池化框。SPP可以对最后一个卷积层输出的每一个特征图进行不同尺度的特征提取,最后生成融合多个区域信息的多尺度特征[12],同时避免了CNN对输入图像尺寸的限制而造成极光图像经过裁剪、缩放等操作丢失部分重要信息。图2为空间金字塔池化示意图。
SPP的原理如图2所示:
(1) 首先是输入层,其大小可以是任意尺寸,输入图像经过CNN卷积子网络进行卷积运算,到最后一个卷积层输出若干个特征图;
(2) 然后进入SPP层,从左往右3个格子表示池化框大小分别为 1×1, 2×2, 4×4,先看第3个格子,假设最后一个卷积层的输出为512个7×7的特征图,则将其分成16×256份,其他两个池化框同理,即将特征图分别分成4×256份和1×256份;
(3) 将特征图分成若干等份后分别进行池化操作,一般选择Max Pooling,这样最后一个卷积层得到的特征图通过SPP层后被转化成了16×256+4×256+1×256 = 21×256的矩阵,在送入全连接层时扩展成1维矩阵,即1×5376,所以第1个全连接层的节点数就设置成5376。
2.2.2 幂均值变换
在传统的CNN模型中非线性变换主要来源于激活函数和池化层。为了增加和多样化网络中的非线性变换,在SPP层和之后的全连接层之间引入幂均值变换(PMT)[13],文献[13]验证了引入PMT增加模型非线性的多样性能够有效地提高模型的性能。PMT的原理是给定一个输入
x ,x 为图像特征向量。PMT将x 转换为ln(x+b),ln2(x+b) ,其中b 是参数矩阵。在前向传递时,使∂l/∂y 等于PMT输出的梯度值,其中l为x 经过PMT后的输出值。因为y=[ln(x+b),ln2(x+b)] ,由链式法则得到∂l∂y=∂l∂[ln(x+b),ln2(x+b)] (1) ∂l∂xT=∂l∂yT∂y∂xT=∂l∂(ln(x+b))Tln(x+b)∂xT+∂l∂(ln2(x+b))Tln2(x+b)∂xT (2) 有了前向和反向传播公式,PMT就比较容易集成到CNN模型中,并使用现有的优化器进行端到端的训练,从而可以从数据中学习到更复杂的信息,有利于提取全面准确的特征。
2.3 二进制哈希码的生成
CNN的卷积层提取的是局部特征,而全连接层提取的是能够很好表征输入图像的高层语义信息。AlexNet的fc7层最能表现图像的高层语义信息,但fc7层提取的特征是一个4096维向量,直接用来做相似性计算时面临着计算耗时、占用大量存储空间的问题。
哈希算法作为当前主流的数据降维方法之一,主要目的是将任意长度的输入投影成一串固定长度的二进制哈希码,并且利用汉明距离来度量二值编码之间的相似性,使得不同哈希码能保持图像之间的语义相似性。本文在AlexNet的fc7和fc8层之间加入哈希层,使得fc7层学习到的高维语义特征映射为哈希码,这样哈希码中也包含了图像的语义信息,可以明显提高图像检索的效果。
如图1中测试网络所示,查询图像输入测试网络,会依次通过CNN卷积子网络、SPP_MPT层、全连接层以及哈希层,提取哈希层中Sigmoid输出的值,记为
P(i) ,阈值设定为 0.5,把[0, 1]之间的输出值通过Hi 转换为二进制哈希码用来检索。本文检索使用的哈希码长度为N ,对于i=1,2,···,N ,每一位哈希码为Hi={1,P(i)≥0.50,其他 (3) 2.4 损失函数设计
多任务学习MTL(Multi-Task Learning)就是利用额外的信息来提升各个任务的学习性能而提出的一种机制。本文在设计损失函数时充分利用极光图像的标签信息和图像对之间的相似性信息,避免图像标签信息的浪费,同时将哈希层的损失作为优化目标之一,能够进一步保持二值哈希码之间的语义相似性。本文方法的损失函数表示为
Lt=μLcel+λLcl (4) 式中
Lcel 和Lcl 分别表示交叉熵损失函数(CrossEntropyLoss)和对比损失函数(ContrasiveLoss), μ和λ为权重因子。式(4)符号右侧第1部分为交叉熵损失函数。分类损失层以每一个图像预测的类别概率以及其真实标签作为输入,用来衡量样本预测类别与真实标签之间的相似度。交叉熵损失函数的公式为
Lcel=−1n∑x[ylny∗+(1−y)ln(1−y∗)] (5) 其中
x 表示样本,n 表示样本的总数,y 为期望的输出,y∗ 为神经元的实际输出。式(4)符号右侧第2部分为对比损失函数。假设有
N 对训练样本(Ii,1,Ii,2) ,i=1,2,···,N ,yi 衡量样本对之间的相似度(yi 等于0表示相似,yi 等于 1表示不相似),则优化目标是尽量减小相似样本间的距离并拉大不相似样本间的距离,即Lcl=N∑i=1{12(1−yi)∥bi,1−bi,2∥22+12yimax(m−∥bi,1−bi,2∥22,0)} (6) 其中,
bi,1 和bi,2 表示图像对由哈希层输出的近似哈希码,用欧式距离来进行优化;边界参数m > 0;前一项是衡量相似图像对应的近似哈希码之间所存在的距离而计算出损失;后一项表示在图像对不相似的情况下,如果对应的近似哈希码之间的距离小于m 的值就会产生损失。3. 实验结果与分析
3.1 数据集与性能评价
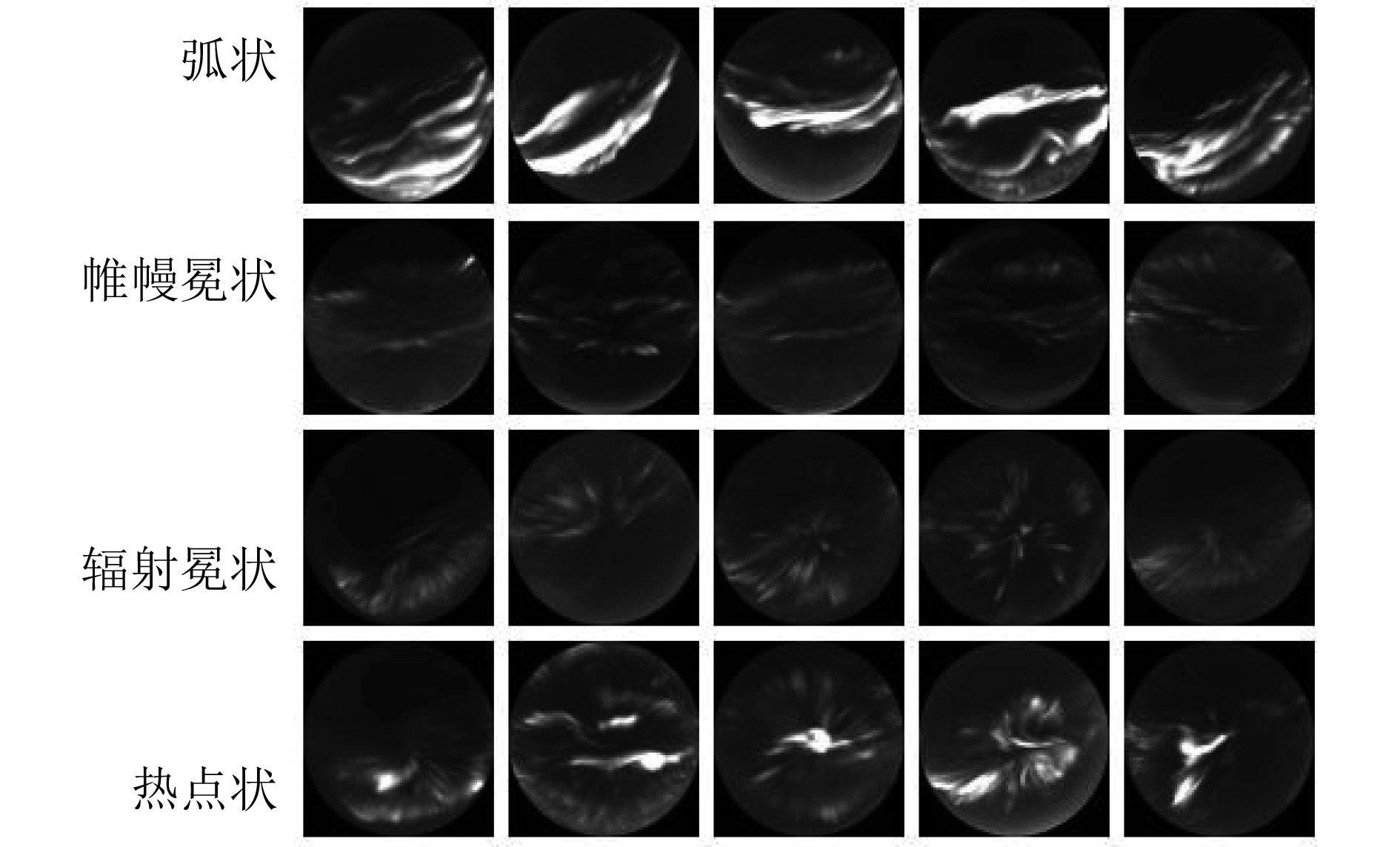
为了验证本文方法的有效性,在极光图像数据集和公共数据集 CIFAR-10上分别进行评估。本文使用的极光图像数据集,来自中国极地科考站北极黄河站的极光观测数据,总共有8001幅极光图像,其中包含3934幅弧状极光(arc)、1786幅帷幔冕状极光(drapery)、1497幅辐射冕状极光(radial)和784幅热点状极光(hot-spot)。如图3所示为4类极光类型图像。CIFAR-10数据集包含有 60000 张大小为 32×32 的图像,总共有 10 个类别,每个类别有 6000 张图像,包括50000 张训练集和 10000 张测试集。
本文图像检索的性能评价采用Top-k 检索返回的准确率曲线、MAP和查准率-查全率(Precision-Recall, P-R)曲线3项指标。Top-k 检索返回的准确率曲线是衡量检索返回的与查询图像二值哈希码汉明距离最小的前
K 张图像中相似图像所占的比例。P-R 曲线是指按照汉明距离从小到大的排序,所有测试图像的平均查全率和平均查准率的曲线图。MAP是指P-R 曲线所包围的面积。图像分类的性能评价指标是平均准确率(Accuracy)和4分类归一化混淆矩阵。
3.2 实验结果与分析
3.2.1 极光数据集上的实验
首先分别验证加入哈希层损失和SPP_PMT层的有效性。实验中使用48位哈希码来进行说明,CNN卷积子网络使用AlexNet的前5个卷积层。表1是考虑哈希层损失(同时使用对比损失和交叉熵损失)与不考虑哈希层损失(只使用交叉熵损失)两种情况下的MAP值和准确率的对比结果。表2表示有无SPP_PMT层两种情况(都加入哈希层损失)下的MAP值和准确率的对比结果。
表 1 有无哈希层损失两种方法对比方法 MAP 准确率 不考虑哈希层损失 0.7563 0.8705 考虑哈希层损失 0.8554 0.9073 表 2 有无SPP_PMT层两种方法对比方法 MAP 准确率 不加SPP_PMT 0.8554 0.9073 加入SPP_PMT 0.8963 0.9367 从表1可以看出在哈希层中引入损失作为优化目标之一使得二进制哈希码之间保持良好的语义相似性,MAP值和准确率分别提高了9.91%和3.68%,说明联合哈希损失和分类损失可以充分利用图像的标签信息和图像对之间的相似性信息,效果有一定的提升,从而验证了哈希损失的有效性。
从表2可以看出在CNN中嵌入了SPP和PMT,可以提取到多尺度的特征,使得网络可以从图像中捕获更复杂的关系。MAP值和准确率分别提高了4.09%和2.94%,验证了SPP_PMT的有效性。
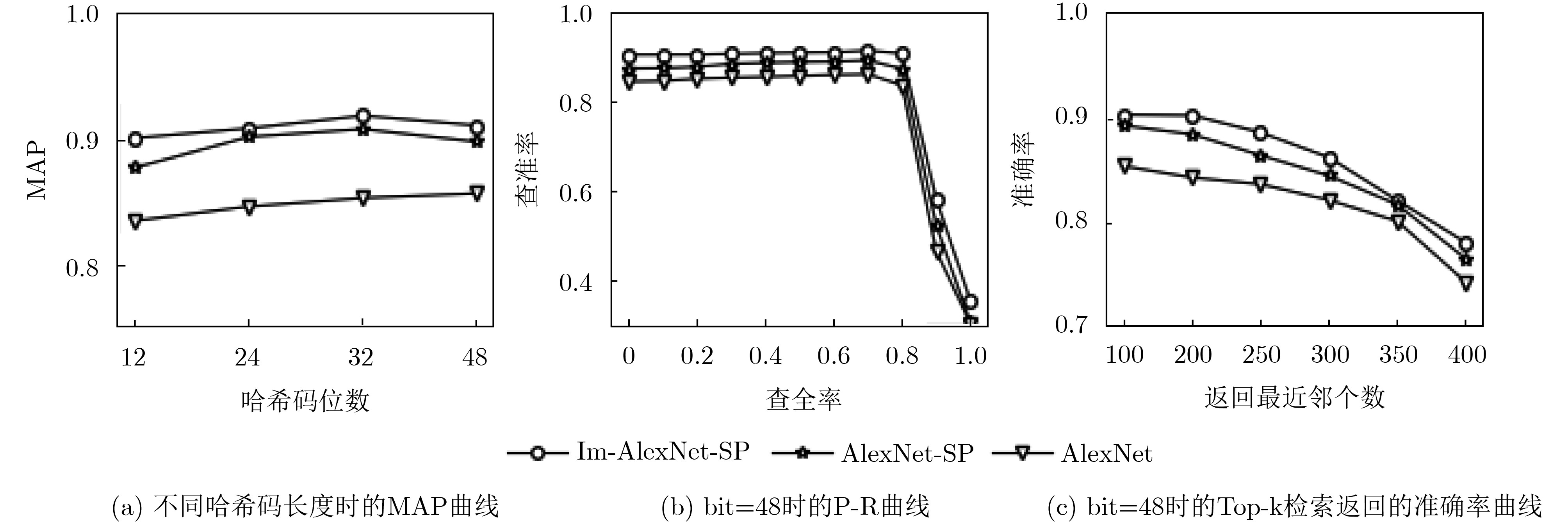
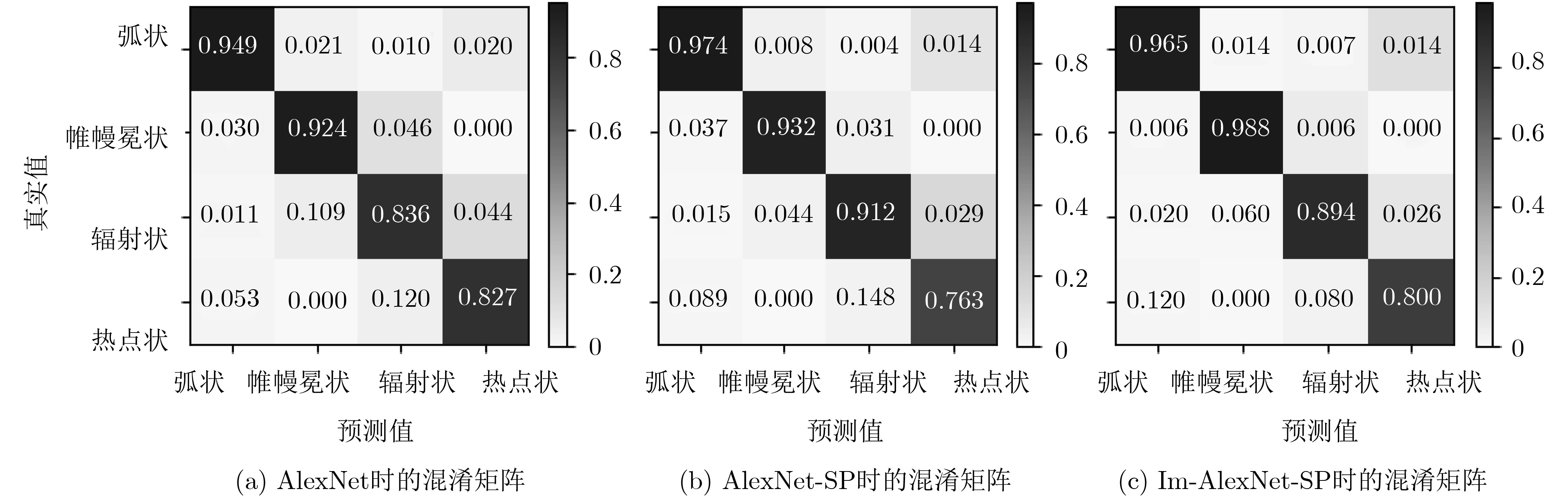
然后分别用AlexNet, AlexNet-SP(使用AlexNet并加入SPP_PMT)和Im-AlexNet-SP(使用Im-AlexNet并加入SPP_PMT)3种方法进行对比。都考虑了哈希层损失,并设置不同的哈希码长度(bit)。表3为不同哈希码长度下的MAP以及模型参数大小和训练时间对比。图4为MAP, P-R以及Top-k检索返回的准确率曲线。表4为在不同哈希码长度下的分类准确率。图5从左到右分别为AlexNet, AlexNet-SP和Im-AlexNet-SP在bit=48哈希码下的4分类混淆矩阵。
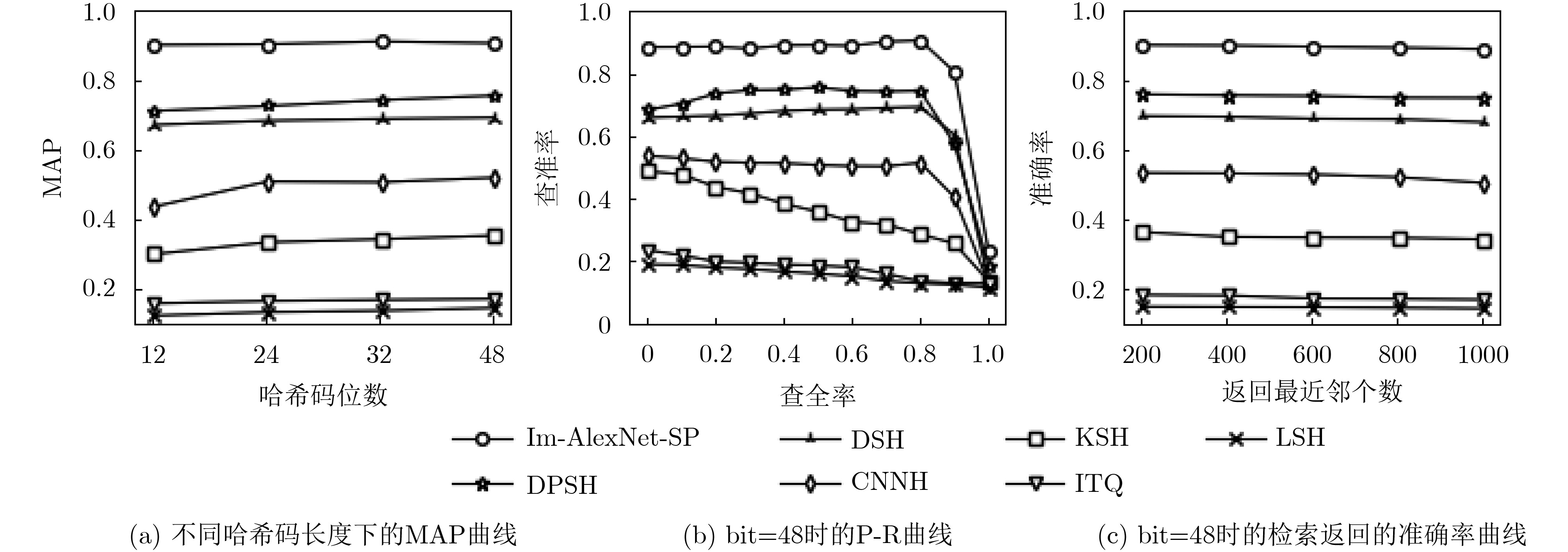
表 3 3种方法的MAP以及在bit=48下模型参数大小(MB)和训练时间(min)方法 不同哈希码长度(bit)下的MAP 参数大小 训练时间 12 24 32 48 AlexNet 0.8336 0.8450 0.8518 0.8554 218.20 158 AlexNet-SP 0.8729 0.9004 0.9066 0.8963 179.15 115 Im-AlexNet-SP 0.8995 0.9072 0.9173 0.9095 100.77 80 表 4 3种方法在不同哈希码长度下的准确率方法 不同哈希码长度(bit)下的准确率 12 24 32 48 AlexNet 0.8964 0.8995 0.8988 0.9073 AlexNet-SP 0.9312 0.9298 0.9325 0.9367 Im-AlexNet-SP 0.9320 0.9305 0.9410 0.9384 从表3和图4可以看到3种方法MAP,P-R曲线和Top-k 检索返回的准确率曲线以及模型参数大小与训练时间对比。经过对AlexNet进行改进后使得新提取的图像特征表达效果更好,在加深网络的同时实现通道的信息整合,不仅MAP和精度有一定程度提高,最高MAP值达到91.73%,而且模型参数和训练时间相比之下都有所减小,在提升检索性能的同时,加快模型训练速度。
从表4可以看到3种方法的极光图像分类的情况,前两种方法对比可以看出SPP_PMT层对极光分类效果有较大提高;后两种方法对比可以看出对AlexNet改进后对于准确率略有提高,最高达到94.10%。但从图5的混淆矩阵图看出弧状和帷幔冕状极光图像的分类准确率都较高,热点状极光主要被错分成了弧状类和辐射冕状类,经分析主要原因是热点状极光具有亮斑、不规则块、涡旋、射线束等多种复杂结构,与弧状和辐射冕状极光具有局部相似性,且热点状极光样本数量较其他几种偏少,所以容易导致错分情况。
最后将本文方法与其他几种极光图像检索算法(HE[14], VLAD[15], MAC[16]和MS-RMAC[17])进行对比。表5为本文方法(bit=48)与其他几种算法的MAP以及平均查询时间对比。从性能来看,与基于传统SIFT特征的方法(HE和VLAD)相比,基于CNN特征检索方法(MAC, MS-RMAC以及本文方法)的MAP有明显提高,尤其是本文方法取得最高90.95%的MAP值,这得益于多尺度CNN特征融合和联合损失来训练。从效率来看,MAC和MS-RMAC是最耗时的,因为它们使用高维的CNN特征;相反,由于PCA对特征进行降维操作,VLAD获得了惊人的效率,HE模型紧随其后。而本文方法使用哈希算法和CNN结合将高维特征向量映射为低维紧凑的二值哈希码,达到了数据降维的作用,减少了检索时间。
表 5 本文方法与其他极光检索算法的MAP以及平均查询时间对比(s)方法 MAP 平均查询时间 HE 0.5253 0.65 VLAD 0.5868 0.52 MAC 0.6558 1.22 MS-RMAC 0.6901 2.89 本文Im-AlexNet-SP 0.9095 0.43 3.2.2 CIFAR-10数据集上的实验
为了验证本文方法的检索效果对其他数据集的可扩展性,同时与其他主流的哈希算法(如LSH[18], ITQ[19], KSH[20], CNNH[8], DSH[10], DPSH[9]等)进行对比。表6是不同哈希算法在CIFAR-10不同哈希码长度下的MAP对比。图6是不同哈希算法在CIFAR-10上MAP, PR以及Top- k 检索返回的准确率曲线。
表 6 不同哈希算法在CIFAR-10不同哈希码长度下的MAP方法 不同哈希码长度(bit)下的MAP 12 24 32 48 本文Im-AlexNet-SP 0.902 0.904 0.912 0.907 DPSH 0.713 0.727 0.744 0.757 DSH 0.673 0.685 0.690 0.694 CNNH 0.439 0.511 0.509 0.522 KSH 0.303 0.337 0.346 0.356 ITQ 0.162 0.169 0.172 0.175 LSH 0.127 0.137 0.141 0.149 从表6和图6中可以看出基于CNN的深度哈希算法(CNNH, DSH, DPSH和本文方法)总体上优于传统的哈希算法(LSH, ITQ和KSH),其中CNNH算法性能不算好,由于该算法不属于端到端的学习,其哈希编码和CNN的训练过程是相互独立的,不能互相反馈,也就没有发挥出深度网络的强大学习能力。而 DSH算法只使用了图像对的相似度信息,没有加入图像的标签信息,因此检索精度低于本文方法。由以上分析可知,一方面本文方法在 CIFAR-10 上也达到了比较理想的检索效果,其中当哈希长度为32 bit时MAP 值达到91.2%,相较于经典的 DSH 算法相比提升了 22.2%,同DPSH算法相比MAP值提升了16.8%,从而验证了本文方法的可拓展性和有效性。
4. 结束语
本文基于CNN强大的特征学习能力以及哈希编码的数据降维、检索速度快等优势提出了一种新的深度哈希算法,充分利用标签信息和图像对相似度信息来训练网络模型,并将SPP和PMT嵌入到网络中来提取数据中更复杂的特征信息。此外,针对AlexNet做出改进不仅提升了检索性能、减少了模型参数、节省了存储空间、加快了模型训练,还能有效用于极光图像分类。在CIFAR-10上与主流的哈希算法对比中,本文方法实现了最佳的检索性能,进一步验证所提方法的扩展性。同时也有两点需要改进,一方面极光数据集偏小,且类别之间存在不均衡,因此需要针对小数据集以及不均衡的问题使用更合适的模型和一些策略来改进。另一方面由于极光形态结构复杂且是动态变化的,尤其是有些热点状极光图像在视觉上可能是几种类型的混合形态,所以在进行特征提取时应结合极光特有的形态以解决热点状极光容易被错分的问题。
-
[1] Vishwanath S, Jindal N, and Goldsmith A. Duality,achievable rates and sum-rate capacity of Gaussian MIMObroadcast channels [J].IEEE Trans. on Information Theory.2003, 49(10):2658-2668 [2] Viswanath P and Tse D N C. Sum capacity of the vectorGaussian broadcast channel and uplink-downlink duality [J].IEEE Trans. on Information Theory.2003, 49(8):1912-1921 [3] Yu W and Cioffi J. Sum capacity of Gaussian vectorbroadcast channels [J].IEEE Trans. on Information Theory.2004, 50(9):1875-1892 [4] Han Z, Ji Z, and Liu K J R. Fair multiuser channel allocationfor OFDMA networks using Nash bargaining solutions andcoalitions[J].IEEE Trans. on Communication.2005, 53(8):1366-1376 [5] Caire G and Shamai S. On the achievable throughput of amultiantenna Gaussian broadcast channel [J].IEEE Trans.on Information Theory.2003, 49(7):1691-1706 [6] Douligeris C and Mazumdar R R. More on Pareto-optimalflow control. Proceedings of the 26th Allerton Conference onCommunication, Control, and Computing, Urbana, IL,United States, 1987: 553-574. [7] Reklaitis G V, Ravindran A, and Ragsdell K M. EngineeringOptimization: Methods and Applications[M]. 2rd, New York:Wiley, 1983, Chap. 3, 5, 6. [8] Tu Z Y and Blum R S. Multiuser diversity for a dirty paperapproach[J].IEEE Trans. on Communications Letters.2003,7(8):370-372 [9] Jiang J, Buehrer R M, and Tranter W H. Greedy schedulingperformance for a zero-forcing dirty-paper coded system [J].IEEE Trans. on Communication.2006, 54(5):789-793 期刊类型引用(11)
1. 刘传升,丁卫平,程纯,黄嘉爽,王海鹏. ViTH:面向医学图像检索的视觉Transformer哈希改进算法. 西南大学学报(自然科学版). 2024(05): 11-26 .  百度学术
百度学术2. 赵永晖,胡海根. 基于子空间关系学习的跨模态哈希检索方法. 计算机应用与软件. 2024(10): 304-313 . 百度学术3. 蒋伟进,孙永霞,朱昊冉,陈萍萍,张婉清,陈君鹏. 边云协同计算下基于ST-GCN的监控视频行为识别机制. 南京大学学报(自然科学). 2022(01): 163-174 . 百度学术4. 宋志平,朱亚俐,吾尔尼沙·买买提,库尔班·吾布力. 一种海量图像下的高精度特征检索算法. 计算机仿真. 2022(04): 185-188+302 . 百度学术5. 李然,杨玉婷,张志强,刘鹰,黄健隆,李浩淼. 智能鱼类信息共享平台的构建. 大连海洋大学学报. 2022(03): 497-504 . 百度学术6. 汤德林. 一种图像降重系统在近视治疗仪故障检测中的实现. 信息记录材料. 2022(08): 59-62 . 百度学术7. 张壮领,陈彩娜,毕明利. 基于ARM+FPGA方案的便携式智能勘灾设备的设计. 工业仪表与自动化装置. 2021(03): 55-60 . 百度学术8. 袁浩. 基于深度字典学习的图像分类方法. 信息与电脑(理论版). 2021(12): 55-57 . 百度学术9. 高晶,曹福凯,闫明,Muhd Khaizer Omar. 信息相似性下网络对抗文本重复数据分级索引. 计算机仿真. 2021(10): 462-465+470 . 百度学术10. 顾广华 ,霍文华 ,苏明月 ,付灏 . 基于非对称监督深度离散哈希的图像检索. 电子与信息学报. 2021(12): 3530-3537 .  本站查看
本站查看11. 杨月. 数字图书馆交互式信息分类检索模型设计. 科技通报. 2021(12): 112-116 . 百度学术其他类型引用(8)
-

 下载:
下载:



































 百度学术
百度学术
计量
- 文章访问数: 3628
- HTML全文浏览量: 107
- PDF下载量: 1397
- 被引次数: 19
 下载:
下载:
