

A Lightweight Semantic Visual Simultaneous Localization and Mapping Framework for Inspection Robots in Dynamic Environments
-
摘要: 为提升巡检机器人在城市动态环境中的定位精度与鲁棒性,该文提出一种基于第3代定向快速与旋转简要同步定位与建图系统 (ORB-SLAM3)的轻量级语义视觉同步定位与建图(SLAM)框架。该框架通过紧耦合所提出的轻量级语义分割模型(DHSR-YOLOSeg)输出的语义信息,实现动态特征点的精准剔除与稳健跟踪,从而有效缓解动态目标干扰带来的特征漂移与建图误差累积问题。DHSR-YOLOSeg基于YOLO第11代轻量级分割模型(YOLOv11n-seg)架构,融合动态卷积模块(C3k2_DynamicConv)、轻量特征融合模块(DyCANet)与复用共享卷积分割(RSCS)头,在分割精度小幅提升的同时,有效降低了计算资源开销,整体展现出良好的轻量化与高效性。在COCO数据集上,相较于基础模型,DHSR-YOLOSeg实现参数量减少13.8%、109次浮点运算(GFLOPs)降低23.1%、平均精度指标(mAP50)提升约2%;在KITTI数据集上,DHSR-YOLOSeg相比其他主流分割模型及YOLO系列不同版本,在保持较高分割精度的同时,进一步压缩了模型参数量与计算开销,系统整体帧率得到有效提升。同时,所提语义SLAM系统通过动态特征点剔除有效提升了定位精度,平均轨迹误差相比ORB-SLAM3降低8.78%;在此基础上,系统平均每帧处理时间较主流方法如DS-SLAM和DynaSLAM分别降低约18.55%与41.83%。研究结果表明,该语义视觉SLAM框架兼具实时性与部署效率,显著提升了动态环境下的定位稳定性与感知能力。Abstract:
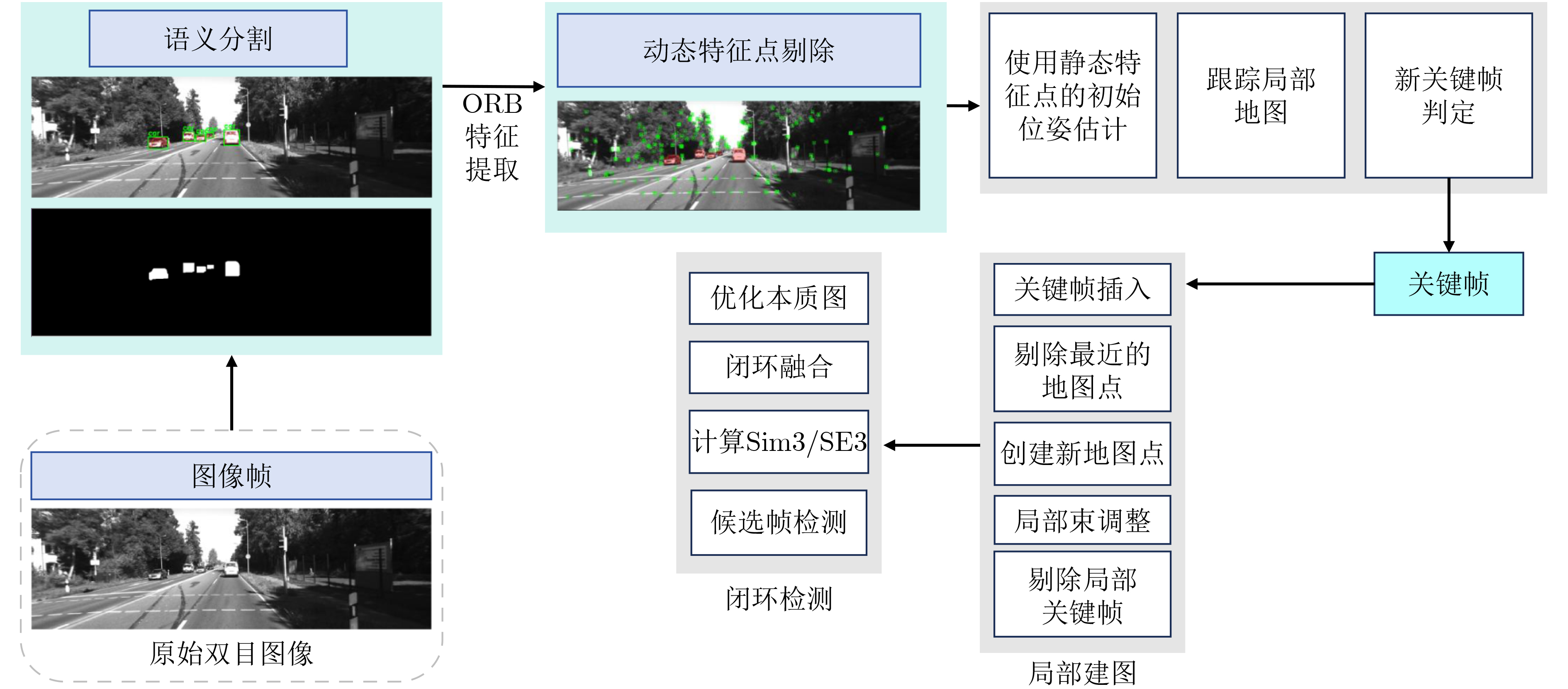
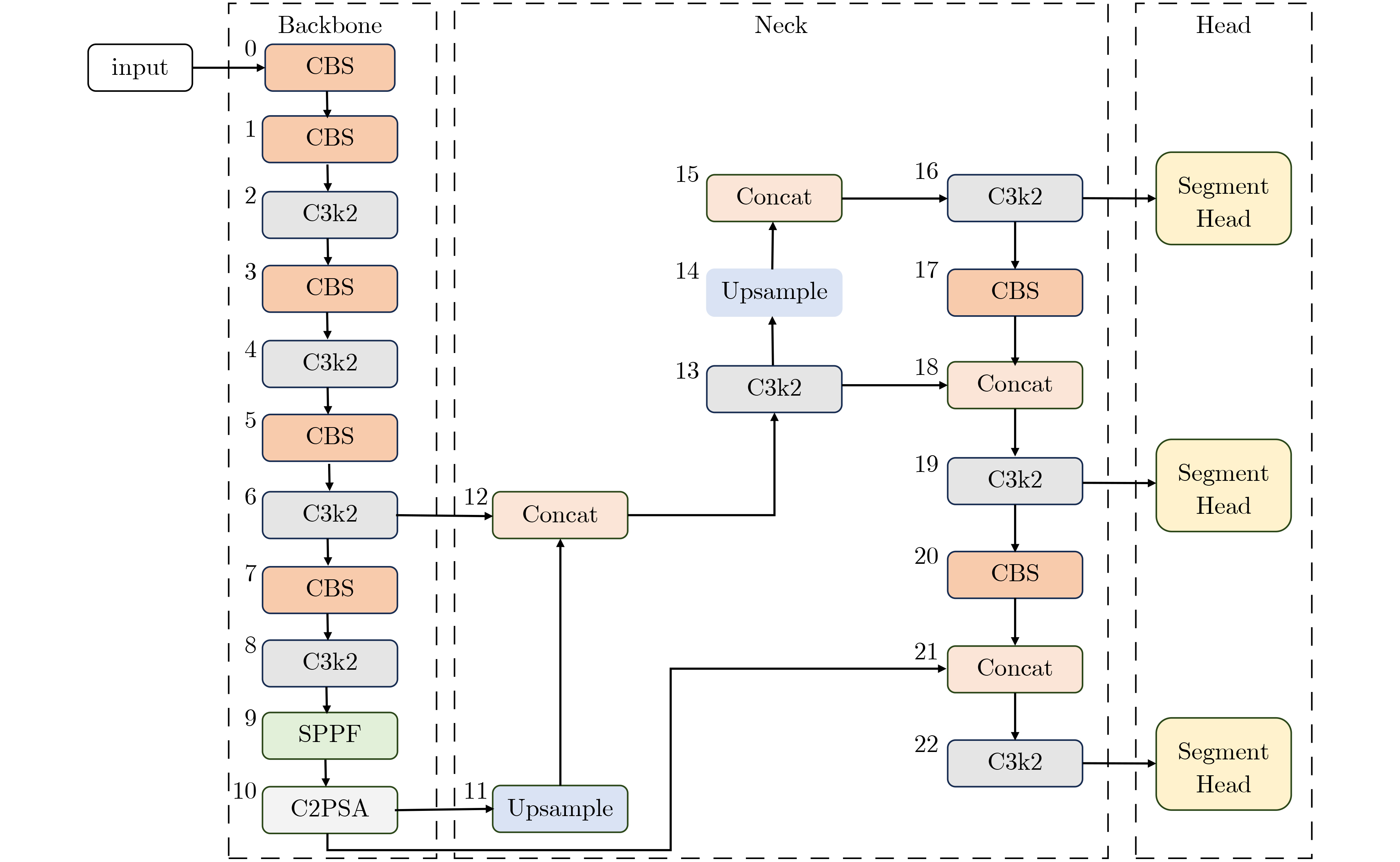
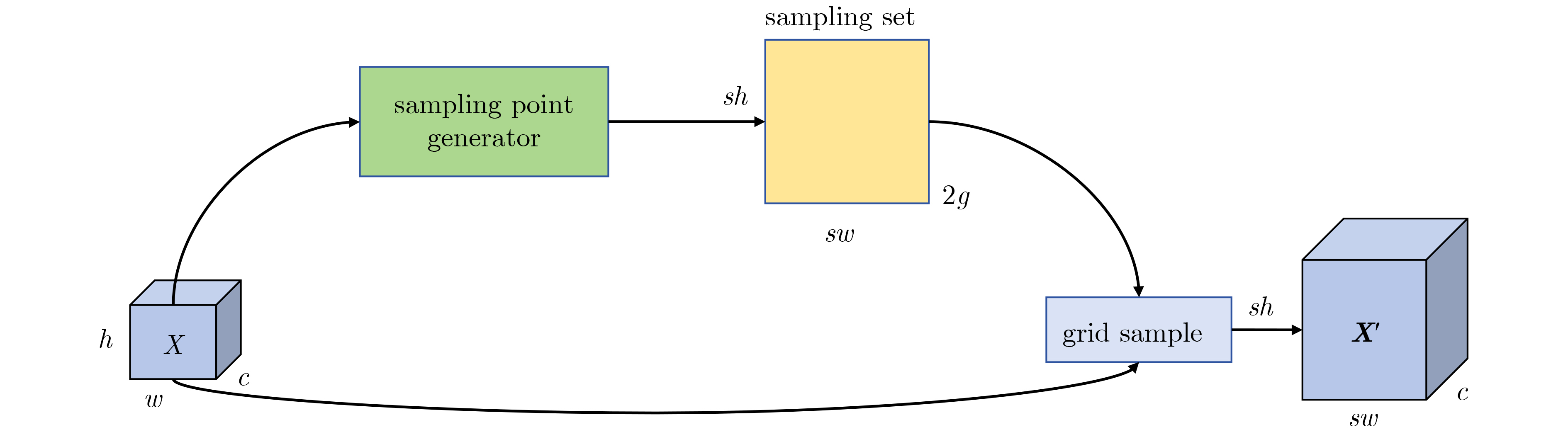
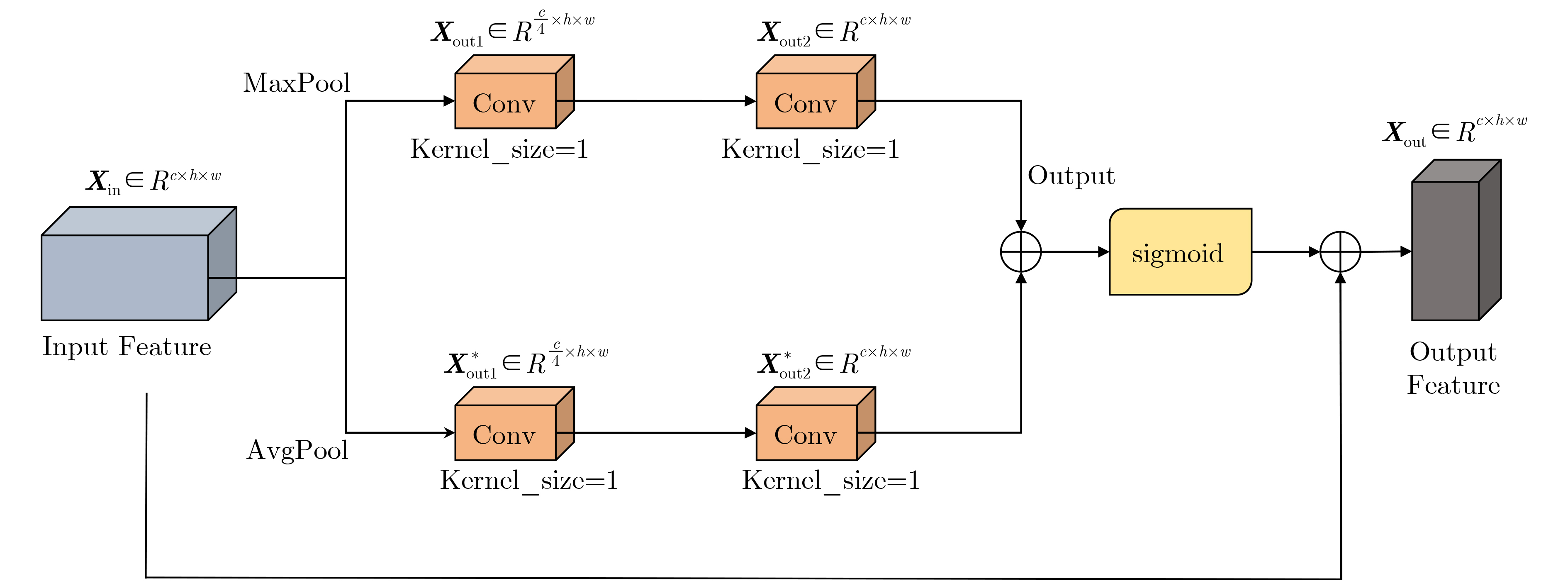
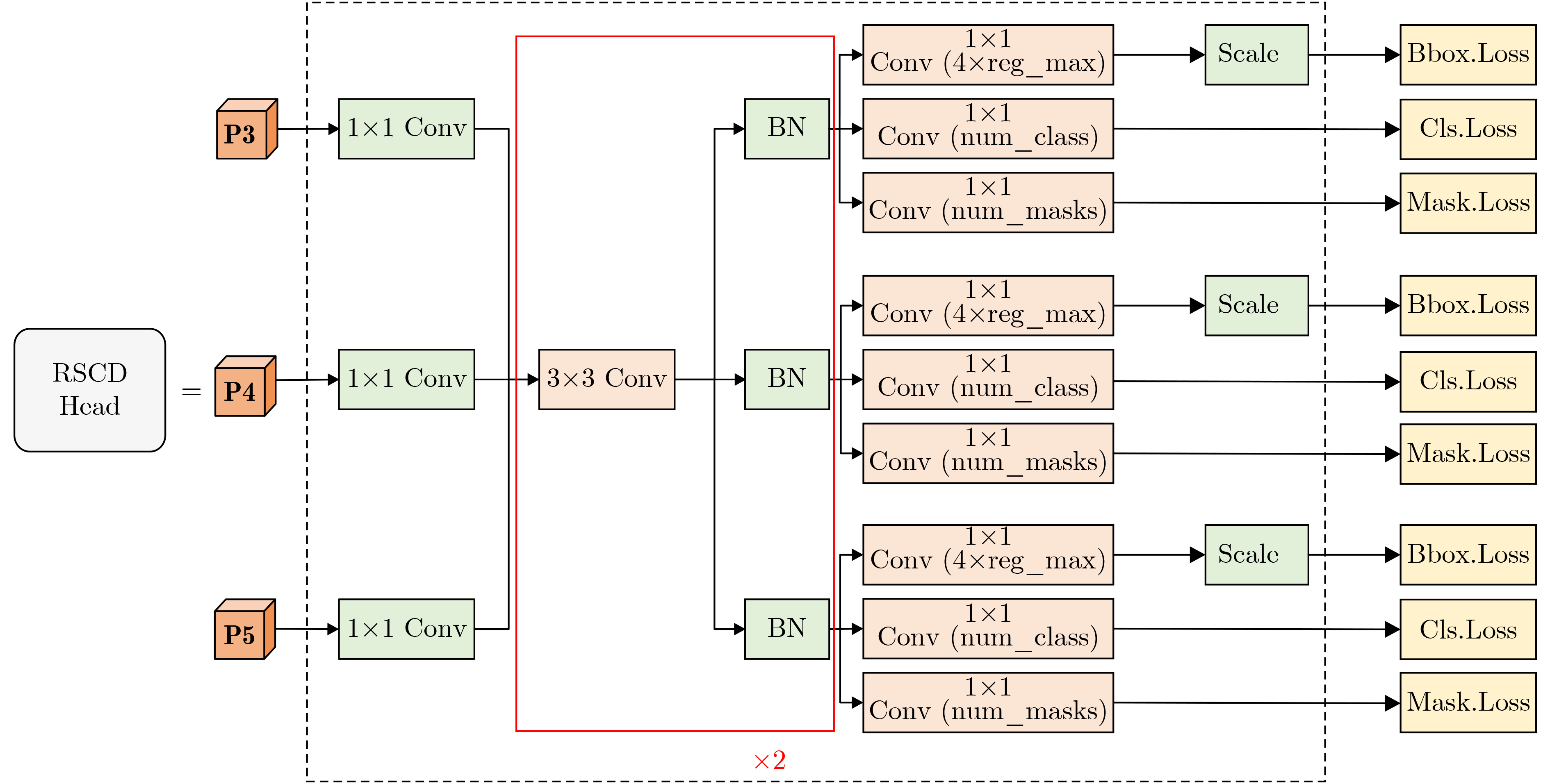
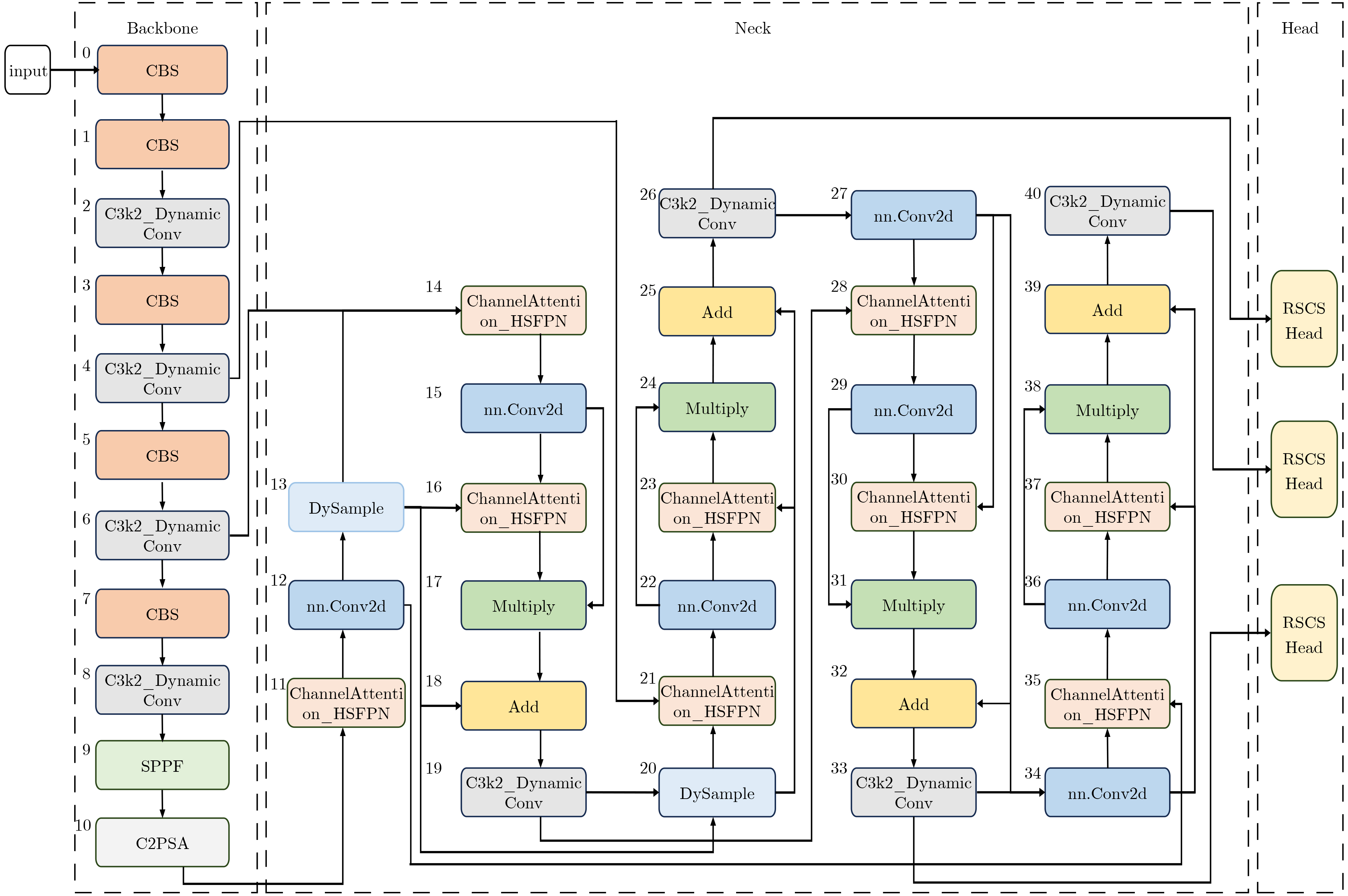
Objective In complex dynamic environments such as industrial parks and urban roads, inspection robots depend heavily on visual Simultaneous Localization And Mapping (SLAM) systems. However, the presence of moving objects often causes feature drift and map degradation, reducing SLAM performance. Furthermore, conventional semantic segmentation models typically require extensive computational resources, rendering them unsuitable for embedded platforms with limited processing capabilities, thereby constraining SLAM deployment in autonomous inspection tasks. To address these challenges, this study proposes a lightweight semantic visual SLAM framework designed for inspection robots operating in dynamic environments. The framework incorporates a semantic segmentation-based dynamic feature rejection method to achieve real-time identification of dynamic regions at low computational cost, thereby improving SLAM robustness and mapping accuracy. Methods Building upon the 11th generation lightweight YOLO segmentation model (YOLOv11n-seg), a systematic lightweight redesign is implemented. to enhance performance under constrained computational resources. First, the original neck is replaced with DyCANet, a lightweight multi-scale feature fusion module that integrates dynamic point sampling and channel attention to improve semantic representation and boundary segmentation. DyCANet combines DySample, a dynamic upsampling operator that performs content-aware spatial sampling with minimal overhead, and ChannelAttention_HSFPN, a hierarchical attention structure that strengthens multi-scale integration and highlights critical semantic cues, particularly for small or occluded objects in complex scenes. Second, a Dynamic Convolution module (DynamicConv) is embedded into all C3k2 modules to enhance the adaptability and efficiency of feature extraction. Inspired by the Mixture-of-Experts framework, DynamicConv applies a conditional computation mechanism that dynamically adjusts kernel weights based on the input feature characteristics. This design allows the network to extract features more effectively across varying object scales and motion patterns, improving robustness against dynamic disturbances with low computational cost. Third, the original segmentation head is replaced by the Reused and Shared Convolutional Segmentation Head (RSCS Head), which enables decoder structure sharing across multi-scale branches. RSCS reduces redundant computation by reusing convolutional layers and optimizing feature decoding paths, further improving overall model efficiency while maintaining segmentation accuracy. These architectural modifications result in DHSR-YOLOSeg, a lightweight semantic segmentation model that significantly reduces parameter count and computational cost while preserving performance. DHSR-YOLOSeg is integrated into the tracking thread of ORB-SLAM3. to provide real-time semantic information. This enables dynamic object detection and the removal of unstable feature points during localization, thereby enhancing the robustness and trajectory consistency of SLAM in complex dynamic environments. Results and Discussions Ablation experiments on the COCO dataset demonstrate that, compared with the baseline YOLOv11n-seg, the proposed DHSR-YOLOSeg achieves a 13.8% reduction in parameter count, a 23.1% decrease in Giga Floating Point Operations (GFLOPs), and its Average Precision at IoU 0.5 (mAP50) is the sameas the baseline YOLOv11n-seg’s ( Table 1 ). On the KITTI dataset, DHSR-YOLOSeg reaches an inference speed of 60.19 frame/s, which is 2.14% faster than YOLOv11n-seg and 275% faster than the widely used Mask R-CNN (Table 2 ). For trajectory accuracy evaluation on KITTI sequences 00~10, DHSR-YOLOSeg outperforms ORB-SLAM3 in 8 out of 10 sequences, achieving a maximum Root Mean Square Error (RMSE) reduction of 16.76% and an average reduction of 8.78% (Table 3 ). Compared with DynaSLAM and DS-SLAM, the proposed framework exhibits more consistent error suppression across sequences, improving both trajectory accuracy and stability. In terms of runtime efficiency, DHSR-YOLOSeg achieves an average per-frame processing time of 48.86 ms on the KITTI dataset, 18.55% and 41.38% lower than DS-SLAM and DynaSLAM, respectively (Table 4 ). The per-sequence processing time ranges from 41 to 55 ms, which is comparable to the 35.64 ms of ORB-SLAM3, indicating that the integration of semantic segmentation introduces only a modest computational overhead.Conclusions This study addresses the challenge of achieving robust localization for inspection robots operating in dynamic environments, particularly in urban road settings characterized by frequent interference from pedestrians, vehicles, and other moving objects. To this end, a semantic-enhanced visual SLAM framework is proposed, in which a lightweight semantic segmentation model, DHSR-YOLOSeg, is integrated into the stereo-based ORB-SLAM3 pipeline. This integration enables real-time identification of dynamic objects and removal of their associated feature points, thereby improving localization robustness and trajectory consistency. The DHSR-YOLOSeg model incorporates three key architectural components—DyCANet for feature fusion, DynamicConv for adaptive convolution, and the RSCS Head for efficient multi-scale decoding. Together, these components reduce the model’s size and computational cost while preserving segmentation performance, providing an efficient and deployable perception solution for resource-constrained platforms. Experimental findings show that: (1) ablation tests on the COCO dataset confirm substantial reductions in complexity with preserved accuracy, supporting embedded deployment; (2) frame rate comparisons on the KITTI dataset demonstrate superior performance over both lightweight and standard semantic segmentation methods, meeting real-time SLAM requirements; (3) trajectory evaluations indicate that the dynamic feature rejection strategy effectively mitigates localization errors in dynamic scenes; and (4) the overall system maintains high runtime efficiency, ensuring a practical balance between semantic segmentation and real-time localization performance. However, current experiments are conducted under ideal conditions using standardized datasets, without fully reflecting real-world challenges such as multi-sensor interference or unstructured environments. Moreover, the trade-offs between model complexity and accuracy for each lightweight module have not been systematically assessed. Future work will focus on multimodal sensor fusion and adaptive dynamic perception strategies to enhance the robustness and applicability of the proposed system in real-world autonomous inspection scenarios. -
表 1 消融实验结果
实验序号 模块1 模块2 模块3 参数量(M) GFLOPs 模型大小 准确率 mAP50 基准模型 × × × 2.83 10.40 6.00 0.76 0.51 1 √ × × 3.71 10.00 7.80 076 0.52 2 × √ × 2.08 9.00 4.50 0.75 0.50 3 × × √ 2.58 9.10 7.00 0.76 0.51 4 √ √ × 2.63 8.90 5.60 0.76 0.51 5 √ × √ 3.44 8.90 8.70 0.75 0.52 6 × √ √ 1.89 8.10 4.60 0.73 0.49 7 √ √ √ 2.44 8.00 5.70 0.77 0.51  下载: 导出CSV
下载: 导出CSV
表 2 对比实验结果
模型 参数量(M) GFLOPs mAP50 推理帧率(帧/s) Mask R-CNN 35.92 67.16 0.47 16.05 YOLOv5n-seg 2.05 4.31 0.48 57.89 YOLOv8n-seg 3.26 6.78 0.50 56.51 YOLOv11n-seg 2.84 5.18 0.50 58.93 DHSR-YOLOSeg 1.45 4.49 0.51 60.19
下载: 导出CSV
表 3 不同语义SLAM方法在KITTI序列上的轨迹RMSE误差对比(m)
序列 ORB-SLAM3 DynaSLAM DS-SLAM 本文 00 1.490 1.009 1.249 1.296 01 13.319 17.471 15.395 12.873 02 4.241 4.492 4.166 3.531 04 0.273 0.254 0.261 0.244 05 0.994 0.833 0.924 0.947 06 1.121 0.716 1.219 1.162 07 0.630 0.658 0.644 0.534 08 3.517 2.475 3.973 3.466 09 1.697 1.261 1.779 1.715 10 1.046 0.752 1.026 0.993
下载: 导出CSV
表 4 不同语义SLAM方法平均每帧跟踪处理时间对比(ms)
序列 ORB-SLAM3 DynaSLAM DS-SLAM 本文 00 36.25 84.91 64.75 44.27 01 33.47 78.78 57.08 41.90 02 37.07 86.71 61.86 50.63 04 36.01 84.38 57.38 52.27 05 36.71 85.92 59.37 50.11 06 36.74 85.99 61.09 48.45 07 35.23 82.66 59.89 48.95 08 36.90 86.34 63.92 54.76 09 35.37 82.97 58.18 50.62 10 34.61 81.29 56.37 46.69
下载: 导出CSV
-
[1] HALDER S and AFSARI K. Robots in inspection and monitoring of buildings and infrastructure: A systematic review[J]. Applied Sciences, 2023, 13(4): 2304. doi: 10.3390/app13042304. [2] LI Yuhao, FU Chengguo, YANG Hui, et al. Design of a closed piggery environmental monitoring and control system based on a track inspection robot[J]. Agriculture, 2023, 13(8): 1501. doi: 10.3390/agriculture13081501. [3] 罗朝阳, 张荣芬, 刘宇红, 等. 自动驾驶场景下的行人意图语义VSLAM[J]. 计算机工程与应用, 2024, 60(17): 107–116. doi: 10.3778/j.issn.1002-8331.2306-0159.LUO Zhaoyang, ZHANG Rongfen, LIU Yuhong, et al. Pedestrian intent semantic VSLAM in automatic driving scenarios[J]. Computer Engineering and Applications, 2024, 60(17): 107–116. doi: 10.3778/j.issn.1002-8331.2306-0159. [4] 李国逢, 谈嵘, 曹媛媛. 手持SLAM: 城市测量的新方法与实践[J]. 测绘通报, 2024(S2): 255–259. doi: 10.13474/j.cnki.11-2246.2024.S253.LI Guofeng, TAN Rong, and CAO Yuanyuan. Handheld SLAM: Emerging techniques and practical implementations in urban surveying[J]. Bulletin of Surveying and Mapping, 2024(S2): 255–259. doi: 10.13474/j.cnki.11-2246.2024.S253. [5] ZHANG Tianzhe and DAI Jun. Electric power intelligent inspection robot: A review[J]. Journal of Physics: Conference Series, 2021, 1750(1): 012023. doi: 10.1088/1742-6596/1750/1/012023. [6] MUR-ARTAL R, MONTIEL J M M, and TARDÓS J D. ORB-SLAM: A versatile and accurate monocular SLAM system[J]. IEEE Transactions on Robotics, 2015, 31(5): 1147–1163. doi: 10.1109/TRO.2015.2463671. [7] MUR-ARTAL R and TARDÓS J D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255–1262. doi: 10.1109/TRO.2017.2705103. [8] CAMPOS C, ELVIRA R, RODRÍGUEZ J J G, et al. ORB-SLAM3: An accurate open-source library for visual, visual–inertial, and multimap SLAM[J]. IEEE Transactions on Robotics, 2021, 37(6): 1874–1890. doi: 10.1109/TRO.2021.3075644. [9] QIN Tong, LI Peiliang, and SHEN Shaojie. VINS-Mono: A robust and versatile monocular visual-inertial state estimator[J]. IEEE Transactions on Robotics, 2018, 34(4): 1004–1020. doi: 10.1109/TRO.2018.2853729. [10] ZANG Qiuyu, ZHANG Kehua, WANG Ling, et al. An adaptive ORB-SLAM3 system for outdoor dynamic environments[J]. Sensors, 2023, 23(3): 1359. doi: 10.3390/s23031359. [11] WU Hangbin, ZHAN Shihao, SHAO Xiaohang, et al. SLG-SLAM: An integrated SLAM framework to improve accuracy using semantic information, laser and GNSS data[J]. International Journal of Applied Earth Observation and Geoinformation, 2024, 133: 104110. doi: 10.1016/j.jag.2024.104110. [12] BESCOS B, FÁCIL J M, CIVERA J, et al. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 4076–4083. doi: 10.1109/LRA.2018.2860039. [13] VINCENT J, LABBÉ M, LAUZON J S, et al. Dynamic object tracking and masking for visual SLAM[C]. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, USA, 2020: 4974–4979. doi: 10.1109/IROS45743.2020.9340958. [14] KHANAM R and HUSSAIN M. YOLOv11: An overview of the key architectural enhancements[EB/OL]. https://arxiv.org/abs/2410.17725, 2024. [15] XU Ziheng, NIU Jianwei, LI Qingfeng, et al. NID-SLAM: Neural implicit representation-based RGB-D SLAM in dynamic environments[C]. 2024 IEEE International Conference on Multimedia and Expo (ICME), Niagara Falls, Canada, 2024: 1–6. doi: 10.1109/ICME57554.2024.10687512. [16] GONG Can, SUN Ying, ZOU Chunlong, et al. Real-time visual SLAM based YOLO-fastest for dynamic scenes[J]. Measurement Science and Technology, 2024, 35(5): 056305. doi: 10.1088/1361-6501/ad2669. [17] WU Peiyi, TONG Pengfei, ZHOU Xin, et al. Dyn-DarkSLAM: YOLO-based visual SLAM in low-light conditions[C]. 2024 IEEE 25th China Conference on System Simulation Technology and its Application (CCSSTA), Tianjin, China, 2024: 346–351. doi: 10.1109/CCSSTA62096.2024.10691775. [18] ZHANG Ruidong and ZHANG Xinguang. Geometric constraint-based and improved YOLOv5 semantic SLAM for dynamic scenes[J]. ISPRS International Journal of Geo-Information, 2023, 12(6): 211. doi: 10.3390/ijgi12060211. [19] YANG Tingting, JIA Shuwen, YU Ying, et al. Enhancing visual SLAM in dynamic environments with improved YOLOv8[C]. The Sixteenth International Conference on Digital Image Processing (ICDIP), Haikou, China, 2024: 132741Y. doi: 10.1117/12.3037734. [20] HAN Kai, WANG Yunhe, GUO Jianyuan, et al. ParameterNet: Parameters are all you need for large-scale visual pretraining of mobile networks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 15751–15761. doi: 10.1109/CVPR52733.2024.01491. [21] YU Jiazuo, ZHUGE Yunzhi, ZHANG Lu, et al. Boosting continual learning of vision-language models via mixture-of-experts adapters[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 23219–23230. doi: 10.1109/CVPR52733.2024.02191. [22] LIU Wenze, LU Hao, FU Hongtao, et al. Learning to upsample by learning to sample[C]. The IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 6004–6014. doi: 10.1109/ICCV51070.2023.00554. [23] HUANGFU Yi, HUANG Zhonghao, YANG Xiaogang, et al. HHS-RT-DETR: A method for the detection of citrus greening disease[J]. Agronomy, 2024, 14(12): 2900. doi: 10.3390/agronomy14122900. [24] CAO Qi, CHEN Hang, WANG Shang, et al. LH-YOLO: A lightweight and high-precision SAR ship detection model based on the improved YOLOv8n[J]. Remote Sensing, 2024, 16(22): 4340. doi: 10.3390/rs16224340. [25] YU Chao, LIU Zuxin, LIU Xinjun, et al. DS-SLAM: A semantic visual SLAM towards dynamic environments[C]. 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 2018: 1168–1174. doi: 10.1109/IROS.2018.8593691. -

 下载:
下载:






图(10) / 表(4)
计量
- 文章访问数: 1115
- HTML全文浏览量: 738
- PDF下载量: 100
- 被引次数: 0
