

Multimodal Hypergraph Learning Guidance with Global Noise Enhancement for Sentiment Analysis under Missing Modality Information
-
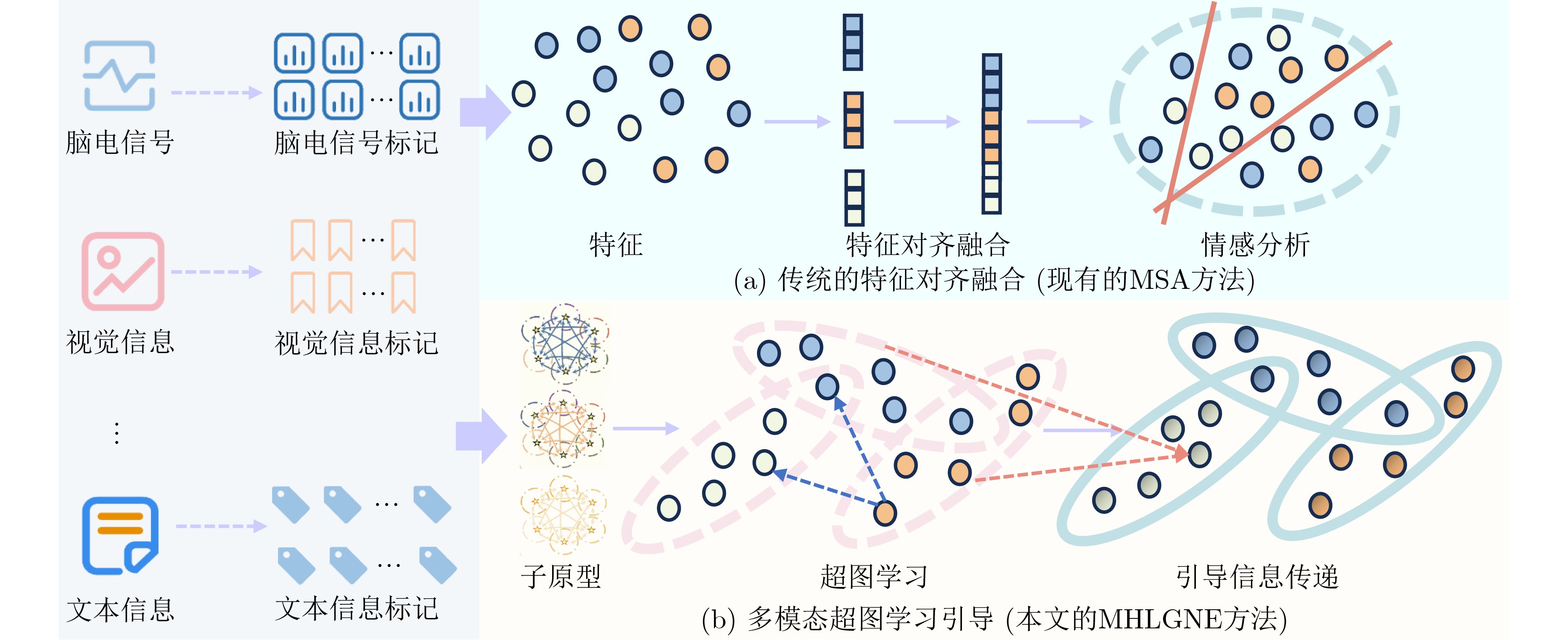
摘要: 多模态情感分析(MSA)通过多种模态信息来全面揭示人类情感状态。现有MSA研究在面临现实世界中的复杂场景时,仍然面临两方面的关键挑战:(1)忽略了现实世界复杂场景下的模态信息缺失,以及模型鲁棒性问题。(2)缺乏模态间丰富的高阶语义关联学习和跨模态信息传递机制。为了克服这些问题,该文提出一种带全局噪声增强的多模态超图学习引导情感分析方法(MHLGNE),旨在增强现实世界复杂场景中模态信息缺失条件下的多模态情感分析性能。具体而言,MHLGNE通过专门设计的自适应全局噪声采样模块从全局视角补充缺失的模态信息,从而增强模型的鲁棒性,并提高泛化能力。此外,还提出一个多模态超图学习引导模块来学习模态间丰富的高阶语义关联并引导跨模态信息传递。在公共数据集上的大量实验评估表明,MHLGNE在克服这些挑战方面表现优异。Abstract:
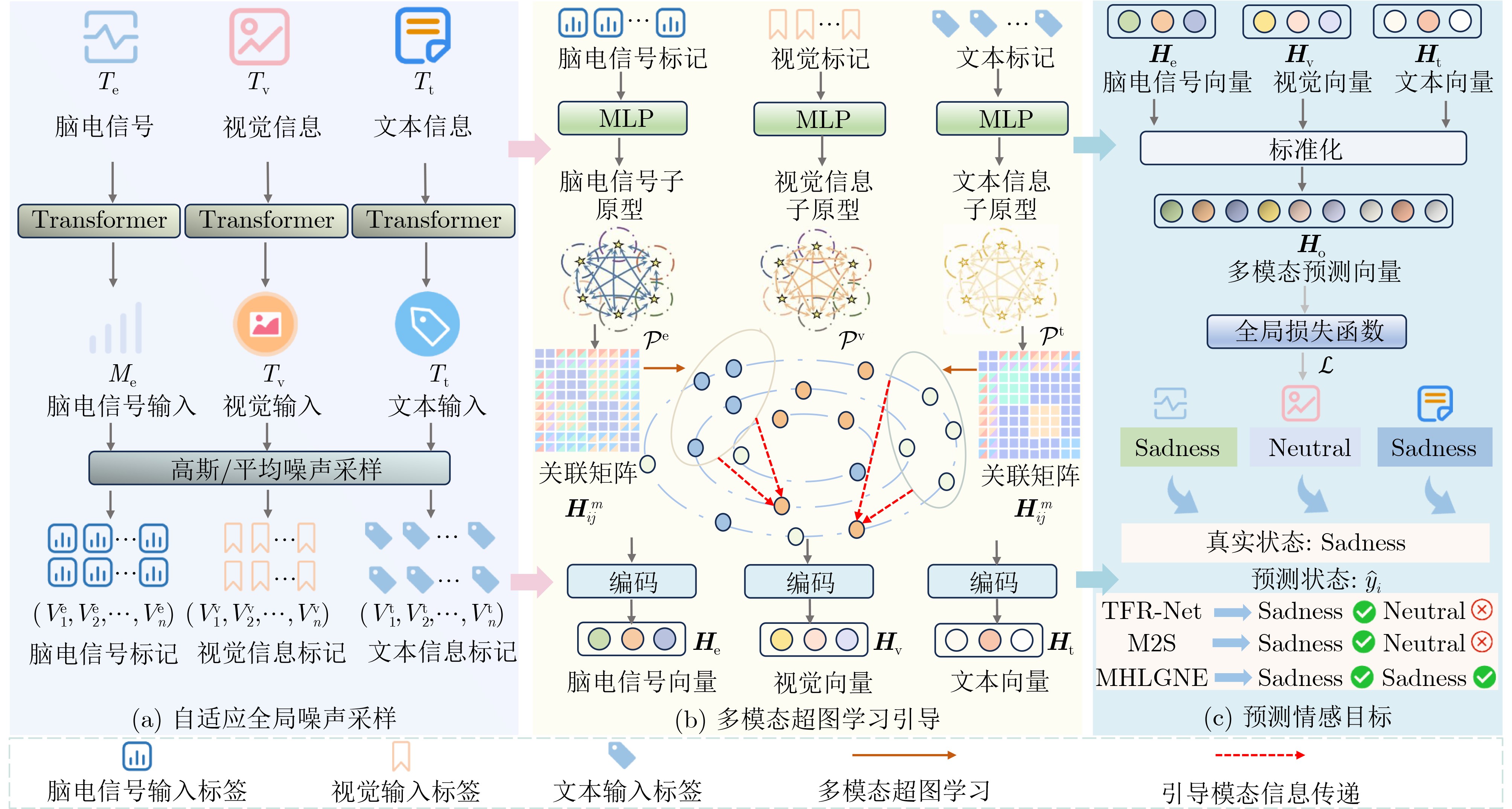
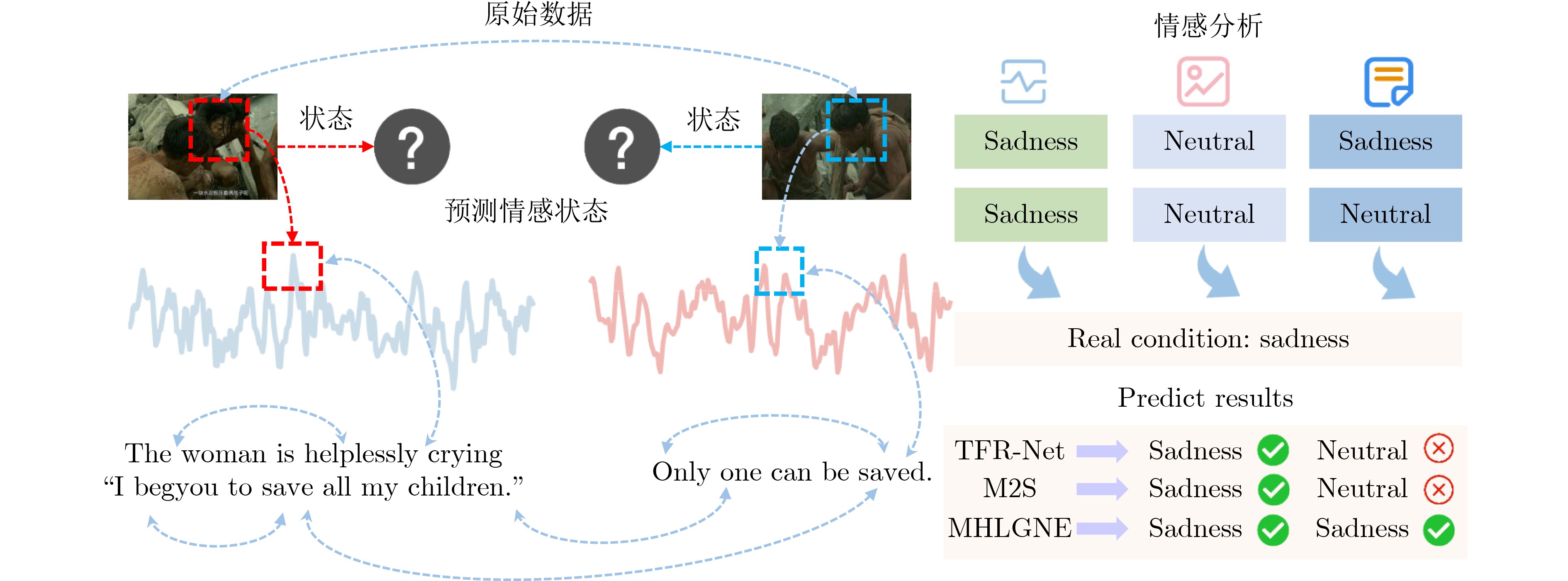
Objective Multimodal Sentiment Analysis (MSA) has shown considerable promise in interdisciplinary domains such as Natural Language Processing (NLP) and Affective Computing, particularly by integrating information from ElectroEncephaloGraphy (EEG) signals, visual images, and text to classify sentiment polarity and provide a comprehensive understanding of human emotional states. However, in complex real-world scenarios, challenges including missing modalities, limited high-level semantic correlation learning across modalities, and the lack of mechanisms to guide cross-modal information transfer substantially restrict the generalization ability and accuracy of sentiment recognition models. To address these limitations, this study proposes a Multimodal Hypergraph Learning Guidance method with Global Noise Enhancement (MHLGNE), designed to improve the robustness and performance of MSA under conditions of missing modality information in complex environments. Methods The overall architecture of the MHLGNE model is illustrated in Fig. 2 and consists of the Adaptive Global Noise Sampling Module, the Multimodal Hypergraph Learning Guiding Module, and the Sentiment Prediction Target Module. A pretrained language model is first applied to encode the multimodal input data. To simulate missing modality conditions, the input data are constructed with incomplete modal information, where a modality $ m\in \{{\mathrm{e,v,t}}\} $ is randomly absent. The adaptive global noise sampling strategy is then employed to supplement missing modalities from a global perspective, thereby improving adaptability and enhancing both robustness and generalization in complex environments. This design allows the model to handle noisy data and missing modalities more effectively. The Multimodal Hypergraph Learning Guiding Module is further applied to capture high-level semantic correlations across different modalities, overcoming the limitations of conventional methods that rely only on feature alignment and fusion. By guiding cross-modal information transfer, this module enables the model to focus on essential inter-modal semantic dependencies, thereby improving sentiment prediction accuracy. Finally, the performance of MHLGNE is compared with that of State-Of-The-Art (SOTA) MSA models under two conditions: complete modality data and randomly missing modality information.Results and Discussions Three publicly available MSA datasets (SEED-IV, SEED-V, and DREAMER) are employed, with features extracted from EEG signals, visual images, and text. To ensure robustness, standard cross-validation is applied, and the training process is conducted with iterative adjustments to the noise sampling strategy, modality fusion method, and hypergraph learning structure to optimize sentiment prediction. Under the complete modality condition, MHLGNE is observed to outperform the second-best M2S model across most evaluation metrics, with accuracy improvements of 3.26%, 2.10%, and 0.58% on SEED-IV, SEED-V, and DREAMER, respectively. Additional metrics also indicate advantages over other SOTA methods. Under the random missing modality condition, MHLGNE maintains superiority over existing MSA approaches, with improvements of 1.03% in accuracy, 0.24% in precision, and 0.08 in Kappa score. The adaptive noise sampling module is further shown to effectively compensate for missing modalities. Unlike conventional models that suffer performance degradation under such conditions, MHLGNE maintains robustness by generating complementary information. In addition, the multimodal hypergraph structure enables the capture of high-level semantic dependencies across modalities, thereby strengthening cross-modal information transfer and offering clear advantages when modalities are absent. Ablation experiments confirm the independent contributions of each module. The removal of either the adaptive noise sampling or the multimodal hypergraph learning guiding module results in notable performance declines, particularly under high-noise or severely missing modality conditions. The exclusion of the cross-modal information transfer mechanism causes a substantial decline in accuracy and robustness, highlighting its essential role in MSA. Conclusions The MHLGNE model, equipped with the Adaptive Global Noise Sampling Module and the Multimodal Hypergraph Learning Guiding Module, markedly improves the performance of MSA under conditions of missing modalities and in tasks requiring effective cross-modal information transfer. Experiments on SEED-IV, SEED-V, and DREAMER confirm that MHLGNE exceeds SOTA MSA models across multiple evaluation metrics, including accuracy, precision, Kappa score, and F1 score, thereby demonstrating its robustness and effectiveness. Future work may focus on refining noise sampling strategies and developing more sophisticated hypergraph structures to further strengthen performance under extreme modality-missing scenarios. In addition, this framework has the potential to be extended to broader sentiment analysis tasks across diverse application domains. -
表 1 实验数据集的统计数据
数据集 训练集 验证集 测试集 总和 受试者 模态/维度 SEED-IV 4250 1836 2041 8127 15(×3) 脑电信号/310(62×5) SEED-V 8234 2106 4102 14632 16(×3) 脑电信号/310(62×5) DREAMER 6048 1416 1835 9299 23(×3) 脑电信号/70(14×5)  下载: 导出CSV
下载: 导出CSV
表 2 在完整模态数据设置下,不同方法在SEED-IV, SEED-V和DREAMER数据集上执行MSA任务的结果
方法 SEED-IV SEED-V DREAMER Acc(%) Pre(%) Kappa(%) Efficiency(ms) Acc(%) Pre(%) Kappa(%) Efficiency(ms) Acc(%) Pre(%) F1(%) Efficiency(ms) BDAE-regressor 73.60 72.93 0.75 12.791 70.03 69.24 0.62 14.302 78.25 79.74 0.72 9.183 BDAE-cGAN 75.72 74.20 0.66 28.684 73.60 73.82 0.61 32.491 80.23 79.93 0.63 20.104 Uni-Code 66.23 61.53 0.62 9.362 50.75 49.67 0.52 10.203 68.17 67.59 0.63 5.402 ECO-FET 70.03 72.34 0.74 49.278 60.07 60.42 0.51 51.361 73.09 75.43 0.73 37.621 CTFN 64.27 64.32 0.71 16.392 62.73 62.56 0.65 19.302 73.48 72.24 0.66 10.451 EMMR 68.16 68.13 0.60 190.350 65.04 64.35 0.68 203.166 71.62 71.27 0.65 182.580 TFR-Net 78.42 74.10 0.76 247.610 76.60 75.31 0.70 249.017 80.23 78.47 0.82 210.096 MAET 77.49 75.02 0.75 392.471 76.53 75.82 0.72 418.712 82.35 80.92 0.78 370.204 CAETFN 82.71 81.90 0.78 529.306 81.93 81.04 0.77 682.173 92.11 91.80 0.83 492.035 HAS-Former 84.36 83.74 0.82 91.025 83.02 82.61 0.78 204.723 92.08 92.85 0.87 83.904 M2S 84.70 85.47 0.83 102.394 82.77 83.52 0.78 172.480 93.74 94.16 0.87 92.480 MEDA 80.42 82.14 0.75 271.103 80.20 80.36 0.74 256.902 85.42 84.29 0.82 219.032 MHLGNE 87.96 86.70 0.89 362.402 85.12 85.40 0.84 375.192 94.32 94.02 0.88 306.271
下载: 导出CSV
表 3 在随机模态信息缺失设置下,不同方法在SEED-IV, SEED-V和DREAMER数据集上执行MSA任务的整体性能比较
方法 SEED-IV SEED-V DREAMER Acc(%) Pre(%) Kappa(%) Efficiency(ms) Acc(%) Pre(%) Kappa(%) Efficiency(ms) Acc(%) Pre(%) F1(%) Efficiency(ms) BDAE-regressor 52.42 51.29 0.50 28.023 48.57 48.13 0.48 67.201 53.30 52.49 0.62 32.503 BDAE-cGAN 50.21 50.13 0.40 37.961 47.31 46.80 0.41 92.280 51.29 51.13 0.60 52.401 Uni-Code 51.86 51.43 0.41 20.274 50.20 48.97 0.41 49.014 58.20 57.90 0.67 28.194 ECO-FET 56.90 55.68 0.51 62.017 53.01 51.24 0.50 90.103 65.90 65.42 0.72 60.209 CTFN 58.71 57.11 0.52 20.420 55.44 53.76 0.50 58.091 68.21 66.20 0.74 42.501 EMMR 64.34 64.23 0.55 186.652 60.12 59.03 0.53 241.320 72.32 71.02 0.82 220.590 TFR-Net 68.20 68.19 0.58 260.726 62.40 60.20 0.57 293.651 74.25 73.97 0.78 248.102 MAET 70.09 70.25 0.60 411.102 61.37 60.82 0.54 453.204 72.45 72.10 0.75 391.472 CAETFN 74.16 73.60 0.62 540.230 64.92 64.15 0.60 729.608 78.03 77.82 0.79 521.070 HAS-Former 73.20 72.98 0.62 122.917 65.08 64.59 0.61 237.502 82.19 82.95 0.80 109.271 M2S 75.49 74.02 0.63 124.103 66.25 65.38 0.62 203.206 85.60 84.20 0.85 100.726 MEDA 71.30 70.84 0.61 291.410 65.42 64.92 0.62 291.352 82.42 81.91 0.78 232.910 MHLGNE 76.52 74.26 0.71 368.504 66.92 65.72 0.63 384.102 84.13 82.92 0.80 312.159
下载: 导出CSV
表 4 MHLGNE模态信息完全缺失的研究分析(%)
方法 SEED-IV SEED-V DREAMER Acc Pre Kappa Acc Pre Kappa Acc Pre F1 脑电信号 77.20 82.46 0.68 77.65 81.49 0.69 83.97 90.53 0.64 视觉信息 75.26 81.14 0.66 74.83 80.10 0.67 82.43 89.14 0.61 文本信息 79.63 83.40 0.73 79.90 82.21 0.72 86.45 91.42 0.68 脑电信号 + 视觉信息 80.76 84.10 0.70 79.20 83.09 0.70 87.96 93.43 0.67 视觉信息 + 文本信息 82.84 85.24 0.75 82.03 84.36 0.73 88.70 92.05 0.71 脑电信号 + 文本信息 84.56 85.42 0.76 83.04 84.75 0.74 90.20 93.61 0.73 全部模态信息(本文) 87.96 86.70 0.89 85.12 85.40 0.84 94.32 94.02 0.88
下载: 导出CSV
表 5 MHLGNE关键组件的消融研究分析(%)
方法 SEED-IV SEED-V DREAMER Acc Pre Kappa Acc Pre Kappa Acc Pre F1 w/o自适应全局噪声采样 82.49 85.92 0.72 80.01 79.85 0.78 87.90 92.73 0.73 w/o多模态超图学习 82.06 84.05 0.72 79.35 78.02 0.77 87.24 90.84 0.71 w/o引导信息传递机制 85.72 86.46 0.74 83.29 85.16 0.79 92.18 93.62 0.76 全部(本文) 87.96 86.70 0.89 85.12 85.40 0.84 94.32 94.02 0.88
下载: 导出CSV
-
[1] 刘佳, 宋泓, 陈大鹏, 等. 非语言信息增强和对比学习的多模态情感分析模型[J]. 电子与信息学报, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274.LIU Jia, SONG Hong, CHEN Dapeng, et al. A multimodal sentiment analysis model enhanced with non-verbal information and contrastive learning[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274. [2] WANG Pan, ZHOU Qiang, WU Yawen, et al. DLF: Disentangled-language-focused multimodal sentiment analysis[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 21180–21188. doi: 10.1609/aaai.v39i20.35416. [3] XU Qinfu, WEI Yiwei, WU Chunlei, et al. Towards multimodal sentiment analysis via hierarchical correlation modeling with semantic distribution constraints[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 21788–21796. doi: 10.1609/aaai.v39i20.35484. [4] XU Xi, LI Jianqiang, ZHU Zhichao, et al. A comprehensive review on synergy of multi-modal data and AI technologies in medical diagnosis[J]. Bioengineering, 2024, 11(3): 219. doi: 10.3390/bioengineering11030219. [5] LIU Huan, LOU Tianyu, ZHANG Yuzhe, et al. EEG-based multimodal emotion recognition: A machine learning perspective[J]. IEEE Transactions on Instrumentation and Measurement, 2024, 73: 4003729. doi: 10.1109/TIM.2024.3369130. [6] ZHAO Xuefeng, WANG Yuxiang, ZHONG Zhaoman. Text-in-image enhanced self-supervised alignment model for aspect-based multimodal sentiment analysis on social media[J]. Sensors, 2025, 25(8): 2553. doi: 10.3390/s25082553. [7] SUN Hao, NIU Ziwei, WANG Hongyi, et al. Multimodal sentiment analysis with mutual information-based disentangled representation learning[J]. IEEE Transactions on Affective Computing, 2025, 16(3): 1606–1617. doi: 10.1109/TAFFC.2025.3529732. [8] ZHAO Sicheng, YANG Zhenhua, SHI Henglin, et al. SDRS: Sentiment-aware disentangled representation shifting for multimodal sentiment analysis[J]. IEEE Transactions on Affective Computing, 2025, 16(3): 1802–1813. doi: 10.1109/TAFFC.2025.3539225. [9] LUO Yuanyi, LIU Wei, SUN Qiang, et al. TriagedMSA: Triaging sentimental disagreement in multimodal sentiment analysis[J]. IEEE Transactions on Affective Computing, 2025, 16(3): 1557–1569. doi: 10.1109/TAFFC.2024.3524789. [10] WANG Yuhao, LIU Yang, ZHENG Aihua, et al. Decoupled feature-based mixture of experts for multi-modal object re-identification[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 8141–8149. doi: 10.1609/aaai.v39i8.32878. [11] WU Sheng, HE Dongxiao, WANG Xiaobao, et al. Enriching multimodal sentiment analysis through textual emotional descriptions of visual-audio content[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 1601–1609. doi: 10.1609/aaai.v39i2.32152. [12] SUN Xin, REN Xiangyu, and XIE Xiaohao. A novel multimodal sentiment analysis model based on gated fusion and multi-task learning[C]. The ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, South Korea, 2024: 8336–8340. doi: 10.1109/ICASSP48485.2024.10446040. [13] LI Meng, ZHU Zhenfang, LI Kefeng, et al. Diversity and balance: Multimodal sentiment analysis using multimodal-prefixed and cross-modal attention[J]. IEEE Transactions on Affective Computing, 2025, 16(1): 250–263. doi: 10.1109/TAFFC.2024.3430045. [14] LIU Zhicheng, BRAYTEE A, ANAISSI A, et al. Ensemble pretrained models for multimodal sentiment analysis using textual and video data fusion[C]. The ACM Web Conference 2024, Singapore, Singapore, 2024: 1841–1848. doi: 10.1145/3589335.3651971. [15] TANG Jiajia, LI Kang, JIN Xuanyu, et al. CTFN: Hierarchical learning for multimodal sentiment analysis using coupled-translation fusion network[C]. The 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (volume 1: Long Papers), 2021: 5301–5311. doi: 10.18653/v1/2021.acl-long.412. [16] ZENG Jiandian, ZHOU Jiantao, and LIU Tianyi. Mitigating inconsistencies in multimodal sentiment analysis under uncertain missing modalities[C]. 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 2022: 2924–2934. doi: 10.18653/v1/2022.emnlp-main.189. [17] LIU Yankai, CAI Jinyu, LU Baoliang, et al. Multi-to-single: Reducing multimodal dependency in emotion recognition through contrastive learning[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 1438–1446. doi: 10.1609/aaai.v39i2.32134. [18] TAO Chuanqi, LI Jiaming, ZANG Tianzi, et al. A multi-focus-driven multi-branch network for robust multimodal sentiment analysis[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 1547–1555. doi: 10.1609/aaai.v39i2.32146. [19] BALTRUŠAITIS T, ROBINSON P, and MORENCY L P. OpenFace: An open source facial behavior analysis toolkit[C]. 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, USA, IEEE, 2016: 1–10. doi: 10.1109/WACV.2016.7477553. [20] LIU Yinhan, OTT M, GOYAL N, et al. RoBERTa: A robustly optimized BERT pretraining approach[EB/OL]. https://arxiv.org/abs/1907.11692, 2019. [21] FANG Feiteng, BAI Yuelin, NI Shiwen, et al. Enhancing noise robustness of retrieval-augmented language models with adaptive adversarial training[C]. The 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 2024: 10028–10039. doi: 10.18653/v1/2024.acl-long.540. [22] CHEN Zhuo, GUO Lingbing, FANG Yin, et al. Rethinking uncertainly missing and ambiguous visual modality in multi-modal entity alignment[C]. The 22nd International Semantic Web Conference on the Semantic Web, Athens, Greece, 2023: 121–139. doi: 10.1007/978-3-031-47240-4_7. [23] GAO Min, ZHENG Haifeng, FENG Xinxin, et al. Multimodal fusion using multi-view domains for data heterogeneity in federated learning[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 16736–16744. doi: 10.1609/aaai.v39i16.33839. [24] ZHOU Yan, FANG Qingkai, and FENG Yang. CMOT: Cross-modal Mixup via optimal transport for speech translation[C]. The 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada, 2023: 7873–7887. doi: 10.18653/v1/2023.acl-long.436. [25] ZHENG Weilong, LIU Wei, LU Yifei, et al. EmotionMeter: A multimodal framework for recognizing human emotions[J]. IEEE Transactions on Cybernetics, 2019, 49(3): 1110–1122. doi: 10.1109/TCYB.2018.2797176. [26] LIU Wei, QIU Jielin, ZHENG Weilong, et al. Comparing recognition performance and robustness of multimodal deep learning models for multimodal emotion recognition[J]. IEEE Transactions on Cognitive and Developmental Systems, 2022, 14(2): 715–729. doi: 10.1109/TCDS.2021.3071170. [27] KATSIGIANNIS S and RAMZAN N. DREAMER: A database for emotion recognition through EEG and ECG signals from wireless low-cost off-the-shelf devices[J]. IEEE Journal of Biomedical and Health Informatics, 2018, 22(1): 98–107. doi: 10.1109/JBHI.2017.2688239. [28] JIANG Huangfei, GUAN Xiya, ZHAO Weiye, et al. Generating multimodal features for emotion classification from eye movement signals[J]. Australian Journal of Intelligent Information Processing Systems, 2019, 15(3): 59–66. [29] YAN Xu, ZHAO Liming, and LU Baoliang. Simplifying multimodal emotion recognition with single eye movement modality[C]. The 29th ACM International Conference on Multimedia, 2021: 1057–1063. doi: 10.1145/3474085.3475701. [30] XIA Yan, HUANG Hai, ZHU Jieming, et al. Achieving cross modal generalization with multimodal unified representation[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2021: 2774. [31] JIANG Weibang, LI Ziyi, ZHENG Weilong, et al. Functional emotion transformer for EEG-assisted cross-modal emotion recognition[C]. The ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024: 1841–1845. doi: 10.1109/ICASSP48485.2024.10446937. [32] YUAN Ziqi, LI Wei, XU Hua, et al. Transformer-based feature reconstruction network for robust multimodal sentiment analysis[C]. The 29th ACM International Conference on Multimedia, 2021: 4400–4407. doi: 10.1145/3474085.3475585. [33] JIANG Weibang, LIU Xuanhao, ZHENG Weilong, et al. Multimodal adaptive emotion transformer with flexible modality inputs on a novel dataset with continuous labels[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 5975–5984. doi: 10.1145/3581783.3613797. [34] LI Jiabao, LIU Ruyi, MIAO Qiguang, et al. CAETFN: Context adaptively enhanced text-guided fusion network for multimodal sentiment analysis[J]. IEEE Transactions on Affective Computing, 2025. doi: 10.1109/TAFFC.2025.3590246. [35] HUANG Jiayang, VONG C M, LI Chen, et al. HSA-former: Hierarchical spatial aggregation transformer for EEG-based emotion recognition[J]. IEEE Transactions on Computational Social Systems, 2025. doi: 10.1109/TCSS.2025.3567298. [36] DENG Jiawen and REN Fuji. Multi-label emotion detection via emotion-specified feature extraction and emotion correlation learning[J]. IEEE Transactions on Affective Computing, 2023, 14(1): 475–486. doi: 10.1109/TAFFC.2020.3034215. -

 下载:
下载:


图(3) / 表(5)
计量
- 文章访问数: 771
- HTML全文浏览量: 367
- PDF下载量: 54
- 被引次数: 0
