

Data-Driven Secure Control for Cyber-Physical Systems under Denial-of-Service Attacks: An Online Mode-Dependent Switching-Q-Learning Algorithm
-
摘要: 基于学习策略和切换系统理论,该文研究了拒绝服务(DoS)攻击下未知信息物理系统(CPS)的安全分析与控制问题。考虑到攻击能量有限性,采用攻击频率和持续时间来描述DoS攻击。特别地,不同于现有的安全学习方法,该文利用切换系统理论提出了一种在线模态依赖的切换-Q-学习控制新算法及相应的数据驱动安全评估新准则。首先,将休眠和活跃DoS攻击下的未知CPS分别转化为一类含有稳定和不稳定子系统的未知切换系统。随后设计了一种新颖的在线模态依赖的切换-Q-学习算法,进而获得数据驱动的最优安全控制增益。同时通过约束子系统阶段和切换阶段的能量函数,提出了一种具有攻击频率和持续时间约束的数据驱动安全评估准则。最后通过网络化轮式机器人系统的对比实验验证了该方法的高效性和优越性。Abstract:
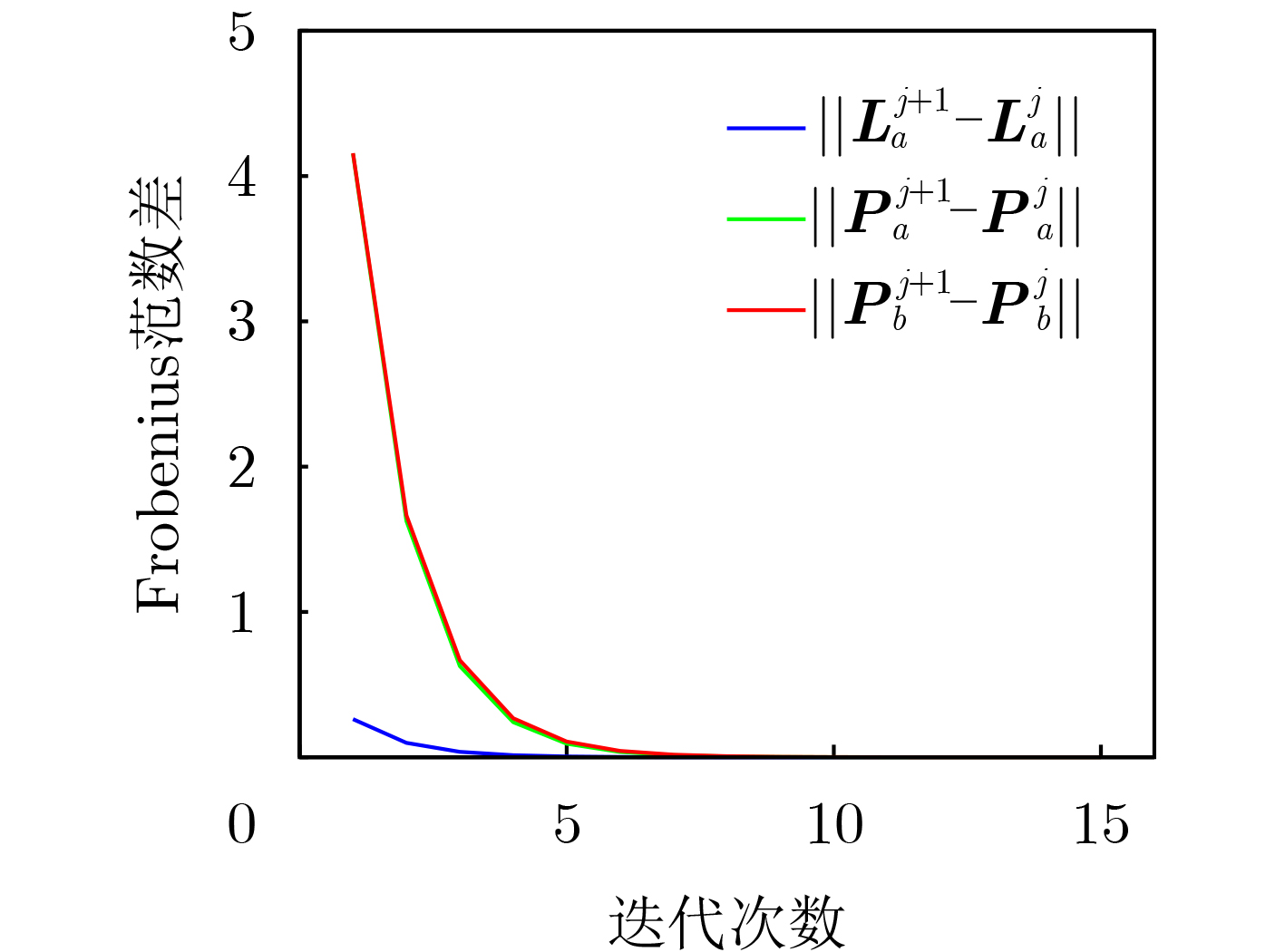
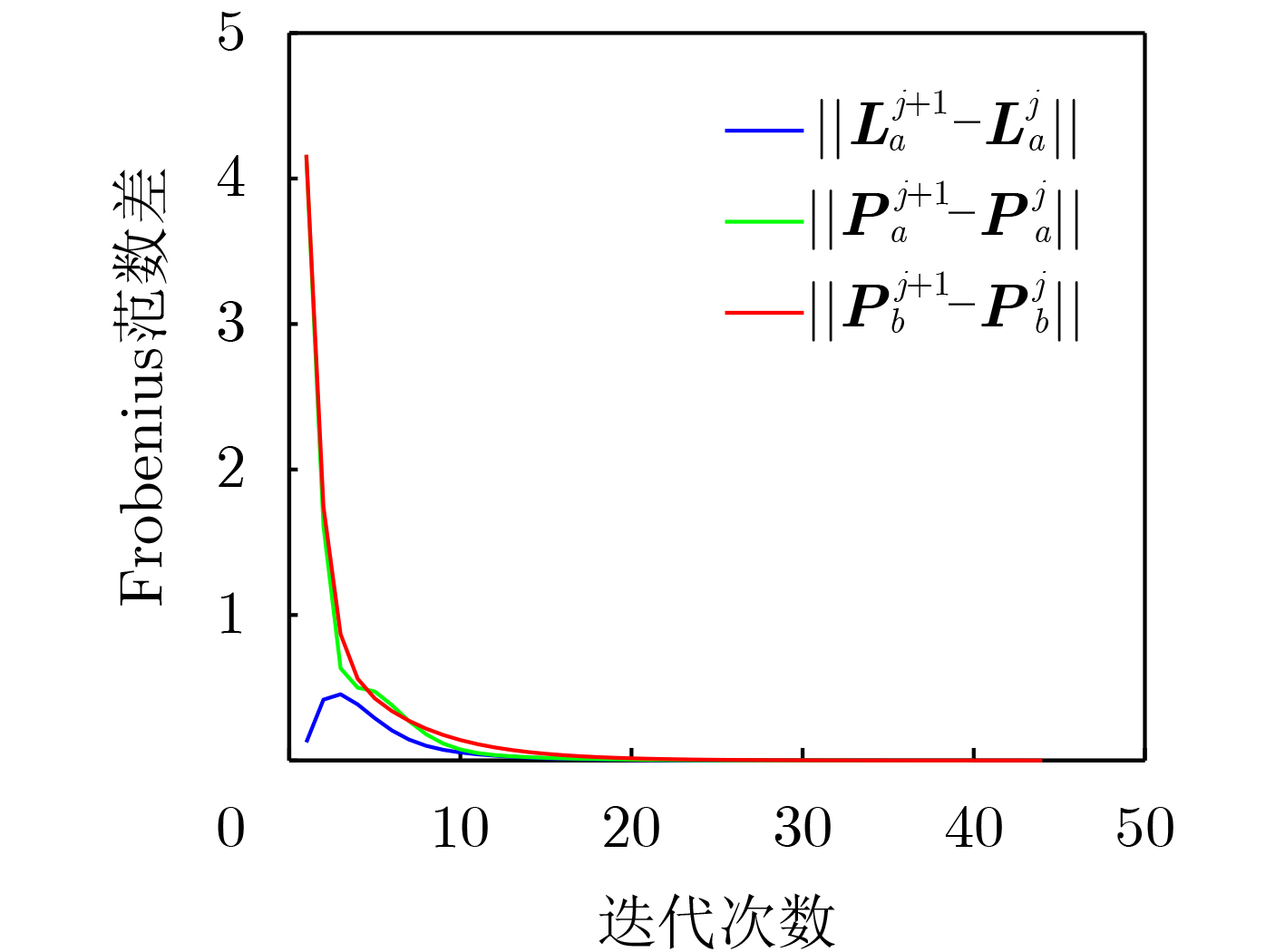
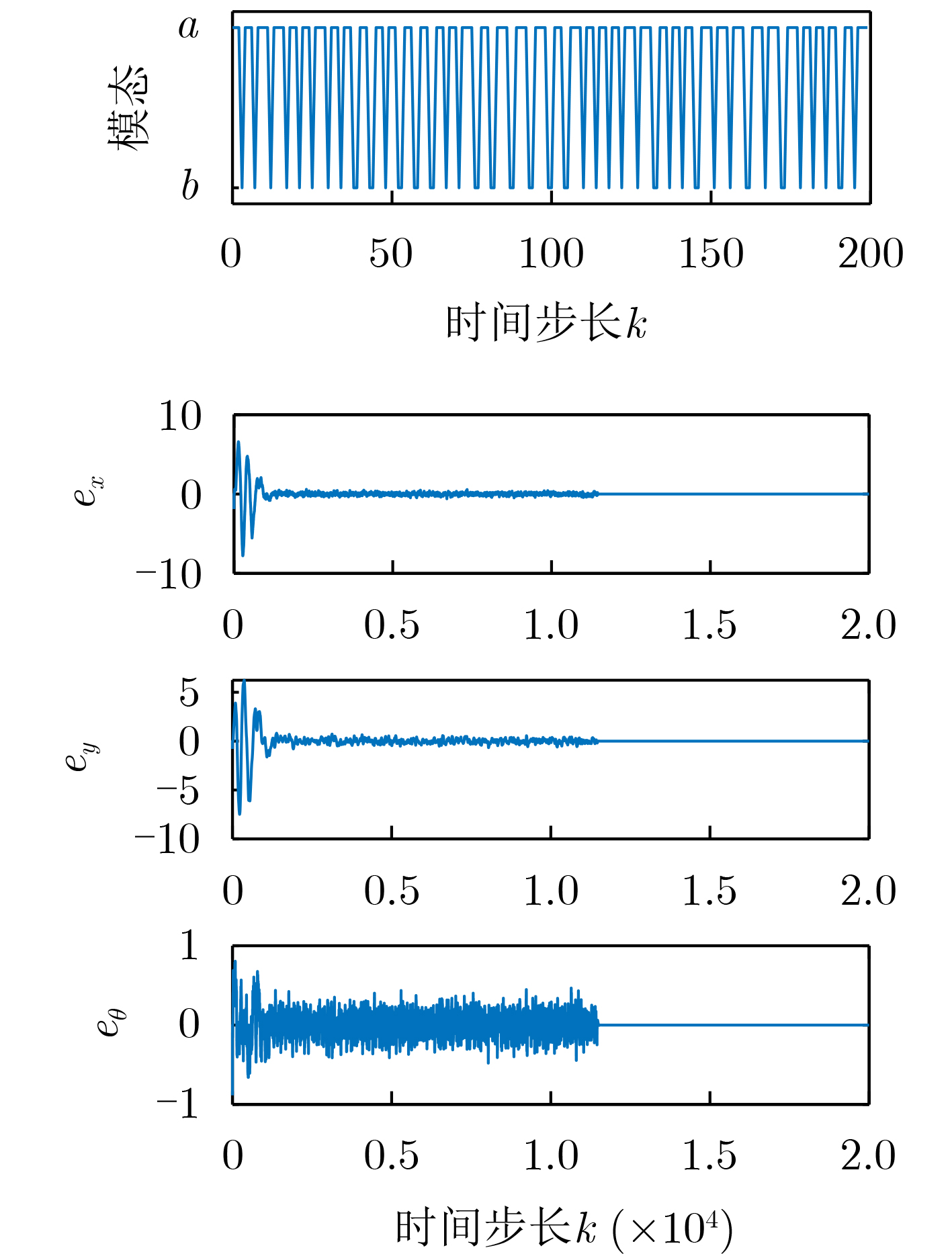
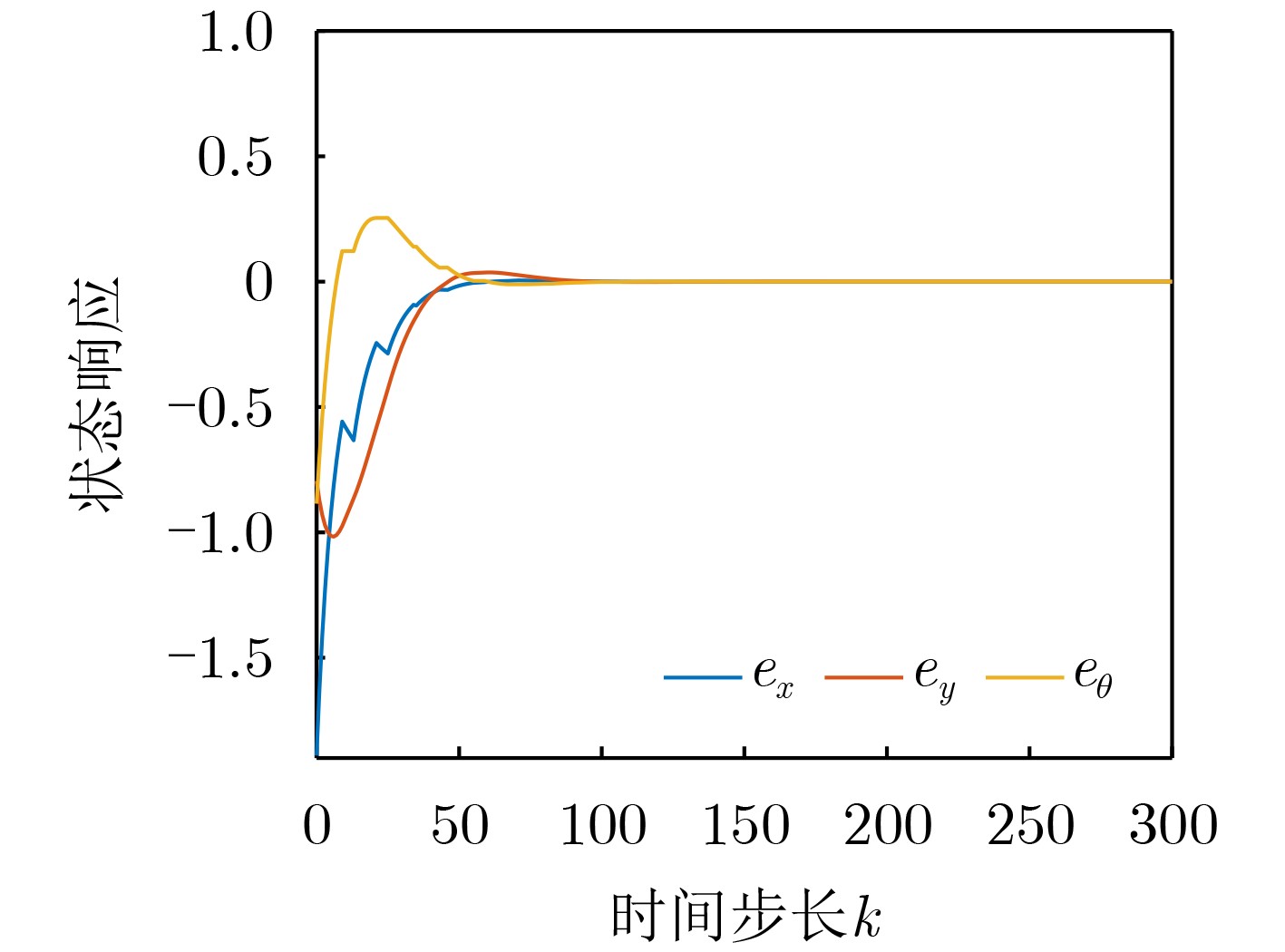
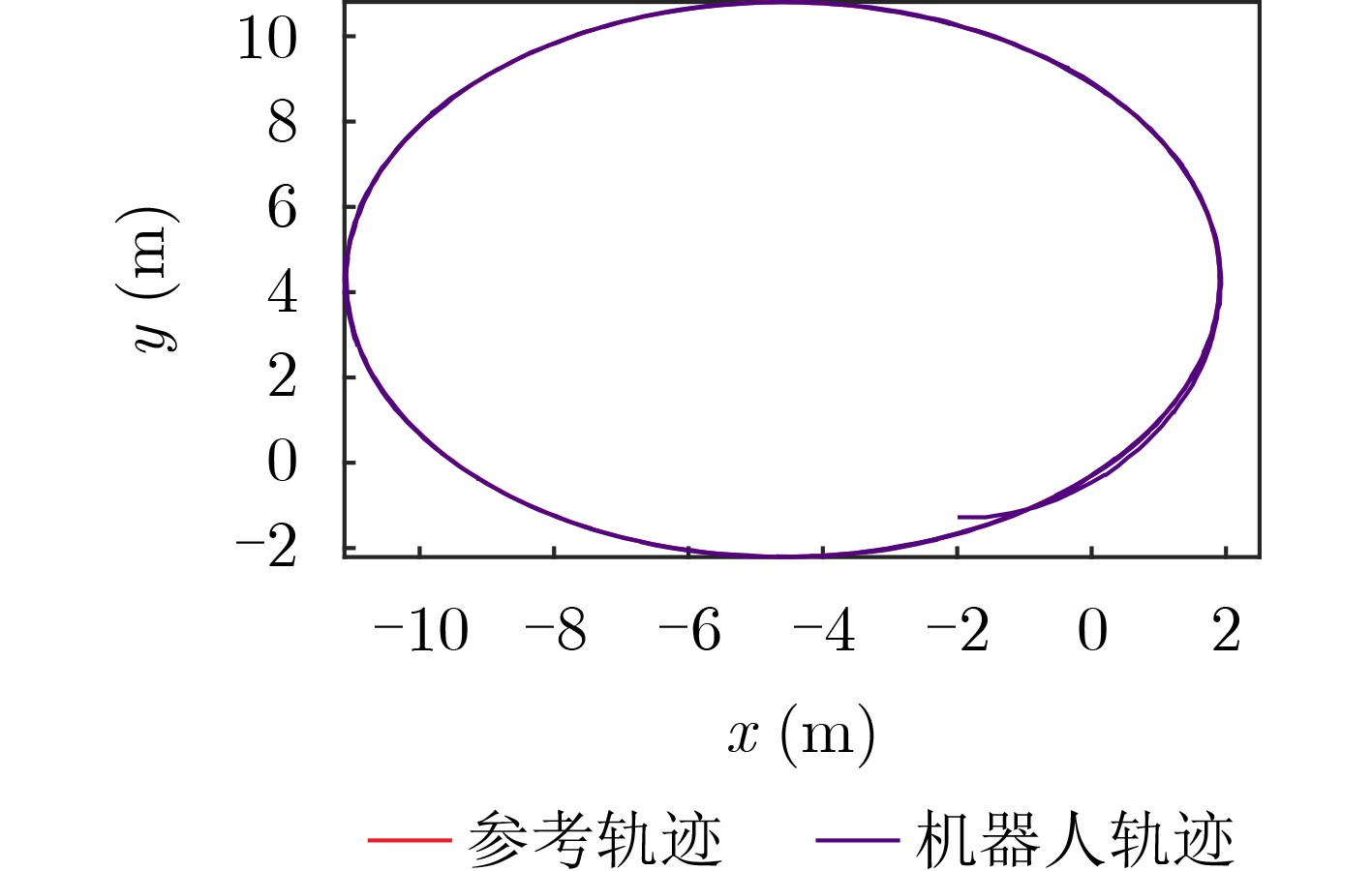
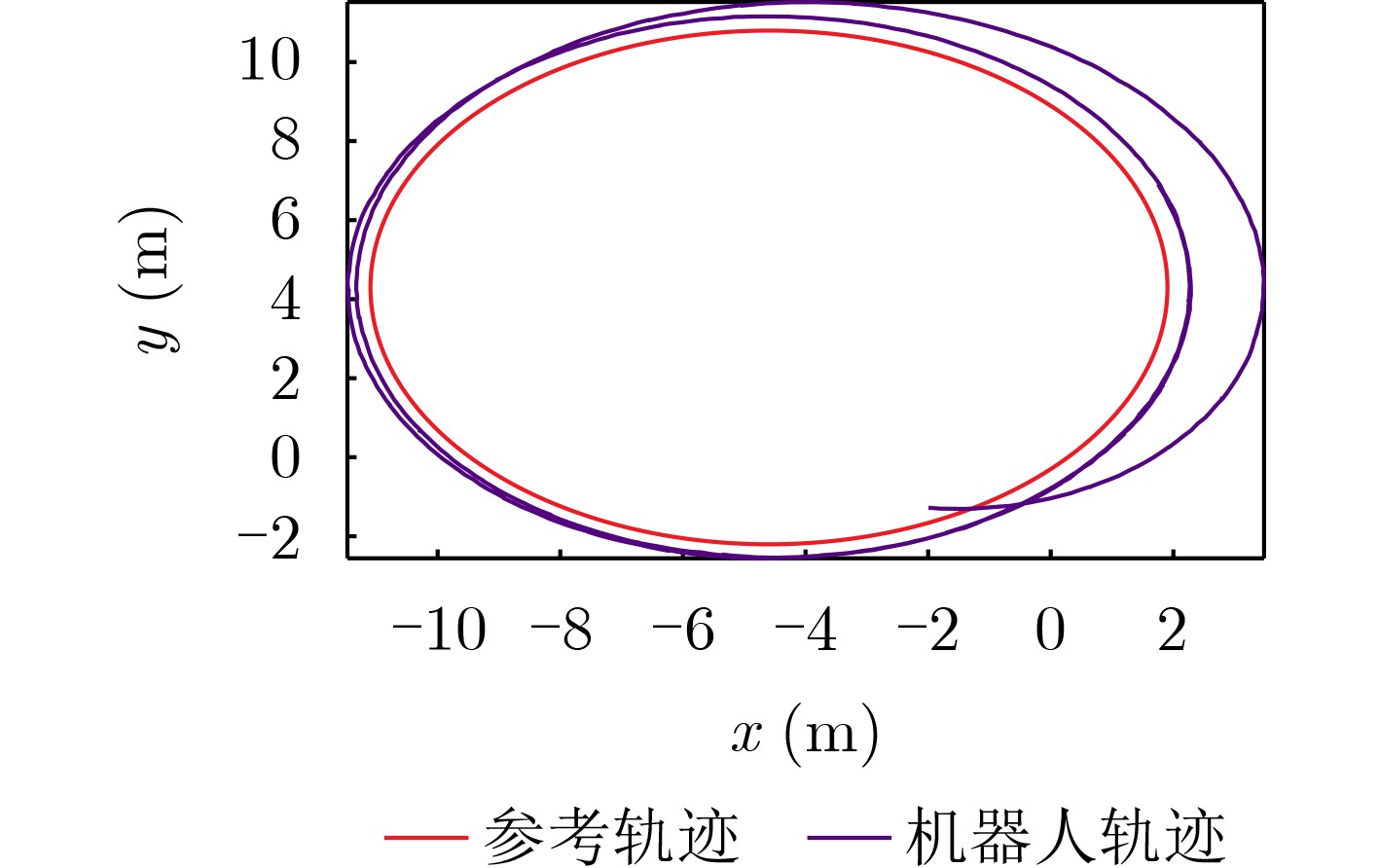
Objective The open network architecture of Cyber-Physical Systems (CPSs) enables flexibility and scalability, but also increases vulnerability to cyber-attacks. In particular, Denial-of-Service (DoS) attacks represent a predominant threat, causing packet loss and performance degradation by channel jamming. CPSs under dormant and active DoS attacks can be modeled as dual-mode switched systems with stable and unstable subsystems, respectively. Therefore, switched system theory provides a promising framework for secure control design with high degrees of freedom and reduced conservatism. However, exact modeling of practical CPSs remains difficult due to attacks and noise. Although Q-learning-based control shows potential for unknown CPSs, a critical gap persists for switched systems with unstable modes, especially in establishing an evaluable stability criterion. Hence, learning-based secure control design and an evaluable security criterion for unknown CPSs under DoS attacks remain open problems. Methods An online mode-dependent switching-Q-learning algorithm is proposed to study data-driven secure control and an evaluable criterion for unknown CPSs under DoS attacks. First, CPSs under dormant and active DoS attacks are transformed into switched systems with stable and unstable subsystems, respectively. Then, the optimal control problem of the value function is addressed for model-based switched systems by constructing a Generalized Switching Algebraic Riccati Equation (GSARE) and deriving the corresponding mode-dependent optimal security controller. The existence and uniqueness of the GSARE solution are proved. Based on these results, a data-driven optimal security control law is developed through a novel online mode-dependent switching-Q-learning algorithm. Finally, by using the learned control gains and parameter matrices, a data-driven evaluable security criterion related to attack frequency and duration is established under switching and subsystem constraints. Results and Discussions Comparative experiments using a wheeled robot are conducted to verify the efficiency and advantages of the proposed methods. First, comparison between the model-based result (Theorem 1) and the data-driven result (Algorithm 1) shows that the optimal control gains and parameter matrices under threshold errors are successfully obtained from both the GSARE and the proposed learning algorithm, as indicated by the iterative curves ( Fig. 2 andFig. 3 ). Meanwhile, the tracking errors of the CPS converge to zero under the proposed data-driven controller (Fig. 5 ), ensuring exponential stability and verifying algorithm effectiveness. Second, the learning process curves (Fig. 4 ) show that although the initial learned control gain is not stabilizing, Algorithm 1 still converges to an optimal stabilizing gain. This result reduces conservatism compared with existing Q-learning approaches that require stabilizing initial gains. Third, comparison between the proposed data-driven evaluable security criterion (Theorem 2) and existing criteria shows that, even when the learned switching parameters do not satisfy conventional dwell-time constraints, the proposed criterion yields attack frequency and duration bounds under new switching and subsystem constraints. As shown in Tab. 1, the proposed criterion is less conservative than existing evaluable criteria. Finally, applying the learned controller and obtained DoS constraints to robot tracking control demonstrates faster and more accurate trajectory tracking compared with existing Q-learning controllers (Fig. 6 andFig. 7 ), confirming the advantages of the proposed approach.Conclusions Based on switched system theory and learning-based control, an online mode-dependent switching-Q-learning algorithm and a corresponding evaluable security criterion are presented for unknown CPSs under DoS attacks. (1) By representing CPSs under dormant and active DoS attacks as switched systems with stable and unstable subsystems, respectively, the security problem is transformed into a stabilization problem with increased design freedom and reduced conservatism. (2) A novel online mode-dependent switching-Q-learning algorithm is developed for unknown switched systems with unstable modes, and comparative experiments show reduced conservatism relative to existing Q-learning methods. (3) A data-driven evaluable security criterion is established to characterize attack frequency and duration under switching and subsystem constraints, demonstrating lower conservatism than existing criteria based on single-subsystem or dwell-time constraints. -
1 在线模态依赖的切换-Q-学习控制算法
1:设定初始值$ {\boldsymbol{L}}_a^0 $, $ {\boldsymbol{\mathcal{P}}}_i^0 $, $ {\boldsymbol{P}}_i^0 $和$j = 0$,其中$i \in \{ a,b\} $. 2:设定学习误差阈值$ \varepsilon _i^{} $ 3:执行策略更新式(32) 4:执行策略评估式(31) 5:如果 $ \Vert {{\boldsymbol{P}}}_{i}^{j+1}-{{\boldsymbol{P}}}_{i}^{j}\Vert \lt {\epsilon}_{i} $,那么 6: 输出参数矩阵$ {\boldsymbol{P}}_i^{j + 1} $和最优控制增益$ {\boldsymbol{L}}_a^{j + 1} $ 7:否则 8: $j = j + 1$ 9: 返回步骤3 10:结束判断  下载: 导出CSV
下载: 导出CSV
表 1 本文与文献[24]的数据驱动安全评估准则比较
本文定理2 (基于
本文算法1)文献[24]推论1(基于[24]中
算法1)切换参数: ${\mu _a} = 1.04$, ${\mu _b} = 1.74$ 无 子系统参数: ${\eta _a} = 0.8$, $ {\eta _b} = 1.55 $ $ {\mu _1}{\text{ = 0}}{\text{.11}} $, $ {\mu _2}{\text{ = 18}}{\text{.5}} $ 攻击约束: ${\tau _{\text{F}}} = {\text{10}}{\text{.26}}$, ${\tau _{\text{D}}} = 4$ $\tau \ge 6$($ {{T}}=6 $下)
下载: 导出CSV
-
[1] 杨挺, 刘亚闯, 刘宇哲, 等. 信息物理系统技术现状分析与趋势综述[J]. 电子与信息学报, 2021, 43(12): 3393–3406. doi: 10.11999/JEIT211135.YANG Ting, LIU Yachuang, LIU Yuzhe, et al. Review on cyber-physical system: Technology analysis and trends[J]. Journal of Electronics & Information Technology, 2021, 43(12): 3393–3406. doi: 10.11999/JEIT211135. [2] 杨光红, 芦安洋, 安立伟. 网络攻击下的信息物理系统安全状态估计研究综述[J]. 控制与决策, 2023, 38(8): 2093–2105. doi: 10.13195/j.kzyjc.2023.0885.YANG Guanghong, LU Anyang, and AN Liwei. A survey on secure state estimation of cyber-physical systems under cyber attacks[J]. Control and Decision, 2023, 38(8): 2093–2105. doi: 10.13195/j.kzyjc.2023.0885. [3] LU Kangdi and WU Zhengguang. Resilient event-triggered load frequency control for cyber-physical power systems under DoS attacks[J]. IEEE Transactions on Power Systems, 2023, 38(6): 5302–5313. doi: 10.1109/TPWRS.2022.3229667. [4] OBAYYA M, AL-WESABI F N, ALABDAN R, et al. Artificial intelligence for traffic prediction and estimation in intelligent cyber-physical transportation systems[J]. IEEE Transactions on Consumer Electronics, 2024, 70(1): 1706–1715. doi: 10.1109/TCE.2023.3320513. [5] 李云鹏, 张立宪, 韩岳江, 等. 基于模型预测控制的子母式无人机编队飞行控制方法[J]. 自动化学报, 2025, 51(2): 312–326. doi: 10.16383/j.aas.c240405.LI Yunpeng, ZHANG Lixian, HAN Yuejiang, et al. Model predictive control-based formation flight control method for composite UAVs[J]. Acta Automatica Sinica, 2025, 51(2): 312–326. doi: 10.16383/j.aas.c240405. [6] LANGNER R. Stuxnet: Dissecting a cyberwarfare weapon[J]. IEEE Security & Privacy, 2011, 9(3): 49–51. doi: 10.1109/MSP.2011.67. [7] KHAN S. Distributed sensors, computation and AI for automation, protection and maintenance of power grid[C]. Proceedings of the 2022 18th International Computer Engineering Conference, Cairo, Egypt, 2022: 130–135. doi: 10.1109/ICENCO55801.2022.10032522. [8] XU Hang, BARBOT S, and WANG Teng. Remote sensing through the fog of war: Infrastructure damage and environmental change during the Russian-Ukrainian conflict revealed by open-access data[J]. Natural Hazards Research, 2024, 4(1): 1–7. doi: 10.1016/j.nhres.2024.01.006. [9] WANG Zhe, ZHANG Heng, YANG Chaoqun, et al. Improved zero-dynamics attack scheduling with state estimation[J]. IEEE/CAA Journal of Automatica Sinica, 2025, 12(2): 472–474. doi: 10.1109/JAS.2024.124737. [10] ZHAO Rui, ZUO Zhiqiang, SHI Yang, et al. DoS and stealthy deception attacks for switched systems: A cooperative approach[J]. IEEE Transactions on Automatic Control, 2024, 69(7): 4396–4410. doi: 10.1109/TAC.2023.3321248. [11] DE PERSIS C and TESI P. Input-to-state stabilizing control under denial-of-service[J]. IEEE Transactions on Automatic Control, 2015, 60(11): 2930–2944. doi: 10.1109/TAC.2015.2416924. [12] SU Lei and YE Dan. Observer-based output feedback control for cyber-physical systems under randomly occurring packet dropout and periodic DoS attacks[J]. ISA Transactions, 2019, 95: 58–67. doi: 10.1016/j.isatra.2019.05.008. [13] TAN Wen, HOU Zhongsheng, and LI Yuanxin. Data-driven containment control for unknown MIMO nonlinear MASs under aperiodic DoS attacks[J]. IEEE Transactions on Automation Science and Engineering, 2025, 22: 7762–7772. doi: 10.1109/TASE.2024.3469153. [14] DEBRUHL B and TAGUE P. Digital filter design for jamming mitigation in 802.15. 4 communication[C]. Proceedings of 20th International Conference on Computer Communications and Networks, Lahaina, USA, 2011: 1–6. doi: 10.1109/ICCCN.2011.6006020. [15] SHI Ting, SHI Peng, and CHAMBERS J. Dynamic event-triggered model predictive control under channel fading and denial-of-service attacks[J]. IEEE Transactions on Automation Science and Engineering, 2024, 21(4): 6448–6459. doi: 10.1109/TASE.2023.3325534. [16] YUAN Yuan, YUAN Huanhuan, GUO Lei, et al. Resilient control of networked control system under DoS attacks: A unified game approach[J]. IEEE Transactions on Industrial Informatics, 2016, 12(5): 1786–1794. doi: 10.1109/TII.2016.2542208. [17] SAEEDI M, ZAREI J, RAZAVI-FAR R, et al. Event-triggered adaptive optimal fast terminal sliding mode control under denial-of-service attacks[J]. IEEE Systems Journal, 2022, 16(2): 2684–2692. doi: 10.1109/JSYST.2021.3073816. [18] ZHU Yanzheng and ZHENG Weixing. Observer-based control for cyber-physical systems with periodic DoS attacks via a cyclic switching strategy[J]. IEEE Transactions on Automatic Control, 2020, 65(8): 3714–3721. doi: 10.1109/TAC.2019.2953210. [19] WU Chengwei, WU Ligang, LIU Jianxing, et al. Active defense-based resilient sliding mode control under denial-of-service attacks[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 237–249. doi: 10.1109/TIFS.2019.2917373. [20] SHEN Hao, LIU Xinmiao, MA Qian, et al. Observer-based control for interval type-2 fuzzy systems under PDT-based DoS attacks[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025, 55(6): 3780–3790. doi: 10.1109/TSMC.2025.3547320. [21] WANG Fuxing, LONG Yue, and LI Tieshan. Thruster fault detection for unmanned marine vehicles under DoS attacks: An asynchronous switched method[C]. Proceedings of the 14th International Conference on Information Science and Technology, Chengdu, China, 2024: 554–559. doi: 10.1109/ICIST63249.2024.10805417. [22] 华和安, 方勇纯, 钱辰, 等. 基于线性滤波器的四旋翼无人机强化学习控制策略[J]. 电子与信息学报, 2021, 43(12): 3407–3417. doi: 10.11999/JEIT210251.HUA He’an, FANG Yongchun, QIAN Chen, et al. Reinforcement learning control strategy of quadrotor unmanned aerial vehicles based on linear filter[J]. Journal of Electronics & Information Technology, 2021, 43(12): 3407–3417. doi: 10.11999/JEIT210251. [23] REN Yan, ZHANG Heng, YANG Wei, et al. Transferable adversarial attack against deep reinforcement learning-based smart grid dynamic pricing system[J]. IEEE Transactions on Industrial Informatics, 2024, 20(6): 9015–9025. doi: 10.1109/TII.2024.3379645. [24] YIN Liyuan, XU Lezhong, HOU Fusheng, et al. Security analysis and control under periodic DoS attacks[J]. IEEE Internet of Things Journal, 2024, 11(5): 8473–8484. doi: 10.1109/JIOT.2023.3319703. [25] LIU Jinliang, DONG Yanhui, ZHA Lijuan, et al. Reinforcement learning-based tracking control for networked control systems with DoS attacks[J]. IEEE Transactions on Information Forensics and Security, 2024, 19: 4188–4197. doi: 10.1109/TIFS.2024.3376250. [26] GAO Weinan, DENG Chao, JIANG Yi, et al. Resilient reinforcement learning and robust output regulation under denial-of-service attacks[J]. Automatica, 2022, 142: 110366. doi: 10.1016/j.automatica.2022.110366. [27] LI Hao, CHEN Hua, and ZHANG Wei. On model-free reinforcement learning for switched linear systems: A subspace clustering approach[C]. Proceedings of the 2018 56th Annual Allerton Conference on Communication, Control, and Computing, Monticello, USA, 2018: 123–130, doi: 10.1109/ALLERTON.2018.8635985. [28] CHEN Hua, ZHANG Linfang, and ZHANG Wei. Optimal control inspired Q-learning for switched linear systems[C]. Proceedings of the 2020 American Control Conference (ACC), Denver, USA, 2020: 4003–4010. doi: 10.23919/ACC45564.2020.9147818. [29] ZHANG Xuewen, WANG Yun, XIA Jianwei, et al. Optimal tracking control for discrete-time modal persistent dwell time switched systems based on Q-learning[J]. Optimal Control Applications and Methods, 2023, 44(6): 3327–3341. doi: 10.1002/oca.3040. [30] SUN Jiayue, ZHANG Huaguang, WANG Yingchun, et al. Optimal tracking control of switched systems applied in grid-connected hybrid generation using reinforcement learning[J]. Neural Computing and Applications, 2021, 33(15): 9363–9374. doi: 10.1007/s00521-021-05696-2. [31] WU Jiacheng, LIAN Bosen, SU Hongye, et al. Data-driven weighted $\tiny{H_\infty }$ control of persistent dwell time switched systems with optimal disturbance attenuation guaranteed[J]. IEEE Transactions on Automation Science and Engineering, 2025, 22: 8162–8173. doi: 10.1109/TASE.2024.3480449. [32] ZHAI Lijing and VAMVOUDAKIS K G. Data-based and secure switched cyber-physical systems[J]. Systems & Control Letters, 2021, 148: 104826. doi: 10.1016/j.sysconle.2020.104826. [33] ZHANG Wei, ABATE A, HU Jianghai, et al. Exponential stabilization of discrete-time switched linear systems[J]. Automatica, 2009, 45(11): 2526–2536. doi: 10.1016/j.automatica.2009.07.018. [34] AL-TAMIMI A, LEWIS F L, and ABU-KHALAF M. Model-free Q-learning designs for linear discrete-time zero-sum games with application to H-infinity control[J]. Automatica, 2007, 43(3): 473–481. doi: 10.1016/j.automatica.2006.09.019. [35] FEI Zhongyang, SHI Shuang, and SHI Peng. Analysis and Synthesis for Discrete-Time Switched Systems: A Quasi-Time-Dependent Method[M]. Cham: Springer, 2020: 23–25. doi: 10.1007/978-3-030-25812-2. -


 下载:
下载:


图(7) / 表(2)
计量
- 文章访问数: 645
- HTML全文浏览量: 310
- PDF下载量: 102
- 被引次数: 0
