

Lightweight AdderNet Circuit Enabled by STT-MRAM In-Memory Absolute Difference Computation
-
摘要: 随着人工智能研究的不断深入,卷积神经网络(Convolutional Neural Networks, CNN)在资源受限环境中的部署需求不断上升。然而,受限于冯·诺依曼架构,CNN加速器随着部署模型深度增加,卷积核逐层堆叠所引发的乘累加运算呈现超线性增长趋势。为此,该文提出一种基于自旋转移矩磁性随机存储器(Spin Transfer Torque-Magnetoresistive Random Access Memory, STT-MRAM)的轻量型加法神经网络(AdderNet)加速电路设计方案。该方案首先将L1范数引入存算一体架构,提出STT-MRAM绝对差值原位计算方法,以轻量级加法取代乘累加运算;其次,设计基于磁阻状态映射的可配置全加器,结合稀疏优化策略,跳过零值参与的冗余逻辑判断;最后,进一步构建支持单周期进位链更新的并行全加器阵列,实现高效的卷积核映射与多核L1范数并行计算。实验结果显示,在CIFAR-10数据集上,该加速器实现90.66%的识别准确率,仅较软件模型下降1.18%,同时在133 MHz频率下达到32.31 GOPS的最大吞吐量与494.56 GOPS/W的峰值能效。Abstract:
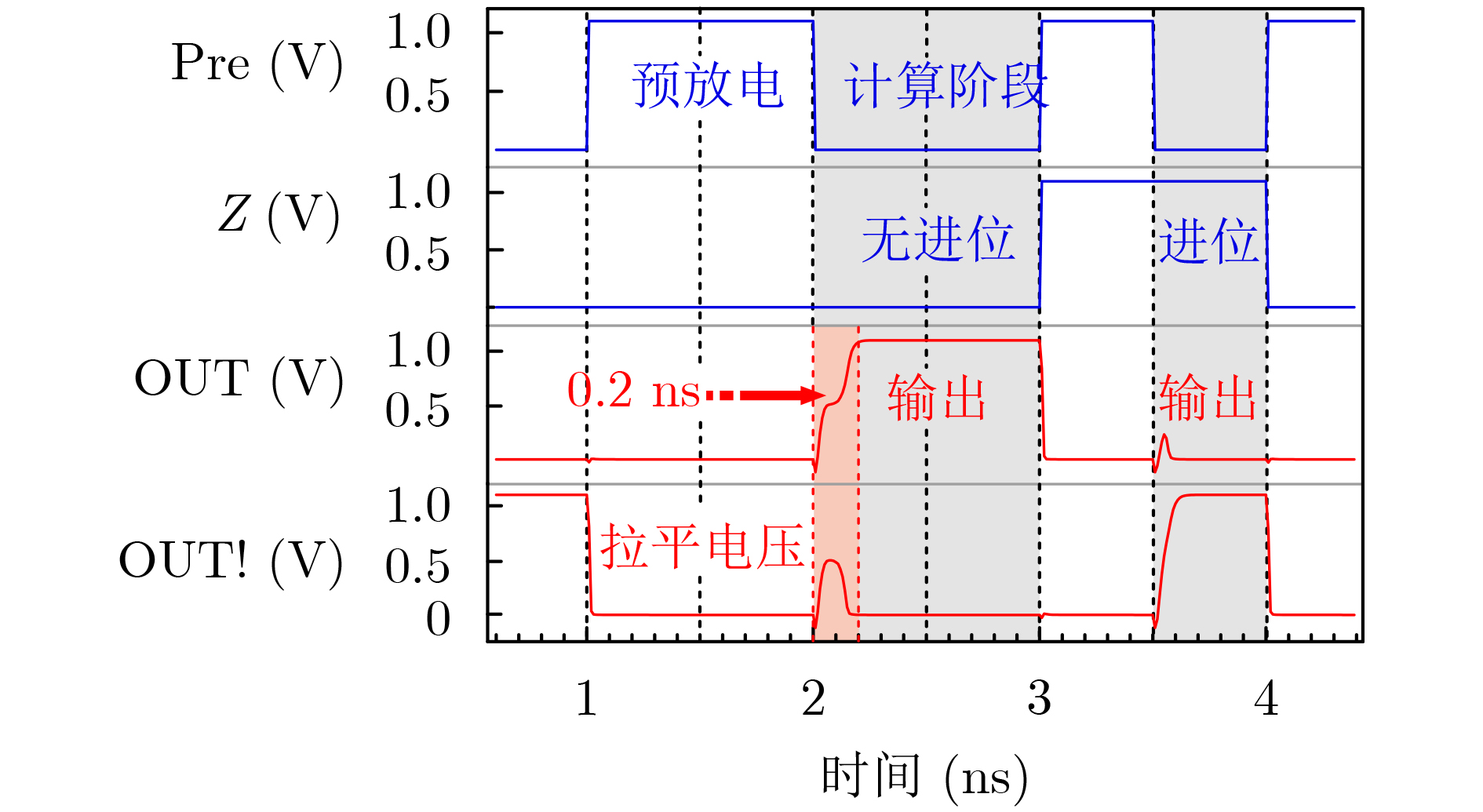
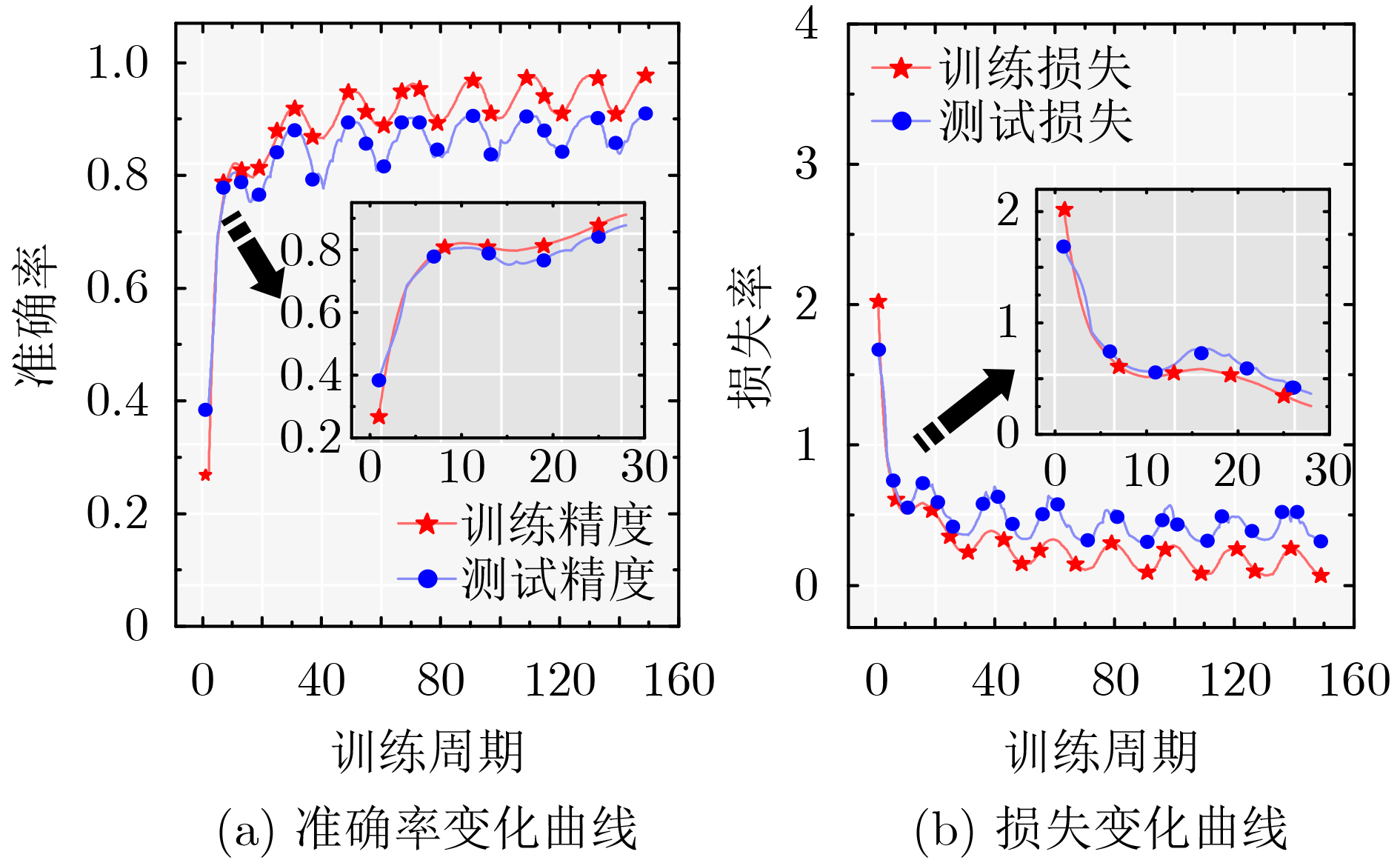
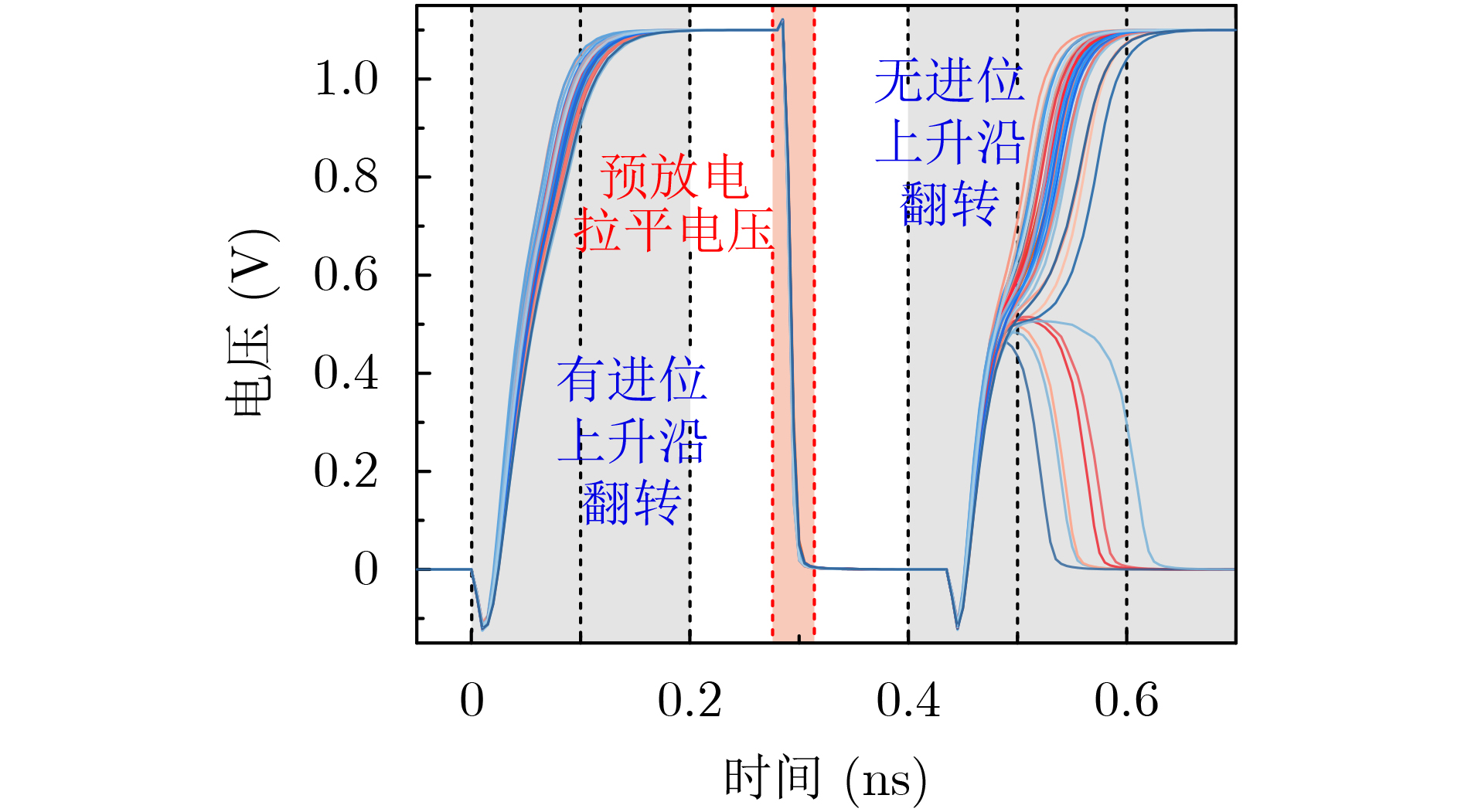
Objective To address the challenges of complex multiply-accumulate operations and high energy consumption in hardware implementations of Convolutional Neural Networks (CNNs), this study proposes a Processing-In-Memory (PIM) AdderNet acceleration architecture based on Spin-Transfer Torque Magnetic Random Access Memory (STT-MRAM), with innovations at the circuit level. Specifically, a novel in-situ absolute difference computation circuit is designed to support L1-norm operations, replacing traditional multipliers and simplifying the data path and computational logic. By leveraging magnetic resistance state mapping, a reconfigurable full-adder unit is developed that enables single-cycle carry-chain updates and multi-mode logic switching, thereby enhancing parallel computing efficiency and energy-performance ratio. Through array-level integration and coordinated control with heterogeneous peripheral circuits, this work establishes a scalable and energy-efficient PIM-based convolutional acceleration system, providing a practical and viable paradigm for deploying deep learning hardware in resource-constrained environments. Methods To achieve energy-efficient acceleration of AdderNet in resource-constrained environments, this study proposes a circuit-level Computing-In-Memory (CIM) architecture based on STT-MRAM. The L1 norm is embedded into the memory array to enable in-situ absolute difference computation, thereby replacing conventional multiply-accumulate operations and simplifying datapath complexity. To reduce redundant operations caused by frequent zero-value interactions in AdderNet, a sparsity-aware computation strategy is implemented, which bypasses invalid operations and lowers dynamic power consumption. A reconfigurable full-adder unit is further designed using magnetoresistive state mapping, supporting single-cycle carry-chain propagation and logic mode switching. These units are integrated into a scalable parallel array structure that performs L1-norm operations efficiently. The architecture is complemented by optimized dataflow control and heterogeneous peripheral circuits, forming a complete low-power AdderNet accelerator. Simulation and hardware-level validations confirm the accuracy, throughput, and energy efficiency of the proposed system under realistic workloads. Results and Discussions Simulation results confirm the effectiveness and efficiency of the proposed MRAM-based AdderNet hardware accelerator under realistic inference workloads. The fabricated full-adder unit supports in-memory computation with dual-mode configurability for both sum and carry operations ( Fig. 2 ,Fig. 3 ). The proposed 1-bit full adder produces correct logical outputs in both modes, with timing waveforms validating reliable switching behavior under a 40 nm CMOS process (Fig. 7 ,Fig. 8 ). The parallel array structure, which integrates multiple MRAM-based full-adder units, enables efficient L1-norm-based convolution through element-wise absolute difference (Fig. 4 ) and maps standard convolution kernels into a format compatible with the proposed architecture (Fig. 5b ). Device-level Monte Carlo simulations reveal tightly distributed resistance states, with coefficients of variation of low-resistance and high-resistance states of approximately 1.1% (CVLRS) and 1.2% (CVHRS), respectively, and a resistance window of ~5349 Ω, ensuring accurate bit-level distinction (Fig. 6 ). The MRAM device also exhibits robust noise margins (NM ≈ 50.5), confirming its suitability for logic-in-memory operations. On the CIFAR-10 dataset, the accelerator achieves a classification accuracy of 90.66%, with only a 1.18% reduction compared with the floating-point software baseline (Fig. 9 ,Fig. 10 ). The final design achieves a peak throughput of 32.31 GOPS and a peak energy efficiency of 494.56 GOPS/W at 133 MHz, exceeding several state-of-the-art designs (Table 2 ).Conclusions To address the high computational complexity and energy consumption of traditional convolutional multiply-accumulate operations, this study proposes an MRAM-based AdderNet hardware accelerator that incorporates L1-norm computation and sparsity optimization strategies. At the circuit level, an in-situ absolute difference computation method based on STT-MRAM is introduced, together with a magnetic resistance state-mapped full-adder circuit that enables fast and configurable carry and sum computations. Building on these units, a scalable parallel full-adder array is constructed to replace multiplications with lightweight additions, and the complete accelerator is implemented with integrated peripheral circuits. Simulation results validate the proposed design. On the same benchmark dataset, the accelerator achieves an accuracy of 90.66% through circuit–algorithm co-optimization, with accuracy degradation limited to 1.18% compared with the software reference model. Although the training process shows periodic local oscillations, the overall convergence trend follows an exponential decay pattern. The architecture ultimately achieves a peak throughput of 32.31 GOPS and a peak energy efficiency of 494.56 GOPS/W at 133 MHz, exceeding conventional approaches in both performance and energy efficiency. -
表 1 多层感知机操作数统计
层别 总操作数 “0”操作数 占比(%) 输入层-隐藏层 1003250000 868548048 86.57 隐藏层-输出层 12800000 6795030 53.08 输入层-输出层 1016320000 875613078 86.16  下载: 导出CSV
下载: 导出CSV
表 2 与相关文献比较结果
i5-1235U
CPU[14]i7-12700H
CPU[14]i5-1235U
iGPU[14]i7-12700H
iGPU[14]ICCAD
2022[15]TCAS-I
2024[13]TCAS-I
2025[16]本文 工艺(nm) 10 10 10 10 N/A 65 N/A 40 电压(V) 1.1-1.3 1.1-1.3 0.9-1.1 0.9-1.1 12(FPGA) 1.2 12(FPGA) 0.6-1.1 单元结构 N/A N/A N/A N/A LUT 2T1M LUT 3T3M 频率(MHz) 4400 4700 1200 1400 200 117 200 133 位宽(bit) 8 8 8 8 8 8 6 8 功耗(mW) 5500 11500 1200 1650 1695 63.82 381 65.33 网络模型 ResNet-50 ResNet-50 ResNet-50 ResNet-50 ResNet-20 VGG-8 ResNet-20 ResNet-20 数据集 N/A N/A N/A N/A CIFAR-10 CIFAR-10 CIFAR-10 CIFAR-10 准确率(%) N/A N/A N/A N/A 89.9% 93.72% 90.52% 90.66% 最大吞吐量
(GOPS)151.18 424 200.32 360.49 214.6 20.93 12.08/kLUT 32.31 能效
(GOPS/W)27.48 2.6 166.9 218.48 126.6 246.68 562.5 494.56
下载: 导出CSV
-
[1] QI Haoran, QIU Yuwei, LUO Xing, et al. An efficient latent style guided transformer-CNN framework for face super-resolution[J]. IEEE Transactions on Multimedia, 2024, 26: 1589–1599. doi: 10.1109/TMM.2023.3283856. [2] 陈晓雷, 王兴, 张学功, 等. 面向360度全景图像显著目标检测的相邻协调网络[J]. 电子与信息学报, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502.CHEN Xiaolei, WANG Xing, ZHANG Xuegong, et al. Adjacent coordination network for salient object detection in 360 degree omnidirectional images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502. [3] 李沫谦, 杨陟卓, 李茹, 等. 基于多尺度卷积的阅读理解候选句抽取[J]. 中文信息学报, 2024, 38(8): 128–139,157. doi: 10.3969/j.issn.1003-0077.2024.08.015.LI Moqian, YANG Zhizhuo, LI Ru, et al. Evidence sentence extraction for reading comprehension based on multi-scale convolution[J]. Journal of Chinese Information Processing, 2024, 38(8): 128–139,157. doi: 10.3969/j.issn.1003-0077.2024.08.015. [4] LU Ye, XIE Kunpeng, XU Guanbin, et al. MTFC: A multi-GPU training framework for cube-CNN-based hyperspectral image classification[J]. IEEE Transactions on Emerging Topics in Computing, 2021, 9(4): 1738–1752. doi: 10.1109/TETC.2020.3016978. [5] HONG H, CHOI D, KIM N, et al. Mobile-X: Dedicated FPGA implementation of the MobileNet accelerator optimizing depthwise separable convolution[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2024, 71(11): 4668–4672. doi: 10.1109/TCSII.2024.3440884. [6] MUN H G, MOON S, KIM B, et al. Bottleneck-stationary compact model accelerator with reduced requirement on memory bandwidth for edge applications[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2023, 70(2): 772–782. doi: 10.1109/TCSI.2022.3222862. [7] WANG Tianyu, SHEN Zhaoyan, and SHAO Zili. CNN acceleration with joint optimization of practical PIM and GPU on embedded devices[C]. IEEE 40th International Conference on Computer Design (ICCD), Olympic Valley, CA, USA, 2022: 377–384. doi: 10.1109/ICCD56317.2022.00062. [8] BLOTT M, PREUßER T B, FRASER N J, et al. FINN-R: An end-to-end deep-learning framework for fast exploration of quantized neural networks[J]. ACM Transactions on Reconfigurable Technology and Systems, 2018, 11(3): 16. doi: 10.1145/3242897. [9] CONTI F, PAULIN G, GAROFALO A, et al. Marsellus: A heterogeneous RISC-V AI-IoT end-node SoC with 2–8 b DNN acceleration and 30%-boost adaptive body biasing[J]. IEEE Journal of Solid-State Circuits, 2024, 59(1): 128–142. doi: 10.1109/JSSC.2023.3318301. [10] CHEN Hanting, WANG Yunhe, XU Chunjing, et al. AdderNet: Do we really need multiplications in deep learning?[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 1465–1474. doi: 10.1109/CVPR42600.2020.00154. [11] ZHANG Heng, HE Sunan, LU Xin, et al. SSM-CIM: An efficient CIM macro featuring single-step multi-bit MAC computation for CNN edge inference[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2023, 70(11): 4357–4368. doi: 10.1109/TCSI.2023.3301814. [12] 永若雪, 姜岩峰. 关于3D堆叠MRAM热学分析方法的研究[J]. 电子学报, 2023, 51(10): 2775–2782. doi: 10.12263/DZXB.20220275.YONG Ruoxue and JIANG Yanfeng. Research on thermal analysis method of 3D-stacked MRAM[J]. Acta Electronica Sinica, 2023, 51(10): 2775–2782. doi: 10.12263/DZXB.20220275. [13] LUO Lichuan, DENG Erya, LIU Dijun, et al. CiTST-AdderNets: Computing in toggle spin torques MRAM for energy-efficient AdderNets[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2024, 71(3): 1130–1143. doi: 10.1109/TCSI.2023.3343081. [14] OpenVINO. OpenVINO 2025.3[EB/OL]. https://docs.openvino.ai/2025/index.html, 2025. [15] ZHANG Yunxiang, SUN Biao, JIANG Weixiong, et al. WSQ-AdderNet: Efficient weight standardization based quantized AdderNet FPGA accelerator design with high-density INT8 DSP-LUT co-packing optimization[C]. IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Diego, USA, 2022: 1–9. [16] ZHANG Yunxiang, AL KAILANI O, ZHOU Bin, et al. AdderNet 2.0: Optimal addernet accelerator designs with activation-oriented quantization and fused bias removal-based memory optimization[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2025. doi: 10.1109/TCSI.2025.3539912. -

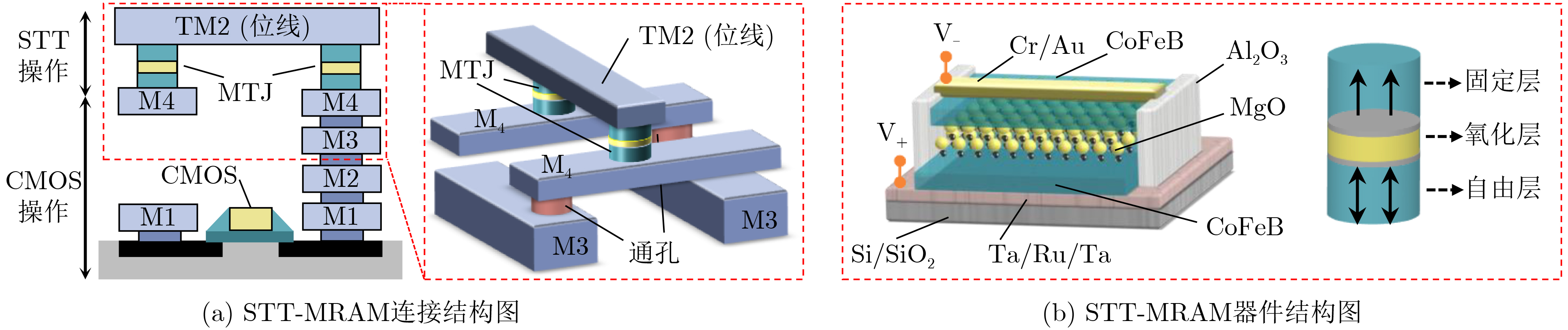
 下载:
下载:

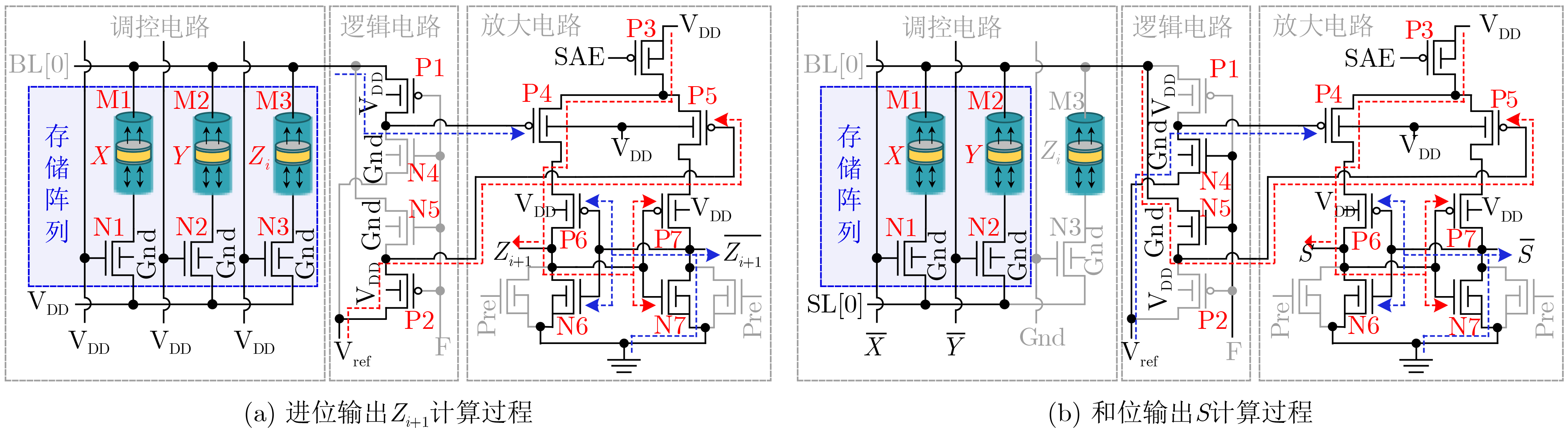
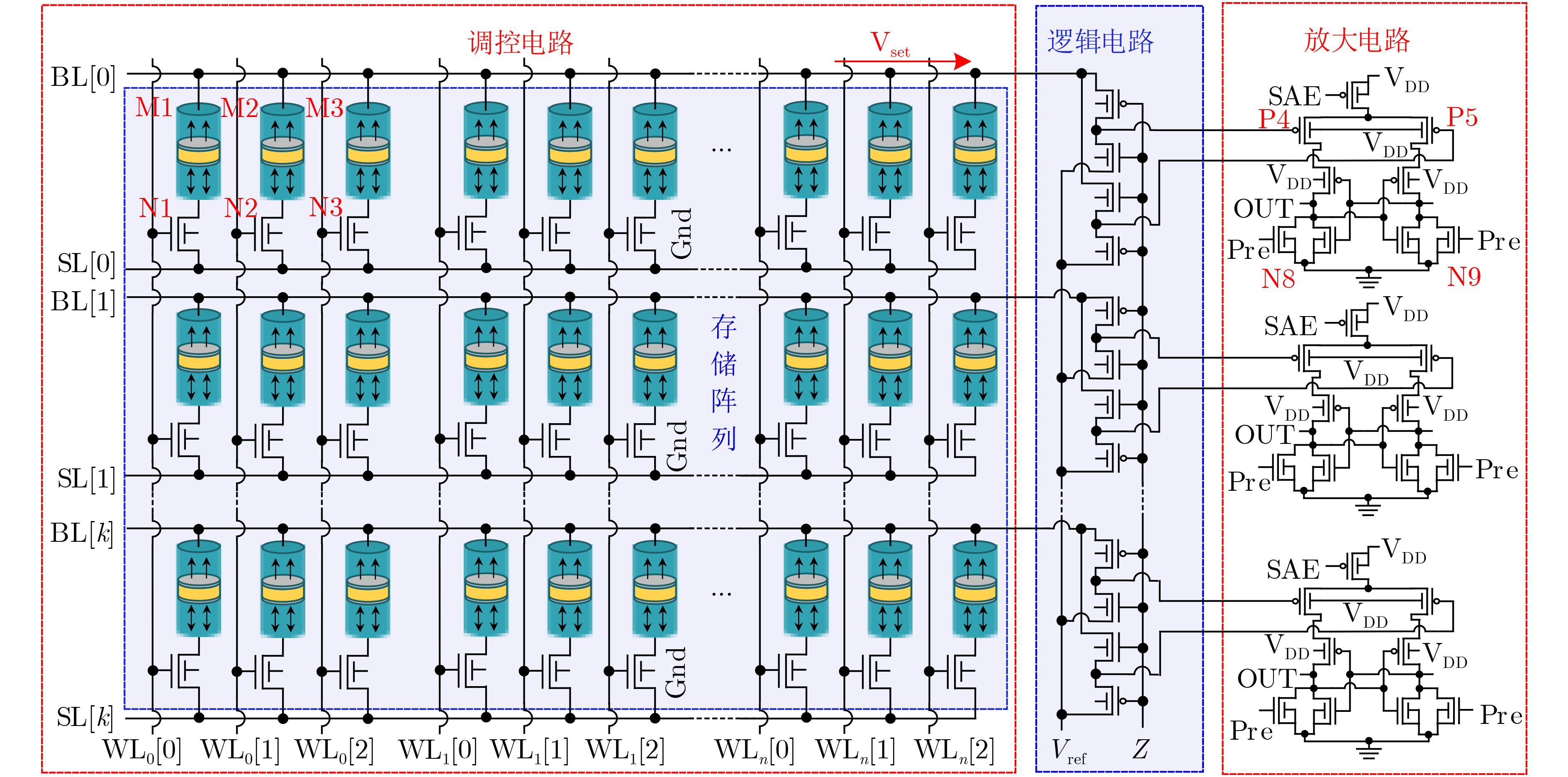


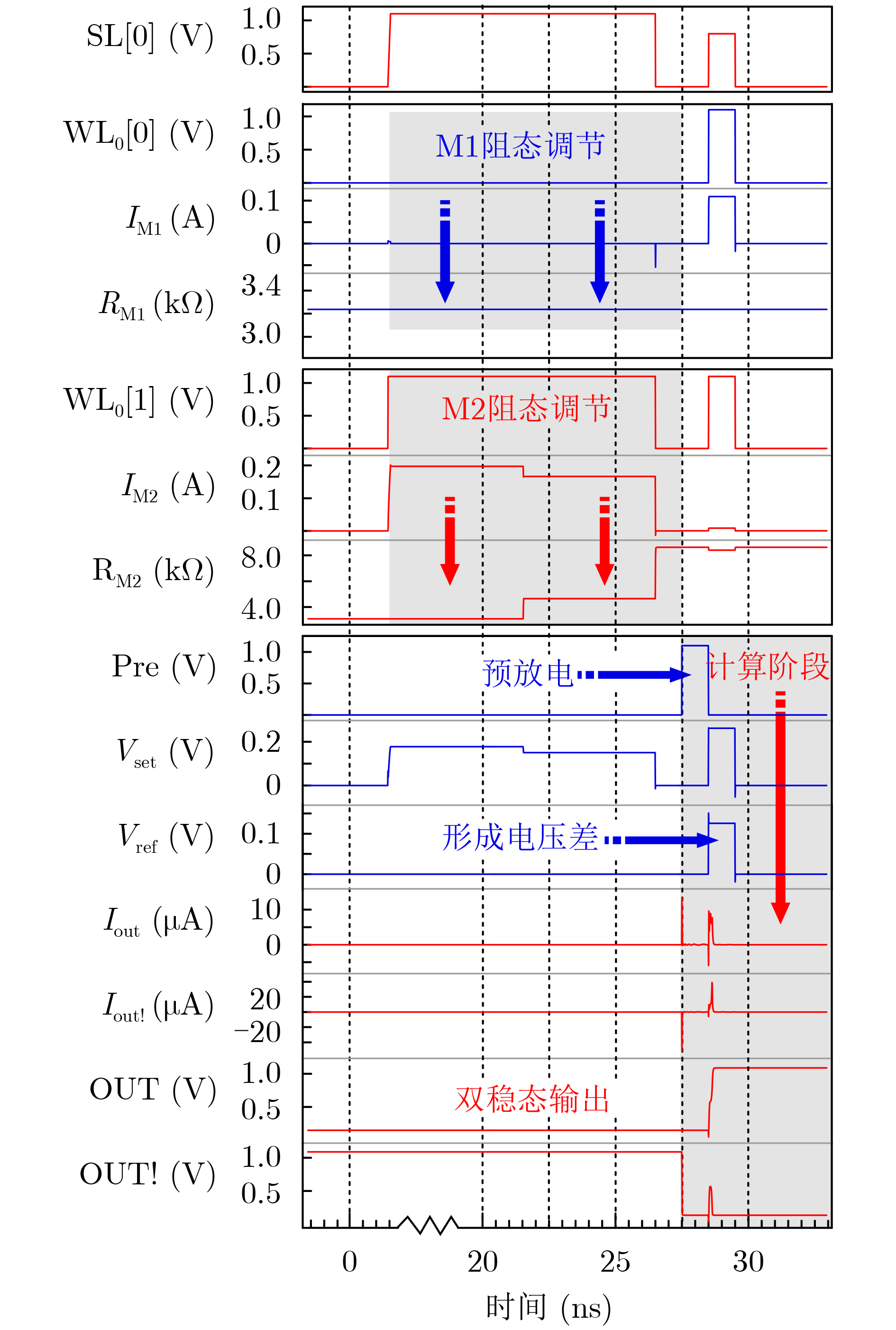



图(11) / 表(2)
计量
- 文章访问数: 517
- HTML全文浏览量: 345
- PDF下载量: 33
- 被引次数: 0
